Команды режима вывода
Система может выводить данные в трех различных режимах:
| Режим проверки | В этом режиме поля выводятся в том виде, в каком они хранятся в записи. При этом система не обеспечивает никаких разделителей между полями или экземплярами повторяющихся полей. Пользователь должен обеспечить адекватное разделение полей с помощью команд размещения, литералов или повторяющихся групп. Режим обычно используется для вывода записей с целью проверки правильности введенных данных; | ||
| Режим заголовка | Этот режим обычно используется для печати заголовков при выводе указателей и таблиц. Все управляющие символы, введенные вместе с данными, такие как разделители терминов (< и >) игнорируются (за исключением указанных ниже случаев), а ограничители подполей заменяются знаками пунктуации (см. ниже); | ||
| Режим данных | Этот режим похож на режим заголовка, но дополнительно после каждого поля автоматически ставится точка (.), за которой следуют два пробела (или просто два пробела, если поле заканчивается каким-либо знаком пунктуации). Отметим, однако, что эта автоматическая пунктуация подавляется, если за командой вывода поля следует суффикс-литерал (см. п. 5 "Литералы"). |
Когда система форматирует поле, содержащее подполе, в режимах заголовка или данных, она автоматически заменяет имеющиеся разделители подполей знаками пунктуации (при этом первый разделитель подполей, если он имеется, всегда игнорируется). Специальная комбинация символов "><"
заменяется на "; ", обеспечивая простой способ форматирования полей, содержащих перечень ключевых фраз, заключенных в угловые скобки. Таблица стандартного замещения разделителей подполей выглядит так:
^a замещается на "; "
от ^b до ^i замещается на ", "
все другие замещаются на ". "
Команды режима вывода представляются в виде Mmc, где:
М - признак команды режима вывода.
m следующим образом определяет режим вывода:
Р режим проверки;
H режим заголовка;
D режим данных.
с - определяет необходимость преобразования букв в прописные:
U буквы преобразуются в прописные;
L буквы преобразованию не подвергаются.
Команда режима вывода может появляться в формате столько раз, сколько это нужно и действует до следующей команды режима вывода. По умолчанию система использует команду MPL. На рис. 6 приведены примеры использования команды.
Формат Выходные данные
----------- ------------------------------------------------------------
mpl,v200 ^aКонструктор Сухой. Люди и самолеты
mhl,v200 Конструктор Сухой. Люди и самолеты
mdl,v200 Конструктор Сухой. Люди и самолеты.
mdu,v200 Конструктор Сухой. Люди и самолеты.
mpl,v210 ^cВоенное изд-во^aМ.^d1993
mdl,v210 Военное изд-во; М., 1993.
Рис. 6
Команды вывода полей
Команды вывода полей - это команды, используемые для извлечения из записи и вывода конкретного поля или подполя. Имеется специальная команда для извлечения и вывода номера записи MFN, хотя, строго говоря, MFN не является полем (MFN не имеет метки).
Комплексный и Последовательный поиски
Факт включения данных видов поиска в сценарий поиска определяется двумя параметрами.
Параметр ComplSearch определяет включение Комплексного поиска: значение 1 - включать, 0 - не включать; по умолчанию - 0.
Параметр SeqSearch определяет включение Последовательного поиска: значение 1 - включать, 0 - не включать; по умолчанию - 0.
Комплексный поиск
Данный вид поиска предназначен для реализации сложных запросов - а именно, для выполнения одновременного поиска по различным элементам описания (видам терминов). Для выполнения комплексного поиска служит соответствующая форма (см. рис. 2.3.4а)
Форма состоит из двух основных рабочих областей:
Область СЦЕНАРИЙ ПОИСКА - служит для формулировки комплексного запроса.
Область СЛОВАРЬ - служит для представления словаря соответствующих терминов с целью их отбора для поиска. Данная область полностью аналогична одноименной области непосредственно на плоскости ПОИСК.
Основным элементом области СЦЕНАРИЙ ПОИСКА является таблица, с помощью которой формулируется собственно комплексный запрос. Каждая строка таблицы служит для описания одного вида поиска и включает пять элементов (соответствующих колонкам таблицы):
*
ВИД ПОИСКА - определяет элемент описания, по которому необходимо провести поиск (ключевые слова, автор, и т.п.). Элемент выбирается с помощью ниспадающего меню, содержащего все элементы, по которым возможен поиск по словарю. Выбор определенного элемента приводит к тому, что соответствующий словарь отображается в области СЛОВАРЬ.
* ТЕРМИН - содержит собственно поисковый термин в соответствии с выбранным видом поиска. Термин может вводиться с клавиатуры или выбираться из словаря. На одной строке может указываться единственный термин (одно ключевое слово, один автор, одно заглавие и т.п.).
* УСЕЧЕНИЕ - определяет, должен ли использоваться аппарат усечения при поиске по данному термину (см. п. 2.3.2).
* КОНТЕКСТ - используется только для вида поиска КЛЮЧЕВЫЕ СЛОВА. Определяет, в каких элементах данных должен находиться заданный термин (см.
п. 2.3.2). Вводится с помощью ниспадающего меню.
* ЛОГИКА - определяет логический оператор, с помощью которого данный термин должен объединяться со следующим термином (см. п. 2.3.2). Вводится с помощью ниспадающего меню.
Рекомендация: Одноименные виды поиска следует указывать последовательно (друг за другом) - при этом они будут объединяться в одну логическую группу.
Кнопка УДАЛИТЬ служит для очистки текущей строки таблицы комплексного запроса.
Кнопка НОВЫЙ служит для очистки всей таблицы запроса.
Для выполнения сформулированного запроса следует нажать кнопку ВЫПОЛНИТЬ.
В случае ненулевого результата комплексного поиска можно перейти к просмотру полученных результатов, нажав кнопку ПРОСМОТР.
Для возврата к основной плоскости ПОИСК необходимо нажать кнопку ВЫХОД.
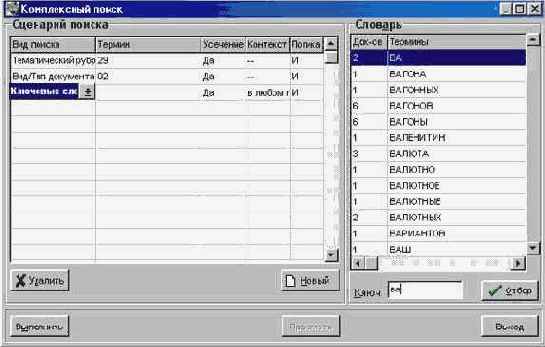
Рис. 2.3.4а.
Форма для комплексного поиска
Контекстные уточнения для поиска "Ключевые слова"
Данное средство сценария поиска позволяет вводить контекстные уточнения для поиска "Ключевые слова" (предполагается, что таковым является первый поиск в общем списке поисков по словарю), т.е. в этом случае у пользователя появляется возможность при поиске по ключевым словам указывать, в каких именно элементах описания должны присутствовать искомые ключевые слова (компонент "Термины в" на плоскости "ПОИСК").
Каждый вид контекстного уточнения описывается двумя параметрами:
CvalifNameNN
CvalifValueNN
где NN - порядковый номер вида контекстного уточнения в общем списке (начиная с 0).
Параметр CvalifNameNN служит для указания названия контекстного уточнения. Например:
CvalifName2=Коллектив/Мероприятие
Параметр CvalifValueNN служит для указания значений идентификаторов поля, определяющих соответствующий контекст уточнения. В общем виде параметр указывается следующим образом:
CvalifValueNN=/(mm1,mm2,….)
где:
mm1,mm2,… - идентификаторы полей.
Указываемые в параметре CvalifValueNN идентификаторы полей фактически определяют вторую компоненту индексных ссылок для поисковых терминов (см. Приложение 5). Пример:
CvalifValue2=/(3)
Общее количество видов контекстных уточнений указывается в параметре CvalifNumb. Например:
CvalifNumb=4
Контроль системы книговыдачи
Контроль системы книговыдачи служит для обнаружения и устранения несогласованностей сведений о книговыдаче в базе данных читателей и базах данных Электронного каталога, которые могут возникать в результате аварий. Возможны два подхода в обнаружении несогласованностей:
Со стороны БД читателя: для каждой записи читателя-должника по данным, указанным в ней, должна быть доступна БД каталога, по шифру документа должна находиться единственная запись каталога, в этой записи должно быть поле экземпляра с заданным инвентарным номером, статус этого экземпляра должен иметь значение "занят" или "многоэкземплярность" с правильным соотношением количества полученных и выданных экземпляров". Нарушение одного из условий считается рассогласованием первого типа, т.е.:
не найдена БД каталога
более одной записи каталога
не найдена запись в БД каталога
найдена запись каталога, но нет поля экземпляра с искомым инвентарным номером
в записи каталога найден нужный экземпляр, но значение статуса не "занят" и не "многоэкземплярность"
при статусе "многоэкземплярность" некорректное соотношение между количеством полученных и выданных экземпляров
Со стороны БД каталога: для экземпляра издания в БД каталога, который числится как занятый или многоэкземплярный при корректном соотношении количества полученных и выданных экземпляров в БД читателя должен существовать читатель, за которым числился бы данный экземпляр. Рассогласованием второго типа считаются ситуации:
некорректное соотношение количеств полученных и выданных экземпляров
нет читателя с данным шифром издания
есть читатель, но он не должник
у читателя-должника для данного шифра издания имя БД каталога или инвентарный номер экземпляра издания не совпадают со значениями в записи каталога
Для запуска контроля системы книговыдачи служит кнопка ВЫПОЛНИТЬ в области КОНТРОЛЬ СИСТЕМЫ КНИГОВЫДАЧИ. Возникающая при этом форма (см. рис. 4.5.2а) служит для указания параметров контроля.
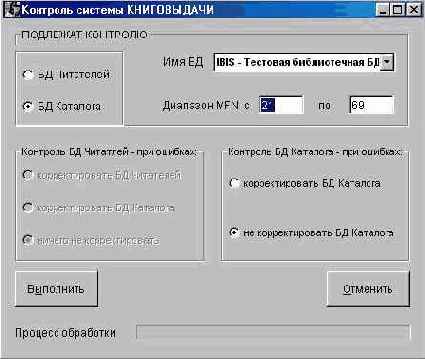
Рис. 4.5.2а. Форма для контроля системы Книговыдачи
Прежде всего необходимо определить режим проверки, сделав соответствующий выбор на панели ПОДЛЕЖАТ КОНТРОЛЮ. Возможны два режима проверки:
БД ЧИТАТЕЛЕЙ. За основу при проверке выбирается база данных читателей. При этом обнаруживаются рассогласования первого типа.
При выборе этого режима активизируется левая панель выбора режимов корректировки:
корректировать базу данных читателя: при обнаружении рассогласования в первых двух случаях, указанных выше, запись читателя корректироваться не будет, в остальных случаях в записи читателя будет оформляться возврат, т.е. записываться дата возврата равная текущей дате;
корректировать базу данных каталога: при обнаружении рассогласования в БД каталога для пятого случая из приведенных выше соответствующий экземпляр помечается как "занятый", остальные случаи отмечаются в протоколе;
ничего не корректировать: информация о рассогласовании только выводится в протокол.
БД КАТАЛОГА. За основу при проверке выбирается база данных каталога и обнаруживаются рассогласования второго типа. При этом предлагается выбрать БД каталога из списка. Если такой выбор не сделан, то проверяются последовательно все БД каталога. Можно задать диапазон MFN проверяемых записей.
При выборе этого режима активизируется правая панель выбора режимов корректировки:
корректировать БД каталога: при обнаружении рассогласования в первом случае из приведенных выше запись корректироваться не будет, для остальных случаев соответствующий экземпляр в записи каталога помечается как "свободный";
не корректировать БД каталога: при обнаружении рассогласования выдается лишь информация в протокол.
Для начала процесса контроля следует нажать кнопку ВЫПОЛНИТЬ. В стандартном диалоговом окне следует задать имя файла протокола или отказаться от его формирования. По завершении процесса контроля выдается соответствующее сообщение.
Копирование документов
Режим предназначен для копирования документов - указанных в виде диапазона внутренних номеров (MFN), отобранных в результате поиска или отмеченных в процессе просмотра - в качестве новых документов в текущую или другую БД. Возможно структурное преобразование документов в процессе копирования в соответствии со специальными таблицами переформатирования. Данный режим, в частности, используется при формировании описаний продолжающихся изданий на основе уже имеющихся поступлений и при формировании аналитических описаний статей на основе имеющихся описаний журналов (подробно об этом в Инструкции каталогизатора).
Следует помнить, что режим копирования связан с текущим контекстом работы, т.е. с установленной подплоскостью: если установлена подплоскость БАЗА ДАННЫХ/ MFN, предполагается копирование документов из установленной базы данных по номерам (MFN); если установлена подплоскость РЕЗУЛЬТАТ ПОИСКА, предполагается копирование результатов поиска по текущему запросу. В частности, если, например, установлена подплоскость РЕЗУЛЬТАТ ПОИСКА и не выбран ни один из запросов (это может быть, когда не проводился ни один поиск) или выбран запрос с нулевым результатом поиска, то нажатие кнопки КОПИРОВАНИЕ не дает никакого эффекта.
После нажатия кнопки КОПИРОВАНИЕ
возникает форма, которая служит для ввода параметров режима копирования (см. рис. 3.3.2а).
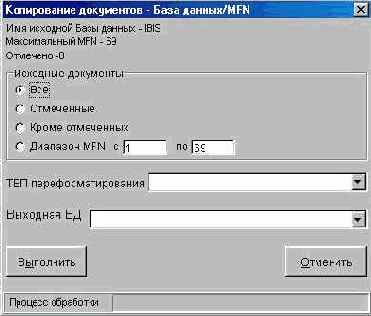
Рис. 3.3.2а.
Форма для ввода параметров копирования
Пользователю предлагается указать следующие параметры:
ИСХОДНЫЕ ДОКУМЕНТЫ - определяет, какие документы будут копироваться. Здесь можно выбрать одно из возможных значений:
ВСЕ - в этом случае будут копироваться все документы в соответствии с контекстом работы: если установлена подплоскость БАЗА ДАННЫХ/MFN - все документы текущей базы данных; если подплоскость РЕЗУЛЬТАТ ПОИСКА - полностью результат поиска по текущему запросу;
ОТМЕЧЕННЫЕ - при этом будут копироваться только документы отмеченные на установленной подплоскости просмотра (имеет смысл только в случае, когда таковые имеются);
КРОМЕ ОТМЕЧЕННЫХ - копируются все документы текущего контекста за исключением отмеченных (при отсутствии отмеченных это равносильно значению ВСЕ);
ДИАПАЗОН MFN - копируются документы текущего контекста, попадающие в указанный диапазон внутренних номеров (MFN). Например, если установлена подплоскость РЕЗУЛЬТАТ ПОИСКА, копируются те документы из результата поиска, чьи номера попадают в указанный диапазон. По умолчанию, если не указана ни нижняя, ни верхняя границы диапазона, понимается весь диапазон документов базы данных от первого до последнего. Если указана лишь одна из границ, вторая считается равной первой, т.е. рассматривается диапазон, содержащий один документ.
ТВП ПЕРЕФОРМАТИРОВАНИЯ - параметр позволяет указать имя таблицы переформатирования, в соответствии с которой будет производиться структурное преобразование документов в процессе копирования. Конкретная таблица переформатирования выбирается из предлагаемого (в ниспадающем меню) списка. Назначение таблиц переформатирования, предлагаемых для БД Электронного каталога, описано в Инструкции каталогизатора. Если таблица переформатирования не задается - документы копируются без преобразования;
ВЫХОДНАЯ БД - параметр позволяет указать базу данных, в которую будут копироваться заданные документы, т.е. БД, в которой будут создаваться новые документы. Это может быть та же самая база данных или иная. Для выбора предлагается список доступных баз данных. Если выходная БД не задана - копирование не выполняется.
Собственно процесс копирования начинается после нажатия кнопки ВЫПОЛНИТЬ.
Завершается процесс копирования сообщением о внутренних номерах (MFN) документов, созданных в процессе копирования.
Копирование в новый документ по результатам поиска
Копирование документов можно проводить в двух режимах на разных плоскостях:
· на плоскости ПРОСМОТР/ВЫВОД – при копировании группы документов, найденных по результатам поиска, или отмеченных, или заданных интервалом номеров в БД, при всех одинаковых параметрах копирования (одна для всех копируемых документов таблица переформатирования, одна БД для записи новых документов);
· на плоскости ВВОД – при копировании одного документа, непосредственно выведенного на экран, путем нажатия кнопки-ярлычка в правой верхней части экрана.
В обоих случаях копируемый документ может быть задан либо номером в БД (на подплоскости БАЗА ДАННЫХ/MFN), либо по результатам поиска на соответствующей подплоскости.
Работа состоит из следующих этапов:
· просмотреть найденный(е) документ(ы) в коротком и/или полном формате (ПРОСМОТР/ВЫВОД – РЕЗУЛЬТАТЫ ПОИСКА) – см. выше;
· отметить (при необходимости) документ или несколько документов, которые наиболее близко подходит к БО новых поступлений (кнопка ОТМЕТИТЬ) – см. выше;
· определить режим копирования (1 или 2 - см. выше), наиболее подходящий для конкретной задачи, и соответственно этому выбору:
· либо нажать кнопку КОПИРОВАНИЕ (оставаясь на плоскости ПРОСМОТР/ВЫВОД) и установить, какие из найденных документов будут копироваться (ВСЕ, или ОТМЕЧЕННЫЕ, или КРОМЕ ОТМЕЧЕННЫХ),
· либо перейти на плоскость ВВОД и установить, соответственно, подплоскость РЕЗУЛЬТАТЫ ПОИСКА или ОТМЕЧЕННЫЕ;
· определить (по ниспадающему меню) Таблицу выбора полей (ТВП) переформатирования; характер основных преобразований показан в Таблице 2 ("Перечень таблиц преобразования");
Работа состоит из следующих этапов:
· провести поиск документа-источника или другой статьи из того же источника: если для копирования выбирается номер журнала, то поиск проводится по шифру издания (с учетом нумерации) или по заглавию журнала с последующим включением через связь (клавиша ПОИСК ПО СВЯЗИ) всех номеров этого журнала и отметкой нужного номера; если для копирования выбирается книга или статья, то поиск проводится по заглавию или другому поисковому признаку;
· просмотреть найденный документ (ПРОСМОТР/ВЫВОД), при наличии "Содержания" или "Оглавления номера" - отметить документ для копирования (кнопка ОТМЕТИТЬ); в этом случае копирование целесообразно проводить непосредственно из документа на плоскости ВВОД (см. выше);
· выбрать режим КОПИРОВАНИЕ (кнопка на плоскости ПРОСМОТР/ ВЫВОД или кнопка-ярлык на плоскости ВВОД);
· при работе из документа при наличии полей "Содержание" или "2-я и последующие статьи сборника", или "Статьи из журнала" прежде, чем нажать кнопку-ярлык, ввести номер статьи для копирования (в документе-книге – на странице "Технология", в документе-номере журнала – на странице "Оглавление");
· выбрать из меню таблицу переформатирования (ниспадающее меню) с учетом вида документа и необходимости использования данных "Содержания";
· определить "Имя базы данных для копирования" (меню по кнопке): это может быть либо та же БД, в которой находится копируемый документ, либо другая;
· после сообщения системы о вводе нового документа (и его номере) перейти в режим ВВОД – БАЗА ДАННЫХ/MFN задавая номера новых (скопированных) записей;
· последовательно заполнять недостающие данные на страницах РЛ, вызывая вложенные РЛ (если есть кнопка расширенных средств ввода) и просматривая документ в окне просмотра перед переходом на очередную страницу. ЭД БО вводятся с учетом рекомендаций п.4.2; если копировалось полное описание статьи, откорректировать введенные данные;
· завершить ввод документа (кнопка СОХРАНИТЬ).
· установить ( по ниспадающему меню) выходную БД, в которую будут записываться новые (скопированные) документы;
· нажать кнопку ВЫПОЛНИТЬ – после завершения процесса копирования на экране появляется сообщение о количестве и номерах скопированных документов;
· перейти на рабочую плоскость ВВОД, подплоскость База данных/MFN и откорректировать документ с учетом специфики заполнения полей (п.4.2) и рекомендаций, указанных в Таблице 2. Во всех случаях обратить внимание на ввод данных нумерации, проверить заглавие, выходные данные и количественные характеристики; для получения подробной информации, касающейся текущего поля, нажимать клавишу <F1>;
· просматривать документ при переходе на новую страницу для самоконтроля;
· завершить ввод (кнопка СОХРАНИТЬ), но обязательно предварительно просмотреть документ, оценивая соответствие описания на экране каталогизируемому изданию.
Сведения об экземплярах переносятся при копировании Спецификации тома только частично: переносятся ЭД "Место хранения" и "Канал поступления" (предполагается, что число экземпляров и их направление являются общими для всех томов одного издания), а ЭД "Статус" определяется равным "2" (экземпляр ожидается).
В новом документе необходимо определить полученные экземпляры - заменить значение статуса на "0" (экземпляр поступил) и внести инвентарный номер и штрих-код; дата регистрации, идентификатор партии (номер КСУ и номер акта) для этих экземпляров при сохранении документа будут введены автоматически. Сведения о других, еще не полученных экземплярах тома, будут рассматриваться системой (и идентифицироваться в форматах выдачи) как заказанные (ожидаемые).
При вводе библиографических данных тома следовать рекомендациям, данным в п.5.1.1.1 для однотомных изданий.
Корректировка
Кнопка КОРРЕКТИРОВКА вызывает форму ввода/корректировки записей (см. рис. 6.5.1а). Вид формы и функционирование ее элементов аналогичны плоскости ввода/корректировки АРМа КАТАЛОГИЗАТОР.
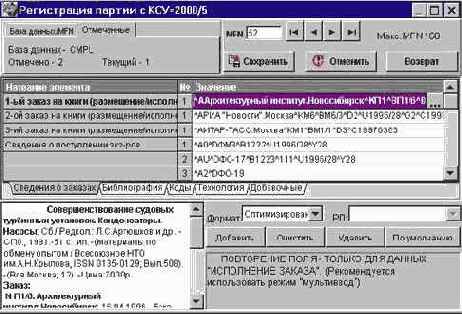
Рис. 6.5.1а. Общий вид формы ввода/корректировки данных
Особенности функционирования режима ввода/корректировки следующие:
Форма состоит из двух плоскостей - БАЗА ДАННЫХ/MFN и ОТМЕЧЕННЫЕ. Если при вызове формы были отметки в словаре или в списке, то отмеченные записи подаются на корректировку в режиме ОТМЕЧЕННЫЕ. При вводе новой записи форма вызывается в режиме БАЗА ДАННЫХ/MFN, устанавливается нужный РЛ и активизируется кнопка НОВЫЙ для ввода последующих новых записей. Независимо от начального состояния формы можно переустанавливать плоскость, вызывать записи на корректировку по их номерам MFN.
Кнопка ВОЗВРАТ служит для возврата в основной модуль.
В окне ФОРМАТ подается список форматов, состав которого зависит от вида рабочего листа текущей (корректируемой) записи.
Если форма вызывается в режимах ПОСТУПЛЕНИЕ или ВЫБЫТИЕ и отмечены записи для корректировки, то будет прочитано значение номера записи КСУ из таблицы настройки и выдано сообщение об установленном значении КСУ для подтверждения корректировки. Установленное значение КСУ будет при корректировке записи автоматически вноситься в поле экземпляра. В заголовке формы указывается, какое значение номера КСУ установлено.
Есть возможность определять как недоступные некоторые функции формы: добавление новых элементов описания, возможность смотреть или корректировать данные на добавочной странице. Для этого используется параметр ini-файла AccessLevel.
Есть возможность определить недоступным сам режим корректировки и ввода новых записей в БД. Для этого служит параметр ini-файла AccessCorr.
Корректировка документов по словарю
Режим предназначен для групповой корректировки документов на основании данных словаря. Режим выполняется в контексте рабочей области СЛОВАРЬ на плоскости ПОИСК и для его вызова служит соответствующая кнопка в этой области. Форма для выполнения данного режима представлена на рис. 3.4.5а.
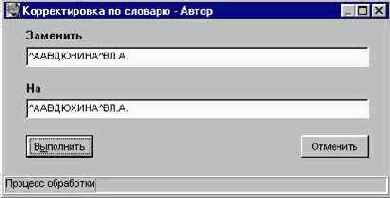 |
Рис. 3.4.5а. Форма для выполнения корректировки по словарю
В строке ЗАМЕНИТЬ системой указывается исходное значение, подлежащее корректировке и соответствующее текущему термину СЛОВАРЯ, - это значение может совпадать с собственно термином словаря или представлять собой полные данные из документа, соответствующие этому термину (в частности, они могут содержать разделители подполей).
В строке НА пользователь указывает результирующее значение, на которое должно быть заменено исходное значение. При указании результирующего значения НЕ СЛЕДУЕТ удалять или изменять разделители полей - если система предлагает их по умолчанию.
Во избежании ложных контекстных замен не следует применять данный режим для корректировки ключевых слов, в особенности коротких.
Собственно процесс корректировки начинается после нажатия кнопки ВЫПОЛНИТЬ. Результат корректировки выводится на экран в виде протокола.
Корректура документа - номера журнала
Корректировка документа - отдельного номера журнала (или другого сериального издания), автоматически создаваемого при регистрации каждого поступления выполняется в следующих случаях (код РЛ "NJ"):
· Ввод "Оглавления" - данных о статьях, напечатанных в номере, не введенных при регистрации, (полностью или частично) и "Приложений на вкладках";
· Ввод данных в повторяющееся поле "Кумулированные номера за другой год" - частные Шифры выпусков журнала за не первый год из кумулированного выпуска. Для приведенного выше примера это может выглядеть следующим образом (шифр журнала, например, С15, данные представлены с подполями):
– 1-е поле (Год, Шифры): ^02000^1С15/2000/1^2С15/2000/2^3С15/2000/3^4С15/2000/4;
– 2-е поле (Год, Шифры): ^02001^1С15/2001/1^2С15/2001/2^3С15/2001/3,
По результатам ввода этих данных в словарь будут включены все шифры, что обеспечит поиск каждого отдельного номера и возможность определения неполученных номеров журналов, а результат поиска будет отсылать к единственному кумулированному выпуску.
Примечание:
Частные Шифры первых трех выпусков журнала за первый (или единственный) год из кумулированного выпуска формируются автоматически; недостающий частный шифр 4-го выпуска нужно дополнительно ввести в поле "Дополнение к номеру";
· Корректировка данных в полях "Вид и объем ресурса" и "Примечания", перенесенных из записи БО, как общие данные, если данные конкретного выпуска отличаются от общих;.
· Ввод сведений о наличии графической информации и полных текстов (см. п. 4.2.9);
· Ввод данных о датах и направлениях передачи номера в пункты технологического пути;
Примечание:
Данные о статьях, введенные в документ-номер журнала, могут быть в дальнейшем использованы при создании самостоятельных документов - аналитического описания статьи (в этой же или в отдельной БД) - см. п. 5.3;
· Ввод сведений о вновь поступивших (не первых) экземплярах;
· Исправление ошибок в регистрационных данных номера (шифр, год, том, номер, примечания), сведениях об экземплярах, сведениях о статьях.
Поиск документа-номера журнала для корректуры может быть проведен двумя путями в зависимости от принятой системы шифровки изданий (см. выше п. 4.2.8):
· Библиотека ведет систему шифровки применительно к журналам; это означает, что в процессе ввода БО журнала в документ был записан шифр, с которым связан каждый номер (выпуск) журнала. В этом случае чтобы найти нужный номер, зная общий для всех номеров шифр, нужно выбрать режим "ПОИСК - ШИФР ИЗДАНИЯ" и искать уникальный шифр номера в структуре: <Общая часть шифра> / <Год> /<Том> / <Номер>, например, W10/1994/11/3;
· Библиотека не применяет никакой системы шифровки. В этом случае нужно:
· в режиме ПОИСК-ЗАГЛАВИЕ ЖУРНАЛА найти запись БО журнала;
· выйти в режим ПРОСМОТР результатов поиска;
· выполнить ПОИСК ПО СВЯЗИ (выбрав элемент для поиска "ЖУРНАЛ – НОМЕРА"), в результате которого будут отобраны ВСЕ зарегистрированные номера журнала в порядке их ввода в БД;
· в процессе их просмотра найти и отметить нужный документ, и затем перейти в режим ВВОД (корректировка) отмеченных документов.
В то же время при необходимости внесения изменений во все документы-номера журнала (аналогично книгам - см.выше п.5.1.2) путь поиска по связи оказывается очень удобным.
Корректура документов
Исправление грамматических и других ошибок, пополнение документов данными о новых поступлениях (экземплярах) и другие подобные действия выполняются в режиме корректуры документов. Корректировка документов осуществляется также на плоскости ВВОД, соответственно на подплоскости БАЗА ДАННЫХ/MFN (корректура по номеру записи в БД) или подплоскости РЕЗУЛЬТАТЫ ПОИСКА (корректура предварительно найденных документов), или на подплоскости ОТМЕЧЕННЫЕ (корректура документов, отмеченных при просмотре результатов поиска). В любом варианте нет необходимости явно определять РЛ, поскольку при корректировке документа-КНИГИ он автоматически подается в соответствии с Кодом РЛ, введенным в документ (в меню он определяется как оптимизированный); при необходимости он может быть изменен (см. п. 4.2.9).
Примечание: Сведения о новых экземплярах (доукомплектование) переносятся в записи БД каталога автоматически из БД комплектования; списание отдельных экземпляров из БД каталога осуществляется также через АРМ "Комплектатор"; проверка фонда проводится в АРМе "Каталогизатор" в режиме корректуры по специальной технологии (см. ниже).
В процессе работы может случиться ситуация, при которой произойдет "размножение" ошибки - например, заглавие общей части многотомного издания, введенное с грамматической ошибкой в один документ, затем переносится при копировании во все другие документы этого издания; к такому же результату может привести ввод через словарь наименования КА или ВКА, или заглавия серии, или предметных рубрик и т.п., если они первоначально были введены в документ с ошибкой. Кроме того, может возникнуть необходимость изменения какого-то ЭД в описаниях всех томов издания в связи, например, с переименованием города, коллектива и т.п.
Во всех этих и подобных им случаях при обнаружении ошибки (возможно, случайном) необходимо обеспечить корректуру всех "связанных" документов в БД электронного каталога. Это можно сделать, проведя корректуру по результатам поиска, причем для поиска нужно задать общий для всех документов набор ЭД, например, заглавие общей части (в томах с частным заглавием при монографическом описании оно выбирается в поисковый словарь из области серии БО, а при сводном описании — из области общей части БО).
Корректуру такого вида целесообразно проводить в режиме Глобальной корректировки документов (см. ниже п. 5.4).
Последовательно просматривая (листания) словари, специалист (каталогизатор, библиограф) легко определит два (или более) рядом стоящие различные написания одного и того же значения поискового термина. Поэтому рекомендуется периодически просматривать словари авторов, заглавий, коллективов, ключевых слов и др. с целью выявления ошибок.
Исправление ошибок, выявленных по словарю, может быть проведено в режиме "Корректировка по словарю" – для тех словарей, у которых высвечивается ярлык режима корректировки (на плоскости ПОИСК, в правом нижнем углу области СЛОВАРЬ).
Работа состоит из следующих этапов:
· установить курсор на термин словаря, требующий корректировки, (при просмотре термина "полностью" (по нажатию правой кнопки мыши) можно определить ошибку в той его части, которая не попадает на обычный просмотр);
· нажать кнопку-ярлык корректировки по словарю – в окне показываются "Заменяемое значение", не подлежащее корректировке (в формате с подполями, на полную длину с возможностью использования скроллинга), и "Заменяющее значение", которое нужно откорректировать;
· нажать кнопку ВЫПОЛНИТЬ;
· просмотреть Протокол корректировки документов, содержащий сведения об откорректированных терминах словаря (указываются MFN документа, метка откорректированного поля и номер его повторения (tag= , occ= )).
В протоколе может присутствовать сообщение "Нет поля/данных для корректировки". Оно может появиться в следующей ситуации:
Один и тот же термин словаря может быть представлен в документе в разных формах, так, например, авторы в разных полях присутствуют либо вместе с инициалами или полным именем, либо раздельно, а в словаре они представлены в единой форме.
"Заменяемое значение" выбирается из первого
документа, поданного на корректуру по результатам поиска, в том формате, в каком оно присутствует в этом документе, и сообщения в протоколе относятся к тем документам, в которых формат заменяемых данных отличается от того, который был подан на корректировку. В этом случае в словаре остается некоторое число неисправленных терминов, которые могут быть откорректированы в следующем сеансе с другим форматом "Заменяемого значения" (он будет подан из первого из оставшихся не откорректированными документами).
Корректура документов-книг, полученных по предварительному или другому заказу
Эта работа ведется только в БД комплектования и состоит из следующих этапов:
·
Найти и отметить в одном из словарей книги, которые поступили на регистрацию; при этом можно использовать словари Заглавий и Авторов, но наиболее удобно использовать словарь "Организация — заказанные книги"; в нем представлены все организации (найти и выделить курсором организацию, из которой поступила регистрируемая партия книг), а в окне связанных записей — перечень кратких БО книг, заказанных в данной организации (числящихся за ней);
· При работе со словарем "Организация — заказанные книги" отметить документы, которые действительно получены в данной партии — либо в окне связанных записей (из полного списка книг, заказанных в выделенной организации), либо по словарям заглавий или авторов;
· Нажать (щелкнуть мышкой) клавишу КОРРЕКТИРОВКА;
· Ответить на вопрос системы "Продолжить работу? Да Нет", которое следует за одним из следующих сообщений:
· Регистрация партии с КСУ=<Значение, установленное по кнопке "Настройка">,
· Не установлено значение КСУ.
При положительном ответе на оба вопроса работа продолжается — вызывается модуль ввода/корректировки и система переходит в режим корректуры отмеченных документов; в первом случае установленное КСУ будет автоматически вводиться в поля об исполнении заказа и о полученных экземплярах, а во втором — значения КСУ в эти поля нужно будет вводить с клавиатуры.
При отрицательном ответе на оба вопроса система остается в том же состоянии (отметки документов, подлежащих корректуре, сохраняются); для продолжения работы нужно ввести или изменить значение КСУ по кнопке "Настройка" и опять нажать кнопку КОРРЕКТИРОВКА.
· Последовательно ввести данные в каждый отобранный документ-книгу в следующие поля:
· "1,2,3-й заказ на книги — Размещение/Исполнение" — обязательно; ввести ЭД "Получено (экз)"; при поэтапном исполнении заказа для каждой полученной партии, начиная со второй, для ввода этого ЭД заполняется новая строка;
· "Сведения о заказе/поступлении экземпляров" — обязательно; если не было введено при заказе, поле вводится как новое, иначе — корректируется (исключение для томов многотомника – см. ниже п.3.2.4);
· Сведения о цене издания (если не было введено при заказе);
· Откорректировать библиографические данные (заглавие, выходные данные, раздел знаний и т.п.) — при необходимости;
· В процессе ввода данных в окне просмотра можно видеть БО издания и введенные данные и следить за корректностью вводимой информации.
Примечание: При наличии кодированных ЭД "язык текста", "тип", "вид" и "характер" документа (с учетом ЭД "получено не на баланс"), а также индексов УДК/ББК или ЭД "Раздел знаний" после завершения обработки всей партии книг, автоматически будут получены данные по распределению всей полученной литературы по соответствующим разрезам.
Цена первого экземпляра (или всех при равных их ценах) вводится в поле "ISBN, Цена"; для экземпляров, цена которых отличается от общей, цена вводится в поле конкретного экземпляра.
В полях "РАЗМЕЩЕНИЕ/ИСПОЛНЕНИЕ ЗАКАЗА" (для 1-го, 2-го и 3-го заказов) должен быть отмечен факт частичного или полного выполнения соответствующего заказа. Для этого в части "ПОЛУЧЕНО" для соответствующего заказа вводится только один ЭД — число полученных экземпляров; при поэтапном исполнении заказа для каждой полученной партии, начиная со второй, для ввода этих данных заполняется новая строка:
Примечание: ЭД " Номер записи КСУ поступлений" будет введен автоматически при сохранении документа (вводится значение, установленное по кнопке "Настройка"),
В поле "СВЕДЕНИЯ О ПОСТУПЛЕНИИ ЭКЗЕМПЛЯРОВ" для каждого полученного экземпляра необходимо ввести (по клавише <F2> или кнопке с тремя точками вызываются вложенные РЛ):
· новый статус (получен) — с использованием меню,
Примечание: для заказов со статусами "C" и "U" (ЦБС или ВУЗ) статус менять не нужно.
· инвентарный номер (вводится с использованием аппарата "максимальных номеров"; достаточно перенести из словаря указанное в нем значение, на единицу большее последнего введенного номера);
· штрих-код,
· номер записи КСУ и/или акта ИУ (если не установлено по кнопке "Настройка"),
· цена экземпляра, отличная от общей.
ЭД "Номер записи КСУ" или/и "Номер акта" имеют особое значение, поскольку они определяют принадлежность определенного(ых) экземпляра(ов) книги (из многих, полученных в разное время, и, возможно, по разным заказам от разных источников) к определенной партии, что используется при подготовке выходных форм для партии полученных книг.
Кроме того, ввод в данные об экземпляре и об исполнении заказа только этих ЭД, являющихся идентификаторами партии, позволяет привязать общие данные партии (дата поступления, общее количество экземпляров, источник поступления) к каждому из документов-книг, принадлежащих к этой партии.
При корректировке ЭД "Статус экземпляра" могут быть введены значения "0"(получен), "C","U" или "R".
Код статуса "C" используется при обработке данных ЦБС в том случае, когда полученные для сети экземпляры должны быть отражены в Центральном ЭК только общим числом экземпляров и не могут быть выданы, в то время как в каталогах Библиотек сети они представляются индивидуально и выдаются читателям; в выходном документе "Инвентарный список" эти экземпляры не отражаются, но в сведениях об итоговых поступлениях за определенный период учитываются.
Код статуса "U" используется при обработке данных БИУ экземпляров, например, для Библиотек Университетов (ВУЗ), в том случае, когда полученные экземпляры должны быть отражены в Центральном ЭК только общим числом экземпляров и выдаются читателю без определения конкретного экземпляра.
Примечание: Для статусов "C" и "U" число полученных экземпляров указывается в ЭД "Число экземпляров", а в ЭД "Инвентарный номер" может быть указан ГРУППОВОЙ Инвентарный номер (в случае, если таковой применяется пользователем).
Код статуса "R", временный (до сохранения документа), технологический, используется в технологии для облегчения ввода группы экземпляров, описываемых индивидуально и различающихся лишь последовательными инвентарными номерами и местом хранения (остальные ЭД – место хранения, номер партии (КСУ, акт), канал поступления, цена и дата ввода – у них одинаковы); поля экземпляров со статусом "R" при "сохранении" документа автоматически "размножаются" соответственно указанному ЧИСЛУ таким образом, что в каждое из них вводятся:
Статус 0;
ЭД "Инвентарный номер", отличающийся от предыдущего на 1; при этом ПЕРВОМУ экземпляру присваивается инвентарный номер, значение которого либо равно заданному, либо равно 1 (при отсутствии заданного значения в поле со статусом "R");
все остальные данные переносятся без изменения из поля, введенного со статусом "R".
Возможно применение технологии процесса "Размножение экземпляров", позволяющей вводить последовательные инвентарные номера экземпляров для разных мест их хранения:
за одно обращение к справочнику путем группового ввода в повторяющиеся поля отбираются и вводятся в документ направления (места хранения) всех экземпляров; при этом статус может либо отсутствовать, либо быть равным "2" (заказан);
вводится одно поле со статусом "R" (с указанием числа экземпляров и инвентарного номера первого из них) и всеми остальными ЭД, общими для всех размножаемых экземпляров;
при сохранении документа размноженные по инвентарным номерам экземпляры объединяются с направлениями; "лишние" направления формируются как заказанные со статусом "2".
Примечание: Это единственный случай, когда система позволяет временно (до сохранения) записать в документ поля экземпляров без ЭД "Статус" — поля, состоящие только из одного ЭД "Место хранения", и при наличии хотя бы одного поля со статусом "R".
ЧИСЛО экземпляров и НАЧАЛЬНЫЙ номер задаются в ЭД "Инвентарный номер экземпляра" через разделительный знак "/" (например, 5/12567 —
5 экземпляров, начиная с номера 12567).
Структура инвентарного номера определяется пользователем и не контролируется системой. Так, например, номер может начинаться с буквенной части (в разных хранилищах Библиотеки могут применяться разные системы инвентарного учета), или с неизменяемой цифровой части, которая отделяется от изменяемой разделительным знаком, например, знаком "-" или "/" (система инвентарного учета экземпляров под одним инвентарным номером), или сочетание этих двух вариантов, или любая другая конструкция.
Определение структуры и начального значения для автоматического ввода "последовательных" номеров, среди которых каждый следующий отличается от предыдущего на 1, производится по следующему алгоритму:
· для выделения из заданного начального номера изменяемой цифровой части система сканирует заданное значение, начиная справа, и определяет числовую часть его до первого встретившегося нецифрового символа (это — начальное цифровое значение инвентарного номера);
· сканирование продолжается далее (справа налево) для выделения неизменяемой части инвентарного номера (это текст между первым встретившимся нецифровым знаком и последним символом "/", за которым (слева) стоит число);
· если числовая часть справа отсутствует, считается, что начальный номер не задан и счет ведется с 1; при наличии неизменяемой части она включается в номер, изменяемая часть которого начинается с 1.
Примеры задания инвентарных номеров для размножения:
Введено 5/, результат размножения: 1; 2; 3; 4; 5;
Введено 3/123, результат размножения: 123; 124; 125.
Введено 3/1789-, результат размножения:1789-1; 1789-2; 1789-3;
Введено 4/АБ156, результат размножения: АБ156; АБ157; АБ158; АБ159;
Введено 2/К19/12, результат размножения: К19/12; К19/13;
В один документ можно ввести подряд необходимое число повторений поля со статусом "R", например, для групп экземпляров, полученных в разных партиях (по разным каналам) или направляемых в разные места хранения с разной системой инвентарных номеров. При этом начальный номер (если он нужен) ставится только в первом из них или, соответственно, в тех группах, где не должно быть непрерывности.
При вводе можно использовать данные о максимальном значении инвентарного номера из введенных в БД (по клавише <F2> или кнопке открывается словарь), причем если в Библиотеке-пользователе ведется несколько разных систем инвентарных номеров, в словаре будет представлен максимальный введенный номер по каждой системе, например, начинающиеся с разных букв); однако, если работу по присвоению инвентарных номеров ведут одновременно несколько человек, могут случаться накладки в случае их обращения к словарю, еще не актуализированному после "взятия" номера одним из них.
Штрих-код, естественно, оригинальный, вводится индивидуально для каждого экземпляра в полученные повторения поля.
Инвентарный номер и штрих-код экземпляра автоматически проверяются на дублетность с введенными ранее в БД. Проверка проводится как по БД комплектования, так и по БД каталога (но не внутри одного документа). При этом дублетный штрих-код системой блокируется, а дублетный инвентарный номер пропускается с выдачей сообщение о дублетности.
Литералы
Литерал - это строка символов, заключенная в соответствующие ограничители, которая вносится в выводимый текст в таком виде, как она приведена в формате. Литералы могут использоваться, например, для именования полей.
Существуют литералы трех типов:
| Условный литерал | Он определяет текст, который будет выведен только в случае присутствия в записи соответствующего ему поля/подполя. Если поле является повторяющимся, то текст будет выведен только один раз, независимо от количества экземпляров поля/подполя. Условные литералы заключаются в двойные кавычки ("), например, "Заглавие: ". | ||
| Повторяющийся литерал | Он определяет текст, который будет выведен только в случае присутствия в записи соответствующего ему поля или подполя. Однако, если поле повторяющееся, литерал будет выводиться для каждого экземпляра поля/подполя. Повторяющиеся литералы заключаются в вертикальные черты (|), например, |Автор: |. | ||
| Безусловный литерал | Он определяет текст, который будет выведен независимо от наличия поля в записи. Безусловные литералы заключаются в одинарные кавычки (') или (‘), например, 'Краткое содержание' или ‘Заголовок‘. |
Литерал не должен содержать ограничителей литерала. Например, безусловный литерал не может содержать одинарную кавычку (хотя может содержать двойные кавычки и/или вертикальные черты).
Условные и/или повторяющиеся литералы связываются с полем или подполем своим расположением в формате. Литералы, предшествующие команде вывода поля/подполя, называемые префикс-литералами, выводятся перед содержимым поля/подполя, в то время, как литералы, следующие за командой вывода поля/подполя, называемые суффикс-литералами, выводятся после содержимого поля/подполя.
Если за повторяющимся префикс-литералом непосредственно следует знак '+' (например, |xxx|+), то он будет выведен перед каждым, кроме первого, экземпляром поля/подполя.
Если повторяющемуся суффикс-литералу непосредственно предшествует знак '+' (например, +|xxx|), то он будет выведен после каждого, кроме последнего, экземпляра поля/подполя.
С полем/ подполем может быть связан более чем один литерал. В этом случае различные литералы должны подчиняться следующим правилам и порядку:
префикс-литералы:
1. Один или более условных префикс-литералов. За условным префикс-литералом могут следовать другие условные префикс-литералы, команды вертикального и горизонтального размещения, и/или команды режима вывода. Все команды между первым условным префикс-литералом и соответствующей ему командой вывода поля/подполя становятся условными и будут выполнены только при наличии поля/подполя, иначе они игнорируются.
2. Один и только один повторяющийся префикс-литерал. Если такой литерал есть, то он должен непосредственно предшествовать соответствующей ему команде вывода поля/подполя.
суффикс-литералы:
3. Один и только один повторяющийся суффикс-литерал. Если такой литерал есть, то он должен следовать непосредственно за соответствующей ему командой вывода поля/подполя.
4. Один и только один условный суффикс-литерал. Если такой литерал есть, то он должен следовать непосредственно за повторяющимся суффикс-литералом или связанной с ним командой вывода поля/подполя.
5. Суффикс-литералы не должны разделяться запятыми и не должно быть запятой между командами вывода поля/подполя и первым суффикс-литералом, так как запятая обозначает конец суффикс-литералов, связанных с данной командой вывода поля/подполя.
Пустые литералы: (т. е. литералы нулевой длины, такие, например, как "" или ||) вполне допустимы и могут использоваться, например, как префикс-литералы для обеспечения условного вертикального размещения или как суффикс-литералы для временного подавления автоматической пунктуации, которая обеспечивается в режиме данных.
Литералы подвергаются преобразованию в прописные буквы, если расположены после соответствующей команды режима вывода.
Примеры различных типов литералов приведены на рис. 8.
Формат Выходные данные
----------- ------------------------------------------------------------
'MFN: ',mfn(3) MFN: 034
mdl,"Заглавие: " v200 Заглавие: Конструктор Сухой. Люди и
самолеты.
v675 623.746623.746(092) Сухой П.О.
v675|; | 623.746; 623.746(092) Сухой П.О.;
v675+|; | 623.746; 623.746(092) Сухой П.О.
|; |v675 ; 623.746; 623.746(092) Сухой П.О.
|; |+v675 623.746; 623.746(092) Сухой П.О.
"УДК"/v675+|; | УДК
623.746; 623.746(092) Сухой П.О.
|(|v675|)| (623.746)(623.746(092) Сухой П.О.)
"(УДК: ",v675+|; |")" (УДК: 623.746; 623.746(092) Сухой П.О.)
mdl,v210 Военное изд-во; М., 1993.
mdl,v210"" Военное изд-во; М., 1993
Рис. 8
Логические выражения
Логические выражения используются для вычисления истинности одного или более условий. Операндами логического выражения могут быть:
| Выражения отношений: | они сравнивают два значения и определяют, удовлетворяют ли они отношению, например, mfn<10; | ||
| Логические функции: | такие, например, как p(v24), которые возвращают значение "истина" или "ложь" в зависимости от наличия поля, специфицированного в аргументе (см. п. 8.3). |
Выражение отношения позволяет определять находятся ли указанные два значения в соответствующем соотношении или нет. Общий вид выражения отношения следующий:
выражение-1 оператор-отношения выражение-2,
где:
| выражение-1 | числовое или строковое выражение; | ||
| оператор-отношения | может быть одним из следующих:
= равно; <> не равно; < меньше; <= меньше или равно; > больше; >= больше или равно; : содержит (используется только для строковых выражений); | ||
| выражение-2 | выражение того же типа, что и выражение-1, т. е. выражение-1 и выражение-2 должны быть либо оба числовыми, либо оба строковыми. |
Операторы отношений =, <>, <, <=, >, >= имеют обычное значение при их применении к числовым выражениям. При сравнении строковых выражений применяются следующие правила:
1. Кроме оператора "содержит" (:) строки сравниваются в точности в том виде, в каком они есть, т.е. прописные и строчные буквы сравниваются по своим кодам (например, код буквы А будет меньше кода буквы а);
2. Два строковых выражения не считаются равными, если они не имеют одинаковой длины. Если два выражения, представляющие строки различной длины, таковы, что посимвольно совпадают до конца более короткой строки, то считается, что более короткая строка является меньше более длинной строки.
Оператор "содержит" (:) проверяет наличие вхождения строки символов, определенной выражением-2, в другую строку, определенную выражением-1.
При наличии такого вхождения выражение принимает значение истина. Этот оператор является нечувствительным к прописным и строчным буквам: для него соответствующие прописные и строчные буквы одинаковы.
Например, результатом выражения
v10 : 'химия'
будет истина, если поле 10 содержит в качестве своей подстроки строку химия, в противном случае результатом будет ложь. Отметим, что вторым операндом может быть произвольная строка символов, которая не обязательно совпадает со словом. Так, в приведенном выше примере, результат будет истина не только, когда поле 10 содержит слово химия, но и когда поле содержит такие слова, как биохимия, фотохимия и др.
Операнды логических выражений могут объединяться с помощью следующих логических операторов:
|
NNOT |
оператор дает значение истина, когда операнд имеет значение ложь, и значение ложь, когда операнд - истина. Оператор NOT может использоваться только как унарный, т.е. он всегда применяется к логическому выражению, следующему за ним. |
|
AAND |
этот оператор дает значение истина, когда оба операнда истинны. Если хотя бы один из операндов имеет значение ложь, то результатом является ложь. |
|
OOR |
этот оператор выполняет операцию включающего ИЛИ. Результатом является истина, когда один или оба операнда истинны, в противном случае результатом является ложь. |
На рис. 10 приведены примеры логических выражений.
Выражения Значения
---------------------------------- ----------------------
mfn=34 Истина
not mfn=34 Ложь
not (not mfn=34) Истина
v20 = 'люди' Ложь
v200 : 'люди' Истина
v200 : 'ЛЮДИ' Истина
v210^c.6 = 'Военное' Ложь
v210^c.7 = ‘Военное' Истина
(v200 : 'люди') AND (v210^c.7= 'Военное') Истина
Рис. 10
Меню ИНСТРУМЕНТЫ
Меню содержит режимы, служащие для запуска основных инструментальных средств системы:
Редактор РЛ и справочников - запуск редактора, предназначенного для корректировки/создания экранных форм ввода (рабочих листов полей и подполей) и простых (неиерархических) справочников. Подробно данное средство описано в Приложении 8.
Редактор INI-файлов и сценариев поиска - запуск редактора, предназначенного для корректировки/создания INI-файлов и сценариев поиска в БД. Подробно данное средство описано в Приложении 6.
Редактор иерархических справочников - запуск редактора, предназначенного для корректировки/создания иерархических справочников. Подробно данное средство описано в Приложении 3.
Генератор табличных форм - запуск редактора, предназначенного для корректировки/создания табличных выходных форм (в т.ч. указателей). Подробно данное средство описано в Приложении 9.
Меню ОПЦИИ
Меню содержит единственный режим - АВТОМАТИЧЕСКИЙ ОПРОС, который служит для установки интервала времени, определяющего частоту автоматического обновления системных параметров в информационном окне. Интервал может быть установлен в пределах 0 - 60 сек. (см. рис. 5.2.4а). При значении интервала 0 автоматическое обновление параметров не производится.
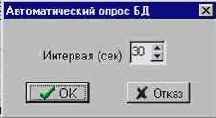
Рис. 5.2.4а. Форма для установки интервала автоматического опроса БД
В соответствии с этим методом формируется элемент из каждой строки, созданной форматом. Этот метод обычно используется для индексирования в целом всего поля или подполя. Однако заметим, что система в данном случае строит элементы все же из строк, а не из полей. В качестве выходного результата форматирования выступает строка символов, в которой нет никакого указания на ее принадлежность (или принадлежность части строки) тому или иному полю или подполю. В связи с этим, надо следить за правильностью формулировки формата, чтобы он порождал правильные данные, особенно когда производится индексация повторяющихся полей и/или более чем одного поля. Другими словами, при использовании данного метода формат выборки данных должен быть таким, чтобы он порождал точно одну строку для каждого индексируемого элемента.
При этом создается элемент из каждого подполя или строки, созданных форматом. Так как в этом случае система будет производить поиск кодов разделителей подполей в строке, созданной форматом, то для обеспечения правильной работы метода в формате должен быть указан режим проверки mpl
(или вообще не указан никакой режим, так как режим проверки выбирается по умолчанию), который обеспечивает сохранность разделителей подполей в выходном результате формата (напомним, что режимы заголовка и данных заменяют разделители подполей на знаки пунктуации). Заметим, что метод индексирования 1 включает в себя метод индексирования 0.
Создается элемент из каждого термина или фразы, заключенных в угловые скобки (<...>). Любой текст, расположенный вне скобок, не индексируется. Заметим, что данный метод требует, чтобы в формате указывался режим проверки, так как любой другой режим удаляет угловые скобки. Например, текст
<Отчет> по использованию <информатики> и <программирования> в <средней школе>
приведет к порождению следующих элементов:
отчет
информатики
программирования
средней школе
Создается элемент из каждого термина или фразы, заключенных в косые черты (/.../). Во всем остальном он работает точно так же, как и метод индексирования 2. Например, текст
/Отчет/ по использованию /информатики/ и /программирования/ в /средней школе/
приведет к порождению следующих элементов:
отчет
информатики
программирования
средней школе
Создается элемент из каждого слова в тексте, созданном форматом. Словом является непрерывная последовательность алфавитных символов Алфавитные символы определяются с помощью системной таблицы ISISACW.TAB.
При использовании этого метода можно предотвратить индексацию по некоторым незначащим словам, определив их в специальном файле, получившем название файла стоп-слов (файл с расширением STW в директории БД).
При использовании данного метода для индексации поля, содержащего разделители подполей, в формате выборки данных необходимо указать режимы заголовка или данных (mhl или mdl) с тем, чтобы замена разделителей подполей произошла до индексации, так как в противном случае буква разделителя подполей будет рассматриваться как составная часть слова.
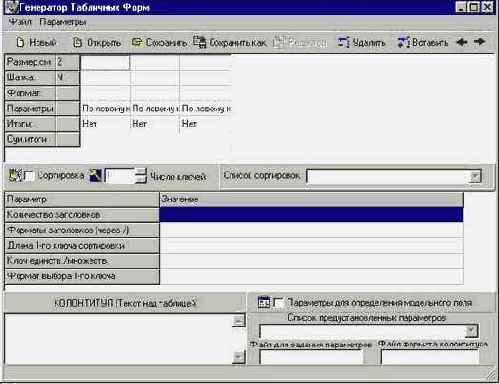
Методика создания табличных форм
Интерфейс Генератора табличных форм разделен по вертикали на три независимые области:
- верхняя - служит для описания собственно таблицы;
- средняя - служит для описания сортировки (если она применяется);
- нижняя - служит для описания параметров и заголовков над таблицей.
В пункте "Параметры" главного меню определяются вид нумерации и формат бумаги.
В верхней области находится образ создаваемой таблицы. Здесь задаются размеры колонок (в см), названия колонок, форматы выбора данных, параметры колонок и итоги.
На панели инструментов (под главным меню) есть кнопки удаления/добавления колонок (перед выделенной) и кнопки "стрелки" удаления/добавления крайних колонок.
Заголовки колонок можно ввести непосредственно в соответствующие ячейки или через оконный редактор, который активизируется по двойному щелчку мыши на выделенной ячейке 2 строки таблицы.
Форматы выбора данных можно вводить непосредственно в ячейку 3-й строки таблицы или через оконный редактор (активизируется двойным щелчком мыши), или путем выбора из списка предустановленных форматов. Список предустановленных форматов находится в файле fmtlist.mnu. Пользователь имеет возможность изменять и дополнять его.
Параметры колонки (выравнивание) задается в 4-й строке таблицы.
Колонки, по которым подсчитываются итоги, задаются в 5-й строке таблицы. Результаты итогов, которые выводятся в нижней части таблицы, задаются в 6-й строке в виде формата, в котором используются условные поля - Vi, где i - номер колонки с итогами, считая слева направо только колонки, в 5-й строке которых стоит - 'ДА'. Например, если в таблице 6 колонок и по 3 и 5 подводятся итоги, то формат итогов может быть такой - 'ИТОГО: 'V1,' 'V2 где V1 - итог по 3 колонке, V2 - итог по 5 колонке.
В первой колонке по умолчанию задается сквозная нумерация документов в таблице. Вид нумерации можно выбрать через пункт "Параметры" главного меню.
В средней области интерфейса задаются ключи сортировки. Таблица для задания ключей активизируется индикатором "СОРТИРОВКА".
Сортировка может быть задана с помощью меню "СПИСОК СОРТИРОВОК". Список предустановленных сортировок находится в файле sortlist.mnu - пользователь имеет возможность вести его самостоятельно. Для добавления в список нового вида сортировки необходимо добавить в файл sortlist.mnu две строки:
@<имя_файла_сортировки> с расширением .SRW
название сортировки
Ключи сортировки могут указываться и непосредственно с помощью соответствующей таблицы в средней области интерфейса. Количество ключей сортировки определяется с помощью числового индикатора "ЧИСЛО КЛЮЧЕЙ". Для описания каждого ключа сортировки служат три параметра: длина ключа, режим сортировки и формат выбора. Поддерживаются два режима сортировки: "единственный ключ" и "множественный ключ". В режиме "единственный ключ" только первая строка (если она есть) результата форматирования становится ключом сортировки. В режиме "множественный ключ" каждая строка результата форматирования становится ключом сортировки. Форматы заголовков (имеющих отношение к сортировке) задаются в виде форматов, в которых используются условные поля - Vi, где i - номер ключа сортировки. Форматы заголовков (если их больше одного) указываются через разделитель "/".
В нижней области интерфейса задаются колонтитул (слева в окне редактора) и дополнительные параметры.
Дополнительными параметрами являются:
· Формат определения добавочного колонтитула – имя файла .PFT
· Инструмент ввода значения, которое доступно во всех применяемых при печати форматах как 991 поле (v991) – имя файла .WSS (см. Приложение 8)
Чтобы задать дополнительные параметры, нужно отметить индикатор "ПАРАМЕТРЫ ДЛЯ ОПРЕДЕЛЕНИЯ МОДЕЛЬНОГО ПОЛЯ". Эти параметры (имена файлов) записываются в выходной файл с расширением HDR. Они также могут быть выбраны из предустановленного списка, который содержится в файле HDRRLIST.MNU.
Методы индексирования
Метод индексирования определяет специфическую обработку данных, созданных форматом. Имеется девять методов индексирования. Они идентифицируются числовыми кодами от 0 до 8. Описание методов индексирования приведено ниже.
Методы индексирования 5, 6, 7 и 8
аналогичны соответственно методам 1, 2, 3, 4
за исключением того, что они дополнительно предоставляют возможность присоединять к индексируемым терминам префиксы. Присоединяемый префикс определяется в формате выборки данных в виде безусловного литерала и имеет следующий вид:
'dp...pd', [format]
где:
|
Вd |
выбранный по усмотрению пользователя ограничитель (который не попадает в текст префикса; |
|
Pp..p |
собственно префикс. |
1 8 '/К=/',v200^a
приведет к индексированию каждого слова подполя А поля 200 с предварительным присоединением к каждому термину префикса "К=".
Эти методы широко применяются в системе ИРБИС для определения принадлежности терминов к определенным элементам описания. Именно на основе этих методов создается модель словарей по различным элементам данных ("Авторы", "Заглавие" и т.д.) При этом при показе словарей соответствующие префиксы опускаются.
Назначение
Система автоматизации библиотек ИРБИС представляет собой типовое интегрированное решение для автоматизации библиотечных технологий и предназначена для использования в условиях библиотек любого типа и профиля.
Назначение и общая характеристика пользовательского интерфейса
АРМ "Администратор" представляет собой рабочее место специалиста, выполняющего операции над базами данных системы в целом в целях поддержания их актуального состояния и сохранности.
Необходимо отметить, что АРМ "Администратор" содержит режимы работы, связанные с существенными преобразованиями баз данных, вплоть до их полного опустошения и удаления, поэтому к работе с данным АРМом должен допускаться только ответственный и подготовленный работник, знакомый с настоящим описанием, а также всеми другими документами по системе.
Пользовательский интерфейс АРМа "Администратор" состоит из главного меню, служащего для запуска тех или иных режимов работы (которые носят исключительно пакетный характер), информационного окна, в котором представляются основные параметры текущей базы данных, и таблицы, содержащей сведения о текущих пользователях системы (см. рис. 5.1а).
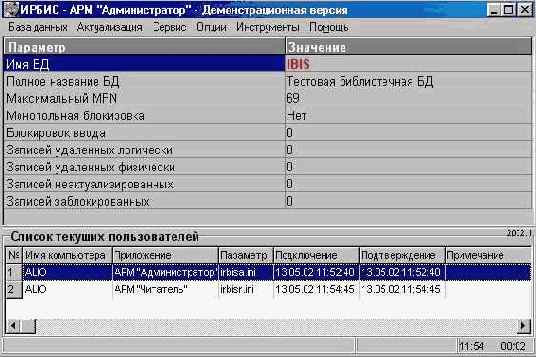
Рис. 5.1а. Общий вид интерфейса АРМа "Администратор"
Все основные режимы работы (включенные в главное меню) адресуются к текущей базе данных. Если ни одна из доступных баз данных не установлена в качестве текущей, все основные режимы работы (кроме выполнения пакетных заданий и вызова инструментальных средств) остаются недоступными.
Назначение и основные характеристики
АРМ "Читатель" представляет собой автоматизированное рабочее место конечного пользователя Электронного каталога библиотеки и предназначен для обеспечения доступа к базам данных Электронного каталога с целью поиска необходимой литературы (информации) и формирования заказа на ее выдачу.
В условиях ЛВС система обеспечивает возможность одновременного поиска в одних и тех же базах данных Электронного каталога произвольного количества пользователей (т.е. АРМов "Читатель").
Можно выделить следующие основные характеристики АРМа "Читатель":
· Комфортный, дружественный интерфейс, рассчитанный на пользователя, который не обладает никакими специальными знаниями;
· Учет различных уровней подготовки пользователя, т.е. один и тот же результат может быть достигнут как путем выполнения последовательности простейших операций, рассчитанных на начинающего пользователя, так и за счет выполнения одной нетривиальной операции, рассчитанной на подготовленного пользователя;
· Наличие широкого спектра поисковых средств, обеспечивающих быстрый (путем прямого доступа через словари) поиск в БД Электронного каталога по всем основным элементам библиографического описания и их сочетаниям;
· Возможность работы с несколькими базами данных, составляющими Электронный каталог;
· Наличие безбумажной технологии формирования заказа на выдачу литературы.
АРМ "Каталогизатор" - представляет собой рабочее место библиотечного работника, выполняющего все функции по формированию (пополнению и корректировке) баз данных Электронного каталога. Кроме того, АРМ "Каталогизатор" используется для формирования и ведения баз данных Читателей, Авторитетных файлов, Алфавитно-предметного.указателя к УДК/ББК и Тезауруса.
В условиях ЛВС система обеспечивает функционирование произвольного количества АРМов "Каталогизатор" с возможностью одновременного пополнения (корректировки) одной базы данных.
Для формирования БД Электронного каталога АРМ "Каталогизатор" предлагает технологию, в которой можно выделить следующие основные характеристики:
·
Структура библиографического описания, основанная на международном стандарте UNIMARC. Имеется возможность - в соответствии с требованиями пользователя - изменения данной структуры (как в сторону упрощения, так и в сторону дополнения);
· Широкий набор рабочих листов (экранных форм), ориентированных на различные виды изданий (включая нетрадиционные) и типы библиографического описания;
· Автоматизированная технология лингвистической обработки (систематизация, предметизация, индексирование) изданий, включающая аппарат тематической навигации по Рубрикатору ГРНТИ, Алфавитно-предметному указателю к УДК/ББК, Авторитетному файлу предметных заголовков и Тезаурусу;
· Оригинальная технология описания периодических изданий (журналов), которая обеспечивает с одной стороны наличие сводного описания издания в целом, включающего сведения о поступлении всех его номеров (томов), и с другой стороны - наличие описания отдельного номера, содержащего сведения о входящих в него статьях;
· Специальная технология копирования данных, исключающая необходимость повторного ввода при создании аналогичных библиографических описаний, - в частности: при обработке многотомных (продолжающихся) изданий;
АРМ "Книговыдача" представляет собой рабочее место библиотечного работника, выполняющего функции по выдаче и возврату литературы. В условиях ЛВС система обеспечивает работу с очередью формируемых заказов на выдачу в режиме реального времени. т.е. заказы, формируемые на АРМах "Читатель", автоматически поступают на АРМ "Книговыдача".
Можно отметить следующие основные характеристики АРМа "Книговыдача":
·
Простая и удобная технология ведения очереди заказов на выдачу литературы и фиксирования их исполнения;
· Наличие оперативной - обновляющейся в режиме реального времени - информации о свободных экземплярах заказанной литературы;
· Наличие оперативной - обновляющейся в режиме реального времени - информации о выданной литературе и читателях, имеющих ее на руках;
· Простая технология фиксирования факта возврата литературы и освобождения соответствующего экземпляра;
· Учет всех сведений о выдаче/возврате литературы в индивидуальных карточках (документах) читателей;
· Возможность получения статистических сведений о функционировании книговыдачи - в частности, о должниках, задолженной литературе и количестве выдач (статистика спроса);
· Специальная ускоренная технология выдачи/возврата, основанная на штрих-кодировании читательских билетов и экземпляров изданий.
Примечание:
Запись читателей, т.е. ведение базы данных читателей (RDR) осуществляется в АРМе "Каталогизатор".
АРМ "Комплектатор" представляет собой автоматизированное рабочее место библиотечного работника, который на основе ведения специальной базы данных выполняет функции по комплектованию и учету фондов библиотеки, а именно:
·
Ввод кратких библиографических данных и данных об издающих и распространяющих организациях для оформления заказов на издания;
· Отслеживание выполнения заказов, контроль невыполненных или недовыполненных заказов;
· Контроль поступления литературы в библиотеку, ввод данных для книги суммарного учета (КСУ) о поступившей партии, получение документов для бухгалтерии;
· Списание книг из фонда с учетом передачи в другие подразделения и докомплектования;
· Автоматическая передача записей в электронный каталог;
· Первичный ввод кратких библиографических данных периодических изданий и данных об адресатах подписки;
· Оформление подписки;
· Использование базы данных каталога периодики и базы данных издательского каталога книг;
· Передача записей в электронный каталог после получения первого номера выписанного издания.
Рис. 6.2а.
Общий вид пользовательского интерфейса АРМа "Комплектатор"
Некоторые особенности, связанные с работой в автоматизированной системе
· знаки препинания, определяющие области и элементы описания, ПЕРЕД элементом данных (ЭД) НЕ СТАВИТЬ;
· при сокращении слов точку в конце элемента данных (ЭД), стоящего последним в области описания, НЕ СТАВИТЬ (в противном случае в формате просмотра точка будет удваиваться);
· после знаков препинания обязательно ставить пробел (они необходимы для верстки при просмотре документа на экране);
· ОБЯЗАТЕЛЬНО использовать вложенные РЛ при появлении соответствующего указания (см. ниже).
Часть данных (поля сложной структуры с подполями — см. п.4.2 и книгу “ИРБИС Приложение”) вводится через вложенные рабочие листы — о наличии такого РЛ свидетельствует кнопка расширенных средств ввода, появляющаяся при “активизации поля” (когда курсор стоит на поле и оно выделено цветом); при нажатии кнопки с тремя точками "…" (или клавиши <F2>) на экране появляется перечень всех возможных для этого поля ЭД; обязательного заполнения всех ЭД в поле не требуется.
Примечание: В основном РЛ введенная информация представлена в виде подполей с разделителями (символ “^” и буква, которые выделены цветом). Эти служебные символы, необходимые для правильной работы системы, вводятся автоматически ПРИ ВЫХОДЕ ИЗ ВЛОЖЕННОГО РЛ; поэтому НЕОБХОДИМО вводить данные с его использованием там, где появляется кнопка расширенных средств ввода с тремя точками "…". Если пользователь начинает вводить данные без нажатия кнопки (или клавиши <F2>), вложенный РЛ открывается автоматически, но первым ЭД в нем не обязательно окажется тот, который уже введен, что потребует корректировки (переноса) данных. Корректировать данные в поле можно и без вызова вложенного РЛ, обязательно сохраняя разделители подполей.
Часть данных вводится в виде повторяющихся полей простой или сложной (с подполями) структуры (например, сведения о нескольких экземплярах — см.
также книгу “ИРБИС Приложение”); признак повторяемости поля – наличие "1" в столбце "Номер" в РЛ. Каждое появление (повторение) имеет соответствующий номер. Для ввода нового повторения поля нужно щелкнуть по номеру того появления, ЗА которым вы хотите поставить новое.
Ввод данных в повторяющиеся поля можно осуществлять и в другом, табличном, виде. Для вызова этого режима требуется ДВАЖДЫ щелкнуть по тексту нужного поля в столбце "Название элемента" в РЛ. В табличном виде каждое появление поля представляется одной строкой, а все его подполя располагаются по столбцам, имеющим заголовки. Порядок ввода новых повторений поля аналогичен описанному выше, но удаление выделенного курсором появления поля легко осуществляется по кнопке "Удалить повторение поля"; кроме того, можно легко вводить идентичные данные по столбцам – двойной щелчок по выделенному курсором подполю вызывает ввод в него значения из предшествующей строки этого же столбца.
Часть данных (см. п.4.2 и книгу “ИРБИС Приложение”) вводится с использованием меню, или словаря текущей БД Электронного каталога (ЭК), или Авторитетных (Authority) файлов (внешних БД). Когда во вложенном РЛ курсор устанавливается в подполе, для которого предусмотрено использование меню (кодовая информация), или словаря, появляется кнопка расширенных средств ввода; при нажатии этой кнопки или клавиши <F2> на экране появляется соответствующее меню или фрагмент словаря.
При работе с МЕНЮ, подведя курсор к нужному значению, сделайте его текущим (цвет меняется) и нажмите кнопку ВВОД (либо щелкните по нему мышкой ДВАЖДЫ) — информация из меню (код) будет перенесена в РЛ. Во многих меню можно использовать поле "ключ" для быстрого поиска нужного значения. Часть меню имеет древовидную структуру.
При работе со СЛОВАРЕМ, также подведя курсор к нужному значению, сделайте его текущим (щелкните по нему мышкой) и нажмите кнопку ВВОД (либо щелкните по нему мышкой ДВАЖДЫ) — информация из словаря (полный текст) будет перенесена в РЛ (в окне "Ключ" можно задавать начальные буквы интересующего пользователя поискового термина, нажатие кнопки "Полностью" позволяет просмотреть значение термина полностью в том виде, в каком он будет перенесен в документ, и выбрать один из нескольких терминов, начальные значения которых совпадают, а различия видны только при просмотре термина ПОЛНОСТЬЮ).
При работе с АВТОРИТЕТНЫМИ ФАЙЛАМИ, определив нужное значение, отметьте его (щелкните в окне мышкой), по кнопке ВВОД информация будет перенесена в РЛ; в окне "Ключ" можно задавать начальные буквы интересующего пользователя поискового термина для немедленного скроллинга словаря; нажатие кнопки "Полностью" позволяет просмотреть полный текст авторитетной записи в виде пояснительного текста и в виде связанных терминов (связи типа "см." и "см. также"), причем для переноса в документ можно отметить связанный (отсылочный) термин. Кнопка "Отобрано" показывает число отобранных к данному моменту терминов, нажатие этой кнопки дает их список. При работе с неповторяющимся ЭД отметить можно лишь один термин.
ЭД, которые можно вводить с использованием Авторитетных файлов, вводятся в документ через отдельное подполе, в которое ПОСЛЕ переноса данных в соответствующие подполя (для авторов, коллективов, предметных рубрик) записывается Номер записи в соответствующем Авторитетном файле.
Примечание: ИРБИС предоставляет пользователю лишь средства создания, ведения, приема (импорта) и использования готовых БД Авторитетных записей, но не сами БД.
При вводе однотипных данных можно использовать режим "МУЛЬТИВВОДА" (Групповой обработки), позволяющий при одном обращении к МЕНЮ или СЛОВАРЮ, или к Авторитетному файлу отметить и перенести в РЛ сразу нужное число терминов. В этом случае при работе со словарем или меню, или авторитетным файлом, подводя курсор к каждому из нужных значений, делайте отметки в соответствующем окошке и, завершив отбор, нажмите кнопку ВВОД.
При мультивводе в НЕПОВТОРЯЮЩЕЕСЯ поле (например, ввод через словарь ЭД "Cведения об ответственности") между перенесенными однотипными данными автоматически проставляются разделительные знаки.
При использовании МУЛЬТИВВОДа в ПОВТОРЯЮЩИЕСЯ поля необходимо перейти в режим табличного ввода (дважды щелкнуть мышкой по тексту нужного поля в столбце "Название элемента", а затем дважды щелкнуть по "НАИМЕНОВАНИЮ" столбца таблицы соответствующего элемента (ввод через меню или словарь); на каждое из перенесенных однотипных данных будет создано отдельное повторение поля, которое нужно дополнить другими ЭД.
Все эти средства упрощают ввод, снижают вероятность возникновения ошибок, а также обеспечивают корректность возможных впоследствии различных преобразований или корректировки ЭД.
Область библиографического описания (Основное БО)
Данные общей части сводного описания тома многотомного издания
| ЭД: | Заголовок описания (1-й автор, Признак: инвертирование ФИО допустимо? КА или ВКА, Сокращение коллектива по ГОСТ). Заглавие. Сведения, относящиеся к заглавию. Сведения об ответственности. Выходные данные (город, издательство, годы начала и окончания издания). ISBN. ISSN. Сведения об издании. Роль (ДК на заглавие? и Признак "Нехарактерное заглавие"). |
Продолжение — Дополнительные данные общей части сводного описания тома многотомного издания
| ЭД: | Разночтение заглавия. (Наименование и тип разночтения, например, Загл. обл.). Параллельные заглавия. Примечание. Серия, в которую входит многотомное издание (Заглавие и Номер в серии. Роль (ДК на заглавие?)). Предыдущее заглавие издания (Заглавие. Год переименования. ISSN. КА. Шифр. Роль (ДК на заглавие?)) |
В этих полях (для сводного БО тома) вводятся сведения об общей части многотомного издания. В заголовок сводного БО тома может быть введен 1-й автор (если авторов не более 3-х), КА или ВКА. Автора, сведения об ответственности (лица), заглавие издания, заглавие серии, предыдущее заглавие, наименование издательства, КА и ВКА можно вводить с использованием словарей.
ЭД "Сведения об ответственности" заполняется по общим правилам (по числу авторов), вторые и последующие сведения об ответственности отделяются символом ";".
Возможны 3 способа заполнения ЭД "Сведения об ответственности":
· простой ввод с клавиатуры;
· с использованием режима мультиввода для неповторяющегося ЭД: отобранные за одно обращение к словарю ФИО автоматически инвертируются (инициалы, а при их отсутствии – полное имя, ставятся перед фамилией, если нет указания о запрете инверсии в ЭД "Роль: инвертирование ФИО допустимо?") и разделяются запятыми;
· если ЭД "Сведения об ответственности" не заполнен, то при сохранении документа он будет формироваться автоматически из введенных данных о заголовке описания, об авторах, лицах и коллективах с вторичной ответственностью (см.
выше п.4.2.2 поле "Авторы, редакторы …, КА, ВКА — из общей части БО");
При этом:
· выполняется инвертирование ФИО ( изменение порядка вывода текста до и после пробела), если нет указания о запрете инверсии (ЭД "Роль: инвертирование ФИО допустимо?");
· при отсутствии Автора — заголовка описания и наличии более 4-х "других" авторов записываются три первые из них и формируется константа "и др." или "et al." — в соответствии с графикой введенного кода языка основного текста (1-е значение).
Примечание:
Если ЭД "Автор – заголовок описания" введен, то число "других" авторов не анализируется, и они вводятся все;
· вводятся КА и ВКА (соответственно, в сокращенном или полном виде), которые отделяются от предыдущих данных и между собой разделяются точкой с запятой.
Если ЭД "Сведения об ответственности" заполнен (при вводе нового документа, или при конвертировании, или в записях, накопленных при работе в более ранних версиях ИРБИСа), то при сохранении документа проводится анализ его наполнения; при этом если 1-й автор — заголовок описания в нем отсутствует, он будет автоматически дополнительно введен, так же, как и второй автор (из документов, введенных в более ранних версиях).
Примечание: Введенные через словарь или автоматически сформированные данные могут быть откорректированы пользователем (например, ввод текста типа "Редкол. в сост. …", изменение падежей фамилий и др.).
При использовании словаря вместе с издательством переносится также и город (или города), а вместе с предыдущим заглавием издания переносятся также и другие данные о нем (ISSN, год изменения, шифр, сведения об ответственности) – естественно, при их наличии в соответствующей записи, ранее введенной в БД ЭК.
Поле данных сводного описания многотомного издания может повторяться в следующих случаях:
· для нескольких издательств ( в соответствующие повторения полей записываются наименования второго и последующих издательств и их города; несколько городов одного издательства могут быть введены с использованием меню в режиме мультиввода в неповторяющееся подполе (автоматически разделяются знаком ";"));
· для нескольких серий (в которые входит описываемое многотомное издание);
· для нескольких параллельных заглавий (несколько параллельных заглавий можно ввести и в одно повторение поля, разделяя их знаком " =.").
Заглавие многотомного издания (вместе с номером тома) и заглавие серии включаются в поисковый словарь заглавий, а отдельные слова из них — в словарь ключевых слов; Если введен признак нехарактерного общего заглавия (например, для "Собраний сочинений"), автор — заголовок описания учитывается в алгоритме сверки на дублетность и вместе с заглавием выводится в словарь.
Наименования коллективных авторов выводятся в словарь коллективов, а отдельные слова из них — в словарь ключевых слов; индивидуальные авторы — в словарь авторов, наименование издательства – в словарь издающих организаций.
Для изданий, описываемых "под заглавием", при необходимости может быть введена специальная разметка текста (см. п.4.1.1)
Заглавие и сведения об ответственности
|
ЭД: |
Заглавие. Сведения, относящиеся к заглавию. Сведения об ответственности (первые и последующие). Номер тома. Роль (ДК на заглавие? и Признак "Нехарактерное заглавие") |
(обязательно).
Повторяющиеся данные внутри ЭД "Сведения, относящиеся к заглавию" нужно разделять символом ":", но ПЕРЕД ним разделительный знак не ставится.
Возможны 3 способа заполнения ЭД "Сведения об ответственности" ("Первые сведения" — имена лиц, "Последующие сведения" — коллективы):
· простой ввод с клавиатуры;
· с использованием режима мультиввода для неповторяющегося ЭД: отобранные за одно обращение к словарю авторов ФИО (авторов, редакторов и других лиц) автоматически инвертируются (инициалы, а при их отсутствии – полное имя, ставятся перед фамилией, если нет указания о запрете инверсии в ЭД "Роль: инвертирование ФИО допустимо?") и разделяются запятыми; отобранные за одно обращение к словарю КА и ВКА разделяются точкой с запятой;
· если один или оба ЭД из "Сведений об ответственности" не заполнен, то при сохранении документа они будут формироваться автоматически из введенных данных о заголовке описания, об авторах, лицах и коллективах с вторичной ответственностью (см. выше п.4.2.2 — поля авторов, редакторов, коллективов, не входящих в заголовок описания).
При этом:
· выполняется инвертирование ФИО (изменение порядка вывода текста до и после пробела), если нет указания о запрете инверсии (ЭД "Роль: инвертирование ФИО допустимо?");
· при отсутствии Автора — заголовка описания и наличии более 4-х "других" авторов записываются три первые из них и формируется константа "и др." или "et al." — в соответствии с графикой введенного кода языка основного текста (1-е значение).
Примечание:
Если ЭД "Автор – заголовок описания" введен, то число "других" авторов не анализируется, и они вводятся все;
· если введены данные только для ЭД "Последующие сведения об ответственности" (т.е. введены только коллективы), то данные о коллективной ответственности автоматически переносятся в ЭД "Первые сведения об ответственности".
Если ЭД "Сведения об ответственности" заполнен (при вводе нового документа, или при конвертировании, или в записях, накопленных при работе в более ранних версиях ИРБИСа), то при сохранении документа проводится анализ его наполнения; при этом если 1-й автор — заголовок описания в нем отсутствует, он будет автоматически дополнительно введен, так же, как и второй автор (из документов, введенных в более ранних версиях).
Примечание: Для Сборника без общего заглавия автоматическое формирование ЭД "Сведения об ответственности" не выполняется, если заполнено поле "2-я и последующие статьи сборника". Поэтому для обеспечения представления данных в выходных форматах в соответствии с требованиями ГОСТ 7.1-84 для этого вида издания в некоторых случаях каталогизатору придется манипулировать последовательностью ввода и сохранения данных, например, сохранить документ и сформировать сведения об ответственности, относящиеся к изданию в целом, до заполнения поля о статьях сборника. В принципе промежуточные сохранения рекомендуется выполнять периодически, чтобы не потерять введенные данные при возникновении аварийной ситуации.
Введенные через словарь или автоматически сформированные данные могут быть откорректированы пользователем (например, ввод текста типа "Редкол. в сост. ….", изменение падежей фамилий и др.).
Для заглавия книги можно определить требование на подготовку Добавочной каталожной карточки на заглавие (ЭД "роль", ввод через меню).
Заглавие включается в поисковый словарь заглавий, а отдельные слова из него - в словарь ключевых слов. Для частного заглавия тома, нужно указать признак нехарактерности его (например, заглавия отдельных томов словаря, имеющего алфавитное деление); в этом случае нехарактерное заглавие будет включаться в словарь заглавий не самостоятельно, а вместе с общим заглавием многотомного издания, например, "Словарь…т.1. А — В" (ЭД "роль", ввод через меню).
При вводе БО автореферата или диссертации ЭД "Сведения, относящиеся к заглавию" может быть сформирован автоматически при сохранении документа на основе информации, введенной в поле "Примечание о диссертации" и уточненного кода "Характер документа" (автореферат или диссертация).
Для изданий, описываемых "под заглавием", при необходимости может быть введена специальная разметка текста (см. п.4.1.1)
Выпуск, часть (номер — заглавие)
|
ЭД: |
Выпуск (номер и заглавие), Часть (номер и заглавие), Роль (характер заглавия) |
В данном поле указываются сведения о 2-й (выпуск) и 3-й (часть) единицах деления, в то время, как сведения о номере 1-й (том) единицы деления указываются в поле "Заглавие" (если дается сводное описание тома) или в поле "Серия" (если дается монографическое описание) — номер тома в многотомном издании. Заглавия включаются в поисковый словарь заглавий, а отдельные слова из них — в словарь ключевых слов. ЭД "роль" (ввод через меню) вводится для нехарактерного заглавия выпуска/части, которое будет включаться в словарь заглавий не самостоятельно, а вместе с общим.
Вторая и третья статьи сборника
|
ЭД: |
Заглавие. Параллельные заглавия (до 3-х). Сведения, относящиеся к заглавию. 1,2,3-й авторы. Сведения об ответственности. Часть/раздел (номер и заглавие). Подраздел (номер и заглавие). Роль (инвертировать авторов). Признак произведения тех же авторов. |
В данном поле ЭД "Автор" (до 3-х авторов каждой статьи), включает фамилию и (через один пробел) инициалы или полное имя (после фамилии должны стоять запятая и пробел); всех авторов можно вводить с использованием словаря либо в режиме мультиввода, либо индивидуально. ЭД "роль" (ввод через меню) относится ко всем авторам и определяет, можно ли инвертировать (менять местами) в каталожных карточках и в форматах просмотра части введенного ФИО, стоящие до и после пробела (в частности, для иностранных изданий часто такой инверсии не требуется); по умолчанию (то есть при незаполненном поле) инверсия выполняется.
Если в сборнике помещено несколько произведений одного автора, то этого автора можно указать лишь для последнего из его произведений, а для остальных сделать ссылки (ЭД "Признак произведения тех же авторов" — ввод через меню) на то, что автор данного произведения (статьи) указан в одном из последующих повторений поля; сведения, относящиеся к заглавию (общие для всех статей) также можно ввести один раз вместе с автором.
Если в сборнике помещено несколько произведений первого автора, который выводится в заголовок описания, то он должен быть повторен, как автор статьи, в последней из его работ (по общим правилам) с указанием отсылок во всех предыдущих статьях.
Если в сборнике помещено два произведения первого автора, который выводится в заголовок описания, то он должен быть повторен, как автор второй статьи (в первом повторении поля).
Если в сборнике помещено только одно произведение первого автора, который выводится в заголовок описания, но к нему имеются дополнительные данные (параллельные заглавия, сведения, относящиеся к заглавию и др.), относящиеся не ко всему сборнику, а именно к первой статье, то все эти частные данные нужно вводить в первое повторение поля и повторно ввести в него и автора.
Для получения корректных Добавочных каталожных карточек (на статью, автор которой задан ссылкой) в этих ссылках нужно указать также номер повторения поля, в котором этот автор (или авторы) указан.
ЭД "Сведения об ответственности" так же, как и для других типов заглавий, могут быть сформированы автоматически при сохранении документа на основе введенных авторов (с учетом признака допустимости инвертирования ФИО), либо введены с клавиатуры, либо введены через словарь в режиме мультиввода (все лица за одно обращение к словарю); при необходимости можно откорректировать введенные автоматически или через словарь данные – изменить падежи, добавить сведения о функциях (ред., переводчик и т.п.). Если сведения о редакторах и других лицах с вторичной ответственностью ввести через словарь, то при сохранении документа введенные данные будут дополнены: перед ними будут включены сведения об авторах, введенные ранее в отдельных подполях.
Если необходимо обеспечить включение в поисковый словарь имен редакторов, переводчиков и других лиц с вторичной ответственностью, относящихся к статьям (что в данном поле не предусмотрено), можно поступить следующим образом:
· ввести данные о 2-й и других статьях, как описано выше; при этом сведения о лицах с вторичной ответственностью вводятся в ЭД "Сведения об ответственности";
· ПОСЛЕ этого ввести сведения в поле "Редакторы, составители…", относящиеся к изданию в целом, — в этом случае НЕ будет формироваться ЭД "Сведения об ответственности", относящиеся к изданию в целом, что исключит повторный вывод одних и тех же данных в выходных форматах, но обеспечит возможность поиска по этим ЭД.
Примечание: При вводе данных в это поле, они отражаются в окне просмотра только после сохранения документа.
Авторы выводятся в поисковый словарь авторов, заглавия включаются в поисковый словарь заглавий, а отдельные слова из них — в словарь ключевых слов.
Сведения об издании
|
ЭД: |
ОБЛАСТЬ Библиографического Описания (Расширенное БО)Область примечаний В системе выделены следующие поля примечаний: · общие; · примечания о языке (примечание типа "текст параллельно на англ. и фр. яз."); · о наличии библиографии и справочного аппарата (с использованием файла меню); · об интеллектуальной ответственности (примечание типа "авторы указаны на обороте титульного листа"); · об электронном ресурсе (режим доступа, источник основного заглавия, о библиографической истории, о датах, другие примечания); · о диссертации. Примечание о диссертации
Код номенклатуры специальности (до трех значений) вводится с использованием меню и включается в поисковый словарь. Если данное поле заполнено, а ЭД "Сведения, относящиеся к заглавию" отсутствует, то при сохранении документа он будет формироваться с учетом значения ЭД "Код характера документа" (автореферат или диссертация). Следующие примечания, вынесены на отдельную страницу (закладку) РЛ "Редкие": · о наличии автографов (все ЭД, которыми описывается "Автор", за исключением сведений о месте его работы); данные могут быть введены с использованием словаря БД ЭК или Авторитетного файла; сведения о наличии автографа включаются в словарь авторов с пометой "\автограф\" и в отдельный словарь автографов (имен); · о наличии экслибриса (свободный текст), может быть подключено меню с часто встречающимися вариантами текстов; · о наличии пометок автора (свободный текст); · о наличии пометок владельца коллекции (свободный текст); · о состоянии (сохранности) книги или каталогизируемого предмета (свободный текст); · о технике изготовления книги или каталогизируемого предмета (свободный текст); · о приплетенных изданиях (конволют или аллигат). Признаки наличия всех этих данных включаются в словарь "Редкие книги" в виде кодов; сведения об автографах и приплетенных изданиях — дополнительно и в общие словари авторов, заглавий, ключевых слов и др. Приплетенные издания
Поле повторяющееся, каждое повторение содержит данные об одном издании, вышедшем самостоятельно, а позже объединенном с другими изданиями по разным признакам (тематика, авторство и др.). При вводе данных в это поле используются все методы, описанные выше для аналогичных ЭД в других полях, и соблюдаются те же принципы: · Авторы (фамилия, инициалы или полное имя) могут быть введены за одно обращение к словарю (мультиввод в отдельные подполя); при вводе с клавиатуры соблюдается правило, по которому инициалы отделяются от фамилии пробелом, а полное имя отделяется от фамилии запятой и пробелом; · В ЭД "Сведения об ответственности" редакторы и другие лица могут быть также введены за одно обращение к словарю (мультиввод в одно подполе, отдельные ФИО разделяются точкой с запятой). При сохранении документа перед введенными данными будут дополнительно введены сведения об авторах (с учетом указания о допустимости инвертирования ФИО, относящегося ко всем авторам). Введенные через словарь или автоматически сформированные данные могут быть откорректированы (например, введены данные типа "Редкол.:", изменены падежи фамилий, полные имена заменены инициалами и др.); · Издательство (вместе с городом) может быть введено через словарь; город (или несколько городов одного издательства) могут быть введены за одно обращение к меню (разделяются точкой с запятой); · сведения об иллюстрациях вводятся через меню (только одно значение); · при вводе ЭД "Объем" (число страниц) предполагается, что приплетенные издания относятся только к традиционным печатным изданиям, и в выходных документах наименование единицы измерения без анализа введенных данных берется из ORG.MNU (для кода "4" по умолчанию установлено значение "с"); · Если каталогизируемый документ является томом многотомного издания (РЛ SPEC), вводятся дополнительные ЭД: · если приплетенным является еще один том того же издания, вводится "Признак общего заглавия многотомника"; в этом случае в ЭД "Заглавие" нужно вводить заглавие тома, а также может быть введен "Признак нехарактерного заглавия тома" - указание на то, что заглавие тома нужно выводить в словарь не самостоятельно, а вместе с общим заглавием; · если приплетенным является том другого издания, в ЭД "Заглавие" вводится общее заглавие и заглавие тома; · Обозначение и номер тома. Авторы приплетенных изданий выводятся в словарь авторов, издательства (вместе с городом) – в словарь издающих организаций, заглавия – в словарь заглавий, а отдельные слова из них – в словарь ключевых слов. Самостоятельное приложение
Основной документ, к которому относится приложение
Основной документ или самостоятельное приложение к нему можно быстро найти в режиме "Поиск по связи", если найдено одно из них. Область серии
Если на том многотомника, имеющего частное заглавие, вводится СВОДНОЕ описание, в поле "Серия" вводятся только сведения о сериях, в которые входит отдельный описываемый том, и номер тома в них (в этом случае заглавие общей части и сведения о сериях, в которые входит издание в целом, введено в отдельном поле, а номер тома введен в поле "Заглавие"). ЭД "Наименование" можно вводить с использованием словаря (отдельный словарь заглавий серий вместе со сведениями об ответственности). При монографическом описании тома каталогизатор может решить, нужно ли выводить сведения о серии в область серии БО, а также задать требование на подготовку Добавочной каталожной карточки на серию (ЭД "роль", ввод через меню). В любом случае наименование каждой серии включается вместе со сведениями об ответственности как в отдельный словарь, так и в общий поисковый словарь заглавий, а отдельные слова из них – в словарь ключевых слов. Параллельные заглавия
Транслитерированное заглавие
|