Абстрагирование
Аппарат абстракции — удобный инструмент для борьбы со сложностью реальных систем. Создавая понятие в интересах какой-либо задачи, мы отвлекаемся (абстрагируемся) от несущественных характеристик конкретных объектов, определяя только существенные характеристики. Например, в абстракции «часы» мы выделяем характеристику «показывать время», отвлекаясь от таких характеристик конкретных часов, как форма, цвет, материал, цена, изготовитель.
Итак, абстрагирование сводится к формированию абстракций. Каждая абстракция фиксирует основные характеристики объекта, которые отличают его от других видов объектов и обеспечивают ясные понятийные границы.
Абстракция концентрирует внимание на внешнем представлении объекта, позволяет отделить основное в поведении объекта.от его реализации. Абстракцию удобно строить путем выделения обязанностей объекта.
Пример: физический объект — датчик скорости, устанавливаемый на борту летательного аппарата (ЛА). Создадим его абстракцию. Для этого сформулируем обязанности датчика:
q знать проекцию скорости ЛА в заданном направлении;
q показывать текущую скорость;
q подвергаться настройке.
Теперь опишем абстракцию датчика. Описание сформулируем как спецификацию класса на языке Ada 95 [4]:
Package Класс_ДатчикСкорости is
subtype Скорость is Float range ...
subtype Направление is Natural range ...
type ДатчикСкорости is tagged private;
function НовыйДатчик(нокер: Направление)
return ДатчикСкорости:
function ТекущаяСкорость (the: ДатчикСкорости)
return Скорость;
procedure Настраивать(the: in out ДатчикСкорости;
ДействитСкорость: Скорость);
private — закрытая часть спецификации
-- полное описание типа ДатчикСкорости
end Класс_ДатчикСкорости;
Здесь Скорость и Направление — вспомогательные подтипы, обеспечивающие задание операций абстракции (НовыйДатчик, ТекущаяСкорость, Настраивать). Приведенная абстракция — это только спецификация класса датчика, настоящее его представление скрыто в приватной части спецификации и теле класса. Класс ДэтчикСкорости — еще не объект. Собственно датчики — это его экземпляры, и их нужно создать, прежде чем с ними можно будет работать. Например, можно написать так:
ДатчикПродольнойСкорости : ДатчикСкорости;
ДатчикПоперечнойСкорости : ДатчикСкорости;
ДатчикНормальнойСкорости : ДатчикСкорости;
Абстракция
Абстракция — это механизм, который позволяет проектировщику выделять главное в программном компоненте (как свойства, так и операции) без учета второстепенных деталей. По мере перемещения на более высокие уровни абстракции мы игнорируем все большее количество деталей, обеспечивая все более общее представление понятия или элемента. По мере перемещения на более низкие уровни абстракции мы вводим все большее количество деталей, обеспечивая более удачное представление понятия или элемента.
Класс — это абстракция, которая может быть представлена на различных уровнях детализации и различными способами (например, как список операций, последовательность состояний, последовательности взаимодействий). Поэтому объектно-ориентированные метрики должны представлять абстракции в терминах измерений класса. Примеры: количество экземпляров класса в приложении, количество родовых классов на приложение, отношение количества родовых к количеству неродовых классов.
Агрегация
Связи обозначают равноправные (клиент-серверные) отношения между объектами. Агрегация обозначает отношения объектов в иерархии «целое/часть». Агрегация обеспечивает возможность перемещения от целого (агрегата) к его частям (свойствам).
В примере из подраздела «Связи» объект РабочийКонтроллер имеет свойство регулятор, чьим классом является РегуляторУгла. Поэтому объект РабочийКонтроллер является агрегатом (целым), а экземпляр РегулятораУгла — одной из его частей. Из РабочегоКонтроллера всегда можно попасть в его регулятор. Обратный же переход (из части в целое) обеспечивается не всегда.
Агрегация может обозначать, а может и не обозначать физическое включение части в целое. На рис. 9.7 приведен пример физического включения (композиции) частей (Двигателя, Сидений, Колес) в агрегат Автомобиль. В этом случае говорят, что части включены в агрегат по величине.

Рис. 9.7. Физическое включение частей в агрегат
На рис. 9.8 приведен пример нефизического включения частей (Студента, Преподавателя) в агрегат Вуз. Очевидно, что Студент и Преподаватель являются элементами Вуза, но они не входят в него физически. В этом случае говорят, что части включены в агрегат по ссылке.

Рис. 9.8. Нефизическое включение частей в агрегат
Итак, между объектами существуют два вида отношений — связи и агрегация. Какое из них выбрать?
При выборе вида отношения должны учитываться следующие факторы:
q связи обеспечивают низкое сцепление между объектами;
q агрегация инкапсулирует части как секреты целого.
Вложенные части демонстрируют свою множественность (мощность, кратность) в правом верхнем углу своего символа. Если метка множественности опущена, по умолчанию считают, что ее значение «много». Вложенный элемент может иметь роль в агрегате. Используется синтаксис
роль : имяКласса.

Рис. 9.14. Агрегация классов

Рис. 9.15. Формы представления композиции
Эта роль соответствует той роли, которую играет часть в неявном (в этой нотации) отношении композиции между частью и целым (агрегатом).
Отметим, что, как представлено в правой части рис. 9.15, в сущности, свойства (атрибуты) класса находятся в отношении композиции между всем классом и его элементами-свойствами. Тем не менее в общем случае свойства должны иметь примитивные значения (числа, строки, даты), а не ссылаться на другие классы, так как в «атрибутной» нотации не видны другие отношения классов-частей. Кроме того, свойства классов не могут находиться в совместном использовании несколькими классами.
Актеры и элементы Use Case
Вершинами в диаграмме Use Case являются актеры и элементы Use Case. Их обозначения показаны на рис. 12.26.
Актеры представляют внешний мир, нуждающийся в работе системы. Элементы Use Case представляют действия, выполняемые системой в интересах актеров.

Рис. 12.26. Обозначения актера и элемента Use Case
Актер — это роль объекта вне системы, который прямо взаимодействует с ее частью — конкретным элементом (элементом Use Case). Различают актеров и пользователей. Пользователь — это физический объект, который использует систему. Он может играть несколько ролей и поэтому может моделироваться несколькими актерами. Справедливо и обратное — актером могут быть разные пользователи.
Например, для коммерческого летательного аппарата можно выделить двух актеров: пилота и кассира. Сидоров — пользователь, который иногда действует как пилот, а иногда — как кассир. Как изображено на рис. 12.27, в зависимости от роли Сидоров взаимодействует с разными элементами Use Case.

Рис. 12.27. Модель Use Case
Элемент Use Case — это описание последовательности действий (или нескольких последовательностей), которые выполняются системой и производят для отдельного актера видимый результат.
Один актер может использовать несколько элементов Use Case, и наоборот, один элемент Use Case может иметь несколько актеров, использующих его. Каждый элемент Use Case задает определенный путь использования системы. Набор всех элементов Use Case определяет полные функциональные возможности системы.
Альтернативные потоки
Е-1: введен неправильный ID-номер покупателя. Покупатель может повторить ввод ID-номера или прекратить элемент Use Case.
Е-2: введены неправильные пункт назначения/дата полета. Покупатель может повторить ввод пункта назначения/даты полета или прекратить элемент Use Case.
Е-3: нет подходящих авиарейсов. Покупатель информируется, что в данное время такой полет невозможен. Возврат к началу элемента Use Case.
Е-4: не может быть создана связь между покупателем и авиарейсом. Информация сохраняется, система создаст эту связь позже. Элемент Use Case продолжается.
Е-5: введен неправильный номер заказа. Покупатель может повторить ввод правильного номера заказа или прекратить элемент Use Case.
Е-6: не может быть удалена связь между покупателем и авиарейсом. Информация сохраняется, система будет удалять эту связь позже. Элемент Use Case продолжается.
Е-7: система не может вывести информацию заказа. Возврат к началу элемента Use Case.
Е-8: некорректные параметры кредитной карты. Покупатель может повторить ввод параметров карты или прекратить элемент Use Case.
Таким образом, в данной спецификации зафиксировано, что внутри элемента Use Case находится один основной поток и двенадцать вспомогательных потоков действий. В дальнейшем разработчик может принять решение о выделении из этого элемента Use Case самостоятельных элементов Use Case. Очевидно, что если самостоятельный элемент Use Case содержит подпоток, то его следует подключать к базовому элементу Use Case отношением include. В свою очередь, самостоятельный элемент Use Case с альтернативным потоком подключается к базовому элементу Use Case отношением extend.
Анализ чувствительности программного проекта
СОСОМО II — авторитетная и многоплановая модель, позволяющая решать самые разнообразные задачи управления программным проектом.
Рассмотрим возможности этой модели в задачах анализа чувствительности — чувствительности программного проекта к изменению условий разработки.
Будем считать, что корпорация «СверхМобильныеСвязи» заказала разработку ПО для встроенной космической системы обработки сообщений. Ожидаемый размер ПО — 10 KLOC, используется серийный микропроцессор. Примем, что масштабные факторы имеют номинальные значения (показатель степени В = 1,16) и что автоматическая генерация кода не предусматривается. К проведению разработки привлекаются главный аналитик и главный программист высокой квалификации, поэтому средняя зарплата в команде составит $ 6000 в месяц. Команда имеет годовой опыт работы с этой проблемной областью и полгода работает с нужной аппаратной платформой.
В терминах СОСОМО II проблемную область (область применения продукта) классифицируют как «операции с приборами» со следующим описанием: встроенная система для высокоскоростного мультиприоритетного обслуживания удаленных линий связи, обеспечивающая возможности диагностики.
Оценку пост-архитектурных факторов затрат для проекта сведем в табл. 2.27.
Из таблицы следует, что увеличение затрат в 1,3 раза из-за очень высокой сложности продукта уравновешивается их уменьшением вследствие высокой квалификации аналитика и программиста, а также активного использования программных утилит.
Таблица 2.27. Оценка пост-архитектурных факторов затрат
| Фактор | Описание | Оценка | Множитель | ||||
| RELY | Требуемая надежность ПО | Номинал. | 1 | ||||
| DATA | Размер базы данных — 20 Кбайт | Низкая | 0,93 | ||||
| CPLX | Сложность продукта | Очень высок. | 1,3 | ||||
| RUSE | Требуемая повторная используемость | Номинал. | 1 | ||||
| DOCU | Документирование жизненного цикла | Номинал. | 1 | ||||
| TIME | Ограничения времени выполнения (70%) | Высокая | 1,11 | ||||
| STOR | Ограничения оперативной памяти (45 из 64 Кбайт, 70%) | Высокая | 1,06 | ||||
| PVOL | Изменчивость платформы (каждые 6 месяцев) | Номинал. | 1 | ||||
| ACAP | Возможности аналитика (75%) | Высокая | 0,83 | ||||
| PCAP | Возможности программиста (75%) | Высокая | 0,87 | ||||
| AEXP | Опыт работы с приложением (1 год) | Номинал. | 1 | ||||
| PEXP | Опыт работы с платформой (6 месяцев) | Низкая | 1,12 | ||||
| LTEX | Опыт работы с языком и утилитами (1 год) | Номинал. | 1 | ||||
| PCON | Непрерывность персонала ( 1 2% в год) | Номинал. | 1 | ||||
| TOOL | Активное использование программных утилит | Высокая | 0,86 | ||||
| SITE | Мультисетевая разработка (телефоны) | Низкая | 1,1 | ||||
| SCED | Требуемый график разработки | Номинал. | 1 | ||||
| Множитель поправки Мр | 1,088 |
Рассчитаем затраты и стоимость проекта:
ЗАТРАТЫ = AхРАЗМЕРBхМр=2,5(10)1,16х1,088=36x1,088= 39[чел.-мес],
СТОИМОСТЬ = ЗАТРАТЫ х $6000 = $234 000.
Таковы стартовые условия программного проекта. А теперь обсудим несколько сценариев возможного развития событий.
Анализ риска
На этой стадии исследуется область неопределенности, имеющаяся в наличии перед созданием программного продукта. Анализируется ее влияние на проект. Нет ли скрытых от внимания трудных технических проблем? Не станут ли изменения, проявившиеся в ходе проектирования, причиной недопустимого отставания по срокам? В результате принимается решение — выполнять проект или нет.
В ходе анализа оценивается вероятность возникновения Рi и величина потери Li для каждого выявленного i-го элемента риска. В результате вычисляется влияние REi i-го элемента риска на проект.
Вероятности определяются с помощью экспертных оценок или на основе статистики, накопленной за предыдущие разработки. Итоги анализа, как показано в табл. 15.1, сводятся в таблицу.
Таблица 15.1. Оценка влияния элементов риска
| Элемент риска | Вероятность, % | Потери | Влияние риска | ||||
| 1. Критическая программная ошибка | 3-5 | 10 | 30-50 | ||||
| 2. Ошибка потери ключевых данных | 3-5 | 8 | 24-40 | ||||
| 3. Отказоустойчивость недопустимо снижает производительность | 4-8 | 7 | 28-56 | ||||
| 4. Отслеживание опасного условия как безопасного | 5 | 9 | 45 | ||||
| 5. Отслеживание безопасного условия как опасного | 5 | 3 | 15 | ||||
| 6. Аппаратные задержки срывают планирование | 6 | 4 | 24 | ||||
| 7. Ошибки преобразования данных приводят к избыточным вычислениям | 8 | 1 | 8 | ||||
| 8. Слабый интерфейс пользователя снижает эффективность работы | 6 | 5 | 30 | ||||
| 9. Дефицит процессорной памяти | 1 | 7 | 7 | ||||
| 10. СУБД теряет данные | 2 | 2 | 4 |
Ассоциации классов
Ассоциация обозначает семантическое соединение классов.
Пример: в системе обслуживания читателей имеются две ключевые абстракции — Книга и Библиотека. Класс Книга играет роль элемента, хранимого в библиотеке. Класс Библиотека играет роль хранилища для книг.

Рис. 9.10. Ассоциация
Отношение ассоциации между классами изображено на рис. 9.10. Очевидно, что ассоциация предполагает двухсторонние отношения:
q для данного экземпляра Книги выделяется экземпляр Библиотеки, обеспечивающий ее хранение;
q для данного экземпляра Библиотеки выделяются все хранимые Книги.
Здесь показана ассоциация один-ко-многим. Каждый экземпляр Книги имеет указатель на экземпляр Библиотеки. Каждый экземпляр Библиотеки имеет набор указателей на несколько экземпляров Книги.
Ассоциация обозначает только семантическую связь. Она не указывает направление и точную реализацию отношения. Ассоциация пригодна для анализа проблемы, когда нам требуется лишь идентифицировать связи. С помощью создания ассоциаций мы приводим к пониманию участников семантических связей, их ролей, мощности (количества элементов).
Ассоциация один-ко-многим, введенная в примере, означает, что для каждого экземпляра класса Библиотека есть 0 или более экземпляров класса Книга, а для каждого экземпляра класса Книга есть один экземпляр Библиотеки. Эту множественность обозначает мощность ассоциации. Мощность ассоциации бывает одного из трех типов:
q один-к-одному;
q один-ко-многим;
q многие-ко-многим.
Примеры ассоциаций с различными типами мощности приведены на рис. 9.11, они имеют следующий смысл:
q у европейской жены один муж, а у европейского мужа одна жена;
q у восточной жены один муж, а у восточного мужа сколько угодно жен;
q у заказа один клиент, а у клиента сколько угодно заказов;
q человек может посещать сколько угодно зданий, а в здании может находиться сколько угодно людей.

Рис. 9.11. Ассоциации с различными типами мощности
Бизнес-модели
Достаточно часто перед тем, как решиться на заказ ПО, организация проводит бизнес-моделирование. Цели бизнес-моделирования:
q отобразить структуру и процессы деятельности организации;
q обеспечить ясное, комплексное и, главное, одинаковое понимание нужд организации как сотрудниками, так и будущими разработчиками ПО;
q сформировать реальные требования к программному обеспечению деятельности организации.
Для достижения этих целей разрабатываются две модели: Q бизнес-модель Use Case; а бизнес-объектная модель.
Бизнес-модель Use Case задает внешнее представление бизнес-процессов организации (с точки зрения внешней среды — клиентов и партнеров).
Как показано на рис. 12.57, бизнес-модель Use Case строится с помощью бизнес-актеров и бизнес-элементов Use Case — простого расширения средств, используемых в обычных диаграммах Use Case.
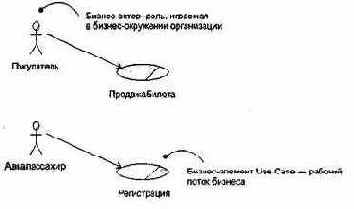
Рис. 12.57. Фрагмент бизнес-модели Use Case для аэропорта
Бизнес-актеры определяют внешние сущности и людей, с которыми взаимодействует бизнес. Бизнес-актер представляет собой человека, но информационная система, взаимодействующая с бизнесом, также может играть роль такого актера.
Бизнес-элементы Use Case изображают различные рабочие потоки бизнеса. Последовательности действий в бизнес-элементах Use Case обычно описываются диаграммами деятельности.
Бизнес-объектная модель отражает внутреннее представление бизнес-процессов организации (с точки зрения ее сотрудников).
Как показано на рис. 12.58, бизнес-объектная модель строится с помощью бизнес-работников и бизнес-сущностей — классов со специальными стереотипами. Эти классы имеют специальные графические обозначения.

Рис. 12.58. Фрагмент бизнес-объектной модели аэропорта
Бизнес-работник — абстракция человека, действующего в бизнесе. Бизнес-сущности являются «предметами», обрабатываемыми или используемыми бизнес-работниками по мере выполнения бизнес-элемента Use Case. Например, бизнес-сущность представляет собой документ или существенную часть продукта. Фактически бизнес-объектная модель отображается с помощью диаграмм классов.
Быстрая разработка приложений
Модель быстрой разработки приложений (Rapid Application Development) — второй пример применения инкрементной стратегии конструирования (рис. 1.5).
RAD-модель обеспечивает экстремально короткий цикл разработки. RAD — высокоскоростная адаптация линейной последовательной модели, в которой быстрая разработка достигается за счет использования компонентно-ориентированного конструирования. Если требования полностью определены, а проектная область ограничена, RAD-процесс позволяет группе создать полностью функциональную систему за очень короткое время (60-90 дней). RAD-подход ориентирован на разработку информационных систем и выделяет следующие этапы:
q бизнес-моделирование. Моделируется информационный поток между бизнес-функциями. Ищется ответ на следующие вопросы: Какая информация руководит бизнес-процессом? Какая генерируется информация? Кто генерирует ее? Где информация применяется? Кто обрабатывает ее?
q моделирование данных. Информационный поток, определенный на этапе бизнес-моделирования, отображается в набор объектов данных, которые требуются для поддержки бизнеса. Идентифицируются характеристики (свойства, атрибуты) каждого объекта, определяются отношения между объектами;
q моделирование обработки. Определяются преобразования объектов данных, обеспечивающие реализацию бизнес-функций. Создаются описания обработки для добавления, модификации, удаления или нахождения (исправления) объектов данных;
q генерация приложения. Предполагается использование методов, ориентированных на языки программирования 4-го поколения. Вместо создания ПО с помощью языков программирования 3-го поколения, RAD-процесс работает с повторно используемыми программными компонентами или создает повторно используемые компоненты. Для обеспечения конструирования используются утилиты автоматизации;
q тестирование и объединение. Поскольку применяются повторно используемые компоненты, многие программные элементы уже протестированы. Это уменьшает время тестирования (хотя все новые элементы должны быть протестированы).

Рис. 1.5. Модель быстрой разработки приложений
Применение RAD возможно в том случае, когда каждая главная функция может быть завершена за 3 месяца. Каждая главная функция адресуется отдельной группе разработчиков, а затем интегрируется в целую систему.
Применение RAD имеет- и свои недостатки, и ограничения.
1. Для больших проектов в RAD требуются существенные людские ресурсы (необходимо создать достаточное количество групп).
2. RAD применима только для таких приложений, которые могут декомпозироваться на отдельные модули и в которых производительность не является критической величиной.
3. RAD не применима в условиях высоких технических рисков (то есть при использовании новой технологии).
Цикломатическая сложность
Цикломатическая сложность — метрика ПО, которая обеспечивает количественную оценку логической сложности программы. В способе тестирования базового пути Цикломатическая сложность определяет:
q количество независимых путей в базовом множестве программы;
q верхнюю оценку количества тестов, которое гарантирует однократное выполнение всех операторов.
Независимым называется любой путь, который вводит новый оператор обработки или новое условие. В терминах потокового графа независимый путь должен содержать дугу, не входящую в ранее определенные пути.
ПРИМЕЧАНИЕ
Путь начинается в начальном узле, а заканчивается в конечном узле графа. Независимые пути формируются в порядке от самого короткого к самому длинному.
Перечислим независимые пути для потокового графа из примера 1:
Путь 1: 1-8.
Путь 2: 1-2-3-7а-7b-1-8.
Путь 3: 1-2-4-5-7а-7b-1-8.
Путь 4: 1-2-4-6-7а-7b-1-8.
Заметим, что каждый новый путь включает новую дугу.
Все независимые пути графа образуют базовое множество.
Свойства базового множества:
1) тесты, обеспечивающие его проверку, гарантируют:
q однократное выполнение каждого оператора;
q выполнение каждого условия по True-ветви и по False-ветви;
2) мощность базового множества равна цикломатической сложности потокового графа.
Значение 2-го свойства трудно переоценить — оно дает априорную оценку количества независимых путей, которое имеет смысл искать в графе.
Цикломатическая сложность вычисляется одним из трех способов:
1) цикломатическая сложность равна количеству регионов потокового графа;
2) цикломатическая сложность определяется по формуле
V(G)-E-N+2,
где Е — количество дуг, N — количество узлов потокового графа;
3) цикломатическая сложность формируется по выражению V(G) =p+ 1, где р — количество предикатных узлов в потоковом графе G.
Вычислим цикломатическую сложность графа из примера 1 каждым из трех способов:
1) потоковый граф имеет 4 региона;
2) V(G) = 11 дуг - 9 узлов + 2 = 4;
3) V(G) = 3 предикатных узла +1=4.
Таким образом, цикломатическая сложность потокового графа из примера 1 равна четырем.
Действия в состояниях
Для указания действий, выполняемых при входе в состояние и при выходе из состояния, используются метки entry и exit соответственно.
Например, как показано на рис. 12.6, при входе в состояние Активна выполняется операция УстановитьТревогу() из класса Контроллер, а при выходе из состояния — операция СбросТревоги().

Рис. 12.6. Входные и выходные действия и деятельность в состоянии Активна
Действие, которое должно выполняться, когда система находится в данном состоянии, указывается после метки do. Считается, что такое действие начинается при входе в состояние и заканчивается при выходе из него. Например, в состоянии Активна это действие ПодтверждатьТревогу().
Декомпозиция подсистем на модули
Известны два типа моделей модульной декомпозиции:
q модель потока данных;
q модель объектов.
В основе модели потока данных лежит разбиение по функциям.
Модель объектов основана на слабо сцепленных сущностях, имеющих собственные наборы данных, состояния и наборы операций.
Очевидно, что выбор типа декомпозиции должен определяться сложностью разбиваемой подсистемы.
Деревья наследования
При использовании отношений обобщения строится иерархия классов. Некоторые классы в этой иерархии могут быть абстрактными. Абстрактным называют класс, который не может иметь экземпляров. Имена абстрактных классов записываются курсивом. Например, на рис. 11.16 показаны абстрактные классы Млекопитающие, Собаки, Кошки.

Рис. 11.16. Абстрактность и полиморфизм
Кроме того, здесь имеются конкретные классы ОхотничьиСобаки, Сеттер, каждый из которых может иметь экземпляры.
Обычно класс наследует какие-то характеристики класса-родителя и передает свои характеристики классу-потомку. Иногда требуется определить конечный класс, который не может иметь детей. Такие классы помечаются теговой величиной (характеристикой) leaf, записываемой за именем класса. Например, на рисунке показан конечный класс Сеттер.
Иногда полезно отметить корневой класс, который не может иметь родителей. Такой класс помечается теговой величиной (характеристикой) root, записываемой за именем класса. Например, на рисунке показан корневой класс Млекопитающие.
Аналогичные свойства имеют и операции. Обычно операция является полиморфной, это значит, что в различных точках иерархии можно определять операции с похожей сигнатурой. Такие операции из дочерних классов переопределяют поведение соответствующих операций из родительских классов. При обработке сообщения (в период выполнения) производится полиморфный выбор одной из операций иерархии в соответствии с типом объекта. Например, ОтображатьВнешнийВид () и ВлезатьНаДерево (дуб) — полиморфные операции. К тому же операция Млекопитающие::ОтображатьВнешнийВид ( ) является абстрактной, то есть неполной и требующей для своей реализации потомка. Имя абстрактной операции записывается курсивом (как и имя класса). С другой стороны, Млекопитающие::УзнатьВес () — конечная операция, что отмечается характеристикой leaf. Это значит, что операция не полиморфна и не может перекрываться.
Диаграмма потоков данных

Рис. 5.6. Отображение в модульную структуру ПС потока действия 1
Шаг 6. Детализация структуры ПС. Производится отображение в структуру каждого потока действия. Каждый поток действия имеет свой тип. Могут встретиться поток-«преобразование» (отображается по предыдущей методике) и поток запросов. На рис. 5.6 приведен пример отображения потока действия 1. Подразумевается, что он является потоком преобразования.
Шаг 7. Уточнение иерархической структуры ПС. Уточнение выполняется для повышения качества системы. Как и при предыдущей методике, критериями уточнения служат: независимость модулей, эффективность реализации и тестирования, улучшение сопровождаемости.
Диаграммы деятельности
Диаграмма деятельности представляет особую форму конечного автомата, в которой показываются процесс вычислений и потоки работ. В ней выделяются не обычные состояния объекта, а состояния выполняемых вычислений — состояния действий. При этом полагается, что процесс вычислений не прерывается внешними событиями. Словом, диаграммы деятельности очень похожи на блок-схемы алгоритмов.
Основной вершиной в диаграмме деятельности является состояние действия (рис. 12.13), которое изображается как прямоугольник с закругленными боковыми сторонами.

Рис. 12.13. Состояние действия
Состояние действия считается атомарным (действие нельзя прервать) и выполняется за один квант времени, его нельзя подвергнуть декомпозиции. Если нужно представить сложное действие, которое можно подвергнуть дальнейшей декомпозиции (разбить на ряд более простых действий), то используют состояние под-деятельности. Изображение состояния под-деятельности содержит пиктограмму в правом нижнем углу (рис. 12.14).

Рис. 12.14. Состояние под-деятельности
Фактически в данную вершину вписывается имя другой диаграммы, имеющей внутреннюю структуру.
Переходы между вершинами — состояниями действий — изображаются в виде стрелок. Переходы выполняются по окончании действий.
Кроме того, в диаграммах деятельности используются вспомогательные вершины:
q решение (ромбик с одной входящей и несколькими исходящими стрелками);
q объединение (ромбик с несколькими входящими и одной исходящей стрелкой);
q линейка синхронизации — разделение (жирная горизонтальная линия с одной входящей и несколькими исходящими стрелками);
q линейка синхронизации — слияние (жирная горизонтальная линия с несколькими входящими и одной исходящей стрелкой);
q начальное состояние (черный кружок);
q конечное состояние (незакрашенный кружок, в котором размещен черный кружок меньшего размера).
Вершина «решение» позволяет отобразить разветвление вычислительного процесса, исходящие из него стрелки помечаются сторожевыми условиями ветвления.
Вершина «объединение» отмечает точку слияния альтернативных потоков действий.
Линейки синхронизации позволяют показать параллельные потоки действий, отмечая точки их синхронизации при запуске (момент разделения) и при завершении (момент слияния).
Пример диаграммы деятельности приведен на рис. 12.15. Эта диаграмма описывает деятельность покупателя в Интернет-магазине. Здесь представлены две точки ветвления — для выбора способа поиска товара и для принятия решения о покупке. Присутствуют три линейки синхронизации: верхняя отражает разделение на два параллельных процесса, средняя отражает и разделение, и слияние процессов, а нижняя — только слияние процессов.

Рис. 12.15. Диаграмма деятельности покупателя в Интернет-магазине
Дополнительно на этой диаграмме показаны две плавательные дорожки — дорожка покупателя и дорожка магазина, которые разделены вертикальной линией. Каждая дорожка имеет имя и фиксирует область деятельности конкретного лица, обозначая зону его ответственности.
Диаграммы последовательности
Диаграмма последовательности — вторая разновидность диаграмм взаимодействия. Отражая сценарий поведения в системе, эта диаграмма обеспечивает более наглядное представление порядка передачи сообщений. Правда, она не позволяет показать такие детали, которые видны на диаграмме сотрудничества (структурные характеристики объектов и связей).
Графически диаграмма последовательности — разновидность таблицы, которая показывает объекты, размещенные вдоль оси X, и сообщения, упорядоченные по времени вдоль оси Y.

Рис. 12.21. Диаграмма последовательности системы управления полетом
Как показано на рис. 12.21, объекты, участвующие во взаимодействии, помещаются на вершине диаграммы, вдоль оси X. Обычно слева размещается объект, инициирующий взаимодействие, а справа — объекты по возрастанию подчиненности. Сообщения, посылаемые и принимаемые объектами, помещаются вдоль оси Y в порядке возрастания времени от вершины к основанию диаграммы. Используются те же синтаксис и обозначения синхронизации, что и в диаграммах сотрудничества. Таким образом, обеспечивается простое визуальное представление потока управления во времени.
От диаграмм сотрудничества диаграммы последовательности отличают две важные характеристики.
Первая характеристика — линия жизни объекта.
Линия жизни объекта — это вертикальная пунктирная линия, которая обозначает период существования объекта. Большинство объектов существуют на протяжении всего взаимодействия, их линии жизни тянутся от вершины до основания диаграммы. Впрочем, объекты могут создаваться в ходе взаимодействия. Их линии жизни начинаются с момента приема сообщения «create». Кроме того, объекты могут уничтожаться в ходе взаимодействия. Их линии жизни заканчиваются с момента приема сообщения «destroy». Как представлено на рис. 12.22, уничтожение линии жизни отмечается пометкой X в конце линии:
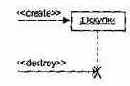
Рис. 12.22. Создание и уничтожение объекта
Вторая характеристика — фокус управления.
Фокус управления — это высокий тонкий прямоугольник, отображающий период времени, в течение которого объект выполняет действие (свою или подчиненную процедуру).
Вершина прямоугольника отмечает начало действия, а основание — его завершение. Момент завершения может маркироваться сообщением возврата, которое показывается пунктирной стрелкой. Можно показать вложение фокуса управления (например, рекурсивный вызов собственной операции). Для этого второй фокус управления рисуется немного правее первого (рис. 12.23).

Рис. 12.23. Вложение фокусов управления
Замечания.
1. Для отображения «условности» линия жизни может быть разделена на несколько параллельных линий жизни. Каждая отдельная линия соответствует условному ветвлению во взаимодействии. Далее в некоторой точке линии жизни могут быть снова слиты (рис. 12.24).

Рис. 12.24. Параллельные линии жизни
2. Ветвление показывается множеством стрелок, идущих из одной точки. Каждая стрелка отмечается сторожевым условием (рис. 12.25).

Рис. 12.25. Ветвление
Диаграммы потоков данных
Диаграмма потоков данных ПДД — графическое средство для изображения информационного потока и преобразований, которым подвергаются данные при движении от входа к выходу системы. Элементы диаграммы имеют вид, показанный на рис. 3.1. Диаграмма может использоваться для представления программного изделия на любом уровне абстракции.
Пример системы взаимосвязанных диаграмм показан на рис. 3.2.
Диаграмма высшего (нулевого) уровня представляет систему как единый овал со стрелкой, ее называют основной или контекстной моделью. Контекстная модель используется для указания внешних связей программного изделия. Для детализации (уточнения системы) вводится диаграмма 1-го уровня. Каждый из преобразователей этой диаграммы — подфункция общей системы. Таким образом, речь идет о замене преобразователя F на целую систему преобразователей.
Дальнейшее уточнение (например, преобразователя F3) приводит к диаграмме 2-го уровня. Говорят, что ПДД1 разбивается на диаграммы 2-го уровня.

Рис. 3.2. Система взаимосвязанных диаграмм потоков данных
ПРИМЕЧАНИЕ
Важно сохранить непрерывность информационного потока и его согласованность. Это значит, что входы и выходы у каждого преобразователя на любом уровне должны оставаться прежними. В диаграмме отсутствуют точные указания на последовательность обработки. Точные указания откладываются до этапа проектирования.
Диаграмма потоков данных — это абстракция, граф. Для связи графа с проблемной областью (превращения в граф-модель) надо задать интерпретацию ее компонентов — дуг и вершин.
Диаграммы размещения
Диаграмма размещения (развертывания) — вторая из двух разновидностей диаграмм реализации UML, моделирующих физические аспекты объектно-ориентированных систем. Диаграмма размещения показывает конфигурацию обрабатывающих узлов в период работы системы, а также компоненты, «живущие» в них.
Элементами диаграмм размещения являются узлы, а также отношения зависимости и ассоциации. Как и другие диаграммы, диаграммы размещения могут включать примечания и ограничения. Кроме того, диаграммы размещения могут включать компоненты, каждый из которых должен жить в некотором узле, а также содержать пакеты или подсистемы, используемые для группировки элементов модели в крупные фрагменты. При необходимости визуализации конкретного варианта аппаратной топологии в диаграммы размещения могут помещаться объекты.
Диаграммы схем состояний
Диаграмма схем состояний — одна из пяти диаграмм UML, моделирующих динамику систем. Диаграмма схем состояний отображает конечный автомат, выделяя поток управления, следующий от состояния к состоянию. Конечный автомат — поведение, которое определяет последовательность состояний в ходе существования объекта. Эта последовательность рассматривается как ответ на события и включает реакции на эти события.
Диаграмма схем состояний показывает:
1) набор состояний системы;
2) события, которые вызывают переход из одного состояния в другое;
3) действия, которые происходят в результате изменения состояния.
В языке UML состоянием называют период в жизни объекта, на протяжении которого он удовлетворяет какому-то условию, выполняет определенную деятельность или ожидает некоторого события. Как показано на рис. 12.1, состояние изображается как закругленный прямоугольник, обычно включающий его имя и подсостоя-ния (если они есть).

Рис. 12.1. Обозначение состояния
Переходы между состояниями отображаются помеченными стрелками (рис. 12.2).

Рис. 12.2. Переходы между состояниями
На рис. 12.2 обозначено: Событие — происшествие, вызывающее изменение состояния, Действие — набор операций, запускаемых событием.
Иначе говоря, события вызывают переходы, а действия являются реакциями на переходы.
Примеры событий:
| баланс < 0
помехи уменьшить(Давление) after (5 seconds) when (time = 16:30) | Изменение в состоянии
Сигнал (объект с именем) Вызов действия Истечение периода времени Наступление абсолютного момента времени |
Примеры действий:
| Кассир. прекратитьВыплаты( )
flt:= new(Фильтp); Ш.убратьПомехи( ) send Ник. привет | Вызов одной операции
Вызов двух операций Посылка сигнала в объект Ник |
ПРИМЕЧАНИЕ
Для отображения посылки сигнала используют специальное обозначение — перед именем сигнала указывают служебное слово send.
Для отображения перехода в начальное состояние принято обозначение, показанное на рис. 12.3.

Рис. 12.3. Переход в начальное состояние
Соответственно, обозначение перехода в конечное состояние имеет вид, представленный на рис. 12.4.

Рис. 12.4. Переход в конечное состояние
В качестве примера на рис. 12.5 показана диаграмма схем состояний для системы охранной сигнализации.

Рис. 12.5. Диаграмма схем состояний системы охранной сигнализации
Из рисунка видно, что система начинает свою жизнь в состоянии Инициализация, затем переходит в состояние Ожидание. В этом состоянии через каждые 10 секунд (по событию after (10 sec.)) выполняется самопроверка системы (операция Самопроверка ()). При наступлении события Тревога (Датчик) реализуются действия, связанные с блокировкой периметра охраняемого объекта, — исполняется операция БлокироватьПериметр() и осуществляется переход в состояние Активна. В активном состоянии через каждые 5 секунд по событию after (5 sec.) запускается операция ПриемКоманды(). Если команда получена (наступило событие Сброс), система возвращается в состояние Ожидание. В процессе возврата разблокируется периметр охраняемого объекта (операция РазблокироватьПериметр()).
Диаграммы сотрудничества
Диаграммы сотрудничества отображают взаимодействие объектов в процессе функционирования системы. Такие диаграммы моделируют сценарии поведения системы. В русской литературе диаграммы сотрудничества часто называют диаграммами кооперации.
Обозначение объекта показано на рис. 12.16.

Рис. 12.16. Обозначение объекта
Имя объекта подчеркивается и указывается всегда, свойства указываются выборочно. Синтаксис представления имени имеет вид
ИмяОбъекта : ИмяКласса
Примеры записи имени:
| Адам : Человек
: Пользователь мойКомпьютер агент : | Имя объекта и класса
Только имя класса (анонимный объект) Только имя объекта (подразумевается, что имя класса известно) Объект — сирота (подразумевается, что имя класса неизвестно) |
Синтаксис представления свойства имеет вид
Имя : Тип = Значение
Примеры записи свойства:
| номер:Телефон = "7350-420"
активен = True | Имя, тип, значение
Имя и значение |
Объекты взаимодействуют друг с другом с помощью связей — каналов для передачи сообщений. Связь между парой объектов рассматривается как экземпляр ассоциации между их классами. Иными словами, связь между двумя объектами существует только тогда, когда имеется ассоциация между их классами. Неявно все классы имеют ассоциацию сами с собой, следовательно, объект может послать сообщение самому себе.
Итак, связь — это путь для пересылки сообщения. Путь может быть снабжен характеристикой видимости. Характеристика видимости проставляется как стандартный стереотип над дальним концом связи. В языке предусмотрены следующие стандартные стереотипы видимости:
| «global»
«local» «parameter» «self» | Объект-поставщик находится в глобальной области определения
Объект-поставщик находится в локальной области определения объекта-клиента Объект-поставщик является параметром операции объекта-клиента Один и тот же объект является и клиентом, и поставщиком |
Сообщение — это спецификация передачи информации между объектами в ожидании того, что будет обеспечена требуемая деятельность.
Прием сообщения рассматривается как событие.
Результатом обработки сообщения обычно является действие. В языке UML моделируются следующие разновидности действий:
|
Вызов Возврат Посылка(Send) Создание Уничтожение |
В объекте запускается операция Возврат значения в вызывающий объект В объект посылается сигнал Создание объекта, выполняется по стандартному сообщению «create» Уничтожение объекта, выполняется по стандартному сообщению «destroy» |
ВозврВеличина := ИмяСообщения (Аргументы),
где ВозврВеличина задает величину, возвращаемую как результат обработки сообщения.
Примеры записи сообщений:
|
Коорд := ТекущПоложение(самолетТ1) оповещение( ) УстановитьМаршрут(х) «create» |
Вызов операции, возврат значения Посылка сигнала Вызов операции с действительным параметром Стандартное сообщение для создания объекта |
Наиболее общую форму управления задает процедурный или вложенный поток (поток синхронных сообщений). Как показано на рис. 12.17, процедурный поток рисуется стрелками с заполненными наконечниками.

Рис. 12.17. Поток синхронных сообщений
Здесь сообщение 2.1 : Напиток : = Изготовить(Смесь№3) определено как первое сообщение, вложенное во второе сообщение 2 : Заказать(Смесь№3) последовательности, а сообщение 2.2 : Принести(Напиток) — как второе вложенное сообщение. Все сообщения процедурной последовательности считаются синхронными. Работа с синхронным сообщением подчиняется следующему правилу: передатчик ждет до тех пор, пока получатель не примет и не обработает сообщение.
В нашем примере это означает, что третье сообщение будет послано только после обработки сообщений 2.1 и 2.2. Отметим, что степень вложенности сообщений может быть любой. Главное, чтобы соблюдалось правило: последовательность сообщений внешнего уровня возобновляется только после завершения вложенной последовательности.
Менее общую форму управления задает асинхронный поток управления. Как показано на рис. 12.18, асинхронный поток рисуется обычными стрелками. Здесь все сообщения считаются асинхронными, при которых передатчик не ждет реакции от получателя сообщения. Такой вид коммуникации имеет семантику почтового ящика — получатель принимает сообщение по мере готовности. Иными словами, передатчик и получатель не синхронизируют свою работу, скорее, один объект «избавляется» от сообщения для другого объекта. В нашем примере сообщение ПодтверждениеВызова определено как второе сообщение в последовательности.

Рис. 12.18. Поток асинхронных сообщений
Помимо рассмотренных линейных потоков управления, можно моделировать и более сложные формы — итерации и ветвления.
Итерация представляет повторяющуюся последовательность сообщений. После номера сообщения итерации добавляется выражение
*[i := 1 .. n].
Оно означает, что сообщение итерации будет повторяться заданное количество раз. Например, четырехкратное повторение первого сообщения РисоватьСторонуПрямоугольника можно задать выражением
1*[1 := 1 .. 4] : РисоватьСторонуПрямоугольника(i)
Для моделирования ветвления после номера сообщения добавляется выражение условия, например: [х>0]. Сообщение альтернативной ветви помечается таким же номером, но с другим условием: [х<=0]. Пример итерационного и разветвляющегося потока сообщений приведен на рис. 12.19.
Здесь первое сообщение повторяется 4 раза, а в качестве второго выбирается одно из двух сообщений (в зависимости от значения переменной х). В итоге экземпляр рисователя нарисует на экране прямоугольное окно, а экземпляр собеседника выведет в него соответствующее донесение.
Таким образом, для формирования диаграммы сотрудничества выполняются следующие действия:
1) отображаются объекты, которые участвуют во взаимодействии;
2) рисуются связи, соединяющие эти объекты;
3) связи помечаются сообщениями, которые посылают и получают выделенные объекты.

Рис. 12.19. Итерация и ветвление
В итоге формируется ясное визуальное представление потока управления (в контексте структурной организации сотрудничающих объектов).
В качестве примера на рис. 12.20 приведена диаграмма сотрудничества системы управления полетом летательного аппарата.

Рис. 12.20. Диаграмма сотрудничества системы управления полетом
На данной диаграмме представлены пять объектов, явно показаны характеристики видимости всех связей системы. Поток управления в системе включает восемь сообщений: четыре асинхронных и четыре синхронных сообщения. Экземпляр Контроллера СУ ждет приема и обработки сообщений:
q ВклРегСкор( );
q ВрРегУгл();
q ТекущСкор();
q ТекущУгл( ).
Порядок следования сообщений задан их номерами. Для пятого и седьмого сообщений указаны условия:
q включение Регулятора Скорости происходит, если относительное время полета Т больше заданного периода Тзад;
q включение Регулятора Углов обеспечивается, если относительное время поле-; та меньше или равно заданному периоду.
Диаграммы Use Case
Диаграмма Use Case определяет поведение системы с точки зрения пользователя. Диаграмма Use Case рассматривается как главное средство для первичного моделирования динамики системы, используется для выяснения требований к разрабатываемой системе, фиксации этих требований в форме, которая позволит проводить дальнейшую разработку. В русской литературе диаграммы Use Case часто называют диаграммами прецедентов, или диаграммами вариантов использования.
В состав диаграмм Use Case входят элементы Use Case, актеры, а также отношения зависимости, обобщения и ассоциации. Как и другие диаграммы, диаграммы Use Case могут включать примечания и ограничения. Кроме того, диаграммы Use Case могут содержать пакеты, используемые для группировки элементов модели в крупные фрагменты.
Диаграммы в UML
Диаграмма — графическое представление множества элементов, наиболее часто изображается как связный граф из вершин (предметов) и дуг (отношений). Диаграммы рисуются для визуализации системы с разных точек зрения, затем они отображаются в систему. Обычно диаграмма дает неполное представление элементов, которые составляют систему. Хотя один и тот же элемент может появляться во всех диаграммах, на практике он появляется только в некоторых диаграммах. Теоретически диаграмма может содержать любую комбинацию предметов и отношений, на практике ограничиваются малым количеством комбинаций, которые соответствуют пяти представлениям архитектуры ПС. По этой причине UML включает девять видов диаграмм:
1) диаграммы классов;
2) диаграммы объектов;
3) диаграммы Use Case (диаграммы прецедентов);
4) диаграммы последовательности;
5) диаграммы сотрудничества (кооперации);
6) диаграммы схем состояний;
7) диаграммы деятельности;
8) компонентные диаграммы;
9) диаграммы размещения (развертывания).
Диаграмма классов показывает набор классов, интерфейсов, сотрудничеств и их отношений. При моделировании объектно-ориентированных систем диаграммы классов используются наиболее часто. Диаграммы классов обеспечивают статическое проектное представление системы. Диаграммы классов, включающие активные классы, обеспечивают статическое представление процессов системы.
Диаграмма объектов показывает набор объектов и их отношения. Диаграмма объектов представляет статический «моментальный снимок» с экземпляров предметов, которые находятся в диаграммах классов. Как и диаграммы классов, эти диаграммы обеспечивают статическое проектное представление или статическое представление процессов системы (но с точки зрения реальных или фототипичных случаев).
Диаграмма Use Case (диаграмма прецедентов) показывает набор элементов Use Case, актеров и их отношений. С помощью диаграмм Use Case для системы создается статическое представление Use Case. Эти диаграммы особенно важны при организации и моделировании поведения системы, задании требований заказчика к системе.
Диаграммы последовательности и диаграммы сотрудничества — это разновидности диаграмм взаимодействия.
Диаграмма взаимодействия показывает взаимодействие, включающее набор объектов и их отношений, а также пересылаемые между объектами сообщения. Диаграммы взаимодействия обеспечивают динамическое представление системы.
Диаграмма последовательности — это диаграмма взаимодействия, которая выделяет упорядочение сообщений по времени.
Диаграмма сотрудничества (диаграмма кооперации) — это диаграмма взаимодействия, которая выделяет структурную организацию объектов, посылающих и принимающих сообщения. Диаграммы последовательности и диаграммы сотрудничества изоморфны, что означает, что одну диаграмму можно трансформировать в другую диаграмму.
Диаграмма схем состояний показывает конечный автомат, представляет состояния, переходы, события и действия. Диаграммы схем состояний обеспечивают динамическое представление системы. Они особенно важны при моделировании поведения интерфейса, класса или сотрудничества. Эти диаграммы выделяют такое поведение объекта, которое управляется событиями, что особенно полезно при моделировании реактивных систем.
Диаграмма деятельности — специальная разновидность диаграммы схем состояний, которая показывает поток от действия к действию внутри системы. Диаграммы деятельности обеспечивают динамическое представление системы. Они особенно важны при моделировании функциональности системы и выделяют поток управления между объектами.
Компонентная диаграмма показывает организацию набора компонентов и зависимости между компонентами. Компонентные диаграммы обеспечивают статическое представление реализации системы. Они связаны с диаграммами классов в том смысле, что в компонент обычно отображается один или несколько классов, интерфейсов или коопераций.
Диаграмма размещения (диаграмма развертывания) показывает конфигурацию обрабатывающих узлов периода выполнения, а также компоненты, живущие в них. Диаграммы размещения обеспечивают статическое представление размещения системы.Они связаны с компонентными диаграммами в том смысле, что узел обычно включает один или несколько компонентов.
Диаграммы взаимодействия
Диаграммы взаимодействия предназначены для моделирования динамических аспектов системы. Диаграмма взаимодействия показывает взаимодействие, включающее набор объектов и их отношений, а также пересылаемые между объектами сообщения. Существуют две разновидности диаграммы взаимодействия — диаграмма последовательности и диаграмма сотрудничества. Диаграмма последовательности — это диаграмма взаимодействия, которая выделяет упорядочение сообщений по времени. Диаграмма сотрудничества — это диаграмма взаимодействия, которая выделяет структурную организацию объектов, посылающих и принимающих сообщения. Элементами диаграмм взаимодействия являются участники взаимодействия — объекты, связи, сообщения.
Доопределение функций
Следующий шаг — доопределение функций. Этот шаг развивает диаграмму системной спецификации этапа анализа. Уточняются процессы-модели. В них вводятся дополнительные функции. Джексон выделяет 3 типа сервисных функций:
1. Встроенные функции (задаются командами, вставляемыми в структурный текст процесса-модели).
2. Функции впечатления (наблюдают вектор состояния процесса-модели и вырабатывают выходные результаты).
3. Функции диалога.
Они решают следующие задачи:
q наблюдают вектор состояния процесса-модели;
q формируют и выводят поток данных, влияющий на действия в процессе-модели;
q выполняют операции для выработки некоторых результатов.
Встроенную функцию введем в модель ТРАНСПОРТ-1. Предположим, что в модели есть панель с лампочкой, сигнализирующей о прибытии. Лампочка включается командой LON(i), а выключается командой LOFF(i). По мере перемещения транспорта между остановками формируется поток LAMP-команд. Модифицированный структурный текст модели ТРАНСПОРТ-1 принимает вид
ТРАНСПОРТ-1
LON(l);
опрос SV;
ЖДАТЬ цикл ПОКА ПРИБЫЛ(1)
опрос SV;
конец ЖДАТЬ;
LOFF(l);
покинуть(1);
ТРАНЗИТ цикл ПОКА УБЫЛ(1)
опрос SV;
конец ТРАНЗИТ;
ТРАНСПОРТ цикл
ОСТАНОВКА;
прибыть(i);
LON(i);
ЖДАТЬ цикл ПОКА ПРИБЫЛ(i)
опрос SV;
конец ЖДАТЬ;
LOFF(i);
покинуть(i);
ТРАНЗИТ цикл ПОКА УБЫЛ(i)
опрос SV;
конец ТРАНЗИТ;
конец ОСТАНОВКА;
конец ТРАНСПОРТ;
прибыть(1);
конец ТРАНСПОРТ-1;
Теперь введем функцию впечатления. В нашем примере она может формировать команды для мотора транспорта: START, STOP.
Условия выработки этих команд.
q Команда STOP формируется, когда датчики регистрируют прибытие транспорта на остановку.
q Команда START формируется, когда нажата кнопка для запроса транспорта и транспорт ждет на одной из остановок.
Видим, что для выработки команды STOP необходима информация только от модели транспорта.
В свою очередь, для выработки команды START нужна информация как от модели КНОПКА-1, так и от модели ТРАНСПОРТ-1. В силу этого для реализации функции впечатления введем функциональный процесс М-УПРАВЛЕНИЕ. Он будет обрабатывать внешние данные и формировать команды START и STOP.
Ясно, что процесс М-УПРАВЛЕНИЕ должен иметь внешние связи с моделями ТРАНСПОРТ-1 и КНОПКА. Соединение с моделью КНОПКА организуем через вектор состояния BV. Соединение с моделью ТРАНСПОРТ-1 организуем через поток данных S1D.
Для обеспечения М-УПРАВЛЕНИЯ необходимой информацией опять надо изменить структурный текст модели ТРАНСПОРТ-1. В нем предусмотрим занесение сообщения Прибыл в буфер S1D:
ТРАНСПОРТ-1
LON(l);
опрос SV;
ЖДАТЬ цикл ПОКА ПРИБЫЛ(1)
опрос SV;
конец ЖДАТЬ;
LOFF(l);
Покинуть(1);
ТРАНЗИТ цикл ПОКА УБЫЛ(1)
опрос SV;
конец ТРАНЗИТ;
ТРАНСПОРТ цикл
ОСТАНОВКА;
прибыть(i):
записать Прибыл в S1D;
LON(i);
ЖДАТЬ цикл ПОКА ПРИБЫЛ(i)
опрос SV;
конец ЖДАТЬ;
LOFF(i);
покинуть(i);
ТРАНЗИТ цикл ПОКА УБЫЛ(i)
опрос SV;
конец ТРАНЗИТ;
конец ОСТАНОВКА;
конец ТРАНСПОРТ;
прибыть(1);
записать Прибыл в S1D;
конец ТРАНСПОРТ-1;
Очевидно, что при такой связи процессов необходимо гарантировать, что процесс ТРАНСПОРТ-1 выполняет операции опрос SV, а процесс М-УПРАВЛЕНИЕ читает сообщения Прибытия в S1D с частотой, достаточной для своевременной остановки транспорта. Временные ограничения, планирование и реализация должны рассматриваться в последующих шагах проектирования.
В заключение введем функцию диалога. Свяжем эту функцию с необходимостью развития модели КНОПКА-1. Следует различать первое нажатие на кнопку (оно формирует запрос на поездку) и последующие нажатия на кнопку (до того, как поездка действительно началась).
Диаграмма дополнительного процесса КНОПКА-2, в котором учтено это уточнение, показана на рис. 5.7.

Рис. 5.7. Диаграмма дополнительного процесса КНОПКА-2
Внешние связи модели КНОПКА-2 должны включать:
q одно соединеннее моделью КНОПКА-1 — организуется через поток данных BID (для приема сообщения о нажатии кнопки);
q два соединения с процессом М-УПРАВЛЕНИЕ — одно организуется через поток данных MBD (для приема сообщения о прибытии транспорта), другое организуется через вектор состояния BV (для передачи состояния переключателя Запрос).
Таким образом, КНОПКА-2 читает два буфера данных, заполняемых процессами КНОПКА-1 и М-УПРАВЛЕНИЕ, и формирует состояние внутреннего электронного переключателя Запрос. Она реализует функцию диалога.
Структурный текст модели КНОПКА-2 может иметь следующий вид:
КНОПКА-2
Запрос := НЕТ;
читать B1D;
ГрНАЖ цикл
ЖдатьНАЖ цикл ПОКА Не НАЖАТА
читать B1D;
конец ЖдатьНАЖ;
Запрос := ДА;
читать MBD;
ЖдатьОБСЛУЖ цикл ПОКА Не ПРИБЫЛ
читать MBD;
конец ЖдатьОБСЛУЖ;
Запрос := НЕТ; читать B1D;
конец ГрНАЖ;
конец КНОПКА-2;
Диаграмма системной спецификации, отражающая все изменения, представлена на рис. 5.8.

Рис. 5.8. Полная диаграмма системной спецификации
Встроенная в ТРАНСПОРТ-1 функция вырабатывает LAMP-команды, функция впечатления модели М-УПРАВЛЕНИЕ генерирует команды управления мотором, а модель КНОПКА-2 реализует функцию диалога (совместно с процессом М-УПРАВЛЕНИЕ).
Факторы затрат постархитектурной модели СОСОМО II
Значительную часть времени при использовании модели СОСОМО II занимает работа с факторами затрат. Это приложение содержит описание таблиц Боэма, обеспечивающих оценку факторов затрат.
Факторы продукта
Таблица А.1. Требуемая надежность ПО (Required Software Reliability) RELY
| Фактор | Очень
низкий | Низкий | Номинальный | Высокий | Очень высокий | Сверхвысокий | |||||||
| RELY | Легкое беспокойство | Низкая, легко восстанавливаемые потери | Умеренная, легко восстанавливаемые потери | Высокая, финансовые потери | Риск для человеческой жизни |
Таблица А.2. Размер базы данных (Data Base Size) DATA
| Фактор | Очень низкий | Низкий | Номинальный | Высокий | Очень высокий | Сверхвысокий | |||||||
| DATA | Байты БД/ LOCnporp. < 10 | 10 | 100 | D/P |
ПРИМЕЧАНИЕ
Фактор DATA определяется делением размера БД (D) на длину кода программы (Р). Длина программы представляется в LOC-оценках.
Сложность продукта (Product Complexity) CPLX
Сложность продукта определяют по двум следующим таблицам. Выделяют 5 областей применения продукта: операции управления, вычислительные операции, операции с приборами (устройствами), операции управления данными, операции управления пользовательским интерфейсом. Выбирается область или комбинация областей, которые характеризуют продукт или подсистему продукта. Сложность рассматривается как взвешенное среднее значение для этих областей.
Таблица А.З. Сложность модуля в зависимости от области применения
| CPLX | Операции управления | Вычислительные операции | Операции с приборами | ||||
| Очень низкий | Последовательный код | Вычисление простых | Простые операторы | ||||
| с небольшим | выражений, | чтения и записи, | |||||
| количеством | например, | использующие простые | |||||
| структурированных | A=B+C*(D-E) | форматы | |||||
| операторов: DO, CASE, | |||||||
| IF-THEN-ELSE.Простая | |||||||
| композиция модулей | |||||||
| с помощью вызовов | |||||||
| процедур и простых | |||||||
| сценариев | |||||||
| Низкий | Несложная вложенность | Вычисление выражений | Не требуется знание | ||||
| структурированных | средней сложности, | характеристик | |||||
| операторов. В основном | например | конкретного процессора | |||||
| простые предикаты | D=SQRT(B**2-4*A*C) | или устройства ввода- | |||||
| вывода. Ввод-вывод выполняется на уровне GET/PUT | |||||||
| Номинальный | В основном простая | Использование | Обработка ввода- | ||||
| вложенность. | стандартных | вывода, включающая | |||||
| Некоторое | математических | выбор устройства, | |||||
| межмодульное | и статистических | проверку состояния | |||||
| управление. Таблицы | подпрограмм. | и обработку ошибок | |||||
| решений. Простые | Базовые матричные / | ||||||
| обратные вызовы | векторные операции | ||||||
| (callbacks) или | |||||||
| передачи сообщений, | |||||||
| включение | |||||||
| среднего уровня — | |||||||
| поддержка | |||||||
| распределенной | |||||||
| обработки | |||||||
| Высокий | Высокая вложенность | Базовый численный | Операции ввода-вывода | ||||
| операторов | анализ: | физического уровня | |||||
| с составными | мультивариантная | (определение адресов | |||||
| предикатами. | интерполяция, обычные | физической памяти; | |||||
| Управление | дифференциальные | поиски, чтения и т. д.). | |||||
| очередями и стеками. | уравнения. Базисное | Оптимизированный | |||||
| Однородная | усечение, учет потерь | совмещенный | |||||
| распределенная | точности | ввод-вывод | |||||
| обработка. Управление | |||||||
| ПО реального времени | |||||||
| на единственном | |||||||
| процессоре | |||||||
| Очень высокий | Реентерабельное | Сложный, но | Процедуры для | ||||
| и рекурсивное | структурированный | диагностики | |||||
| программирование. | численный анализ: | по прерыванию, | |||||
| Обработка прерываний | уравнения с плохо | обслуживание | |||||
| с фиксированными | обусловленными | и маскирование | |||||
| . | приоритетами | матрицами, уравнения | прерываний. | ||||
| Синхронизация задач, | в частных производных. | Обслуживание линий | |||||
| сложные обратные | Простой параллелизм | связи. | |||||
| вызовы, гетерогенная | Высокопроизводитель- | ||||||
| распределенная | ные встроенные | ||||||
| обработка. Управление | системы | ||||||
| однопроцессорной | |||||||
| системой в реальном | |||||||
| времени | |||||||
| Сверхвысокий | Планирование | Сложный | Программирование | ||||
| множественных | и неструктурированный | с учетом временных | |||||
| ресурсов с динамически | численный анализ: | характеристик | |||||
| изменяющимися | высокоточный анализ | приборов, | |||||
| приоритетами. | стохастических данных | микропрограммные | |||||
| Управление на уровне | с большим количеством | операции. Критические | |||||
| микропрограмм. | шумов. Сложный | к производительности | |||||
| Управление | параллелизм | встроенные системы | |||||
| распределенной | |||||||
| аппаратурой в реальном | |||||||
| времени |
Таблица А.4. Сложность модуля в зависимости от области применения
|
CPLX |
Операции управления данными |
Операции управления пользовательским интерфейсом |
|
Очень низкий |
Простые массивы в оперативной памяти. Простые запросы к БД, обновления |
Простые входные формы, генераторы отчетов |
|
Низкий |
Использование одного файла без изменения структуры данных, без редактирования и промежуточных файлов. Умеренно сложные запросы к БД, обновления |
Использование билдеров для простых графических интерфейсов |
|
Номинальный |
Ввод из нескольких файлов и вывод в один файл. Простые структурные изменения, простое редактирование. Сложные запросы БД, обновления |
Простое использование набора графических объектов (widgets) |
|
Высокий |
Простые триггеры, активизируемые содержимым потока данных. Сложное изменение структуры данных |
Разработка набора графических объектов, его расширение. Простой голосовой ввод-вывод, мультимедиа |
|
Очень высокий |
Координация распределенных БД. Сложные триггеры. Оптимизация поиска |
Умеренно сложная 2D/3D-графика, динамическая графика, мультимедиа |
|
Сверхвысокий |
Динамические реляционные и объектные структуры с высоким сцеплением. Управление данными с помощью естественного языка |
Сложные мультимедиа, виртуальная реальность |
|
Фактор |
Очень низкий |
Низкий |
Номинальный |
Высокий |
Очень высокий |
Сверхвысокий |
|
RUSE |
Нет |
На уровне проекта |
На уровне программы |
На уровне семейства продуктов |
На уровне нескольких семейств продуктов |
Таблица А.6. Документирование требований жизненного цикла (Documentation match to life-cycle needs) DOCU
|
Фактор |
Очень низкий |
Низкий |
Номинальный |
Высокий |
Очень высокий |
Сверхвысокий |
|
DOCU |
Многие требования жизненного цикла не учтены |
Некоторые требования жизненного цикла не учтены |
Оптимизированы к требованиям жизненного цикла |
Избыточны по отношению к требованиям жизненного цикла |
Очень избыточны по отношению к ребованиям жизненного цикла |
|
Факторы платформы (виртуальной машины)
Таблица А.7. Ограничения времени выполнения (Execution Time Constraint) TIME
|
Фактор |
Очень низкий |
Низкий |
Номинальный |
Высокий |
Очень высокий |
Сверхвысокий |
|
TIME |
Используется ? 50% возможного времени выполнения |
70% |
85% |
95% |
Таблица А.8. Ограничения оперативной памяти (Main Storage Constraint) STOR
|
Фактор |
Очень низкий |
Низкий |
Номинальный |
Высокий |
Очень высокий |
Сверхвысокий |
|
STOR |
Используется ? 50% доступной памяти |
70% |
85% |
95% |
Таблица А.9. Изменчивость платформы (Platform Volatility) PVOL
|
Фактор |
Очень низкий |
Низкий |
Номинальный |
Высокий |
Очень высокий |
Сверхвысокий |
|
PVOL |
Значительные изменения — каждые 12мес.; незначительные — каждый месяц |
Значительные изменения — каждые 6 мес.; незначительные — каждые 2 недели |
Значительные изменения — 2 мес.; незначительные — 1 неделя |
Значительные изменения — 2нед.; незначительные — 2 дня |
|
Таблица А. 10. Возможности аналитика (Analyst Capability) ACAP
|
Фактор |
Очень низкий |
Функциональная связностьФункционально связный модуль содержит элементы, участвующие в выполнении одной и только одной проблемной задачи. Примеры функционально связных модулей: q Вычислять синус угла; q Проверять орфографию; q Читать запись файла; q Вычислять координаты цели; q Вычислять зарплату сотрудника; q Определять место пассажира. Каждый из этих модулей имеет единичное назначение. Когда клиент вызывает модуль, выполняется только одна работа, без привлечения внешних обработчиков. Например, модуль Определять место пассажира должен делать только это; он не должен распечатывать заголовки страницы. Некоторые из функционально связных модулей очень просты (например, Вычислять синус угла или Читать запись файла), другие сложны (например, Вычислять координаты цели). Модуль Вычислять синус угла, очевидно, реализует единичную функцию, но как может модуль Вычислять зарплату сотрудника выполнять только одно действие? Ведь каждый знает, что приходится определять начисленную сумму, вычеты по рассрочкам, подоходный налог, социальный налог, алименты и т. д.! Дело в том, что, несмотря на сложность модуля и на то, что его обязанность исполняют несколько подфункций, если его действия можно представить как единую проблемную функцию (с точки зрения клиента), тогда считают, что модуль функционально связен. Приложения, построенные из функционально связных модулей, легче всего сопровождать. Соблазнительно думать, что любой модуль можно рассматривать как однофункциональный, но не надо заблуждаться. Существует много разновидностей модулей, которые выполняют для клиентов перечень различных работ, и этот перечень нельзя рассматривать как единую проблемную функцию. Критерий при определении уровня связности этих нефункциональных модулей — как связаны друг с другом различные действия, которые они исполняют.
Функционально-ориентированные метрикиФункционально-ориентированные метрики косвенно измеряют программный продукт и процесс его разработки. Вместо подсчета LOC-оценки при этом рассматривается не размер, а функциональность или полезность продукта. Используется 5 информационных характеристик. 1. Количество внешних вводов. Подсчитываются все вводы пользователя, по которым поступают разные прикладные данные. Вводы должны быть отделены от запросов, которые подсчитываются отдельно. 2. Количество внешних выводов. Подсчитываются все выводы, по которым к пользователю поступают результаты, вычисленные программным приложением. В этом контексте выводы означают отчеты, экраны, распечатки, сообщения об ошибках. Индивидуальные единицы данных внутри отчета отдельно не подсчитываются. 3. Количество внешних запросов. Под запросом понимается диалоговый ввод, который приводит к немедленному программному ответу в форме диалогового вывода. При этом диалоговый ввод в приложении не сохраняется, а диалоговый вывод не требует выполнения вычислений. Подсчитываются все запросы — каждый учитывается отдельно. 4. Количество внутренних логических файлов. Подсчитываются все логические файлы (то есть логические группы данных, которые могут быть частью базы данных или отдельным файлом). 5. Количество внешних интерфейсных файлов. Подсчитываются все логические файлы из других приложений, на которые ссылается данное приложение. Вводы, выводы и запросы относят к категории транзакция. Транзакция — это элементарный процесс, различаемый пользователем и перемещающий данные между внешней средой и программным приложением. В своей работе транзакции используют внутренние и внешние файлы. Приняты следующие определения. Внешний ввод — элементарный процесс, перемещающий данные из внешней среды в приложение. Данные могут поступать с экрана ввода или из другого приложения. Данные могут использоваться для обновления внутренних логических файлов. Данные могут содержать как управляющую, так и деловую информацию. Управляющие данные не должны модифицировать внутренний логический файл. Внешний вывод — элементарный процесс, перемещающий данные, вычисленные в приложении, во внешнюю среду. Кроме того, в этом процессе могут обновляться внутренние логические файлы. Данные создают отчеты или выходные файлы, посылаемые другим приложениям. Отчеты и файлы создаются на основе внутренних логических файлов и внешних интерфейсных файлов. Дополнительно этот процесс может использовать вводимые данные, их образуют критерии поиска и параметры, не поддерживаемые внутренними логическими файлами. Вводимые данные поступают извне, но носят временный характер и не сохраняются во внутреннем логическом файле. Внешний запрос — элементарный процесс, работающий как с вводимыми, так и с выводимыми данными. Его результат — данные, возвращаемые из внутренних логических файлов и внешних интерфейсных файлов. Входная часть процесса не модифицирует внутренние логические файлы, а выходная часть не несет данных, вычисляемых приложением (в этом и состоит отличие запроса от вывода). Внутренний логический файл — распознаваемая пользователем группа логически связанных данных, которая размещена внутри приложения и обслуживается через внешние вводы. Внешний интерфейсный файл — распознаваемая пользователем группа логически связанных данных, которая размещена внутри другого приложения и поддерживается им. Внешний файл данного приложения является внутренним логическим файлом в другом приложении. Каждой из выявленных характеристик ставится в соответствие сложность. Для этого характеристике назначается низкий, средний или высокий ранг, а затем формируется числовая оценка ранга. Для транзакций ранжирование основано на количестве ссылок на файлы и количестве типов элементов данных. Для файлов ранжирование основано на количестве типов элементов-записей и типов элементов данных, входящих в файл. Тип элемента-записи — подгруппа элементов данных, распознаваемая пользователем в пределах файла. Тип элемента данных — уникальное не рекурсивное (неповторяемое) поле, распознаваемое пользователем. В качестве примера рассмотрим табл. 2.2. В этой таблице 10 элементов данных: День, Хиты, % от Сумма хитов, Сеансы пользователя, Сумма хитов (по рабочим дням), % от Сумма хитов (по рабочим дням), Сумма сеансов пользователя (по рабочим дням), Сумма хитов (по выходным дням), % от Сумма хитов (по выходным дням), Сумма сеансов пользователя (по выходным дням). Отметим, что поля День, Хиты, % от Сумма хитов, Сеансы пользователя имеют рекурсивные данные, которые в расчете не учитываются. Таблица 2.2. Пример для расчета элементов данных
Таблица 2.3. Примеры элементов данных
Таблица 2.4. Правила учета элементов данных из графического интерфейса пользователя
Например, GUI для обслуживания клиентов может иметь поля Имя, Адрес, Город, Страна, Почтовый Индекс, Телефон, Email. Таким образом, имеется 7 полей или семь элементов данных. Восьмым элементом данных может быть командная кнопка (добавить, изменить, удалить). В этом случае каждый из внешних вводов Добавить, Изменить, Удалить будет состоять из 8 элементов данных (7 полей плюс командная кнопка). Обычно одному экрану GUI соответствует несколько транзакций. Типичный экран включает несколько внешних запросов, сопровождающих внешний ввод. Обсудим порядок учета сообщений. В приложении с GUI генерируются 3 типа сообщений: сообщения об ошибке, сообщения подтверждения и сообщения уведомления. Сообщения об ошибке (например, Требуется пароль) и сообщения подтверждения (например, Вы действительно хотите удалить клиента?) указывают, что произошла ошибка или что процесс может быть завершен. Эти сообщения не образуют самостоятельного процесса, они являются частью другого процесса, то есть считаются элементом данных соответствующей транзакции. С другой стороны, уведомление является независимым элементарным процессом. Например, при попытке получить из банкомата сумму денег, превышающую их количество на счете, генерируется сообщение Не хватает средств для завершения транзакции. Оно является результатом чтения информации из файла счета и формирования заключения. Сообщение уведомления рассматривается как внешний вывод. Данные для определения ранга и оценки сложности транзакций и файлов приведены в табл. 2.5-2.9 (числовая оценка указана в круглых скобках). Использовать их очень просто. Например, внешнему вводу, который ссылается на 2 файла и имеет 7 элементов данных, по табл. 2.5 назначается средний ранг и оценка сложности 4. Таблица 2.5. Ранг и оценка сложности внешних вводов
Таблица 2.6. Ранг и оценка сложности внешних выводов
Таблица 2.7. Ранг и оценка сложности внешних запросов
Таблица 2.8. Ранг и оценка сложности внутренних логических файлов
Таблица 2.9. Ранг и оценка сложности внешних интерфейсных файлов
После сбора всей необходимой информации приступают к расчету метрики — количества функциональных указателей FP (Function Points). Автором этой метрики является А. Албрехт (1979) [7]. Исходные данные для расчета сводятся в табл. 2.10. Таблица 2.10. Исходные данные для расчета FP-метрик
В таблицу заносится количественное значение характеристики каждого вида (по всем уровням сложности). Места подстановки значений отмечены прямоугольниками (прямоугольник играет роль метки-заполнителя). Количественные значения характеристик умножаются на числовые оценки сложности. Полученные в каждой строке значения суммируются, давая полное значение для данной характеристики. Эти полные значения затем суммируются по вертикали, формируя общее количество. Количество функциональных указателей вычисляется по формуле FP = Общее количество х (0,65+ 0,01 x  где Fi — коэффициенты регулировки сложности. Каждый коэффициент может принимать следующие значения: 0 — нет влияния, 1 — случайное, 2 — небольшое, 3 — среднее, 4 — важное, 5 — основное. Значения выбираются эмпирически в результате ответа на 14 вопросов, которые характеризуют системные параметры приложения (табл. 2.11). Таблица 2.11. Определение системных параметров приложения
После вычисления FP на его основе формируются метрики производительности, качества и т. д.:     Область применения метода функциональных указателей — коммерческие информационные системы. Для продуктов с высокой алгоритмической сложностью используются метрики указателей свойств (Features Points). Они применимы к системному и инженерному ПО, ПО реального времени и встроенному ПО. Для вычисления указателя свойств добавляется одна характеристика — количество алгоритмов. Алгоритм здесь определяется как ограниченная подпрограмма вычислений, которая включается в общую компьютерную программу. Примеры алгоритмов: обработка прерываний, инвертирование матрицы, расшифровка битовой строки. Для формирования указателя свойств составляется табл. 2.12. Таблица 2.12. Исходные данные для расчета указателя свойств
Достоинства функционально-ориентированных метрик: 1. Не зависят от языка программирования. 2. Легко вычисляются на любой стадии проекта. Недостаток функционально-ориентированных метрик: результаты основаны на субъективных данных, используются не прямые, а косвенные измерения. FP-оценки легко пересчитать в LOC-оценки. Как показано в табл. 2.13, результаты пересчета зависят от языка программирования, используемого для реализации ПО. Таблица 2.13. Пересчет FP-оценок в LOC-оценки
Генерация программного кодаКоманды для генерации кода на языке Ada 95 содержит пункт Toots главного меню (рис. 17.33). 1. На компонентной диаграмме выделите оба компонента CourseOffering. 2. Выберите команду Tools:Ada95: Code Generation из главного меню. Итоги генерации кода отображаются в окне Code Generation Status (рис. 17.34). Все ошибки заносятся в log-окно. 3. Для завершения процесса генерации кода нажмите кнопку Close.  Рис. 17.33. Меню Tools: генерация кода на языке Ada 95 Рис. 17.34. Статус генерации кода В процессе генерации Rational Rose отображает логическое описание класса в каркас программного кода — в коде появляются языковые описания имени класса, свойств класса и заголовки методов. Кроме того, для описания тела каждого метода формируется программная заготовка. Появляются и программные связи классов. Подразумевается, что программист будет дополнять этот код, работая в конкретной среде программирования, имеющей мост связи с системой Rational Rose. После каждого существенного дополнения программист с помощью возвратного проектирования, основанного на использовании моста связи, будет модифицировать диаграммы классов, вводя в них изменения, соответствующие результатам программирования. Просмотрим код, сгенерированный средой Rational Rose. Фрагмент содержания .ads-файла, отражающего спецификацию класса CourseOffering, представлен на рис. 17.35. Отметим, что в программный текст добавлено то описание, которое было внесено в модель через окно документации. Более того, система Rational Rose подготавливает код к многократной итеративной модификации, защите выполняемых изменений. Стандартный раздел программного кода имеет вид --##begin module.privateDeclarations preserve=yes --##end module.privateDeclarations  Рис. 17.35. Код спецификации класса, сгенерированный средой Rational Rose Запись module.privateDeclarations обозначает имя раздела. Элемент preserve=(yes/no) говорит системе, можно ли при повторной генерации кода этот раздел изменять или нельзя.
 Рис. 17.36. Код тела класса, сгенерированный Rational Rose Полный листинг сгенерированного кода для тела класса выглядит следующим образом: --##begin module.cp preserve=no --##end module.cp -- Body CourseOffering (Package Body) -- Dir : C:\Program Files\Rationa1\Rose\ada95\source -- File: courseoffering.adb with Unchecked_Deallocation; --##begin module.withs preserve=yes --##end module.withs package body CourseOffering is --##begin module.declarations preserve=no --##end module.declarations -- Standard Operations --##begin CourseOffering.CreatefcObject.documentation preserve=yes --##end CourseOffering.Create%Object.documentation function Create return Object is --##begin CourseOffering.Create%Object.declarations preserve=no --##end CourseOfferi ng.Create%Object.declarations begin --##begin CourseOffering.Create%Object.statements preserve=no [statement] --##end CourseOffering.Create%Object.statements end Create; --##begin CourseOffering.Copy%Object.documentation preserve=yes --##end CourseOfferi ng.Copy%Object.documentation function Copy (From : in Object) return Object is --##begin CourseOffering.Copy%Object.declarations preserve=no --##end CourseOffering.Copy%Object.declarations begin --##begin CourseOffering.Copy%Object.statements preserve=no [statement] --##end CourseOfferi ng.Copy%Object.statements end Copy; --##begin CourseOffering.Free%Object.documentation preserve=yes --##end CourseOfferi ng.Free%Object.documentation procedure Free (This : in out Object) is --##begin CourseOffering.Free%Object.declarations preserve=yes --##end CourseOfferi ng.Free%Object.decl arati ons begin --##begin CourseOffering.Free%Object.statements preserve=no [statement] --##end CourseOffering.Free%Object.statements end Free; --##beginCourseOffering. Create%Handle. documentati on preservers=yes --##end CourseOffering.Create%Handle.documentation function Create return Handle is --##begin CourseOffering.Create%Handle.declarations preserve=no --##end CourseOffering.Create%Handle.declarati ons begin --##begin CourseOffering.Create%Handle.statements preserve=no [statement] --##end CourseOfferi ng.Create%Handle.statements end Create; --##begi n CourseOffering.Copy%Handle.documentation preserve=yes --##end CourseOffering.Copy%Handle.documentation function Copy (From : in Handle) return Handle is --##begin CourseOffering.Copy%Handle.declarations preserve=no --##end CourseOfferi ng.Copy%Handle.declarations begin --##begin CourseOffering.Copy%Handle.statements preserve=no [statement] --##end CourseOfferi ng.Copy%Handle.statements end Copy; --##begin CourseOffering.Free%Handle.documentation preserve=yes --##end CourseOfferi ng.Free%Handle.documentation procedure Free (This : in out Handle) is --##begin CourseOffering.Free%Handle.declarations preserve=yes --##end CourseOffering. Free%Handle. declarations begin --##begin CourseOf feri ng.Free%Handle. statements preserve=no [statement] --##end CourseOffering.Free%Handle.statements end Free: -- Other Operations --##begin CourseOffenng.offeringOpen%Object.940157546.documentati on preserve=yes --##end CourseOfferi ng.offeringOpen%Object.940157546.documentation function offeringOpen (This : in Object) return Integer is --##begin CourseOfferi ng.offeri ngOpen%Object.940157546.declarations preserve=yes --##end CourseOfferi ng.offeri ngOpen%Object.940157546.declarations begin --##begin CourseOfferi ng.offeri ngOpen%Object.940157546.statements preserve=yes [statement] --## end CourseOf feri ng. of f eri ngOpen%Object. 940157546. statements end offeringOpen; -- Accessor Operations for Associations --##begin CourseOffering.Get_The_Course%Object.documentati on preserve=yes --##end CourseOfferi ng. Get_The_Course%Object. documentati on function Get_The_Course (This : in Object) return Course.Handle is --##begi n CourseOfferi ng.Get_The_Course%Object.declarati ons preserve=no --##end CourseOffering. Get__The_Course%Object. declarations begin --##begi n CourseOfferi ng.Get_The_Course%Object.statements preserve=no return This.The_Course; --##end CourseOfferi ng.Get_The_Course%Object.statements end Get_Jhe_Course; -- Association Operations --##begin module.associations preserve=no generic type Role_Type is tagged private; type Access_Role_Type is access Role_Type'Class; type Index is range <>; type Array _Of_Access_Role_Type is array (Index range <>) of Access_Role_Type; type Access_Array_Of_Access Role_Type is access Array_Of_Access_Ro1e_Type; package Generic_Tagged_Association is procedure Set (This_Access_Array : in out Access_Array_Of_Access_Role_Type; This_Array : Array_Of_Access_Role_Type; Limit : Positive := Positive ((Index'Last - Index'First) + 1)); function Is_Unique (This_Array : Array_Of_Access_Role_Type; This : Access_Ro1e_Type) return Boolean; function Unique (This_Array : in Array_Of_Access_Role_Type) return Array_Of_Access_Role_Type; pragma Inline (Set, Is_Unique, Unique); end Generic_Tagged_Association; package body Generic_Tagged_Association is procedure Free is new Unchecked_Deallocation ( Array_Of_Access_Role_Type, Access_Array_Of_Access_Role_Type); procedure Set (This_Access_Array : in out Access_Array_Of_Access_Role_Type; This_Array : Array_Of_Access_Role_Type; Limit : Positive := Positive ((Index'Last - Index'First) + 1)) is Valid : Boolean; Pos : Index := This_Array'First; Last : constant Index := This_Array'Last; Temp_Access_Array : Access_Array_Of_Access_Role_Type; begin if Positive(This_Array'Length) > Limit then raise Constraint_Error; end if; if This_Access_Array - null then -- Allocate entries. This_Access_Array := new Array_Of_Access_Role_Type'(This_Array); return; end if; for I in This_Array'Range loop Valid := Is_Unique (Th1s_Access_Array.all. This_Array (I)); pragma Assert (Valid); end loop; -- Reuse any empty slots. for I in This_Access_Array'Range loop if This_Access_Array (I) = null then This_Access_Array (I) := This_Array (Pos); Pos := Pos + 1; if Pos > Last then return; end if; end if; end loop; if Positive(This_Access_Array'Length + (Last - Pos + 1)) > Limit then raise Constraint_Error; end if; -- For any remaining entries, combine by reallocating. Temp_Access_Array := new Array_Of_Access_Role_Type' (This_Access_Array.all & This_Array (Pos .. Last)); Free (This_Access_Array); This_Access_Array := Temp_Access_Array; end Set; function Is_Unique (This_Array : Array_Of_Access_Role_Type; This : Access_Role_Type) return Boolean is begin if This = null then return False; end if; for I in This_Array'Range loop if This_Array (I) = This then return False; end if; end loop; return True; end Is_Unique; function Unique (This_Array : in Array_Of_Access_Role_Type) return Array_Of_Access_Ro1e_Type is First : constant Index := This_Array'First; Count : Index := First; Temp_Array : Array_Of_Access_Role_Type (This_Array'Range); begin for I in This_Array'Range loop if Is_Unique (Temp_Array (First .. Count - 1). This_Array (I)) then Temp_Array (Count) := This_Array (I); Count :- Count + 1; end if; end loop; return Temp_Array (First .. Count - 1); end Unique: end Generic_Tagged_Association; package Role_0bject is new Generic_Tagged_Association (Object, Handle, Positive, Array_Of_Handle, Access_Array_Of_Hand1e); --##end module.associations procedure Associate (This_Handle : in Handle: This_Handle : in Handle) is --#begin Associate%38099E7D0190.declarations preserve=no use Role_0bject; --##end Associate%38099E7D0190.declarations begin --##begin Associate%38Q99E70Q190.statements preserve=no pragma Assert (This_Hand1e /= null); pragma Assert (This_Handle /= null); pragma Assert (This_Handle.The_Course = null or else This_Handle.The_Course = This_Handle); This_Handle.The_Course := This_Handle; Set (This_Handle.The_CourseOffering. Array_Of_Handle'(1 => This_Handle)); --##end Associate3%38099E7D0l90. statements end Associate; procedure Associate (This_Handle : in Handle; This_Array_Of_Handle : in Array_Of_Handle) is --##begin Associate%(1,N)38099E7D0190.declarations preserve=no use Role_0bject; Temp_Array_Of_Handle : constant Array_Of_Handle := Unique (This_Array_Of_Handle): --«end Associate%(l,N)38099E7D0190.declarations begin --##begin Associate%(l.N)38099E7D0190.statements preserve=no pragma Assert (This_Handle /= null); pragma Assert (Temp_Array_Of_Handle'Length > 0); for I in Temp_Array_Of_Handle'Range loop pragma Assert (Temp_Array_Of_Handle (I).The_Course = null or else Temp_Array_Of_Handle (I).The_Course - This_Handle); Temp_Array_Of_Handle (I).The_Course := This_Handle; end loop; Set (This_Handle.The_CourseOffering. Temp_Array_Of_Handle); --##end Associate%(1,N)38099E7D0190.statements end Associate; procedure Dissociate (This : in Handle) is --##begin Dissociate«38099E7D0190.declarations preserve=yes --##end Dissociate«38099E7D0190.declarations begin --##begin Dissociate%38099E7D0190.statements preserve=no pragma Assert (This /= null); for I in This.The_CourseOffering'Range loop if This.The_CourseOffering (I) /= null then if This.The_CourseOffering (I).The_Course = This then This.The_CourseOffering (I).The_Course := null; This.The_CourseOffering (I) := null; end if; end if; end loop; --##end Dissociate%38099E7D0190.statements end Dissociate; procedure Dissociate (This := in Handle) is --##begin Dissociate%38099E7D0190.declarations preserve=yes --##end Dissociate%38099E7D0190.declarations begin --##begin Dissociate%38099E7D0190.statements preserve=no pragma Assert (This /= null): for I in This.The_Course.The_CourseOffering'Range loop if This.The_Course.The_CourseOffering (I) = This then This.The_Course.The_CourseOffering (I) :=null; This.The_Course ;=null; exit: end if; end loop; --##end Dissociat%38099E7D0190.statements end Dissociate; procedure Dissociate (This : in Array_Of_Handle) is --##begin Dissociate%(M)38099E7D0190.declarations preserve=yes --##end Dissociate%(M)38099E7D0190.declarations begin --##begin Dissociate%(M)38099E7D0190.statements preserve=no for I in This'Range loop if This (I) /= null then Dissociate (This (I)); end if; end loop; --##end Dissociate%(M)38099E7D0190.statements end Dissociate; --##begin module.additionalDeclarations preserve=yes --##end module.additionalDec!arations begin --##begin module.statements preserve=no null; --##end module.statements end CourseOffering; Отметим, что в теле есть стандартные методы, которые не задавались в модели, — например, методы constructor, destructor и get/set. Их автоматическая генерация была задана настройкой среды — свойствами генерации. Система обеспечивает настройку параметров генерации для уровней класса, роли, свойства (атрибута) и проекта в целом. Более подробную информацию о свойствах генерации кода можно получить из help-файла. Организация процесса конструированияВ этой главе определяются базовые понятия технологии конструирования программного обеспечения. Как и в любой инженерной дисциплине, основными составляющими технологии конструирования ПО являются продукты (программные системы) и процессы, обеспечивающие создание продуктов. Данная глава посвящена процессам. Здесь рассматриваются основные подходы к организации процесса конструирования. В главе приводятся примеры классических, современных и перспективных процессов конструирования, обсуждаются модели качества процессов конструирования.
Руководство программным проектомВ этой главе детально рассматривается такой элемент процесса конструирования ПО, как руководство программным проектом. Читатель знакомится с вопросами планирования проекта, оценки затрат проекта. В данной главе обсуждаются размерно-ориентированные и функционально-ориентированные метрики затрат, методика их применения. Достаточно подробно описывается наиболее популярная модель для оценивания затрат — СОСОМО II. В качестве иллюстраций приводятся примеры предварительного оценивания проекта, анализа влияния на проект конкретных условий разработки.
Классические методы анализаВ этой главе рассматриваются классические методы анализа требований, ориентированные на процедурную реализацию программных систем. Анализ требований служит мостом между неформальным описанием требований, выполняемым заказчиком, и проектированием системы. Методы анализа призваны формализовать обязанности системы, фактически их применение дает ответ на вопрос: что должна делать будущая система?
Основы проектирования программных системВ этой главе рассматривается содержание этапа проектирования и его место в жизненном цикле конструирования программных систем. Дается обзор архитектурных моделей ПО, обсуждаются классические проектные характеристики: модульность, информационная закрытость, сложность, связность, сцепление и метрики для их оценки.
Классические методы проектированияВ этой главе рассматриваются классические методы проектирования, ориентированные на процедурную реализацию программных систем (ПС). Повторим, что эти методы появились в период революции структурного программирования. Учитывая, что на современном этапе программной инженерии процедурно-ориентированные ПС имеют преимущественно историческое значение, конспективно обсуждаются только два (наиболее популярных) метода: метод структурного проектирования и метод проектирования Майкла Джексона (этот Джексон не имеет никакого отношения к известному певцу). Зачем мы это делаем? Да чтобы знать исторические корни современных методов проектирования.
Структурное тестирование программного обеспеченияВ этой главе определяются общие понятия и принципы тестирования ПО (принцип «черного ящика» и принцип «белого ящика»). Читатель знакомится с содержанием процесса тестирования, после этого его внимание концентрируется на особенностях структурного тестирования программного обеспечения (по принципу «белого ящика»), описываются его достоинства и недостатки. Далее рассматриваются наиболее популярные способы структурного тестирования: тестирование базового пути, тестирование ветвей и операторов отношений, тестирование потоков данных, тестирование циклов.
Функциональное тестирование программного обеспеченияВ этой главе продолжается обсуждение вопросов тестирования ПО на уровне программных модулей. Впрочем, рассматриваемое здесь функциональное тестирование, основанное на принципе «черного ящика», может применяться и на уровне программной системы. После определения особенностей тестирования черного ящика в главе описываются популярные способы тестирования: разбиение по классам эквивалентности, анализ граничных значений, тестирование на основе диаграмм причин-следствий.
Организация процесса тестирования программного обеспеченияВ этой главе излагаются вопросы, связанные с проведением тестирования на всех этапах конструирования программной системы. Классический процесс тестирования обеспечивает проверку результатов, полученных на каждом этапе разработки. Как правило, он начинается с тестирования в малом, когда проверяются программные модули, продолжается при проверке объединения модулей в систему и завершается тестированием в большом, при котором проверяются соответствие программного продукта требованиям заказчика и его взаимодействие с другими компонентами компьютерной системы. Данная глава последовательно описывает содержание каждого шага тестирования. Здесь же рассматривается организация отладки ПО, которая проводится для устранения выявленных при тестировании ошибок.
Основы объектно-ориентированного представления программных системДевятая глава вводит в круг вопросов объектно-ориентированного представления программных систем. В этой главе рассматриваются: абстрагирование понятий проблемной области, приводящее к формированию классов; инкапсуляция объектов, обеспечивающая скрытность их характеристик; модульность как средство упаковки набора классов; особенности построения иерархической структуры объектно-ориентированных систем. Последовательно обсуждаются объекты и классы как основные строительные элементы объектно-ориентированного ПО. Значительное внимание уделяется описанию отношений между объектами и классами.
Базис языка визуального моделированияДля создания моделей анализа и проектирования объектно-ориентированных программных систем используют языки визуального моделирования. Появившись сравнительно недавно, в период с 1989 по 1997 год, эти языки уже имеют представительную историю развития. В настоящее время различают три поколения языков визуального моделирования. И если первое поколение образовали 10 языков, то численность второго поколения уже превысила 50 языков. Среди наиболее популярных языков 2-го поколения можно выделить: язык Буча (G. Booch), язык Рамбо (J. Rumbaugh), язык Джекобсона (I. Jacobson), язык Коада-Йордона (Coad-Yourdon), язык Шлеера-Меллора (Shlaer-Mellor) и т. д [41], [64], [69]. Каждый язык вводил свои выразительные средства, ориентировался на собственный синтаксис и семантику, иными словами — претендовал на роль единственного и неповторимого языка. В результате разработчики (и пользователи этих языков) перестали понимать друг друга. Возникла острая необходимость унификации языков. Идея унификации привела к появлению языков 3-го поколения. В качестве стандартного языка третьего поколения был принят Unified Modeling Language (UML), создававшийся в 1994-1997 годах (основные разработчики — три «amigos» Г. Буч, Дж. Рамбо, И. Джекобсон). В настоящее время разработана версия UML 1.4, которая описывается в данном учебнике [53]. Данная глава посвящена определению базовых понятий языка UML.
Статические модели объектно-ориентированных программных системСтатические модели обеспечивают представление структуры систем в терминах базовых строительных блоков и отношений между ними. «Статичность» этих моделей состоит в том, что здесь не показывается динамика изменений системы во времени. Вместе с тем следует понимать, что эти модели несут в себе не только структурные описания, но и описания операций, реализующих заданное поведение системы. Основным средством для представления статических моделей являются диаграммы классов [8], [23], [53], [67]. Вершины диаграмм классов нагружены классами, а дуги (ребра) — отношениями между ними. Диаграммы используются: q в ходе анализа — для указания ролей и обязанностей сущностей, которые обеспечивают поведение системы; q в ходе проектирования — для фиксации структуры классов, которые формируют системную архитектуру.
Динамические модели объектно-ориентированных программных системДинамические модели обеспечивают представление поведения систем. «Динамизм» этих моделей состоит в том, что в них отражается изменение состояний в процессе работы системы (в зависимости от времени). Средства языка UML для создания динамических моделей многочисленны и разнообразны [8], [23], [41], [53], [67]. Эти средства ориентированы не только на собственно программные системы, но и на отображение требований заказчика к поведению таких систем.
Модели реализации объектно-ориентированных программных системСтатические и динамические модели описывают логическую организацию системы, отражают логический мир программного приложения. Модели реализации обеспечивают представление системы в физическом мире, рассматривая вопросы упаковки логических элементов в компоненты и размещения компонентов в аппаратных узлах [8], [23], [53], [67].
Метрики объектно-ориентированных программных системПри конструировании объектно-ориентированных программных систем значительная часть затрат приходится на создание визуальных моделей. Очень важно корректно и всесторонне оценить качество этих моделей, сопоставив качеству числовую оценку. Решение данной задачи требует введения специального метрического аппарата. Такой аппарат развивает идеи классического оценивания сложных программных систем, основанного на метриках сложности, связности и сцепления. Вместе с тем он учитывает специфические особенности объектно-ориентированных решений. В этой главе обсуждаются наиболее известные объектно-ориентированные метрики, а также описывается методика их применения.
Унифицированный процесс разработки объектно-ориентированных ПСВ первой главе рассматривались основы организации процессов разработки ПО. В данной главе внимание сосредоточено на детальном обсуждении унифицированного процесса разработки объектно-ориентированного ПО, на базе которого возможно построение самых разнообразных схем конструирования программных приложений. Далее описывается содержание ХР-процесса экстремальной разработки, являющегося носителем адаптивной технологии, применяемой в условиях частого изменения требований заказчика.
Объектно-ориентированное тестированиеНеобходимость и важность тестирования ПО трудно переоценить. Вместе с тем следует отметить, что тестирование является сложной и трудоемкой деятельностью. Об этом свидетельствует содержание глав 6, 7 и 8 глав, в которых описывались классические основы тестирования, разработанные в расчете (в основном) на процедурное ПО. В этой главе рассматриваются вопросы объектно-ориентированного тестирования [17], [18], [42], [50], [51]. Существует мнение, что объектно-ориентированное тестирование мало чем отличается от процедурно-ориентированного тестирования. Конечно, многие понятия, подходы и способы тестирования у них общие, но в целом это мнение ошибочно. Напротив, особенности объектно-ориентированных систем должны вносить и вносят существенные изменения как в последовательность этапов, так и в содержание этапов тестирования. Сгруппируем эти изменения по трем направлениям: q расширение области применения тестирования; q изменение методики тестирования; q учет особенностей объектно-ориентированного ПО при проектировании тестовых вариантов. Обсудим каждое из выделенных направлений отдельно.
Автоматизация конструирования визуальной модели программной системыВ современных условиях создание сложных программных приложений невозможно без использования систем автоматизированного конструирования ПО (CASE-систем). CASE-системы существенно сокращают сроки и затраты разработки, оказывая помощь инженеру в проведении рутинных операций, облегчая его работу на самых разных этапах жизненного цикла разработки. Наиболее известной объектно-ориентированной CASE-системой является Rational Rose. В данной главе рассматривается порядок применения Rational Rose при формировании требований, анализе, проектировании и генерации программного кода.
Главный потокЭтот элемент Use Case начинается, когда покупатель регистрируется в системе и вводит свой пароль. Система проверяет, правилен ли пароль (Е-1), и предлагает покупателю выбрать одно из действий: СОЗДАТЬ, УДАЛИТЬ, ПРОВЕРИТЬ, ВЫПОЛНИТЬ, ВЫХОД. 1. Если выбрано действие СОЗДАТЬ, выполняется подпоток S-1: создать заказ авиабилета. 2. Если выбрано действие УДАЛИТЬ, выполняется подпоток S-2: удалить заказ авиабилета. 3. Если выбрано действие ПРОВЕРИТЬ, выполняется подпоток S-3: проверить заказ авиабилета. 4. Если выбрано действие ВЫПОЛНИТЬ, выполняется подпоток S-4: реализовать заказ авиабилета. 5. Если выбрано действие ВЫХОД, элемент Use Case заканчивается.
Характеристики иерархической структуры программной системыИерархическая структура программной системы — основной результат предварительного проектирования. Она определяет состав модулей ПС и управляющие отношения между модулями. В этой структуре модуль более высокого уровня (начальник) управляет модулем нижнего уровня (подчиненным). Иерархическая структура не отражает процедурные особенности программной системы, то есть последовательность операций, их повторение, ветвления и т. д. Рассмотрим основные характеристики иерархической структуры, представленной на рис. 4.17.  Рис. 4.17. Иерархическая структура программной системы Первичными характеристиками являются количество вершин (модулей) и количество ребер (связей между модулями). К ним добавляются две глобальные характеристики — высота и ширина: q высота — количество уровней управления; q ширина — максимальное из количеств модулей, размещенных на уровнях управления. В нашем примере высота = 4, ширина = 6. Локальными характеристиками модулей структуры являются коэффициент объединения по входу и коэффициент разветвления по выходу. Коэффициент объединения по входу Fan_in(i) — это количество модулей, которые прямо управляют i-м модулем. В примере для модуля n: Fan_in(n)=4. Коэффициент разветвления по выходу Fan_out(i) — это количество модулей, которыми прямо управляет i-й модуль. В примере для модуля m: Fan_out(m)=3. Возникает вопрос: как оценить качество структуры? Из практики проектирования известно, что лучшее решение обеспечивается иерархической структурой в виде дерева. Степень отличия реальной проектной структуры от дерева характеризуется невязкой структуры. Как определить невязку? Вспомним, что полный граф (complete graph) с п вершинами имеет количество ребер ес=n(n-1)/2, а дерево (tree) с таким же количеством вершин — существенно меньшее количество ребер et=n-l. Тогда формулу невязки можно построить, сравнивая количество ребер полного графа, реального графа и дерева. Для проектной структуры с п вершинами и е ребрами невязка определяется по выражению  Значение невязки лежит в диапазоне от 0 до 1. Если Nev = 0, то проектная структура является деревом, если Nev = 1, то проектная структура — полный граф. Ясно, что невязка дает грубую оценку структуры. Для увеличения точности оценки следует применить характеристики связности и сцепления. Хорошая структура должна иметь низкое сцепление и высокую связность. Л. Констентайн и Э. Йордан (1979) предложили оценивать структуру с помощью коэффициентов Fan_in(i) и Fan_out(i) модулей [77]. Большое значение Fan_in(i) — свидетельство высокого сцепления, так как является мерой зависимости модуля. Большое значение Fan_out(i) говорит о высокой сложности вызывающего модуля. Причиной является то, что для координации подчиненных модулей требуется сложная логика управления. Основной недостаток коэффициентов Fan_in(i) и Fan_out(i) состоит в игнорировании веса связи. Здесь рассматриваются только управляющие потоки (вызовы модулей). В то же время информационные потоки, нагружающие ребра структуры, могут существенно изменяться, поэтому нужна мера, которая учитывает не только количество ребер, но и количество информации, проходящей через них. С. Генри и Д. Кафура (1981) ввели информационные коэффициенты ifan_in(i) и ifan_out(j) [35]. Они учитывают количество элементов и структур данных, из которых i-й модуль берет информацию и которые обновляются j-м модулем соответственно. Информационные коэффициенты суммируются со структурными коэффициентами sfan_in(i) и sfan_out( j), которые учитывают только вызовы модулей. В результате формируются полные значения коэффициентов: Fan_in (i) = sfan_in (i) + ifan_in (i), Fan_out (j) = sfan_out (j) + ifan_out (j). На основе полных коэффициентов модулей вычисляется метрика общей сложности структуры: S =  где length(i) — оценка размера i-го модуля (в виде LOC- или FP-оценки). ХР-итерацияСтруктура ХР-итерации показана на рис. 15.17. Организация итерации придает ХР-процессу динамизм, требуемый для обеспечения готовности разработчиков к постоянным изменениям в проекте. Не следует выполнять долгосрочное планирование. Вместо этого выполняется краткосрочное планирование в начале каждой итерации. Не стоит пытаться работать с незапланированными задачами — до них дойдет очередь в соответствии с планом реализации. Привыкнув не добавлять функциональность заранее и использовать краткосрочное планирование, разработчики смогут легко приспосабливаться к изменению требований заказчика. Цель планирования, с которого начинается итерация — выработать план решения программных задач. Каждая итерация должна длиться от одной до трех недель. Пользовательские истории внутри итерации сортируются в порядке их значимости для заказчика. Кроме того, добавляются задачи, которые не смогли пройти предыдущие тесты приемки и требуют доработки. Пользовательским историям и тестам с отказом в приемке сопоставляются задачи программирования. Задачи записываются на карточках, совокупность карточек образует детальный план итерации.  Рис. 15.17. Структура ХР-итерации Для решения каждой из задач требуется от одного до трех дней. Задачи, для которых нужно менее одного дня, группируются вместе, а большие задачи разбивают на более мелкие задачи. Разработчики оценивают количество и длительность задач. Для определения фиксированной длительности итерации используют метрику «скорость проекта», вычисленную по предыдущей итерации (количество завершенных в ней задач/дней программирования). Если предполагаемая скорость превышает предыдущую скорость, заказчик выбирает истории, которые следует отложить до более поздней итерации. Если итерация слишком мала, к разработке принимается дополнительная история. Вполне допустимая практика — переоценка историй и пересмотр плана реализации после каждых трех или пяти итераций. Первоочередная реализация наиболее важных историй — гарантия того, что для клиента делается максимум возможного. Стиль разработки, основанный на последовательности итераций, улучшает подвижность процесса разработки. В каждую ХР-итерацию многократно вкладывается строительный элемент — элемент ХР-разработки. Рассмотрим организацию элемента ХР-разработки.
ХР-процессЭкстремальное программирование (eXtreme Programming, XP) — облегченный (подвижный) процесс (или методология), главный автор которого — Кент Бек (1999) [11]. ХР-процесс ориентирован на группы малого и среднего размера, строящие программное обеспечение в условиях неопределенных или быстро изменяющихся требований. ХР-группу образуют до 10 сотрудников, которые размещаются в одном помещении. Основная идея ХР — устранить высокую стоимость изменения, характерную для приложений с использованием объектов, паттернов* и реляционных баз данных. Поэтому ХР-процесс должен быть высокодинамичным процессом. ХР-группа имеет дело с изменениями требований на всем протяжении итерационного цикла разработки, причем цикл состоит из очень коротких итераций. Четырьмя базовыми действиями в ХР-цикле являются: кодирование, тестирование, выслушивание заказчика и проектирование. Динамизм обеспечивается с помощью четырех характеристик: непрерывной связи с заказчиком (и в пределах группы), простоты (всегда выбирается минимальное решение), быстрой обратной связи (с помощью модульного и функционального тестирования), смелости в проведении профилактики возможных проблем. * Паттерн является решением типичной проблемы в определенном контексте. Большинство принципов, поддерживаемых в ХР (минимальность, простота, эволюционный цикл разработки, малая длительность итерации, участие пользователя, оптимальные стандарты кодирования и т. д.), продиктованы здравым смыслом и применяются в любом упорядоченном процессе. Просто в ХР эти принципы, как показано в табл. 1.2, достигают «экстремальных значений».
Таблица 1.2. Экстремумы в экстремальном программировании
Тот, кто принимает принцип « минимального решения» за хакерство, ошибается, в действительности ХР — строго упорядоченный процесс. Простые решения, имеющие высший приоритет, в настоящее время рассматриваются как наиболее ценные части системы, в отличие от проектных решений, которые пока не нужны, а могут (в условиях изменения требований и операционной среды) и вообще не понадобиться. Базис ХР образуют перечисленные ниже двенадцать методов. 1. Игра планирования (Planning game) — быстрое определение области действия следующей реализации путем объединения деловых приоритетов и технических оценок. Заказчик формирует область действия, приоритетность и сроки с точки зрения бизнеса, а разработчики оценивают и прослеживают продвижение (прогресс). 2. Частая смена версий (Small releases) — быстрый запуск в производство простой системы. Новые версии реализуются в очень коротком (двухнедельном) цикле. 3. Метафора (Metaphor) — вся разработка проводится на основе простой, общедоступной истории о том, как работает вся система. 4. Простое проектирование (Simple design) — проектирование выполняется настолько просто, насколько это возможно в данный момент. 5. Тестирование (Testing) — непрерывное написание тестов для модулей, которые должны выполняться безупречно; заказчики пишут тесты для демонстрации законченности функций. «Тестируй, а затем кодируй» означает, что входным критерием для написания кода является «отказавший» тестовый вариант. 6. Реорганизация (Refactoring) — система реструктурируется, но ее поведение не изменяется; цель — устранить дублирование, улучшить взаимодействие, упростить систему или добавить в нее гибкость. 7. Парное программирование (Pair programming) — весь код пишется двумя программистами, работающими на одном компьютере. 8. Коллективное владение кодом (Collective ownership) — любой разработчик может улучшать любой код системы в любое время. 9. Непрерывная интеграция (Continuous integration) — система интегрируется и строится много раз в день, по мере завершения каждой задачи. Непрерывное регрессионное тестирование, то есть повторение предыдущих тестов, гарантирует, что изменения требований не приведут к регрессу функциональности. 10. 40-часовая неделя (40-hour week) — как правило, работают не более 40 часов в неделю. Нельзя удваивать рабочую неделю за счет сверхурочных работ. 11. Локальный заказчик (On-site customer) — в группе все время должен находиться представитель заказчика, действительно готовый отвечать на вопросы разработчиков. 12. Стандарты кодирования (Coding standards) — должны выдерживаться правила, обеспечивающие одинаковое представление программного кода во всех частях программной системы. Игра планирования и частая смена версий зависят от заказчика, обеспечивающего набор «историй» (коротких описаний), характеризующих работу, которая будет выполняться для каждой версии системы. Версии генерируются каждые две недели, поэтому разработчики и заказчик должны прийти к соглашению о том, какие истории будут осуществлены в пределах двух недель. Полную функциональность, требуемую заказчику, характеризует пул историй; но для следующей двухнедельной итерации из пула выбирается подмножество историй, наиболее важное для заказчика. В любое время в пул могут быть добавлены новые истории, таким образом, требования могут быстро изменяться. Однако процессы двухнедельной генерации основаны на наиболее важных функциях, входящих в текущий пул, следовательно, изменчивость управляется. Локальный заказчик обеспечивает поддержку этого стиля итерационной разработки. «Метафора» обеспечивает глобальное «видение» проекта. Она могла бы рассматриваться как высокоуровневая архитектура, но ХР подчеркивает желательность проектирования при минимизации проектной документации. Точнее говоря, ХР предлагает непрерывное перепроектирование (с помощью реорганизации), при котором нет нужды в детализированной проектной документации, а для инженеров сопровождения единственным надежным источником информации является программный код. Обычно после написания кода проектная документация выбрасывается. Проектная документация сохраняется только в том случае, когда заказчик временно теряет способность придумывать новые истории. Тогда систему помещают в «нафталин» и пишут руководство страниц на пять-десять по «нафталиновому» варианту системы. Использование реорганизации приводит к реализации простейшего решения, удовлетворяющего текущую потребность. Изменения в требованиях заставляют отказываться от всех «общих решений». Парное программирование — один из наиболее спорных методов в ХР, оно влияет на ресурсы, что важно для менеджеров, решающих, будет ли проект использовать ХР. Может показаться, что парное программирование удваивает ресурсы, но исследования доказали: парное программирование приводит к повышению качества и уменьшению времени цикла. Для согласованной группы затраты увеличиваются на 15%, а время цикла сокращается на 40-50%. Для Интернет-среды увеличение скорости продаж покрывает повышение затрат. Сотрудничество улучшает процесс решения проблем, улучшение качества существенно снижает затраты сопровождения, которые превышают стоимость дополнительных ресурсов по всему циклу разработки. Коллективное владение означает, что любой разработчик может изменять любой фрагмент кода системы в любое время. Непрерывная интеграция, непрерывное регрессионное тестирование и парное программирование ХР обеспечивают защиту от возникающих при этом проблем. «Тестируй, а затем кодируй» — эта фраза выражает акцент ХР на тестировании. Она отражает принцип, по которому сначала планируется тестирование, а тестовые варианты разрабатываются параллельно анализу требований, хотя традиционный подход состоит в тестировании «черного ящика». Размышление о тестировании в начале цикла жизни — хорошо известная практика конструирования ПО (правда, редко осуществляемая практически). Основным средством управления ХР является метрика, а среда метрик — «большая визуальная диаграмма». Обычно используют 3-4 метрики, причем такие, которые видимы всей группе. Рекомендуемой в ХР метрикой является «скорость проекта» — количество историй заданного размера, которые могут быть реализованы в итерации. При принятии ХР рекомендуется осваивать его методы по одному, каждый раз выбирая метод, ориентированный на самую трудную проблему группы. Конечно, все эти методы являются «не более чем правилами» — группа может в любой момент поменять их (если ее сотрудники достигли принципиального соглашения по поводу внесенных изменений). Защитники ХР признают, что ХР оказывает сильное социальное воздействие, и не каждый может принять его. Вместе с тем, ХР — это методология, обеспечивающая преимущества только при использовании законченного набора базовых методов. Рассмотрим структуру «идеального» ХР-процесса. Основным структурным элементом процесса является ХР-реализация, в которую многократно вкладывается базовый элемент — ХР-итерация. В состав ХР-реализации и ХР-итерации входят три фазы — исследование, блокировка, регулирование. Исследование (exploration) — это поиск новых требований (историй, задач), которые должна выполнять система. Блокировка (commitment) — выбор для реализации конкретного подмножества из всех возможных требований (иными словами, планирование). Регулирование (steering) — проведение разработки, воплощение плана в жизнь. ХР рекомендует: первая реализация должна иметь длительность 2-6 месяцев, продолжительность остальных реализаций — около двух месяцев, каждая итерация длится приблизительно две недели, а численность группы разработчиков не превышает 10 человек. ХР-процесс для проекта с семью реализациями, осуществляемый за 15 месяцев, показан на рис. 1.8. Процесс инициируется начальной исследовательской фазой. Фаза исследования, с которой начинается любая реализация и итерация, имеет клапан «пропуска», на этой фазе принимается решение о целесообразности дальнейшего продолжения работы. Предполагается, что длительность первой реализации составляет 3 месяца, длительность второй — седьмой реализаций — 2 месяца. Вторая — седьмая реализации образуют период сопровождения, характеризующий природу ХР-проекта. Каждая итерация длится две недели, за исключением тех, которые относят к поздней стадии реализации — «запуску в производство» (в это время темп итерации ускоряется). Наиболее трудна первая реализация — пройти за три месяца от обычного старта (скажем, отдельный сотрудник не зафиксировал никаких требований, не определены ограничения) к поставке заказчику системы промышленного качества очень сложно.  Рис. 1.8. Идеальный ХР-процесс ХР-реализацияСтруктура ХР-реализации показана на рис. 15.16. Исходные требования к продукту фиксируются с помощью пользовательских историй. Истории позволяют оценить время, необходимое для разработки продукта. Они записываются заказчиком и задают действия, которые должна выполнять для него программная система. Каждая история занимает три-четыре текстовых предложения в терминах заказчика. Кроме того, истории служат для создания тестов приемки. Тесты приемки используют для проверки правильности, реализации пользовательских историй.  Рис. 15.16. Структура ХР-реализации Очень часто истории путают с традиционными требованиями к системе. Самое важное отличие состоит в уровне детализации. Истории обеспечивают только такие детали, которые необходимы для оценки времени их реализации (с минимальным риском). Когда наступит время реализовать историю, разработчики получают у заказчика более детальное описание требований. Каждая история получает оценку идеальной длительности — одну, две или три недели разработки (время, за которое история может быть реализована при отсутствии других работ). Если срок превышает три недели, историю следует разбить на несколько частей. При длительности менее недели нужно объединить несколько историй. Другое отличие истории от требований — во главу угла ставятся желания заказчика. В историях следует избегать описания технических подробностей, таких как организация баз данных или описания алгоритмов. Если разработчики не знают, как оценить историю, они создают выброс — быстрое решение, содержащее ответ на трудные вопросы. Выброс — минимальное решение, выполняемое в черновом коде и впоследствии выбрасываемое. Результат выброса — знание, достаточное для оценивания. Итогом архитектурного выброса является создание метафоры системы. Метафора системы определяет ее состав и именование элементов. Она позволяет удержать команду разработчиков в одних и тех же рамках при именовании классов, методов, объектов. Это очень важно для понимания общего проекта системы и повторного использования кодов.
Идентификация рискаВ результате идентификации формируется список элементов риска, специфичных для данного проекта. Выделяют три категории источников риска: проектный риск, технический риск, коммерческий риск. Источниками проектного риска являются: q выбор бюджета, плана, человеческих ресурсов программного проекта; q формирование требований к программному продукту; q сложность, размер и структура программного проекта; q методика взаимодействия с заказчиком. К источникам технического риска относят: q трудности проектирования, реализации, формирования интерфейса, тестирования и сопровождения; q неточность спецификаций; q техническая неопределенность или отсталость принятого решения. Главная причина технического риска — реальная сложность проблем выше предполагаемой сложности. Источники коммерческого риска включают: q создание продукта, не требующегося на рынке; q создание продукта, опережающего требования рынка (отстающего от них); q потерю финансирования. Лучший способ идентификации — использование проверочных списков риска, которые помогают выявить возможный риск. Например, проверочный список десяти главных элементов программного риска может иметь представленный ниже вид. 1. Дефицит персонала. 2. Нереальные расписание и бюджет. 3. Разработка неправильных функций и характеристик. 4. Разработка неправильного пользовательского интерфейса. 5. Слишком дорогое обрамление. 6. Интенсивный поток изменения требований. 7. Дефицит поставляемых компонентов. 8. Недостатки в задачах, разрабатываемых смежниками. 9. Дефицит производительности при работе в реальном времени. 10. Деформирование научных возможностей. На практике каждый элемент списка снабжается комментарием — набором методик для предотвращения источника риска. После идентификации элементов риска следует количественно оценить их влияние на программный проект, решить вопросы о возможных потерях. Эти вопросы решаются на шаге анализа риска.
IDL-описаниеи библиотека типаПомимо информации об интерфейсах, IDL-описание может содержать информацию о библиотеке типа. Библиотека типа определяет важные для клиента характеристики СОМ-объекта: имя его класса, поддерживаемые интерфейсы, имена и адреса элементов интерфейса. Рассмотрим пример приведенного ниже IDL-описания объекта для работы с файлами. Оно состоит из 3 частей. Первые две части описывают интерфейсы IРаботаСФайлами и IПреобразованиеФорматов, третья часть— библиотеку типа ФайлыБибл. По первым двум частям компилятор MIDL генерирует код посредников и заглушек, по третьей части — код библиотеки типа: -----------1-я часть [ object, uuid(E7CDODOO-1827-11CF-9946-444553540000) ] interface IРаботаСФайлами; IUnknown { import "unknown.idl" HRESULT ОткрытьФайл ([in] OLECHAR имя[31]); HRESULT ЗаписатьФайл ([in] OLECHAR имя[31]); HRESULT ЗакрытьФайл ([in] OLECHAR имя[31]); } ----------- 2-я часть [ object. uuid(5FBDD020-1863-11CF-9946-444553540000) ] interface IПреобразованиеФорматов: IUnknown { HRESULT ПреобразоватьФормат ([in] OLECHAR имя[31], [in] OLECHAR формат[31]); } ------------ 3-я часть [ uuid(B253E460-1826-11CF-9946-444553540000), version (1.0)] library ФайлыБибл { importlib ("stdole32.tlb"); [uuid(B2ECFAAO-1827-11CF-9946-444553540000) ] coclass СоФайлы { interface IРаботаСФайлами; interface IпреобразованиеФорматов; } } Описание библиотеки типа начинается с ее уникального имени (записывается после служебного слова uuid), затем указывается номер версии библиотеки. После служебного слова library записывается символьное имя библиотеки (ФайлыБибл). Далее в операторе importlib указывается файл со стандартными определениями IDL - stdole32.tlb. Тело описания библиотеки включает только один элемент — СОМ-класс (coclass), на основе которого создается СОМ-объект. В начале описания СОМ-класса приводится его уникальное имя (это и есть идентификатор класса — CLSID), затем символьное имя — СоФайлы. В теле класса перечислены имена поддерживаемых интерфейсов — РаботаСФайлами и IПреобразованиеФорматов. Как показано на рис. 13.24, доступ к библиотеке типа выполняется по стандартному интерфейсу ITypeLib, а доступ к отдельным элементам библиотеки — по интерфейсу ITypelnfo.  Рис. 13.24. Доступ к библиотеке типа
Иерархическая организацияМы рассмотрели три механизма для борьбы со сложностью: q абстракцию (она упрощает представление физического объекта); q инкапсуляцию (закрывает детали внутреннего представления абстракций); q модульность (дает путь группировки логически связанных абстракций). Прекрасным дополнением к этим механизмам является иерархическая организация — формирование из абстракций иерархической структуры. Определением иерархии в проекте упрощаются понимание проблем заказчика и их реализация — сложная система становится обозримой человеком. Иерархическая организация задает размещение абстракций на различных уровнях описания системы. Двумя важными инструментами иерархической организации в объектно-ориентированных системах являются: q структура из классов («is a»-иерархия); q структура из объектов («part of»-иерархия). Чаще всего «is а»-иерархическая структура строится с помощью наследования. Наследование определяет отношение между классами, где класс разделяет структуру или поведение, определенные в одном другом (единичное наследование) или в нескольких других (множественное наследование) классах. Пример: положим, что программа управления полетом 2-й ступени ракеты-носителя в основном похожа на программу управления полетом 1-й ступени, но все же отличается от нее. Определим класс управления полетом 2-й ступени, который инкапсулирует ее специализированное поведение: with Класс_УпрПолетом1; use Класс_УпрПолетом1; Package Класс_УпрПолетом2 is type Траектория is (Гибкая. Свободная); type УпрПолетом2 is new УпрПолетом1 with private; procedure Установиться: in out УпрПолетом2: тип: Траектория; ориентация : Углы; параметры: Координаты_Скорость; команды: График); procedure УсловияОтделенияЗступени (the: УпрПолетом2; критерий:КритерийОтделения); function ПрогнозОтделенияЗступени (the: УпрПолетом2) return БортовоеВремя; function ИсполнениеКоманд(the: УпрПолетом2) return Boolean; private type УпрПолетом2 is new УпрПолетом1 with record типТраектории: Траектория; доОтделения: БортовоеВремя; выполнениеКоманд: Boolean; end record; end Класс_УпрПолетом2; Видим, что класс УпрПолетом2 — это «is а»-разновидность класса УпрПолетом1, который называется родительским классом или суперклассом. В класс УпрПолетом2 добавлены: q авспомогательный тип Траектория; q три новых свойства (типТраектории, доОтделения, выполнениеКоманд); q три новых метода (УсловияОтделенияЗступени, ПрогнозОтделенияЗступени, ИсполнениеКоманд). Кроме того, в классе УпрПолетом2 переопределен метод суперкласса Установить. Подразумевается, что в наследство классу УпрПолетом2 достался набор методов и свойств класса УпрПолетом1. В частности, тип УпрПолетом2 включает поля типа УпрПолетом1, обеспечивающие прием данных о координатах и скорости ракеты-носителя, ее угловой ориентации и графике выдаваемых команд, а также о критерии отделения следующей ступени. Классы УпрПолетом1и УпрПолетом2 образуют наследственную иерархическую организацию. В ней общая часть структуры и поведения сосредоточены в верхнем, наиболее общем классе (суперклассе). Суперкласс соответствует общей абстракции, а подкласс — специализированной абстракции, в которой элементы суперкласса дополняются, изменяются и даже скрываются. Поэтому наследование часто называют отношением обобщение-специализация. Иерархию наследования можно продолжить. Например, используя класс УпрПолетом2, можно объявить еще более специализированный подкласс — УпрПолетомКосмическогоАппарата. Другая разновидность иерархической организации — «part of»-иерархическая структура — базируется на отношении агрегации. Агрегация не является понятием, уникальным для объектно-ориентированных систем. Например, любой язык программирования, разрешающий структуры типа «запись», поддерживает агрегацию. И все же агрегация особенно полезна в сочетании с наследованием: 1) агрегация обеспечивает физическую группировку логически связанной структуры; 2) наследование позволяет легко и многократно использовать эти общие группы в других абстракциях. Приведем пример класса ИзмерительСУ (измеритель системы управления ЛА): with Класс_НастройкаДатчиков. Класс_Датчик; use Класс_НастройкаДатчиков, Класс_Датчик; Package Класс_ИзмерительСУ is type ИзмерительСУ is tagged private; -- описание методов private type укз_наДатчик is access all Датчик'Class; type ИзмерительСУ is record датчики: array(1..30) of укз_наДатчик; процедураНастройки: НастройкаДатчиков; end record; end Класс_ИзмерительСУ; Очевидно, что объекты типа ИзмерительСУ являются агрегатами, состоящими из массива датчиков и процедуры настройки. Наша абстракция ИзмерительСУ позволяет использовать в системе управления различные датчики. Изменение датчика не меняет индивидуальности измерителя в целом. Ведь датчики вводятся в агрегат с помощью указателей, а не величин. Таким образом, объект типа ИзмерительСУ и объекты типа Датчик имеют относительную независимость. Например, время жизни измерителя и датчиков независимо друг от друга. Напротив, объект типа НастройкаДатчиков физически включается в объект типа ИзмерительСУ и независимо существовать не может. Отсюда вывод — разрушая объект типа ИзмерительСУ, мы, в свою очередь, разрушаем экземпляр НастройкиДатчиков. Интересно сравнить элементы иерархий наследования и агрегации с точки зрения уровня сложности. При наследовании нижний элемент иерархии (подкласс) имеет больший уровень сложности (большие возможности), при агрегации — наоборот (агрегат ИзмерительСУ обладает большими возможностями, чем его элементы — датчики и процедура настройки). Информационная связностьПри информационной (последовательной) связности элементы-обработчики модуля образуют конвейер для обработки данных — результаты одного обработчика используются как исходные данные для следующего обработчика. Приведем пример: Модуль Прием и проверка записи прочитать запись из файла проверить контрольные данные в записи удалить контрольные поля в записи вернуть обработанную запись Конец модуля В этом модуле 3 элемента. Результаты первого элемента (прочитать запись из файла) используются как входные данные для второго элемента (проверить контрольные данные в записи) и т. д. Сопровождать модули с информационной связностью почти так же легко, как и функционально связные модули. Правда, возможности повторного использования здесь ниже, чем в случае функциональной связности. Причина — совместное применение действий модуля с информационной связностью полезно далеко не всегда.
|
