Информационная закрытость
Принцип информационной закрытости (автор — Д. Парнас, 1972) утверждает: содержание модулей должно быть скрыто друг от друга [60]. Как показано на рис. 4.12, модуль должен определяться и проектироваться так, чтобы его содержимое (процедуры и данные) было недоступно тем модулям, которые не нуждаются в такой информации (клиентам).
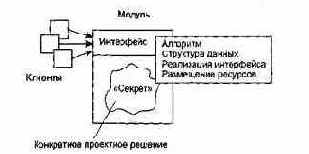
Рис. 4.12. Информационная закрытость модуля
Информационная закрытость означает следующее:
1) все модули независимы, обмениваются только информацией, необходимой для работы;
2) доступ к операциям и структурам данных модуля ограничен.
Достоинства информационной закрытости:
q обеспечивается возможность разработки модулей различными, независимыми коллективами;
q обеспечивается легкая модификация системы (вероятность распространения ошибок очень мала, так как большинство данных и процедур скрыто от других частей системы).
Идеальный модуль играет роль «черного ящика», содержимое которого невидимо клиентам. Он прост в использовании — количество «ручек и органов управления» им невелико (аналогия с эксплуатацией телевизора). Его легко развивать и корректировать в процессе сопровождения программной системы. Для обеспечения таких возможностей система внутренних и внешних связей модуля должна отвечать особым требованиям. Обсудим характеристики внутренних и внешних связей модуля.
Информационная закрытость делает невидимыми операционные детали программного компонента. Другим компонентам доступна только необходимая информация.
Качественные объектно-ориентированные системы поддерживают высокий уровень информационной закрытости. Таким образом, метрики, измеряющие степень достигнутой закрытости, тем самым отображают качество объектно-ориентированного проекта.
Инкапсуляция
Инкапсуляция и абстракция — взаимодополняющие понятия: абстракция выделяет внешнее поведение объекта, а инкапсуляция содержит и скрывает реализацию, которая обеспечивает это поведение. Инкапсуляция достигается с помощью информационной закрытости. Обычно скрываются структура объектов и реализация их методов.
Инкапсуляция является процессом разделения элементов абстракции на секции с различной видимостью. Инкапсуляция служит для отделения интерфейса абстракции от ее реализации.
Пример: физический объект регулятор скорости.
Обязанности регулятора:
q включаться;
q выключаться;
q увеличивать скорость;
q уменьшать скорость;
q отображать свое состояние.
Спецификация класса Регулятор скорости примет вид
with Кяасс_ДатчикСкорости. Класс_Порт;
use Класс_ДатчикСкорости. Класс_Порт;
Package Класс_РегуляторСкорости is
type Режим is (Увеличение, Уменьшение);
subtype Размещение is Natural range ...
type РегуляторСкорости is tagged private;
function НовРегуляторСкорости (номер: Размещение;
напр: Направление; порт; Порт)
return РегуляторСкорости;
procedure Включить(the: in out РегуляторСкорости);
procedure Выключить(1пе: in out РегуляторСкорости);
procedure УвеличитьСкорость(1г1е: in out
РегуляторСкорости);
procedure УменьшитьСкорость(the: in out
РегуляторСкорости);
Function OnpocCocтояния(the: РегуляторСкорости)
eturn Режим;
private
type укз_наПорт is access all Порт;
type РегуляторСкорости is tagged record
Номер; Размещение;
Состояние: Режим;
Управление: укз_наПорт;
end record;
end Класс_РегуляторСкорости;
Здесь вспомогательный тип Режим используется для задания основного типа класса, класс ДатчикСкорости обеспечивает класс регулятора описанием вспомогательного типа Направление, класс Порт фиксирует абстракцию порта, через который посылаются сообщения для регулятора. Три свойства: Номер, Состояние, Управление — формулируют инкапсулируемое представление основного типа класса РегуляторСкорости. При попытке клиента получить доступ к этим свойствам фиксируется семантическая ошибка.
Полное инкапсулированное представление класса РегуляторСкорости включает описание реализаций его методов — оно содержится в теле класса. Описание тела для краткости здесь опущено.
Вспомним, что инкапсуляция — упаковка (связывание) совокупности элементов. Для классических ПС примерами низкоуровневой инкапсуляции являются записи и массивы. Механизмом инкапсуляции среднего уровня являются подпрограммы (процедуры, функции).
В объектно-ориентированных системах инкапсулируются обязанности класса, представляемые его свойствами (а для агрегатов — и свойствами других классов), операциями и состояниями.
Для метрик учет инкапсуляции приводит к смещению фокуса измерений с одного модуля на группу свойств и обрабатывающих модулей (операций). Кроме того, инкапсуляция переводит измерения на более высокий уровень абстракции (пример — метрика «количество операций на класс»). Напротив, классические метрики ориентированы на низкий уровень — количество булевых условий (цикломатическая сложность) и количество строк программы.
Инкрементная модель
Инкрементная модель является классическим примером инкрементной стратегии конструирования (рис. 1.4). Она объединяет элементы последовательной водопадной модели с итерационной философией макетирования.
Каждая линейная последовательность здесь вырабатывает поставляемый инкремент ПО. Например, ПО для обработки слов в 1-м инкременте реализует функции базовой обработки файлов, функции редактирования и документирования; во 2-м инкременте — более сложные возможности редактирования и документирования; в 3-м инкременте — проверку орфографии и грамматики; в 4-м инкременте — возможности компоновки страницы.
Первый инкремент приводит к получению базового продукта, реализующего базовые требования (правда, многие вспомогательные требования остаются нереализованными).
План следующего инкремента предусматривает модификацию базового продукта, обеспечивающую дополнительные характеристики и функциональность.
По своей природе инкрементный процесс итеративен, но, в отличие от макетирования, инкрементная модель обеспечивает на каждом инкременте работающий продукт.
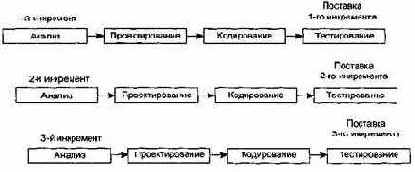
Рис. 1.4. Инкрементная модель
Забегая вперед, отметим, что современная реализация инкрементного подхода — экстремальное программирование ХР (Кент Бек, 1999) [10]. Оно ориентировано на очень малые приращения функциональности.
Интерфейсы
Интерфейс — список операций, которые определяют услуги класса или компонента. Образно говоря, интерфейс — это разъем, который торчит из ящичка компонента. С помощью интерфейсных разъемов компоненты стыкуются друг с другом, объединяясь в систему.
Еще одна аналогия. Интерфейс подобен абстрактному классу, у которого отсутствуют свойства и работающие операции, а есть только абстрактные операции (не имеющие тел). Если хотите, интерфейс похож на улыбку чеширского кота из правдивой истории об Алисе, где кот отдельно и улыбка отдельно. Все операции интерфейса открыты и видимы клиенту (в противном случае они потеряли бы всякий смысл). Итак, операции интерфейса только именуют предлагаемые услуги, не более того.
Очень важна взаимосвязь между компонентом и интерфейсом. Возможны два способа отображения взаимосвязи между компонентом и его интерфейсами. В первом, свернутом способе, как показано на рис. 13.3, интерфейс изображается в форме пиктограммы. Компонент Образ.java, который реализует интерфейс, соединяется со значком интерфейса (кружком) НаблюдательОбраза простой линией. Компонент РыцарьПечальногоОбраза.jауа, который использует интерфейс, связан с ним отношением зависимости.
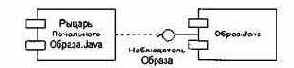
Рис. 13.3. Представление интерфейса в форме пиктограммы
Второй способ представления интерфейса иллюстрирует рис. 13.4. Здесь используется развернутая форма изображения интерфейса, в которой могут показываться его операции. Компонент, который реализует интерфейс, подключается к нему отношением реализации. Компонент, который получает доступ к услугам другого компонента через интерфейс, по-прежнему подключается к интерфейсу отношением зависимости.

Рис. 13.4. Развернутая форма представления интерфейса
По способу связи компонента с интерфейсом различают:
q экспортируемый интерфейс — тот, который компонент реализует и предлагает как услугу клиентам;
q импортируемый интерфейс — тот, который компонент использует как услугу другого компонента.
У одного компонента может быть несколько экспортируемых и несколько импортируемых интерфейсов.
Тот факт, что между двумя компонентами всегда находится интерфейс, устраняет их прямую зависимость. Компонент, использующий интерфейс, будет функционировать правильно вне зависимости от того, какой компонент реализует этот интерфейс. Это очень важно и обеспечивает гибкую замену компонентов в интересах развития системы.
Искусство отладки
Отладка — это локализация и устранение ошибок. Отладка является следствием успешного тестирования. Это значит, что если тестовый вариант обнаруживает ошибку, то процесс отладки уничтожает ее.
Итак, процессу отладки предшествует выполнение тестового варианта. Его результаты оцениваются, регистрируется несоответствие между ожидаемым и реальным результатами. Несоответствие является симптомом скрытой причины. Процесс отладки пытается сопоставить симптом с причиной, вследствие чего приводит к исправлению ошибки. Возможны два исхода процесса отладки:
1) причина найдена, исправлена, уничтожена;
2) причина не найдена.
Во втором случае отладчик может предполагать причину. Для проверки этой причины он просит разработать дополнительный тестовый вариант, который поможет проверить предположение. Таким образом, запускается итерационный процесс коррекции ошибки.
Возможные разные способы проявления ошибок:
1) программа завершается нормально, но выдает неверные результаты;
2) программа зависает;
3) программа завершается по прерыванию;
4) программа завершается, выдает ожидаемые результаты, но хранимые данные испорчены (это самый неприятный вариант).
Характер проявления ошибок также может меняться. Симптом ошибки может быть:
q постоянным;
q мерцающим;
q пороговым (проявляется при превышении некоторого порога в обработке — 200 самолетов на экране отслеживаются, а 201-й — нет);
q отложенным (проявляется только после исправления маскирующих ошибок).
В ходе отладки мы встречаем ошибки в широком диапазоне: от мелких неприятностей до катастроф. Следствием увеличения ошибок является усиление давления на отладчика — «найди ошибки быстрее!!!». Часто из-за этого давления разработчик устраняет одну ошибку и вносит две новые ошибки.
Английский термин debugging (отладка) дословно переводится как «ловля блох», который отражает специфику процесса — погоню за объектами отладки, «блохами».
Рассмотрим, как может быть организован этот процесс «ловли блох» [3], [64].
Различают две группы методов отладки:
q аналитические;
q экспериментальные.
Аналитические методы базируются на анализе выходных данных для тестовых прогонов. Экспериментальные методы базируются на использовании вспомогательных средств отладки (отладочные печати, трассировки), позволяющих уточнить характер поведения программы при тех или иных исходных данных.
Общая стратегия отладки — обратное прохождение от замеченного симптома ошибки к исходной аномалии (месту в программе, где ошибка совершена).
В простейшем случае место проявления симптома и ошибочный фрагмент совпадают. Но чаще всего они далеко отстоят друг от друга.
Цель отладки — найти оператор программы, при исполнении которого правильные аргументы приводят к неправильным результатам. Если место проявления симптома ошибки не является искомой аномалией, то один из аргументов оператора должен быть неверным. Поэтому надо перейти к исследованию предыдущего оператора, выработавшего этот неверный аргумент. В итоге пошаговое обратное прослеживание приводит к искомому ошибочному месту.
В разных методах прослеживание организуется по-разному. В аналитических методах — на основе логических заключений о поведении программы. Цель — шаг за шагом уменьшать область программы, подозреваемую в наличии ошибки. Здесь определяется корреляция между значениями выходных данных и особенностями поведения.
Основное преимущество аналитических методов отладки состоит в том, что исходная программа остается без изменений.
В экспериментальных методах для прослеживания выполняется:
1. Выдача значений переменных в указанных точках.
2. Трассировка переменных (выдача их значений при каждом изменении).
3. Трассировка потоков управления (имен вызываемых процедур, меток, на которые передается управление, номеров операторов перехода).
Преимущество экспериментальных методов отладки состоит в том, что основная рутинная работа по анализу процесса вычислений перекладывается на компьютер. Многие трансляторы имеют встроенные средства отладки для получения информации о ходе выполнения программы.
Недостаток экспериментальных методов отладки — в программу вносятся изменения, при исключении которых могут появиться ошибки. Впрочем, некоторые системы программирования создают специальный отладочный экземпляр программы, а в основной экземпляр не вмешиваются.
Использование диаграмм размещения
Диаграммы размещения используют для моделирования статического представления того, как размещается система. Это представление поддерживает распространение, поставку и инсталляцию частей, образующих физическую систему.
Графически диаграмма размещения — это граф из узлов (или экземпляров узлов), соединенных ассоциациями, которые показывают существующие коммуникации. Экземпляры узлов могут содержать экземпляры компонентов, живущих или запускаемых в узлах. Экземпляры компонентов могут содержать объекты. Как показано на рис. 13.29, компоненты соединяются друг с другом пунктирными стрелками зависимостей (прямо или через интерфейсы).
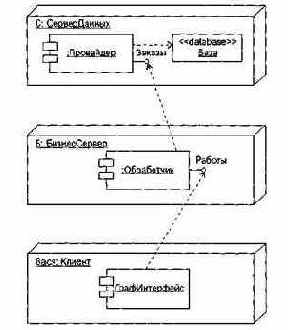
Рис. 13.29. Моделирование размещения компонентов
На этой диаграмме изображена типовая трехуровневая система:
q уровень базы данных реализован экземпляром С узла СерверДанных;
q уровень бизнес-логики представлен экземпляром Б узла БизнесСервер;
q уровень графического интерфейса пользователя образован экземпляром Вася узла Клиент.
В узле сервера данных показано размещение анонимного экземпляра компонента Провайдер и объекта База со стереотипом <<database>>. Узел бизнес-сервера содержит анонимный экземпляр компонента Обработчик, а узел клиента — анонимный экземпляр компонента ГрафИнтерфейс. Кроме того, здесь явно отображены интерфейсы компонентов Провайдер и Обработчик, имеющие, соответственно, имена Заказы и Работы.
Как представлено на рис. 13.30, перемещение компонентов от узла к узлу (или объектов от компонента к компоненту) отмечается стереотипом <<becomes>> на отношении зависимости. В этом случае считают, что компонент (объект) резидентен в узле (компоненте) только в пределах некоторого кванта времени. На рисунке видим, что возможность миграции предоставлена объектам X и Y.
Иногда полезно определить физическое распределение компонентов по процессорам и другим устройствам системы. Есть три способа моделирования распределения:
q графически распределение не показывать, а документировать его в текстовых спецификациях узлов;
q соединять каждый узел с размещаемыми компонентами отношениями зависимости;
q в дополнительной секции узла указывать список размещаемых компонентов.
Диаграмма размещения, иллюстрирующая третий способ моделирования, показана на рис. 13.31.
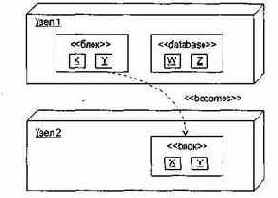
Рис. 13.30. Моделирование перемещения компонентов и объектов
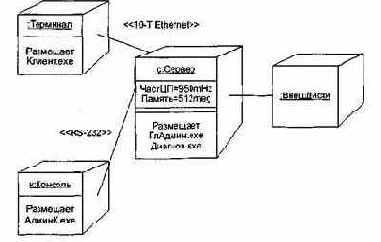
Рис. 13.31. Распределение компонентов в системе
На рисунке показаны два анонимных экземпляра узлов (:ВнешДиски, :Терминал) и два экземпляра узлов с именем (с для Сервера и к для Консоли). Каждый процессор нарисован с дополнительной секцией, в которой показаны размещенные компоненты. В экземпляре Сервера, кроме того, отображены его свойства (ЧастЦП, Память) и их значения.
С помощью стереотипов заданы характеристики физических соединений между процессорами: одно из них определено как Ethernet-соединение, другое — как последовательное RS-232-соединение.
Использование компонентных диаграмм
Компонентные диаграммы используют для моделирования статического представления реализации системы. Это представление поддерживает управление конфигурацией системы, составляемой из компонентов. Подразумевается, что для получения работающей системы существуют различные способы сборки компонентов.
Компонентные диаграммы показывают отношения:
q периода компиляции (среди текстовых компонентов);
q периода сборки, линковки (среди объектных двоичных компонентов);
q периода выполнения (среди машинных компонентов).
Рассмотрим типовые варианты применения компонентных диаграмм.
Использование метрик Чидамбера-Кемерера
Поскольку основу логического представления ПО образует структура классов, для оценки ее качества удобно использовать метрики Чидамбера-Кемерера. Пример расчета метрик для структуры, показанной на рис. 14.4, представлен в табл. 14.4.
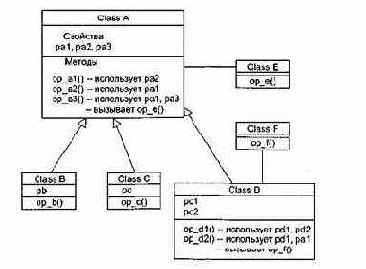
Рис. 14.4. Структура классов для расчета метрик Чидамбера-Кемерера
Прокомментируем результаты расчета. Класс Class А имеет три метода (op_al(), ор_а2(), ор_аЗ()), трех детей (Class В, Class С, Class D) и является корневым классом. Поэтому метрики WMC, NOC и DIT имеют, соответственно, значения 3, 3 и 0.
Метрика СВО для класса Class А равна 1, так как он использует один метод из другого класса (метод ор_е() из класса Class E, он вызывается из метода ор_аЗ()). Метрика RFC для класса Class А равна 4, так как в ответ на прибытие в этот класс сообщений возможно выполнение четырех методов (три объявлены в этом классе, а четвертый метод ор_е() вызывается из ор_аЗ()).
Таблица 14.4. Пример расчета метрик Чидамбера-Кемерера
| Имя класса | WMC | DIT | NOC | СВО | RFC | LCOM | |||||||
| Class A | 3 | 0 | 3 | 1 | 4 | 1 | |||||||
| Class В | 1 | 1 | 0 | 0 | 1 | 0 | |||||||
| Class С | 1 | 1 | 0 | 0 | 1 | 0 | |||||||
| Class D | 2 | 1 | 0 | 2 | 3 | 0 |
Для вычисления метрики LCOM надо определить количество пар методов класса. Оно рассчитывается по формуле

где т — количество методов класса.
Поскольку в классе три метода, возможны три пары: op_al( )&ор_а2(), op_al( )&ор_а3() и ор_а2( )&ор_а3(). Первая и вторая пары не имеют общих свойств, третья пара имеет общее свойство (pal). Таким образом, количество несвязанных пар равно 2, количество связанных пар равно 1, и LCOM = 2-1 = 1.
Отметим также, что для класса Class D метрика СВО равна 2, так как здесь используются свойство pal и метод op_f() из других классов. Метрика LCOM в этом классе равна 0, поскольку методы op_dl() и op_d2() связаны по свойству pdl, а отрицательное значение запрещено.
Изменение методики при объектно-ориентированном тестировании
В классической методике тестирования действия начинаются с тестирования элементов, а заканчиваются тестированием системы. Вначале тестируют модули, затем тестируют интеграцию модулей, проверяют правильность реализации требований, после чего тестируют взаимодействие всех блоков компьютерной системы.
Измерения, меры и метрики
Измерения помогают понять как процесс разработки продукта, так и сам продукт. Измерения процесса производятся в целях его улучшения, измерения продукта — для повышения его качества. В результате измерения определяется мера — количественная характеристика какого-либо свойства объекта. Путем непосредственных измерений могут определяться только опорные свойства объекта. Все остальные свойства оцениваются в результате вычисления тех или иных функций от значений опорных характеристик. Вычисления этих функций проводятся по формулам, дающим числовые значения и называемым метриками.
В IEEE Standard Glossary of Software Engineering Terms метрика определена как мера степени обладания свойством, имеющая числовое значение. В программной инженерии понятия мера и метрика очень часто рассматривают как синонимы.
Элемент ХР-разработки
Структура элемента ХР-разработки показана на рис. 15.18.
День ХР-разработчика начинается с установочной встречи. Ее цели: обсуждение проблем, нахождение решений и определение точки приложения усилий всей команды.
Участники утренней встречи стоят и располагаются по кругу, так можно избежать длинных дискуссий. Все остальные встречи проходят на рабочих местах, за компьютером, где можно просматривать код и обсуждать новые идеи.
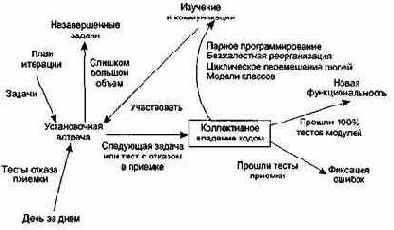
Рис. 15.18. Структура элемента ХР-разработки
Весь день ХР-разработчика проходит под лозунгом коллективного владения кодом программной системы. В результате этого происходит фиксация ошибок и добавление новой функциональности в систему.
Следует удерживаться от соблазна добавлять в продукт функциональность, которая будет востребована позже. Полагают, что только 10% такой функциональности будет когда-либо использовано, а потери составят 90% времени разработчика. В ХР считают, что дополнительная функциональность только замедляет разработку и исчерпывает ресурсы. Предлагается подавлять такие творческие порывы и концентрироваться на текущих, запланированных задачах.
Этап КОНСТРУИРОВАНИЕ
Рассмотрим содержание итераций на этапе конструирования.
Итерация 1 — реализация сценариев элемента Use Case Управление окнами
Для реализации сценария Создание окна программируются следующие операции класса Window:
q framework — создание каркаса окна;
q register — регистрация окна;
q set_call_back — установка функции обратного вызова;
q make_window — задание видимости окна.
Далее реализуются операции общего управления окнами, методы класса Window_Manager:
q add_to_list — добавление нового окна в массив управляемых окон;
q find — поиск окна с заданным переключающим символом.
Программируются операции класса Input-Manager:
q window_prolog — инициализация WUI;
q window_start — запуск цикла обработки событий;
q window_epilog — закрытие WUI.
В ходе реализации перечисленных операций выясняется необходимость и программируется содержание вспомогательных операций.
1. В классе Window_Manager:
q write_to — форматный вывод сообщения в указанное окно;
q hide_win — удаление окна с экрана;
q switchAwayFromTop — подготовка окна к переходу в пассивное состояние;
q switch_to_top — подготовка окна к переходу в активное состояние;
q window_fatal — формирование донесения об ошибке;
q top — переключение окна в активное состояние;
q send_to_top — посылка символа в активное окно.
2. В классе Window:
q put — три реализации для записи в окно символьной, строковой и числовой информации;
q create — создание макета окна (используется операцией framework);
q position — изменение позиции курсора в окне;
q about — возврат информации об окне;
q switch_to — пометка активного окна;
q switch_away — пометка пассивного окна;
q send_to — посылка символа в окно для обработки.
Второй шаг первой итерации ориентирован на реализацию сценария Уничтожение окна. Основная операция — finalize (метод класса Window), она выполняет разрушение окна. Для ее обеспечения создаются вспомогательные операции:
q de_register — удаление окна из массива управляемых окон;
q remove_from_list (метод класса Window_Manager) — вычеркивание окна из регистра.
Для реализации сценария Изменение стиля рамки создаются операции в классе Window:
q mark_border — построение новой рамки окна;
q refresh — перерисовка окна на экране.
В конце итерации создаются операции класса Screen:
q dear_screen — очистка экрана;
q position_cursor — позиционирование курсора;
q put — вывод на экран дисплея строк, символов и чисел.
Результаты оценки качества первой итерации представлены в табл. 15.3.
Таблица 15.3. Оценки качества WUI после первой итерации
|
Метрика |
lnput_ Manager |
Window_ Manager |
Screen |
Root_ Window |
Window |
Среднее значение |
|
WMC |
0,12 |
0,42 |
0,11 |
0 |
0,83 |
0,3 |
|
NOC |
- |
- |
- |
1 |
0 |
0,2 |
|
СВО |
3 |
3 |
0 |
1 |
2 |
1,8 |
|
RFC |
6 |
11 |
0 |
0 |
23 |
8 |
|
LCOM |
3 |
0 |
5 |
0 |
0 |
1,6 |
|
CS |
3/2 |
10/8 |
5/1 |
0/2 |
18/22 |
7,2/7 |
|
NOO |
- |
- |
- |
0 |
0 |
0 |
|
NOA |
- |
- |
- |
0 |
18 |
3,6 |
|
SI |
- |
- |
- |
0 |
0 |
0 |
|
OSAVG |
4 |
4,2 |
2,2 |
0 |
4,6 |
3 |
|
NPAVG |
0 |
1,3 |
1 |
0 |
2,4 |
0,9 |
|
Метрики, вычисляемые для системы |
||||||
|
DIT |
1 |
|
|
|
|
|
|
NC |
5 |
|
|
|
|
|
|
MOM |
35 |
|
|
|
|
|
LOC |
148 |
|
|
|
|
|
Итерация 2 — реализация сценариев элемента Use Case Использование окон
На этой итерации реализуем методы классов Menu и Menu_title, а также добавим необходимые вспомогательные методы в класс Window.
Отметим, что операции, обеспечивающие сценарий Использование простого окна, в основном уже реализованы (на первой итерации). Осталось запрограммировать следующие операции — методы класса Window:
q call_call_back — вызов функции обратного вызова;
q initialize — управляемая инициализация окна;
q clear — очистка окна с помощью пробелов;
q new_line — перемещение на следующую строку окна.
Для обеспечения сценария Использование окна меню создаются следующие операции.
1. В классе Menu:
q framework — создание каркаса окна-меню;
q send_to — обработка пользовательского ввода в окно-меню;
q menu_spot — выделение выбранного элемента меню;
q set_up — заполнение окна-меню именами элементов;
q get_menu_name — возврат имени выбранного элемента меню;
q get_cur_selected_detaits — возврат указателя на выбранное окно и функцию обратного вызова.
2. В классе Menu_title:
q send_to — выделение новой строки меню или вызов функции обратного вызова;
q switch_away — возврат в базовое окно-меню более высокого уровня;
q set_up — установки окна меню-заголовка.
Результаты оценки качества второй итерации представлены в табл. 15.4.
Таблица 15.4. Оценки качества WUI после второй итерации
|
Метрика |
lnput_ Manager |
Window_ Manager |
Screen |
Root_ Window |
Window |
Menu |
Menu title |
Среднее значение |
|
WMC |
0,12 |
0,42 |
0,11 |
0 |
0,98 |
0,33 |
0,27 |
0,32 |
|
NOC |
- |
- |
- |
1 |
1 |
1 |
0 |
0,4 |
|
СВО |
3 |
3 |
0 |
1 |
2 |
2 |
3 |
2 |
|
RFC |
6 |
11 |
0 |
0 |
27 |
9 |
12 |
9,4 |
|
LCOM |
3 |
0 |
5 |
0 |
0 |
0 |
0 |
1,1 |
|
CS |
3/2 |
10/8 |
5/1 |
0/2 |
22/22 |
28/24 |
11/12 |
11,3/10,1 |
|
NOO |
- |
- |
- |
0 |
0 |
2 |
3 |
0,7 |
|
NOA |
- |
- |
- |
0 |
22 |
6 |
0 |
4 |
|
SI |
- |
- |
- |
0 |
0 |
0,23 |
0,46 |
0,1 |
|
oswe |
4 |
4,2 |
2,2 |
0 |
4,45 |
4,13 |
9 |
4,0 |
|
NPAVG |
0 |
1,3 |
1 |
0 |
2,18 |
4,63 |
1,67 |
1,5 |
|
Метрики, вычисляемые для системы |
||||||||
|
DIT |
3 |
|
|
|
|
|
|
|
|
NC |
7 |
|
|
|
|
|
|
|
|
MOM |
48 |
|
|
|
|
|
|
|
|
LOCZ |
223 |
|
|
|
|
|
|
|
Сравним оценки качества первой и второй итераций.
1. Рост системных оценок LOC
2. Увеличение значения DIT и среднего значения NOC говорит об увеличении возможности многократного использования классов.
3. На второй итерации в среднем была ослаблена абстракция классов, о чем свидетельствует увеличение средних значений NOC, NOA, SI.
4. Рост средних значений OSAVG и NPAVG говорит о том, что сотрудничество между объектами усложнилось.
5. Среднее значение СВО указывает на увеличение сцепления между классами (это нежелательно), зато снижение среднего значения LCOM свидетельствует, что связность внутри классов увеличилась (таким образом, снизилась вероятность ошибок в ходе разработки).
Вывод: качество разработки в среднем возросло, так как, несмотря на увеличение средних значений сложности и сцепления (за счет добавления в иерархию наследования новых классов), связность внутри классов была увеличена.
В практике проектирования достаточно типичны случаи, когда в процессе разработки меняются исходные требования или появляются дополнительные требования к продукту. Предположим, что в конце второй итерации появилось дополнительное требование — ввести в WUI новый тип окна — диалоговое окно. Диалоговое окно должно обеспечивать не только вывод, но и ввод данных, а также их обработку.
Для реализации этого требования вводится третья итерация конструирования.
Итерация 3 — разработка диалогового окна
Шаг 1: Спецификация представления диалогового окна.
На этом шаге фиксируется представление заказчика об обязанностях диалогового окна. Положим, что оно имеет следующий вид:
1. Диалоговое окно накапливает посылаемые в него символы, отображая их по мере получения.
2. При получении символа конца сообщения (ENTER) полная строка текста принимается в функцию обратного вызова, связанную с диалоговым окном.
3. Функция обратного вызова реализует обслуживание, требуемое пользователю.
4. Функция обратного вызова обеспечивается прикладным программистом.
Шаг 2: Модификация диаграммы Use Case для WUI.
Очевидно, что дополнительное требование приводит к появлению дополнительного элемента Use Case, который находится в отношении «расширяет» с базовым г элементом Use Case Использование окон.
Диаграмма Use Case принимает вид, представленный на рис. 15.13.
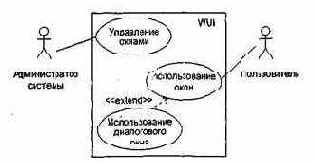
Рис. 15.13. Модифицированная диаграмма Use Case для WUI
Шаг 3: Описание элемента Use Case Использование диалогового окна.
Действия начинаются с ввода пользователем переключающего символа, активизирующего данный тип окна. Символ воспринимается менеджером ввода. Далее пользователь вводит данные, которые по мере поступления отображаются в диалоговом окне. После нажатия пользователем символа окончания ввода (ENTER) данные передаются в функцию обратного вызова как параметр. Выполняется функция обратного вызова, результат выводится в простое окно результата.
Шаг 4: Диаграмма последовательности Использование диалогового окна.
Диаграмма последовательности для сценария Использование диалогового окна показана на рис. 15.14.
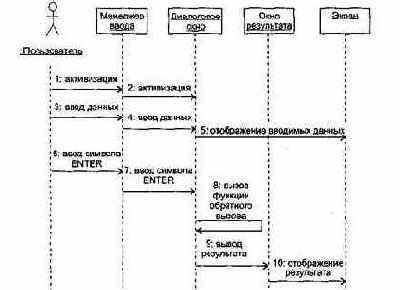
Рис. 15.14. Диаграмма последовательности Использование диалогового окна
Шаг 5: Создание класса.
Для реализации сценария Использование диалогового окна создается новый класс Dialog, который является наследником класса Window. Объекты класса Dialog образуют диалоговые окна.
Класс Dialog переопределяет следующие операции, унаследованные от класса Window:
q framework — формирование диалогового окна. Параметры операции: имя диалогового окна, координаты, ширина окна, заголовок окна и ссылка на функцию обратного вызова. Операция создает каркас окна, устанавливает для него функцию обратного вызова, делает окно видимым и регистрирует его в массиве управляемых окон;
q send_to — обрабатывает пользовательский ввод, посылаемый в диалоговое окно. Окно запоминает символы, вводимые пользователем, а после нажатия пользователем клавиши ENTER вызывает функцию обратного вызова, обрабатывающую эти данные.
Конечное представление иерархии классов WUI показано на рис. 15.15. Результаты оценки качества проекта (в конце третьей итерации) сведены в табл. 15.5. Динамика изменения значений для метрик класса показана в табл. 15.6.
Таблица 15.5. Оценки качества WUI после третьей итерации
|
Метрика |
lnput_ Manager |
Window Manager |
Screen |
Root Window |
Window |
Menu |
Menu-title |
Dialog |
Среднее значение |
|||||||
|
WMC |
0,12 |
0,42 |
0,11 |
0 |
0,98 |
0,33 |
0,27 |
0,23 |
0,31 |
|||||||
|
NOC |
- |
- |
- |
1 |
2 |
1 |
0 |
0 |
0,5 |
|||||||
|
СВО |
3 |
3 |
0 |
1 |
2 |
2 |
3 |
2 |
2 |
|||||||
|
RFC |
6 |
11 |
0 |
0 |
27 |
9 |
12 |
7 |
9,1 |
|||||||
|
LCOM |
3 |
0 |
5 |
0 |
0 |
0 |
0 |
0 |
1 |
|||||||
|
CS |
3/2 |
10/8 |
5/1 |
0/2 |
22/22 |
28/24 |
11/12 |
24/14 |
12,2/10,6 |
|||||||
|
NOO |
- |
- |
- |
0 |
0 |
2 |
3 |
2 |
0,9 |
|||||||
|
NOA |
- |
- |
- |
0 |
22 |
6 |
0 |
0 |
3,5 |
|||||||
|
SI |
- |
- |
- |
0 |
0 |
0,23 |
0,46 |
0,27 |
0,14 |
|||||||
|
OSAVG |
4 |
4,2 |
2,2 |
0 |
4,45 |
4,13 |
9 |
11,5 |
4,9 |
|||||||
|
NPAVG |
0 |
1,3 |
1 |
0 |
2,18 |
4,63 |
1,67 |
4 |
1,8 |
|||||||
|
Метрики, вычисляемые для системы |
||||||||||||||||
|
DIT |
3 |
|
|
|
|
|
|
|
||||||||
|
NC |
8 |
|
|
|
|
|
|
|
|
|||||||
|
NOM |
50 |
|
|
|
|
|
|
|
|
|||||||
LOC |
246 |
|
|
|
|
|
|
|
|
|||||||
Таблица 15.6. Средние значения метрик класса на разных итерациях
|
Метрика |
Итерация 1 |
Итерация 2 |
Итерация 3 |
|
WMC |
0,3 |
0,32 |
0,31 |
|
NOC |
0,2 |
0,4 |
0,5 |
|
СВО |
1,8 |
2 |
2 |
|
RFC |
8 |
9,4 |
9,1 |
|
LCOM |
1,6 |
1,1 |
1 |
|
CS |
7,2/7 |
11,3/10,1 |
12,2/10,6 |
|
NOO |
0 |
0,7 |
0,9 |
|
NOA |
3,6 |
4 |
3,5 |
|
SI |
0 |
0,1 |
0,14 |
|
OSAVG |
3 |
4,0 |
4,9 |
|
NPAVG |
0,9 |
1,5 |
1,8 |
|
DIT |
1 |
3 |
3 |
|
NC |
5 |
7 |
8 |
|
NOM |
35 |
48 |
50 |
LOC |
148 |
223 |
246 |
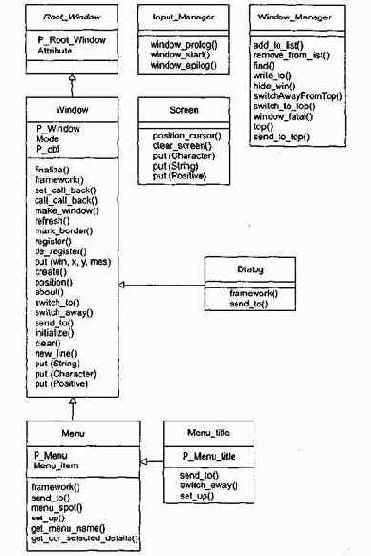
Рис. 15.15. Конечная диаграмма классов WUI
Сравним средние значения метрик второй и третьей итераций:
1. Общая сложность WUI возросла (увеличились значения LOC
2. Увеличились возможности многократного использования классов (о чем свидетельствует рост среднего значения NOC и уменьшение среднего значения WMC).
3. Возросла средняя связность класса (уменьшилось среднее значение метрики LCOM).
4. Уменьшилось среднее значение сцепления класса (сохранилось среднее значение СВО и уменьшилось среднее значение RFC).
Вывод: качество проекта стало выше.
На последней итерации рассчитаны значения интегральных метрик Абреу, они представлены в табл. 15.7. Эти данные также характеризуют качество проекта и подтверждают наши выводы.
Таблица 15.7. Значения метрик Абреу для WUI
|
Метрика |
Значение |
|
МНF |
0,49 |
|
AHF |
0,49 |
|
MIF |
0,49 |
|
AIF |
0,29 |
|
POF |
0,69 |
|
COF |
0,25 |
Этап КОНСТРУИРОВАНИЕ (Construction)
Главное назначение этапа — создать программный продукт, который обеспечивает начальные операционные возможности.
Цели этапа КОНСТРУИРОВАНИЕ:
q минимизировать стоимость разработки путем оптимизации ресурсов и устранения необходимости доработок;
q добиться быстрого получения приемлемого качества;
q добиться быстрого получения контрольных версий (альфа, бета и т. д.).
Основные действия этапа КОНСТРУИРОВАНИЕ:
q управление ресурсами, контроль ресурсов, оптимизация процессов;
q полная разработка компонентов и их тестирование (по сформулированному критерию эволюции);
q оценивание реализаций продукта (по критерию признания из спецификации представления).
В итоге этапа КОНСТРУИРОВАНИЕ создаются следующие артефакты:
q программный продукт, готовый для передачи в руки конечных пользователей;
q описание текущей реализации;
q руководство пользователя.
Реализации продукта создаются в серии итераций. Каждая итерация выделяет конкретный набор элементов риска, выявленных на этапе развития. Обычно в итерации реализуется один или несколько элементов Use Case. Типовая итерация включает следующие действия:
1. Идентификация реализуемых классов и отношений.
2. Определение в классах типов данных (для свойств) и сигнатур (для операций). Добавление сервисных операций, например операций доступа и управления. Добавление сервисных классов (классов-контейнеров, классов-контроллеров). Реализация отношений ассоциации, агрегации и наследования.
3. Создание текста на языке программирования.
4. Создание(обновление) документации.
5. Тестирование функций реализации продукта.
6. Объединение текущей и предыдущей реализаций. Тестирование итерации.
Этап НАЧАЛО
Оконный интерфейс пользователя(WUI) — среда, управляемая событиями. Действия в среде инициируются функциями обратного вызова, которые вызываются в ответ на событие — пользовательский ввод. Ядром WUI является цикл обработки событий, который организуется менеджером ввода.
WUI должен обеспечивать следующие типы неперекрывающихся окон:
q простое окно, в которое может быть выведен текст;
q окно меню, в котором пользователь может задать вариант действий — выбор подменю или функции обратного вызова.
Идентификация актеров
Актерами для WUI являются:
q пользователь прикладной программы, использующей WUI;
q администратор системы, управляющий работой WUI.
Внешнее окружение WUI имеет вид, представленный на рис. 15.5.
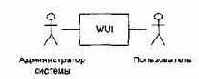
Рис. 15.5. Внешнее окружение WUI
Идентификация элементов Use Case
В WUI могут быть выделены два элемента Use Case:
q управление окнами;
q использование окон.
Диаграмма Use Case для среды WUI представлена на рис. 15.6.
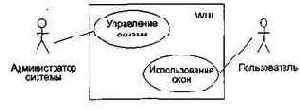
Рис. 15.6. Диаграмма Use Case для среды WUI
Описания элементов Use Case
Описание элемента Use Case Управление окнами.
Действия начинаются администратором системы. Администратор может создать, удалить или модифицировать окно.
Описание элемента Use Case Использование окон.
Действия начинаются пользователем прикладной программы. Обеспечивается возможность работы с меню и простыми окнами.
Этап НАЧАЛО (Inception)
Главное назначение этапа — запустить проект.
Цели этапа НАЧАЛО:
q определить область применения проектируемой системы (ее предназначение, границы, интерфейсы с внешней средой, критерий признания — приемки);
q определить элементы Use Case, критические для системы (основные сценарии поведения, задающие ее функциональность и покрывающие главные проектные решения);
q определить общие черты архитектуры, обеспечивающей основные сценарии, создать демонстрационный макет;
q определить общую стоимость и план всего проекта и обеспечить детализированные оценки для этапа развития;
q идентифицировать основные элементы риска. Основные действия этапа НАЧАЛО:
q формулировка области применения проекта — выявление требований и ограничений, рассматриваемых как критерий признания конечного продукта;
q планирование и подготовка бизнес-варианта и альтернатив развития для управления риском, определение персонала, проектного плана, а также выявление зависимостей между стоимостью, планированием и полезностью;
q синтезирование предварительной архитектуры, развитие компромиссных решений проектирования; определение решений разработки, покупки и повторного использования, для которых можно оценить стоимость, планирование и ресурсы.
В итоге этапа НАЧАЛО создаются следующие артефакты:
q спецификация представления основных проектных требований, ключевых характеристик и главных ограничений;
q начальная модель Use Case (20% от полного представления); а начальный словарь проекта;
q начальный бизнес-вариант (содержание бизнеса, критерий успеха — прогноз дохода, прогноз рынка, финансовый прогноз);
q начальное оценивание риска;
q проектный план, в котором показаны этапы и итерации.
Этап ПЕРЕХОД (Transition)
Главное назначение этапа — применить программный продукт в среде пользователей и завершить реализацию продукта.
Этап начинается с предъявления пользователям бета-реализации продукта. В ней обнаруживаются ошибки, они корректируются в последующих бета-реализациях. Параллельно решаются вопросы размещения, упаковки и сопровождения продукта. После завершения бета-периода тестирования продукт считается реализованным.
Этап РАЗВИТИЕ
На этом этапе создаются сценарии для элементов Use Case, разрабатываются диаграммы последовательности (формализующие текстовые представления сценариев), проектируются диаграммы классов и планируется содержание следующего этапа разработки.
Сценарии для элемента Use Case Управление окнами
В элементе Use Case Управление окнами заданы три потока событий — три сценария.
1. Сценарий Создание окна.
Устанавливаются координаты окна на экране, стиль рамки окна. Образ окна сохраняется в памяти. Окно выводится на экран. Если создается окно меню, содержащее обращение к функции обратного вызова, то происходит установка этой функции. В конце менеджер окон добавляет окно в список управляемых окон WUI.
2. Сценарий Изменение стиля рамки.
Указывается символ, с помощью которого будет изображаться рамка. Образ окна сохраняется в памяти. Окно перерисовывается на экране.
3. Сценарий Уничтожение окна.
Менеджер окон получает указание удалить окно. Менеджер окон снимает окно с регистрации (в массиве управляемых окон WUI). Окно снимает отображение с экрана.
Развитие описания элемента Use Case Использование окон
Действия начинаются с ввода пользователем символа. Символ воспринимается менеджером ввода. В зависимости от значения введенного символа выполняется один из следующих вариантов:
при значении ENTER - вариант ОКОНЧАНИЯ ВВОДА;
при переключающем значении - вариант ПЕРЕКЛЮЧЕНИЯ;
при обычном значении - символ выводится в активное окно.
Вариант ОКОНЧАНИЯ ВВОДА:
при активном окне меню выбирается пункт меню. В ответ либо выполняется функция обратного вызова (закрепленная за этим пунктом меню), либо вызывается подменю (соответствующее данному пункту меню);
при активном простом окне выполняется переход на новую строку окна.
Вариант ПЕРЕКЛЮЧЕНИЯ.
При вводе переключающего символа:
ESC - активным становится окно меню;
TAB - активным становится следующее простое окно;
Ctrl-E - все окна закрываются и сеанс работы заканчивается.
Далее из описания элемента Use Case Использование окон выделяются два сценария: Использование простого окна и Использование окна меню.
На следующем шаге сценарии элементов Use Case преобразуются в диаграммы последовательности — за счет этого достигается формализация описаний, требуемая для построения диаграмм классов. Для построения диаграмм последовательности проводится грамматический разбор каждого сценария элемента Use Case: значащие существительные превращаются в объекты, а значащие глаголы — в сообщения, пересылаемые между объектами.
Диаграммы последовательности
Диаграммы изображены на рис. 15.7-15.11.

Рис. 15.7. Диаграмма последовательности Создание окна
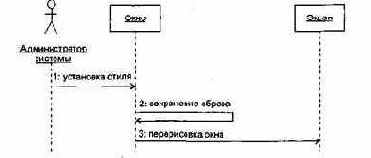
Рис. 15.8. Диаграмма последовательности Изменение стиля рамки
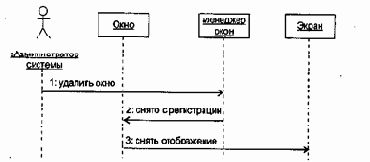
15.9. Диаграмма последовательности Уничтожение окна
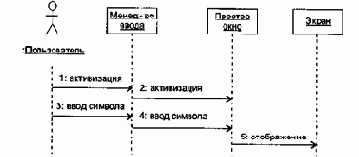
Рис. 15.10. Диаграмма последовательности Использование простого окна
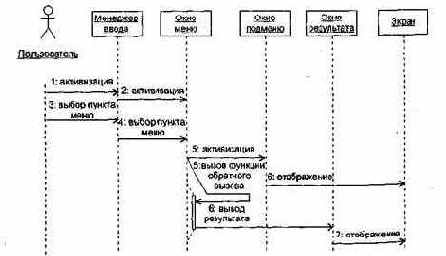
Рис. 15.11. Диаграмма последовательности Использование окна меню
Создание классов
Работа по созданию классов (и включению их в диаграмму классов) требует изучения содержания всех диаграмм последовательности. Проводится она в три этапа.
На первом этапе выявляются и именуются классы. Для этого просматривается каждая диаграмма последовательности. Любой объект в этой диаграмме должен принадлежать конкретному классу, для которого надо придумать имя. Например, резонно предположить, что объекту Менеджер окон должен соответствовать класс Window_Manager, поэтому класс Window_Manager следует ввести в диаграмму. Конечно, если в другой диаграмме последовательности опять появится подобный объект, то дополнительный класс не образуется.
На втором этапе выявляются операции классов. На диаграмме последовательности такая операция соответствует стрелке (и имени) сообщения, указывающей на линию жизни объекта класса. Например, если к линии жизни объекта Менеджер окон подходит стрелка сообщения добавить окно, то в класс Window_Manager нужно ввести си операцию add_to_list().
На третьем этапе определяются отношения ассоциации между классами — они обеспечивают пересылки сообщений между соответствующими объектами.
В нашем примере анализ диаграмм последовательности позволяет выделить следующие классы:
q Window — класс, объектами которого являются простые окна;
q Menu — класс, объектами которого являются окна меню. Этот класс является потомком класса Window;
q Menu_title — класс, объектом которого является окно главного меню. Класс является потомком класса Menu;
q Screen — класс, объектом которого является экран. Этот класс обеспечивает позиционирование курсора, вывод изображения на экран дисплея, очистку экрана;
q Input_Manager — объект этого класса управляет взаимодействием между пользователем и окнами интерфейса. Его обязанности: начальные установки среды WUI, запуск цикла обработки событий, закрытие среды WUI;
q Window_Manager — осуществляет общее управление окнами, отображаемыми на экране. Используется менеджером ввода для получения доступа к конкретному окну.
Для оптимизации ресурсов создается абстрактный суперкласс Root_Window. Он определяет минимальные обязанности, которые должен реализовать любой тип окна (а (посылка символа в окно, перевод окна в активное/пассивное состояние, перерисовка окна, возврат информации об окне). Все остальные классы окон являются его потомками.
Для реализации функций, определенных в сценариях, в классы добавляются свойства и операции. По результатам формирования свойств и операций классов обновляется содержание диаграмм последовательности.
Начальное представление иерархии классов WUI показано на рис. 15.12. Результаты начальной оценки качества проекта сведены в табл. 15.2.
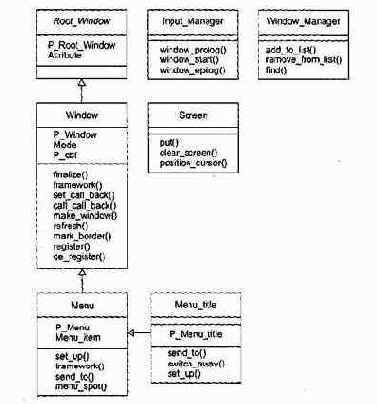
Рис. 15.12. Начальная диаграмма классов WUI
Таблица 15.2. Результаты начальпий оценки качества WUI
|
Метрика |
Input_ Manager |
Window_ Manager |
Screen |
Root_ Window |
Window |
Menu |
Menu_ title |
Среднее значение |
|
|
WMC NOC |
3 - |
3 - |
3 - |
0 1 |
9 1 |
4 1 |
3 0 |
3,57 0,43 |
|
|
Метрики, вычисляемые для системы |
|||||||||
|
DIT NC NOM |
3 7 25 |
||||||||
Отметим, что для упрощения рисунка на этой диаграмме не показаны существующие между классами отношения ассоциации. В реальной диаграмме они обязательно отображаются — без них экземпляры классов не смогут взаимодействовать друг с другом.
Планирование итераций конструирования
На данном шаге составляется план итераций, который определяет порядок действий на этапе конструирования. Цель каждой итерации — уменьшить риск разработки конечного продукта. Для создания начального плана анализируются элементы Us Case, их сценарии и диаграммы последовательности. Устанавливается приоритет их реализации. При завершении каждой итерации будет повторно вычисляться риск. Оценка риска может привести к необходимости обновления плана итераций.
Положим, что максимальный риск связан с реализацией элемента Use Case Управление окнами, причем наиболее опасна разработка сценария Создание окна, среднюю опасность несет сценарий Уничтожение окна и малую опасность — Изменение стиля рамки.
В связи с этими соображениями начальный план итераций принимает вид:
Итерация 1 — реализация сценариев элемента Use Case Управление окнами:
1. Создание окна.
2. Уничтожение окна.
3. Изменение стиля рамки.
Итерация 2 — реализация сценариев элемента Use Case Использование окон:
4. Использование простого окна.
5. Использование окна меню.
Этап РАЗВИТИЕ (Elaboration)
Главное назначение этапа — создать архитектурный базис системы.
Цели этапа РАЗВИТИЕ:
q определить оставшиеся требования, функциональные требования формулировать как элементы Use Case;
q определить архитектурную платформу системы;
q отслеживать риск, устранить источники наибольшего риска;
q разработать план итераций этапа КОНСТРУИРОВАНИЕ.
Основные действия этапа РАЗВИТИЕ:
q развитие спецификации представления, полное формирование критических элементов Use Case, задающих дальнейшие решения;
q развитие архитектуры, выделение ее компонентов.
В итоге этапа РАЗВИТИЕ создаются следующие артефакты:
q модель Use Case (80% от полного представления);
q дополнительные требования (нефункциональные требования, а также другие требования, которые не связаны с конкретным элементом Use Case);
q описание программной архитектуры;
q выполняемый архитектурный макет;
q пересмотренный список элементов риска и пересмотренный бизнес-вариант;
q план разработки для всего проекта, включающий крупноблочный проектный план и показывающий итерации и критерий эволюции для каждой итерации.
Обсудим более подробно главную цель этапа РАЗВИТИЕ — создание архитектурного базиса.
Архитектура объектно-ориентированной системы многомерна — она описывается множеством параллельных представлений. Как показано на рис. 15.4, обычно используется «4+1»-представление [44].
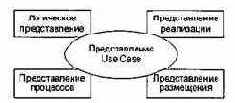
Рис. 15.4. «4+1»-представление архитектуры
Представление Use Case описывает систему как множество взаимодействий с точки зрения внешних актеров. Это представление создается на этапе НАЧАЛО жизненного цикла и управляет оставшейся частью процесса разработки.
Логическое представление содержит набор пакетов, классов и отношений. Изначально создается на этапе развития и усовершенствуется на этапе конструирования.
Представление процессов создается для параллельных программных систем, содержит процессы, потоки управления, межпроцессорные коммуникации и механизмы синхронизации. Представление изначально создается на этапе развития, усовершенствуется на этапе конструирования.
Представление реализации содержит модули и подсистемы. Представление изначально создается на этапе развития и усовершенствуется на этапе конструирования.
Представление размещения содержит физические узлы системы и соединения между узлами. Создается на этапе развития.
В качестве примера рассмотрим порядок создания логического представления архитектуры. Для решения этой задачи исследуются элементы Use Case, разработанные на этапе НАЧАЛО. Рассматриваются экземпляры элементов Use Case — сценарии. Каждый сценарий преобразуется в диаграмму последовательности. Далее в диаграммах последовательности выделяются объекты. Объекты группируются в классы. Классы могут группироваться в пакеты.
Согласно взаимодействиям между объектами в диаграммах последовательности устанавливаются отношения между классами. Для обеспечения функциональности в классы добавляются свойства (они определяют их структуру) и операторы (они определяют поведение). Для размещения общей структуры и поведения создаются суперклассы.
В качестве другого примера рассмотрим разработку плана итераций для этапа КОНСТРУИРОВАНИЕ. Такой план должен задавать управляемую серию архитектурных реализаций, каждая из которых увеличивает свои функциональные возможности, а конечная — покрывает все требования к полной системе. Главным источником информации являются элементы Use Case и диаграммы последовательности. Будем называть их обобщенно — сценариями. Сценарии группируются так, чтобы обеспечивать реализацию определенной функциональности системы. Кроме того, группировки должны устранять наибольший (в данный момент) риск в проекте.
План итераций включает в себя следующие шаги:
1. Определяются все элементы риска в проекте. Устанавливаются их приоритеты.
2. Выбирается группа сценариев, которым соответствуют элемент риска с наибольшим приоритетом. Сценарии исследуются. Порядок исследования определяется не только степенью риска, но и важностью для заказчика, а также потребностью ранней разработки базовых сценариев.
3. В результате анализа сценариев формируются классы и отношения, которые их реализуют.
4. Программируются сформированные классы и отношения.
5. Разрабатываются тестовые варианты.
6. Тестируются классы и отношения. Цель — проверить выполнение функционального назначения сценария.
7. Результаты объединяются с результатами предыдущих итераций, проводится тестирование интеграции.
8. Оценивается итерация. Выделяется необходимая повторная работа. Она назначается на будущую итерацию.
Этапы и итерации
По времени в жизненном цикле процесса выделяют четыре этапа:
q начало (Inception) — спецификация представления продукта;
q развитие (Elaboration) — планирование необходимых действий и требуемых ресурсов;
q конструирование (Construction) — построение программного продукта в виде серии инкрементных итераций;
q переход (Transition) — внедрение программного продукта в среду пользователя (промышленное производство, доставка и применение).
В свою очередь, каждый этап процесса разделяется на итерации. Итерация — это полный цикл разработки, вырабатывающий промежуточный продукт. По мере перехода от итерации к итерации промежуточный продукт инкрементно усложняется, постепенно превращаясь в конечную систему. В состав каждой итерации входят все рабочие потоки — от сбора требований до тестирования. От итерации к итерации меняется лишь удельный вес каждого рабочего потока — он зависит от этапа. На этапе Начало основное внимание уделяется сбору требований, на этапе Развитие — анализу и проектированию, на этапе Конструирование — реализации, на этапе Переход — тестированию. Каждый этап и итерация уменьшают некоторый риск и завершается контрольной вехой. К вехе привязывается техническая проверка степени достижения ключевых целей. По результатам проверки возможна модификация дальнейших действий.
Этапы унифицированного процесса разработки
Обсудим назначение, цели, содержание и основные итоги каждого этапа унифицированного процесса разработки.
Эволюция мер связи для объектно-ориентированных программных систем
В разделах «Связность модуля» и «Сцепление модулей» главы 4 было показано, что классической мерой сложности внутренних связей модуля является связность, а классической мерой сложности внешних связей — сцепление. Рассмотрим развитие этих мер применительно к объектно-ориентированным системам.
Эволюционно-инкрементная организация жизненного цикла разработки
Рассматриваемый подход является развитием спиральной модели Боэма [8], [40], [44], [57]. В этом случае процесс разработки программной системы организуется в виде эволюционно-инкрементного жизненного цикла. Эволюционная составляющая цикла основывается на доопределении требований в ходе работы, инкрементная составляющая — на планомерном приращении реализации требований.
В этом цикле разработка представляется как серия итераций, результаты которых развиваются от начального макета до конечной системы. Каждая итерация включает сбор требований, анализ, проектирование, реализацию и тестирование. Предполагается, что вначале известны не все требования, их дополнение и изменение осуществляется на всех итерациях жизненного цикла. Структура типовой итерации показана на рис. 15.1.
Видно, что критерием управления этим жизненным циклом является уменьшение риска. Работа начинается с оценки начального риска. В ходе выполнения каждой итерации риск пересматривается. Риск связывается с каждой итерацией так, что ее успешное завершение уменьшает риск. План последовательности реализаций гарантирует, что наибольший риск устраняется в первую очередь.
Такая методика построения системы нацелена на выявление и уменьшение риска в самом начале жизненного цикла. В итоге минимизируются затраты на уменьшение риска.

Рис. 15.1. Типовая итерация эволюционно-инкрементного жизненного цикла
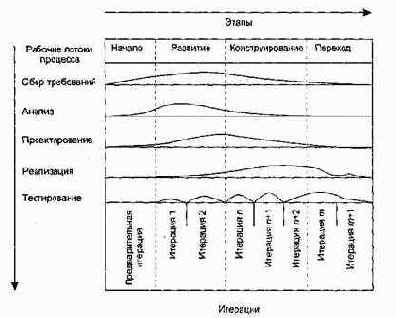
Рис. 15.2. Два измерения унифицированного процесса разработки
Как показано на рис. 15.2, в структуре унифицированного процесса разработки выделяют два измерения:
q горизонтальная ось представляет время и демонстрирует характеристики жизненного цикла процесса;
q вертикальная ось представляет рабочие потоки процесса, которые являются логическими группировками действий.
Первое измерение задает динамический аспект развития процесса в терминах циклов, этапов, итераций и контрольных вех. Второе измерение задает статический аспект процесса в терминах компонентов процесса, рабочих потоков, приводящих к выработке искусственных объектов (артефактов), и участников.
Классический жизненный цикл
Старейшей парадигмой процесса разработки ПО является классический жизненный цикл (автор Уинстон Ройс, 1970) [65].
Очень часто классический жизненный цикл называют каскадной или водопадной моделью, подчеркивая, что разработка рассматривается как последовательность этапов, причем переход на следующий, иерархически нижний этап происходит только после полного завершения работ на текущем этапе (рис. 1.1).
Охарактеризуем содержание основных этапов.
Подразумевается, что разработка начинается на системном уровне и проходит через анализ, проектирование, кодирование, тестирование и сопровождение. При этом моделируются действия стандартного инженерного цикла.
Системный анализ задает роль каждого элемента в компьютерной системе, взаимодействие элементов друг с другом. Поскольку ПО является лишь частью большой системы, то анализ начинается с определения требований ко всем системным элементам и назначения подмножества этих требований программному «элементу». Необходимость системного подхода явно проявляется, когда формируется интерфейс ПО с другими элементами (аппаратурой, людьми, базами данных). На этом же этапе начинается решение задачи планирования проекта ПО. В ходе планирования проекта определяются объем проектных работ и их риск, необходимые трудозатраты, формируются рабочие задачи и план-график работ.
Анализ требований относится к программному элементу — программному обеспечению. Уточняются и детализируются его функции, характеристики и интерфейс.
Все определения документируются в спецификации анализа. Здесь же завершается решение задачи планирования проекта.

Рис. 1.1. Классический жизненный цикл разработки ПО
Проектирование состоит в создании представлений:
q архитектуры ПО;
q модульной структуры ПО;
q алгоритмической структуры ПО;
q структуры данных;
q входного и выходного интерфейса (входных и выходных форм данных).
Исходные данные для проектирования содержатся в спецификации анализа, то есть в ходе проектирования выполняется трансляция требований к ПО во множество проектных представлений. При решении задач проектирования основное внимание уделяется качеству будущего программного продукта.
Кодирование состоит в переводе результатов проектирования в текст на языке программирования.
Тестирование — выполнение программы для выявления дефектов в функциях, логике и форме реализации программного продукта.
Сопровождение — это внесение изменений в эксплуатируемое ПО. Цели изменений:
q исправление ошибок;
q адаптация к изменениям внешней для ПО среды;
q усовершенствование ПО по требованиям заказчика.
Сопровождение ПО состоит в повторном применении каждого из предшествующих шагов (этапов) жизненного цикла к существующей программе но не в разработке новой программы.
Как и любая инженерная схема, классический жизненный цикл имеет достоинства и недостатки.
Достоинства классического жизненного цикла: дает план и временной график по всем этапам проекта, упорядочивает ход конструирования.
Недостатки классического жизненного цикла:
1) реальные проекты часто требуют отклонения от стандартной последовательности шагов;
2) цикл основан на точной формулировке исходных требований к ПО (реально в начале проекта требования заказчика определены лишь частично);
3) результаты проекта доступны заказчику только в конце работы.
Классы
Понятия объекта и класса тесно связаны. Тем не менее существует важное различие между этими понятиями. Класс — это абстракция существенных характеристик объекта.
Коллективное владение кодом
Организацию коллективного владения кодом иллюстрирует рис. 15.19.
Коллективное владение кодом позволяет каждому разработчику выдвигать новые идеи в любой части проекта, изменять любую строку программы, добавлять функциональность, фиксировать ошибку и проводить реорганизацию. Один человек просто не в состоянии удержать в голове проект нетривиальной системы. Благодаря коллективному владению кодом снижается риск принятия неверного решения (главным разработчиком) и устраняется нежелательная зависимость проекта от одного человека.
Работа начинается с создания тестов модуля, она должна предшествовать программированию модуля. Тесты необходимо помещать в библиотеку кодов вместе с кодом, который они тестируют. Тесты делают возможным коллективное создание кода и защищают код от неожиданных изменений. В случае обнаружения ошибки также создается тест, чтобы предотвратить ее повторное появление.
Кроме тестов модулей, создаются тесты приемки, они основываются на пользовательских историях. Эти тесты испытывают систему как «черный ящик» и ориентированы на требуемое поведение системы.

Рис. 15.19. Организация коллективного владения кодом
На основе результатов тестирования разработчики включают в очередную итерацию работу над ошибками. Вообще, следует помнить, что тестирование — один из краеугольных камней ХР.
Все коды в проекте создаются парами программистов, работающими за одним компьютером. Парное программирование приводит к повышению качества без дополнительных затрат времени. А это, в свою очередь, уменьшает расходы на будущее сопровождение программной системы.
Оптимальный вариант для парной работы — одновременно сидеть за компьютером, передавая друг другу клавиатуру и мышь. Пока один человек набирает текст и думает (тактически) о создаваемом методе, второй думает (стратегически) о размещении метода в классе.
Во время очередной итерации всех сотрудников перемещают на новые участки работы. Такие перемещения помогают устранить изоляцию знаний и «узкие места». Особенно полезна смена одного из разработчиков при парном программировании.
Замечено, что программисты очень консервативны. Они продолжают использовать код, который трудно сопровождать, только потому, что он все еще работает. Боязнь модификации кода у них в крови. Это приводит к предельному понижению эффективности систем. В ХР считают, что код нужно постоянно обновлять — удалять лишние части, убирать ненужную функциональность. Этот процесс называют реорганизацией кода (refactoring). Поощряется безжалостная реорганизация, сохраняющая простоту проектных решений. Реорганизация поддерживает прозрачность и целостность кода, обеспечивает его легкое понимание, исправление и расширение. На реорганизацию уходит значительно меньше времени, чем на сопровождение устаревшего кода. Увы, нет ничего вечного — когда-то отличный модуль теперь может быть совершенно не нужен.
И еще одна составляющая коллективного владения кодом — непрерывная интеграция.
Без последовательной и частой интеграции результатов в систему разработчики не могут быть уверены в правильности своих действий. Кроме того, трудно вовремя оценить качество выполненных фрагментов проекта и внести необходимые коррективы.
По возможности ХР-разработчики должны интегрировать и публично отображать, демонстрировать код каждые несколько часов. Интеграция позволяет объединить усилия отдельных пар и стимулирует повторное использование кода.
Коммуникативная связность
При коммуникативной связности элементы-обработчики модуля используют одни и те же данные, например внешние данные. Пример коммуникативно связного модуля:
Модуль Отчет и средняя зарплата
используется Таблица зарплаты служащих
сгенерировать Отчет по зарплате
вычислить параметр Средняя зарплата
вернуть Отчет по зарплате. Средняя зарплата
Конец модуля
Здесь все элементы модуля работают со структурой Таблица зарплаты служащих.
С точки зрения клиента проблема применения коммуникативно связного модуля состоит в избыточности получаемых результатов. Например, клиенту требуется только отчет по зарплате, он не нуждается в значении средней зарплаты. Такой клиент будет вынужден выполнять избыточную работу — выделение в полученных данных материала отчета. Почти всегда разбиение коммуникативно связного модуля на отдельные функционально связные модули улучшает сопровождаемость системы.
Попытаемся провести аналогию между информационной и коммуникативной связностью.
Модули с коммуникативной и информационной связностью подобны в том, что содержат элементы, связанные по данным. Их удобно использовать, потому что лишь немногие элементы в этих модулях связаны с внешней средой. Главное различие между ними — информационно связный модуль работает подобно сборочной линии; его обработчики действуют в определенном порядке; в коммуникативно связном модуле порядок выполнения действий безразличен. В нашем примере не имеет значения, когда генерируется отчет (до, после или одновременно с вычислением средней зарплаты).
Компонентно-ориентированная модель
Компонентно-ориентированная модель является развитием спиральной модели и тоже основывается на эволюционной стратегии конструирования. В этой модели конкретизируется содержание квадранта конструирования — оно отражает тот факт, что в современных условиях новая разработка должна основываться на повторном использовании существующих программных компонентов (рис. 1.7).
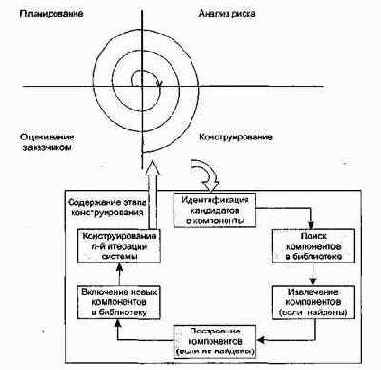
Рис. 1.7. Компонентно-ориентированная модель
Программные компоненты, созданные в реализованных программных проектах, хранятся в библиотеке. В новом программном проекте, исходя из требований заказчика, выявляются кандидаты в компоненты. Далее проверяется наличие этих кандидатов в библиотеке. Если они найдены, то компоненты извлекаются из библиотеки и используются повторно. В противном случае создаются новые компоненты, они применяются в проекте и включаются в библиотеку.
Достоинства компонентно-ориентированной модели:
1) уменьшает на 30% время разработки программного продукта;
2) уменьшает стоимость программной разработки до 70%;
3) увеличивает в полтора раза производительность разработки.
Компонентные диаграммы
Компонентная диаграмма — первая из двух разновидностей диаграмм реализации, моделирующих физические аспекты объектно-ориентированных систем. Компонентная диаграмма показывает организацию набора компонентов и зависимости между компонентами.
Элементами компонентных диаграмм являются компоненты и интерфейсы, а также отношения зависимости и реализации. Как и другие диаграммы, компонентные диаграммы могут включать примечания и ограничения. Кроме того, компонентные диаграммы могут содержать пакеты или подсистемы, используемые для группировки элементов модели в крупные фрагменты.
Компоненты
По своей сути компонент является физическим фрагментом реализации системы, который заключает в себе программный код (исходный, двоичный, исполняемый), сценарные описания или наборы команд операционной системз (имеются в виду командные файлы). Язык UML дает следующее определение.
Компонент — физическая и заменяемая часть системы, которая соответствует набору интерфейсов и обеспечивает реализацию этого набора интерфейсов.
Интерфейс — очень важная часть понятия «компонент», его мы обсудим в следующем подразделе. Графически компонент изображается как прямоугольник с вкладками, обычно включающий имя (рис. 13.1).

Рис. 13.1. Обозначение компонента
Компонент — базисный строительный блок физического представления ПО, поэтому интересно сравнить его с базисным строительным блоком логического представления ПО — классом.
Сходные характеристики компонента и класса:
q наличие имени;
q реализация набора интерфейсов;
q участие в отношениях зависимости;
q возможность быть вложенным;
q наличие экземпляров (экземпляры компонентов можно использовать только в диаграммах размещения).
Вы скажете — много общего. И тем не менее между компонентами и классами есть существенная разница, ее характеризует табл. 13.1.
Таблица 13.1. Различия компонентов и классов
| № | Описание | ||
| 1
2 3 | Классы — логические абстракции, компоненты — физические предметы, которые живут в мире битов. В частности, компоненты могут «жить» в физических узлах, а классы лишены такой возможности
Компоненты являются физическими упаковками, контейнерами, инкапсулирующими в себе различные логические элементы. Они — элементы абстракций другого уровня Классы имеют свойства и операции. Компоненты имеют только операции, которые доступны через их интерфейсы |
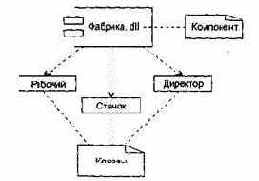
Рис. 13.2. Классы в компоненте
О чем говорят эти различия? Во-первых, класс не может «дышать» воздухом физического мира реализации. Ему нужен скафандр. Таким скафандром является компонент.
Во-вторых, им не жить друг без друга — пустые скафандры никому не нужны. Причем в скафандре-компоненте может находиться несколько классов и коопераций. Итак, в скафандре — физической реализации — располагается набор логики. Как показано на рис. 13.2, с помощью отношения зависимости можно явно отобразить отношение между компонентом и классами, которые он реализует. Правда, чаще всего такие отношения не отображаются. Их удобно представлять в компонентной спецификации.
В-третьих, класс — душа нараспашку (он может даже показать свои свойства). Компонент всегда застегнут на все пуговицы (правда, из него торчат интерфейсные разъемы операций).
Теперь уместно перейти к обсуждению интерфейсов.
Компоновка системы
За последние полвека разработчики аппаратуры прошли путь от компьютеров размером с комнату до крошечных «ноутбуков», обеспечивших возросшие функциональные возможности. За те же полвека разработчики программного обеспечения прошли путь от больших систем на Ассемблере и Фортране до еще больших систем на C++ и Java. Увы, но программный инструментарий развивается медленнее, чем аппаратный инструментарий. В чем главный секрет аппаратчиков? — спросят у аппаратчика-мальчиша программеры-буржуины.
Этот секрет — компоненты. Разработчик аппаратуры создает систему из готовых аппаратных компонентов (микросхем), выполняющих определенные функции и предоставляющих набор услуг через ясные интерфейсы. Задача конструкторов упрощается за счет повторного использования результатов, полученных другими.
Повторное использование — магистральный путь развития программного инструментария. Создание нового ПО из существующих, работоспособных программных компонентов приводит к более надежному и дешевому коду. При этом сроки разработки существенно сокращаются.
Основная цель программных компонентов — допускать сборку системы из двоичных заменяемых частей. Они должны обеспечить начальное создание системы из компонентов, а затем и ее развитие — добавление новых компонентов и замену некоторых старых компонентов без перестройки системы в целом. Ключ к воплощению такой возможности — интерфейсы. После того как интерфейс определен, к выполняемой системе можно подключить любой компонент, который удовлетворяет ему или обеспечивает этот интерфейс. Для расширения системы производятся компоненты, которые обеспечивают дополнительные услуги через новые интерфейсы. Такой подход основывается на особенностях компонента, перечисленных в табл. 13.2.
Таблица 13.2. Особенности компонента
| Компонент физичен. Он живет в мире битов, а не логических понятий и не зависит от языка программирования | |
| Компонент — заменяемый элемент. Свойство заменяемости позволяет заменить один компонент другим компонентом, который удовлетворяет тем же интерфейсам. Механизм замены оговорен современными компонентными моделями (COM, COM+, CORBA, Java Beans), требующими незначительных преобразований или предоставляющими утилиты, которые автоматизируют механизм | |
| Компонент является частью системы, он редко автономен. Чаще компонент сотрудничает с другими компонентами и существует в архитектурной или технологической среде, предназначенной для его использования. Компонент связан и физически, и логически, он обозначает фрагмент большой системы | |
| Компонент соответствует набору интерфейсов и обеспечивает реализацию этого набора интерфейсов |
Вывод: компоненты — базисные строительные блоки, из которых может проектироваться и составляться система. Компонент может появляться на различных уровнях иерархии представления сложной системы. Система на одном уровне абстракции может стать простым компонентом на более высоком уровне абстракции.
Конкретизация
Г. Буч определяет конкретизацию как процесс наполнения шаблона (родового или параметризованного класса). Целью является получение класса, от которого возможно создание экземпляров [22].
Родовой класс служит заготовкой, шаблоном, параметры которого могут наполняться (настраиваться) другими классами, типами, объектами, операциями. Он может быть родоначальником большого количества обычных (конкретных) классов. Возможности настройки родового класса представляются списком формальных родовых параметров. Эти параметры в процессе настройки должны заменяться фактическими родовыми параметрами. Процесс настройки родового класса называют конкретизацией.
В разных языках программирования родовые классы оформляются по-разному. Воспользуемся возможностями языка Ada 95, в котором впервые была реализована идея настройки-параметризации. Здесь формальные родовые параметры записываются между словом generic и заголовком пакета, размещающего класс.
Пример: представим родовой (параметризированный) класс Очередь:
generic
type Элемент is private;
package Класс_Очередь is
type Очередь is limited tagged private;
…
procedure Добавить (В_0чередь: in out Очередь;
элт: Элемент );
…
private
…
end Класс_0чередь;
У этого класса один формальный родовой параметр — тип Элемент. Вместо этого параметра можно подставить почти любой тип данных.
Произведем настройку, то есть объявим два конкретизированных класса — Оче-редьЦелыхЭлементов и ОчередьЛилипутов:
package Класс_ОчередьЦелыхЭлементов is new Класс_0чередь
(Элемент => Integer);
package Класс_ОчередьЛилипутов is new Класс_0чередь
(Элемент => Лилипут);
В первом случае мы настраивали класс на конкретный тип Integer (фактический родовой параметр), во втором случае — на конкретный тип Лилипут.
Классы ОчередьЦелыхЭлементов и ОчередьЛилипутов можно использовать как обычные классы. Они содержат все средства родового класса, но только эти средства настроены на использование конкретного типа, заданного при конкретизации.
Графическая иллюстрация отношений конкретизации приведена на рис. 9.17. Отметим, что отношение конкретизации отображается с помощью подписанной стрелки отношения зависимости. Это логично, поскольку конкретизированный класс зависит от родового класса (класса-шаблона).
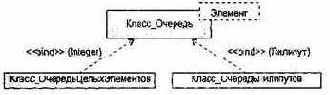
Рис. 9.17. Отношения конкретизации родового класса
Конструктивная модель стоимости
В данной модели для вывода формул использовался статистический подход — учитывались реальные результаты огромного количества проектов. Автор оригинальной модели — Барри Боэм (1981) —дал ей название СОСОМО 81 (Constructive Cost Model) и ввел в ее состав три разные по сложности статистические подмодели [1].
Иерархию подмоделей Боэма (версии 1981 года) образуют:
q базисная СОСОМО — статическая модель, вычисляет затраты разработки и ее стоимость как функцию размера программы;
q промежуточная СОСОМО — дополнительно учитывает атрибуты стоимости, включающие основные оценки продукта, аппаратуры, персонала и проектной среды;
q усовершенствованная СОСОМО — объединяет все характеристики промежуточной модели, дополнительно учитывает влияние всех атрибутов стоимости на каждый этап процесса разработки ПО (анализ, проектирование, кодирование, тестирование и т. д.).
Подмодели СОСОМО 81 могут применяться к трем типам программных проектов. По терминологии Боэма, их образуют:
q распространенный тип — небольшие программные проекты, над которыми работает небольшая группа разработчиков с хорошим стажем работы, устанавливаются мягкие требования к проекту;
q полунезависимый тип — средний по размеру проект, выполняется группой разработчиков с разным опытом, устанавливаются как мягкие, так и жесткие требования к проекту;
q встроенный тип — программный проект разрабатывается в условиях жестких аппаратных, программных и вычислительных ограничений.
Уравнения базовой подмодели имеют вид
Е=аbx(KLOC)

D = cbx (E)

где Е — затраты в человеко-месяцах, D — время разработки, KLOC — количество строк в программном продукте.
Коэффициенты аb, bb, сb, db берутся из табл. 2.14.
Таблица 2.14. Коэффициенты для базовой подмодели СОСОМО 81
| Тип проекта | аb | bb | сb | db | |||||
| Распространенный | 2,4 | 1,05 | 2,5 | 0,38 | |||||
| Полунезависимый | 3,0 | 1,12 | 2,5 | 0,35 | |||||
| Встроенный | 3,6 | 1,20 | 2,5 | 0,32 |
В 1995 году Боэм ввел более совершенную модель СОСОМО II, ориентированную на применение в программной инженерии XXI века [21].
В состав СОСОМО II входят:
q модель композиции приложения;
q модель раннего этапа проектирования;
q модель этапа пост-архитектуры.
Для описания моделей СОСОМО II требуется информация о размере программного продукта. Возможно использование LOC-оценок, объектных указателей, функциональных указателей.
Контрольные вопросы
1. Дайте определение технологии конструирования программного обеспечения.
2. Какие этапы классического жизненного цикла вы знаете?
3. Охарактеризуйте содержание этапов классического жизненного цикла.
4. Объясните достоинства и недостатки классического жизненного цикла.
5. Чем отличается классический жизненный цикл от макетирования?
6. Какие существуют формы макетирования?
7. Чем отличаются друг от друга стратегии конструирования ПО?
8. Укажите сходства и различия классического жизненного цикла и инкрементной модели.
9. Объясните достоинства и недостатки инкрементной модели.
10. Чем отличается модель быстрой разработки приложений от инкрементной модели?
11. Объясните достоинства и недостатки модели быстрой разработки приложений.
12. Укажите сходства и различия спиральной модели и классического жизненного цикла.
13. В чем состоит главная особенность спиральной модели?
14. Чем отличается компонентно-ориентированная модель от спиральной модели и классического жизненного цикла?
15. Перечислите достоинства и недостатки компонентно-ориентированной модели.
16. Чем отличаются тяжеловесные процессы от облегченных процессов?
17. Чем отличаются тяжеловесные процессы от прогнозирующих процессов?
18. Чем отличаются подвижные процессы от облегченных процессов?
19. Перечислите достоинства и недостатки тяжеловесных процессов.
20. Перечислите достоинства и недостатки облегченных процессов.
21. Приведите примеры тяжеловесных процессов.
22. Приведите примеры облегченных процессов.
23. Перечислите характеристики ХР-процесса.
24. Перечислите методы ХР-процесса.
25. В чем состоит главная особенность ХР-процесса?
26. Охарактеризуйте содержание игры планирования в ХР-процессе.
27. Охарактеризуйте назначение метафоры в ХР-процессе.
28. Какова особенность проектирования в ХР-процессе?
29. Какова особенность программирования в ХР-процессе?
30. Что такое реорганизация?
31. Что такое коллективное владение?
32. Какова особенность тестирования в ХР-процессе?
33. Чем отличается ХР-реализация от ХР-итерации?
34. Чем ХР-реализация похожа на ХР-итерацию?
35. Какова длительность ХР-реализации?
36. Какова длительность ХР-итерации?
37. Какова максимальная численность группы ХР-разработчиков?
38. Какие модели качества процессов конструирования вы знаете?
39. Охарактеризуйте модель СММ.
40. Охарактеризуйте уровень зрелости знакомой вам фирмы.
1. Что такое мера?
2. Что такое метрика?
3. Что такое выполнение оценки программного проекта?
4. Что такое анализ риска?
5. Что такое трассировка и контроль?
6. Охарактеризуйте содержание Work Breakdown Structure.
7. Охарактеризуйте рекомендуемое правило распределения затрат проекта.
8. Какие размерно-ориентированные метрики вы знаете?
9. Для чего используют размерно-ориентированные метрики?
10. Определите достоинства и недостатки размерно-ориентированных метрик.
11. Что такое функциональный указатель?
12. От каких информационных характеристик зависит функциональный указатель?
13. Как вычисляется количество функциональных указателей?
14. Что такое коэффициенты регулировки сложности в метрике количества функциональных указателей?
15. Определите достоинства и недостатки функционально-ориентированных метрик.
16. Можно ли перейти от FP-оценок к LOC-оценкам?
17. Охарактеризуйте шаги оценки проекта на основе LOC- и FP-метрик. Чем отличается наиболее точный подход от наименее точного?
18. Что такое конструктивная модель стоимости? Для чего она применяется?
19. Чем отличается версия СОСОМО 81 от версии СОСОМО II?
20. В чем состоит назначение модели композиции? На каких оценках она базируется?
21. В чем состоит назначение модели раннего этапа проектирования?
22. Охарактеризуйте основное уравнение модели раннего этапа проектирования.
23. Охарактеризуйте масштабные факторы модели СОСОМО II.
24. Как оцениваются масштабные факторы?
25. В чем состоит назначение модели этапа пост-архитектуры СОСОМО II?
26. Чем отличается основное уравнение модели этапа пост-архитектуры от аналогичного уравнения модели раннего этапа проектирования?
27. Что такое факторы затрат модели этапа пост-архитектуры и как они вычисляются?
28. Как определяется длительность разработки в модели СОСОМО II?
29. Что такое анализ чувствительности программного проекта?
30. Как применить модель СОСОМО II к анализу чувствительности?
1. Какие задачи решает аппарат анализа?
2. Что такое диаграмма потоков данных?
3. Чем отличается диаграмма потоков данных от блок-схемы алгоритма?
4. Какие элементы диаграммы потоков данных вы знаете?
5. Как формируется иерархия диаграмм потоков данных?
6. Какую задачу решает диаграмма потоков данных высшего (нулевого) уровня? Почему ее называют контекстной моделью?
7. Чем нагружены вершины диаграммы потоков данных?
8. Чем нагружены дуги диаграммы потоков данных?
9. Как организован словарь требований?
10. С чем связана необходимость расширения диаграмм потоков данных для систем реального времени? Какие средства расширения вы знаете?
11. Как решается проблема расширения возможностей управления на базе диаграмм потоков данных?
12. Каковы особенности диаграммы управляющих потоков?
13. Поясните понятие активатора процесса.
14. Поясните понятие условия данных.
15. Поясните понятие управляющей спецификации.
16. Поясните понятие окна управляющей спецификации.
17. Как организована спецификация процесса?
18. Поясните назначение таблицы активации процессов.
19. Поясните организацию диаграммы переходов-состояний.
20. Какие задачи решают методы анализа, ориентированные на структуры данных?
21. Какие методы анализа, ориентированные на структуры данных, вы знаете?
22. Из каких базовых элементов состоят диаграммы Варнье?
23. Какие шаги выполняет метод Джексона на этапе анализа?
24. Какие типы структурных диаграмм Джексона вы знаете?
25. Как организовано в методе Джексона обнаружение объектов?
26. Что такое структура объектов Джексона?
27. Как создается структура объектов Джексона?
28. Поясните диаграмму системной спецификации Джексона.
29. Чем отличается соединение потоком данных от соединения по вектору состояний?
30. Какова задача структурного текста Джексона?
1. Какова цель синтеза программной системы? Перечислите этапы синтеза.
2. Дайте определение разработки данных, разработки архитектуры и процедурной разработки.
3. Какие особенности имеет этап проектирования?
4. Решение каких задач обеспечивает предварительное проектирование?
5. Какие модели системного структурирования вы знаете?
6. Чем отличается модель клиент-сервер от трехуровневой модели?
7. Какие типы моделей управления вы знаете?
8. Какие существуют разновидности моделей централизованного управления?
9. Поясните разновидности моделей событийного управления.
10. Поясните понятия модуля и модульности. Зачем используют модули?
11. В чем состоит принцип информационной закрытости? Какие достоинства он имеет?
12. Что такое связность модуля?
13. Какие существуют типы связности?
14. Дайте характеристику функциональной связности.
15. Дайте характеристику информационной связности.
16. Охарактеризуйте коммуникативную связность.
17. Охарактеризуйте процедурную связность.
18. Дайте характеристику временной связности.
19. Дайте характеристику логической связности.
20. Охарактеризуйте связность по совпадению.
21. Что значит «улучшать связность» ?
22. Что такое сцепление модуля?
23. Какие существуют типы сцепления?
24. Дайте характеристику сцепления по данным.
25. Дайте характеристику сцепления по образцу.
26. Охарактеризуйте сцепление по управлению.
27. Охарактеризуйте сцепление по внешним ссылкам.
28. Дайте характеристику сцепления по общей области.
29. Дайте характеристику сцепления по содержанию.
30. Что значит «улучшать сцепление»?
31. Какие подходы к оценке сложности системы вы знаете?
32. Что определяет иерархическая структура программной системы?
33. Поясните первичные характеристики иерархической структуры.
34. Поясните понятия коэффициента объединения по входу и коэффициента раз ветвления по выходу.
35. Что определяет невязка структуры?
36. Поясните информационные коэффициенты объединения и разветвления.
1. В чем состоит суть метода структурного проектирования?
2. Какие различают типы информационных потоков?
3. Что такое входящий поток?
4. Что такое выходящий поток?
5. Что такое центр преобразования?
6. Как производится отображение входящего потока?
7. Как производится отображение выходящего потока?
8. Как производится отображение центра преобразования?
9. Какие задачи решают главный контроллер, контроллер входящего потока, контроллер выходящего потока и контроллер центра преобразования?
10. Поясните шаги метода структурного проектирования.
11. Что такое входящая ветвь?
12. Что такое диспетчерская ветвь?
13. Какие существуют различия в методике отображения потока преобразований и потока запросов?
14. Какие задачи уточнения иерархической структуры программной системы вы знаете?
15. Какие шаги предусматривает метод Джексона на этапе проектирования?
16. В чем состоит суть развития диаграммы системной спецификации Джексона?
17. Поясните понятие встроенной функции.
18. Поясните понятие функции впечатления.
19. Поясните понятие функции диалога.
20. В чем состоит учет системного времени (в методе Джексона)?
1. Определите понятие тестирования.
2. Что такое тест? Поясните содержание процесса тестирования.
3. Что такое исчерпывающее тестирование?
4. Какие задачи решает тестирование?
5. Каких задач не решает тестирование?
6. Какие принципы тестирования вы знаете? В чем их отличие друг от друга?
7. В чем состоит суть тестирования «черного ящика»?
8. В чем состоит суть тестирования «белого ящика»?
9. Каковы особенности тестирования «белого ящика»?
10. Какие недостатки имеет тестирование «белого ящика»?
11. Какие достоинства имеет тестирование «белого ящика»?
12. Дайте характеристику способа тестирования базового пути.
13. Какие особенности имеет потоковый граф?
14. Поясните понятие независимого пути.
15. Поясните понятие цикломатической сложности.
16. Что такое базовое множество?
17. Какие свойства имеет базовое множество?
18. Какие способы вычисления цикломатической сложности вы знаете?
19. Поясните шаги способа тестирования базового пути.
20. Поясните достоинства, недостатки и область применения способа тестирования базового пути.
21. Дайте общую характеристику способов тестирования условий.
22. Какие типы ошибок в условиях вы знаете?
23. Какие методики тестирования условий вы знаете?
24. Поясните суть способа тестирования ветвей и операторов отношений. Какие он имеет ограничения?
25. Что такое ограничение на результат?
26. Что такое ограничение условия?
27. Что такое ограничивающее множество? Чем удобно его применение?
28. Поясните шаги способа тестирования ветвей и операторов отношений.
29. Поясните достоинства, недостатки и область применения способа тестирования ветвей и операторов отношений.
30. Поясните суть способа тестирования потоков данных.
31. Что такое множество определений данных?
32. Что такое множество использований данных?
33. Что такое цепочка определения-использования?
34. Поясните шаги способа тестирования потоков данных.
35. Поясните достоинства, недостатки и область применения способа тестирования потоков данных.
36. Поясните особенности тестирования циклов.
37. Какие методики тестирования простых циклов вы знаете?
38. Каковы шаги тестирования вложенных циклов?
1. Каковы особенности тестирования методом «черного ящика»?
2. Какие категории ошибок выявляет тестирование методом «черного ящика»?
3. Какие достоинства имеет тестирование методом «черного ящика»?
4. Поясните суть способа разбиения по эквивалентности.
5. Что такое класс эквивалентности?
6. Что может задавать условие ввода?
7. Какие правила формирования классов эквивалентности вы знаете?
8. Как выбирается тестовый вариант при тестировании по способу разбиения по эквивалентности?
9. Поясните суть способа анализа граничных значений.
10. Чем способ анализа граничных значений отличается от разбиения по эквивалентности?
11. Поясните правила анализа граничных значений.
12. Что такое дерево разбиений? Каковы его особенности?
13. В чем суть способа диаграмм причин-следствий?
14. Что такое причина?
15. Что такое следствие?
16. Дайте общую характеристику графа причинно-следственных связей.
17. Какие функции используются в графе причин и следствий?
18. Какие ограничения используются в графе причин и следствий?
19. Поясните шаги способа диаграмм причин-следствий.
20. Какую структуру имеет таблица решений в способе диаграмм причин-следствий?
21. Как таблица решений преобразуется в тестовые варианты?
1. Поясните суть методики тестирования программной системы.
2. Когда и зачем выполняется тестирование элементов? Какой этап конструирования оно проверяет?
3. Когда и зачем выполняется тестирование интеграции? Какой этап конструирования оно проверяет?
4. Когда и зачем выполняется тестирование правильности? Какой этап конструирования оно проверяет?
5. Когда и зачем выполняется системное тестирование? Какой этап конструирования оно проверяет?
6. Поясните суть тестирования элементов.
7. Перечислите наиболее общие ошибки вычислений.
8. Перечислите источники ошибок сравнения и неправильных потоков управления.
9. На какие ситуации ориентировано тестирование путей обработки ошибок?
10. Что такое драйвер тестирования?
11. Что такое заглушка?
12. Поясните порядок работы драйвера тестирования.
13. В чем цель тестирования интеграции?
14. Какие категории ошибок интерфейса вы знаете?
15. В чем суть нисходящего тестирования интеграции?
16. Поясните шаги процесса нисходящей интеграции.
17. Поясните достоинства и недостатки нисходящей интеграции.
18. Какие категории заглушек вы знаете?
19. В чем суть восходящего тестирования интеграции?
20. Поясните шаги процесса восходящей интеграции.
21. Поясните достоинства и недостатки восходящей интеграции.
22. Какие категории драйверов вы знаете?
23. Какова комбинированная стратегия интеграции?
24. Каковы признаки критического модуля?
25. Что такое регрессионное тестирование?
26. В чем суть тестирования правильности?
27. Какие элементы включает минимальная конфигурация программной системы?
28. Что такое альфа-тестирование?
29. Что такое бета-тестирование?
30. В чем суть системного тестирования?
31. Как защищаться от проблемы «указание причины»?
32. В чем суть тестирования восстановления?
33. В чем суть тестирования безопасности?
34. В чем суть стрессового тестирования?
35. В чем суть тестирования производительности?
36. Что такое отладка?
37. Какие способы проявления ошибок вы знаете?
38. Какие симптомы ошибки вы знаете?
39. В чем суть аналитических методов отладки?
40. Поясните достоинства и недостатки аналитических методов отладки.
41. В чем суть экспериментальных методов отладки?
42. Поясните достоинства и недостатки экспериментальных методов отладки.
1. В чем отличие алгоритмической декомпозиции от объектно-ориентированной декомпозиции сложной системы?
2. В чем особенность объектно-ориентированного абстрагирования?
3. В чем особенность объектно-ориентированной инкапсуляции?
4. Каковы средства обеспечения объектно-ориентированной модульности?
5. Каковы особенности объектно-ориентированной иерархии? Какие разновидности этой иерархии вы знаете?
6. Дайте общую характеристику объектов.
7. Что такое состояние объекта?
8. Что такое поведение объекта?
9. Какие виды операций вы знаете?
10. Что такое протокол объекта?
11. Что такое обязанности объекта?
12. Чем отличаются активные объекты от пассивных объектов?
13. Что такое роли объектов?
14. Чем отличается объект от класса?
15. Охарактеризуйте связи между объектами.
16. Охарактеризуйте роли объектов в связях.
17. Какие формы видимости между объектами вы знаете?
18. Охарактеризуйте отношение агрегации между объектами. Какие разновидности агрегации вы знаете?
19. Дайте общую характеристику класса.
20. Поясните внутреннее и внешнее представление класса.
21. Какие вы знаете секции в интерфейсной части класса?
22. Какие виды отношений между классами вы знаете?
23. Поясните ассоциации между классами.
24. Поясните наследование классов.
25. Поясните понятие полиморфизма.
26. Поясните отношения агрегации между классами.
27. Объясните нетрадиционные формы представления агрегации.
28. Поясните отношения зависимости между классами.
29. Поясните отношение конкретизации между классами.
1. Сколько поколений языков визуального моделирования вы знаете?
2. Назовите численность языков визуального моделирования 2-го поколения.
3. Какая необходимость привела к созданию языка визуального моделирования третьего поколения?
4. Поясните назначение UML.
5. Какие строительные блоки образуют словарь UML? Охарактеризуйте их.
6. Какие разновидности предметов UML вы знаете? Их назначение?
7. Перечислите известные вам разновидности структурных предметов UML.
8. Перечислите известные вам разновидности предметов поведения UML.
9. Перечислите известные вам группирующие предметы UML.
10. Перечислите известные вам поясняющие предметы UML.
11. Какие разновидности отношений предусмотрены в UML? Охарактеризуйте каждое отношение.
12. Дайте характеристику диаграммы классов.
13. Дайте характеристику диаграммы объектов.
14. Охарактеризуйте диаграмму Use Case.
15. Охарактеризуйте диаграммы взаимодействия.
16. Дайте характеристику диаграммы последовательности.
17. Дайте характеристику диаграммы сотрудничества.
18. Охарактеризуйте диаграмму схем состояний.
19. Охарактеризуйте диаграмму деятельности.
20. Дайте характеристику компонентной диаграммы.
21. Охарактеризуйте диаграмму размещения.
22. Для чего служат механизмы расширения в UML?
23. Поясните механизм ограничений в UML.
24. Объясните механизм теговых величин в UML.
25. В чем суть механизма стереотипов UML?
1. Поясните назначение статических моделей объектно-ориентированных программных систем.
2. Что является основным средством для представления статических моделей?
3. Как используются статические модели?
4. Какие секции входят в графическое обозначение класса?
5. Какие секции класса можно не показывать?
6. Какие имеются разновидности области действия свойства (операции)?
7. Поясните общий синтаксис представления свойства.
8. Какие уровни видимости вы знаете? Их смысл?
9. Какие характеристики свойств вам известны?
10. Поясните общий синтаксис представления операции.
11. Какой вид имеет форма представления параметра операции?
12. Какие характеристики операций вам известны?
13. Что означают три точки в списке свойств (операций)?
14. Как организуется группировка свойств (операций)?
15. Как ограничить количество экземпляров класса?
16. Перечислите известные вам «украшения» отношения ассоциации.
17. Может ли статическая модель программной системы не иметь отношений ассоциации?
18. Какой смысл имеет квалификатор? К чему он относится?
19. Какие отношения могут иметь пометки видимости и что эти пометки обозначают?
20. Какой смысл имеет класс-ассоциация?
21. Чем отличается агрегация от композиции? Разновидностями какого отношения (в UML) они являются?
22. Что обозначает в UML простая зависимость?
23. Какой смысл имеет отношение обобщения?
24. Какие недостатки у множественного наследования?
25. Перечислите недостатки ромбовидной решетки наследования.
26. В чем смысл отношения реализации?
27. Что обозначает мощность «многие-ко-многим» и в каких отношениях она применяется?
28. Что такое абстрактный класс (операция) и как он (она) отображается?
29. Как запретить полиморфизм операции?
30. Как обозначить корневой класс?
1. Поясните два подхода к моделированию поведения системы. Объясните достоинства и недостатки каждого из этих подходов.
2. Охарактеризуйте вершины и дуги диаграммы схем состояний. В чем состоит назначение этой диаграммы?
3. Как отображаются действия в состояниях диаграммы схем состояний?
4. Как показываются условные переходы между состояниями?
5. Как задаются вложенные состояния в диаграммах схем состояний?
6. Поясните понятие исторического подсостояния.
7. Охарактеризуйте средства и возможности диаграммы деятельности.
8. Когда не следует применять диаграмму деятельности?
9. Какие средства диаграммы деятельности позволяют отобразить параллельные действия?
10. Зачем в диаграмму деятельности введены плавательные дорожки?
11. Как представляется имя объекта в диаграмме сотрудничества?
12. Поясните синтаксис представления свойства в диаграмме сотрудничества.
13. Какие стереотипы видимости используются в диаграмме сотрудничества? Поясните их смысл.
14. В какой форме записываются сообщения в языке UML? Поясните смысл сообщения.
1. В чем основное назначение моделей реализации?
2. Какие вершины и дуги образуют компонентную диаграмму?
3. Что такое компонент? Чем он отличается от класса?
4. Что такое интерфейс?
5. Какие формы представления интерфейса вы знаете?
6. Чем полезен интерфейс?
7. Какие разновидности компонентов вы знаете?
8. Для чего используют компонентные диаграммы?
9. Каково назначение СОМ? Какие преимущества дает использование СОМ?
10. Чем СОМ-объект отличается от обычного объекта?
11. Что должен иметь клиент для использования операции СОМ-объекта?
12. Как идентифицируется СОМ-интерфейс?
13. Как описывается СОМ-интерфейс?
14. Как реализуется СОМ-интерфейс?
15. Чего нельзя делать с СОМ-интерфейсом? Обоснуйте ответ.
16. Объясните назначение и применение операции Querylnterface.
17. Объясните назначение и применение операций AddRef и Release.
18. Что такое сервер СОМ-объекта и какие типы серверов вы знаете?
19. В чем назначение библиотеки СОМ?
20. Как создается одиночный СОМ-объект?
21. Как создаются несколько СОМ-объектов одного и того же класса?
22. Как обеспечить использование нового СОМ-класса старыми клиентами?
23. В чем состоят особенности повторного использования СОМ-объектов?
24. Какие требования предъявляет агрегация к внутреннему СОМ-объекту?
25. Что такое маршалинг и демаршалинг?
26. Поясните назначение посредника и заглушки.
27. Зачем нужна библиотека типа и как она описывается?
28. Какие вершины и ребра образуют диаграмму размещения?
29. Чем отличается узел от компонента?
30. Где можно использовать и где нельзя использовать экземпляры компонентов?
31. Как применяют диаграммы размещения?
1. Какие факторы объектно-ориентированных систем влияют на метрики для их оценки и как проявляется это влияние?
2. Какое влияние оказывает наследование на связность классов?
3. Охарактеризуйте метрики связности классов по данным.
4. Охарактеризуйте метрики связности классов по методам.
5. Какие характеристики объектно-ориентированных систем ухудшают сцепление классов?
6. Объясните, как определить сцепление классов с помощью метрики «зависимость изменения между классами».
7. Поясните смысл метрики локальности данных.
8. Какие метрики входят в набор Чидамбера и Кемерера? Какие задачи они решают?
9. Как можно подсчитывать количество методов в классе?
10. Какие метрики Чидамбера и Кемерера оценивают сцепление классов? Поясните их смысл.
11. Какая метрика Чидамбера и Кемерера оценивает связность класса? Поясните ее смысл.
12. Как добиться независимости метрики WMC от реализации?
13. Как можно оценить информационную закрытость класса?
14. Сравните наборы Чидамбера-Кемерера и Лоренца-Кидда. Чем они похожи? В чем различие?
15. На какие цели ориентирован набор метрик Фернандо Абреу?
16. Охарактеризуйте состав набора метрик Фернандо Абреу.
17. Сравните наборы Чидамбера-Кемерера и Фернандо Абреу. Чем они похожи? В чем различие?
18. Сравните наборы Лоренца-Кидда и Фернандо Абреу. Чем они похожи? В чем различие?
19. Дайте характеристику метрик для объектно-ориентированного тестирования.
1. Что является критерием управления унифицированным процессом разработки? Как он применяется?
2. Какую структуру имеет унифицированный процесс разработки?
3. Какие этапы входят в унифицированный процесс разработки? Поясните назначение этих этапов.
4. Какие рабочие потоки имеются в унифицированном процессе разработки? Поясните назначение этих потоков.
5. Какие модели предусмотрены в унифицированном процессе разработки? Поясните назначение этих моделей.
6. Какие технические артефакты определены в унифицированном процессе разработки? Поясните назначение этих артефактов.
7. В чем суть управления риском?
8. Какие действия определяют управление риском?
9. Какие источники проектного риска вы знаете? 10. Какие источники технического риска вы знаете? И. Какие источники коммерческого риска вы знаете?
12. В чем суть анализа риска?
13. В чем состоит ранжирование риска?
14. В чем состоит планирование управления риском?
15. Что означает разрешение и наблюдение риска? Поясните методику «Отслеживание 10 верхних элементов риска».
1. Что такое CRC-карта? Как ее применить для тестирования визуальных моделей?
2. Поясните особенности тестирования объектно-ориентированных модулей.
3. В чем состоит суть методики тестирования интеграции объектно-ориентированных систем, основанной на потоках?
4. Поясните содержание методики тестирования интеграции объектно-ориентированных систем, основанной на использовании.
5. В чем заключаются особенности объектно-ориентированного тестирования правильности?
6. К чему приводит учет инкапсуляции, полиморфизма и наследования при проектировании тестовых вариантов?
7. Поясните содержание тестирования, основанного на ошибках.
8. Поясните содержание тестирования, основанного на сценариях.
9. Чем отличается тестирование поверхностной структуры от тестирования глубинной структуры системы?
10. В чем состоит стохастическое тестирование класса?
11. Охарактеризуйте тестирование разбиений на уровне классов. Как в этом случае получить категории разбиения?
12. Поясните на примере разбиение на категории по состояниям.
13. Приведите пример разбиения на категории по свойствам.
14. Перечислите известные вам методы тестирования взаимодействия классов. Поясните их содержание.
15. Приведите пример стохастического тестирования взаимодействия классов.
16. Приведите пример тестирования взаимодействия классов путем разбиений.
17. Приведите пример тестирования взаимодействия классов на основе состояний. В чем заключается особенность методики «преимущественно в ширину»?
18. Поясните суть предваряющего тестирования.
19. Какую роль в процессе экстремальной разработки играет рефакторинг?
Кооперации и паттерны
Кооперации (сотрудничества) являются средством представления комплексных решений в разработке ПО на высшем, архитектурном уровне. С одной стороны, ^ кооперации обеспечивают компактность цельной спецификации программного продукта, с другой стороны — несут в себе реализации потоков управления и данных, а также структур данных.
В терминологии фирмы Rational (вдохновителя и организатора побед языка UML) кооперации называют реализациями элементов Use Case, да и обозначения их весьма схожи (рис. 12.42).

Рис. 12.42. Элемент Use Case и его реализация
Обратите внимание на то, что и связаны эти элементы отношением реализации: кооперация реализует конкретный элемент Use Case.
Кооперации содержат две составляющие — статическую (структурную) и динамическую (поведенческую).
Статическая составляющая кооперации задает структуру совместно работающих классов и других элементов (интерфейсов, компонентов, узлов). Чаще всего для этого используют одну или несколько диаграмм классов. Динамическая составляющая кооперации определяет поведение совместно работающих элементов. Обычно для определения применяют одну или несколько диаграмм последовательности.
Таким образом, если заглянуть под «обложку» кооперации, мы увидим набор разнообразных диаграмм. Например, требования к информационной системе авиакассы задаются множеством элементов Use Case, каждый из которых реализуется отдельной кооперацией. Все эти кооперации применяют одни и те же классы, но все же имеют разную функциональную организацию. В частности, поведение кооперации для заказа авиабилета может описываться диаграммой последовательности, показанной на рис. 12.43.
Соответственно, структура кооперации для заказа авиабилета может иметь вид, представленный на рис. 12.44.
Важно понимать, что кооперации отражают понятийный аспект архитектуры системы. Один и тот же элемент может участвовать в различных кооперациях. Ведь речь здесь идет не о владении элементом, а только о его применении.
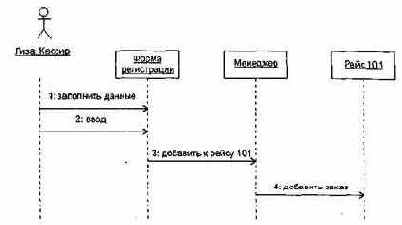
Рис. 12.43. Динамическая составляющая кооперации Заказ авиабилета
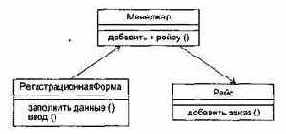
Рис. 12.44. Статическая составляющая кооперации Заказ авиабилета
Рис. 12.45. Обозначение паттерна
Параметризованные, то есть настраиваемые кооперации называют паттернами (образцами). Паттерн является решением типичной проблемы в определенном контексте. Обозначение паттерна имеет вид, представленный на рис. 12.45.
На место параметров настройки паттерна подставляются различные фактические параметры, в результате создаются разные кооперации.
Паттерны рассматриваются как крупные строительные блоки. Их использование приводит к существенному сокращению затрат на анализ и проектирование ПО. повышению качества и правильности разработки на логическом уровне, ведь паттерны создаются опытными профессионалами и отражают проверенные и оптимизированные решения [26], [31], [68].
Итак, паттерны — это наборы готовых решений, рецепты, предлагающие к повторному использованию самое ценное для разработчика — сплав мирового опыта по созданию ПО.
Наиболее распространенные паттерны формализуют и сводят в единые каталоги. Самым известным каталогом проектных паттернов, обеспечивающих этап проектирования ПО, считают каталог «Команды четырех» (Э. Гамма и др.). Он включает в себя 23 паттерна, разделенные на три категории [31]. Как показано в табл. 12.1, по мнению «Команды четырех», описание паттерна должно состоять из четырех основных частей.
Таблица 12.1. Описание паттерна
|
Раздел |
Описание |
|
Имя Проблема Решение Результаты |
Выразительное имя паттерна дает возможность указать проблему проектирования, ее решение и последствия ее решения. Использование имен паттернов повышает уровень абстракции проектирования Формулируется проблема проектирования (и ее контекст), на которую ориентировано применение паттерна. Задаются условия применения Описываются элементы решения, их отношения, обязанности, сотрудничество. Решение представляется в обобщенной форме, которая должна конкретизироваться при применении. Фактически приводится шаблон решения — его можно использовать в самых разных ситуациях Перечисляются следствия применения паттерна и вытекающие из них компромиссы. Такая информация позволяет оценить эффективность применения паттерна в данной ситуации |
Логическая связность
Элементы логически связного модуля принадлежат к действиям одной категории, и из этой категории клиент выбирает выполняемое действие. Рассмотрим следующий пример:
Модуль Пересылка сообщения
переслать по электронной почте
переслать по факсу
послать в телеконференцию
переслать по ftp-протоколу
Конец модуля
Как видим, логически связный модуль — мешок доступных действий. Действия вынуждены совместно использовать один и тот же интерфейс модуля. В строке вызова модуля значение каждого параметра зависит от используемого действия. При вызове отдельных действий некоторые параметры должны иметь значение пробела, нулевые значения и т. д. (хотя клиент все же должен использовать их и знать их типы).
Действия в логически связном модуле попадают в одну категорию, хотя имеют не только сходства, но и различия. К сожалению, это заставляет программиста «завязывать код действий в узел», ориентируясь на то, что действия совместно используют общие строки кода. Поэтому логически связный модуль имеет:
q уродливый внешний вид с различными параметрами, обеспечивающими, например, четыре вида доступа;
q запутанную внутреннюю структуру со множеством переходов, похожую на волшебный лабиринт.
В итоге модуль становится сложным как для понимания, так и для сопровождения.
Локализация
Локализация фиксирует способ группировки информации в программе. В классических методах, где используется функциональная декомпозиция, информация локализуется вокруг функций. Функции в них реализуются как процедурные модули. В методах, управляемых данными, информация группируется вокруг структур данных. В объектно-ориентированной среде информация группируется внутри классов или объектов (инкапсуляцией как данных, так и процессов).
Поскольку в классических методах основной механизм локализации — функция, программные метрики ориентированы на внутреннюю структуру или сложность функций (длина модуля, связность, цикломатическая сложность) или на способ, которым функции связываются друг с другом (сцепление модулей).
Так как в объектно-ориентированной системе базовым элементом является класс, то локализация здесь основывается на объектах. Поэтому метрики должны применяться к классу (объекту) как к комплексной сущности. Кроме того, между операциями (функциями) и классами могут быть отношения не только «один-к-одному». Поэтому метрики, отображающие способы взаимодействия классов, должны быть приспособлены к отношениям «один-ко-многим», «многие-ко-многим».
Макетирование
Достаточно часто заказчик не может сформулировать подробные требования по вводу, обработке или выводу данных для будущего программного продукта. С другой стороны, разработчик может сомневаться в приспосабливаемое™ продукта под операционную систему, форме диалога с пользователем или в эффективности реализуемого алгоритма. В этих случаях целесообразно использовать макетирование.
Основная цель макетирования — снять неопределенности в требованиях заказчика.
Макетирование (прототипирование) — это процесс создания модели требуемого программного продукта.
Модель может принимать одну из трех форм:
1) бумажный макет или макет на основе ПК (изображает или рисует человеко-машинный диалог);
2) работающий макет (выполняет некоторую часть требуемых функций);
3) существующая программа (характеристики которой затем должны быть улучшены).
Как показано на рис. 1.2, макетирование основывается на многократном повторении итераций, в которых участвуют заказчик и разработчик.

Рис. 1.2. Макетирование
Последовательность действий при макетировании представлена на рис. 1.3. Макетирование начинается со сбора и уточнения требований к создаваемому ПО Разработчик и заказчик встречаются и определяют все цели ПО, устанавливают, какие требования известны, а какие предстоит доопределить.
Затем выполняется быстрое проектирование. В нем внимание сосредоточивается на тех характеристиках ПО, которые должны быть видимы пользователю.
Быстрое проектирование приводит к построению макета.
Макет оценивается заказчиком и используется для уточнения требований к ПО.
Итерации повторяются до тех пор, пока макет не выявит все требования заказчика и, тем самым, не даст возможность разработчику понять, что должно быть сделано.
Достоинство макетирования: обеспечивает определение полных требований к ПО.
Недостатки макетирования:
q заказчик может принять макет за продукт;
q разработчик может принять макет за продукт.
Поясним суть недостатков. Когда заказчик видит работающую версию ПО, он перестает сознавать, что детали макета скреплены «жевательной резинкой и проволокой»; он забывает, что в погоне за работающим вариантом оставлены нерешенными вопросы качества и удобства сопровождения ПО. Когда заказчику говорят, что продукт должен быть перестроен, он начинает возмущаться и требовать, чтобы макет «в три приема» был превращен в рабочий продукт. Очень часто это отрицательно сказывается на управлении разработкой ПО.
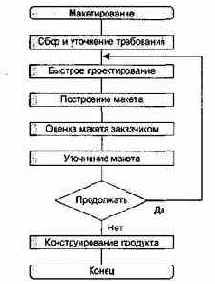
Рис. 1.3. Последовательность действий при макетировании
С другой стороны, для быстрого получения работающего макета разработчик часто идет на определенные компромиссы. Могут использоваться не самые подходящие язык программирования или операционная система. Для простой демонстрации возможностей может применяться неэффективный алгоритм. Спустя некоторое время разработчик забывает о причинах, по которым эти средства не подходят. В результате далеко не идеальный выбранный вариант интегрируется в систему.
Очевидно, что преодоление этих недостатков требует борьбы с житейским соблазном — принять желаемое за действительное.
Маршалинг
Клиент может содержать прямую ссылку на СОМ-объект только в одном случае — когда СОМ-объект размещен в сервере «в процессе». В случае локального или удаленного сервера, как показано на рис. 13.23, он ссылается на посредника.
Посредник — СОМ-объект, размещенный в клиентском процессе и предоставляющий клиенту те же интерфейсы, что и запрашиваемый объект. Запрос клиентом операции через такую ссылку приводит к исполнению кода посредника.
Посредник принимает параметры, переданные клиентом, и упаковывает их для дальнейшей пересылки. Эта процедура называется маршалингом. Затем посредник (с помощью средства коммуникации) посылает запрос в процесс, который на самом деле реализует СОМ-объект.
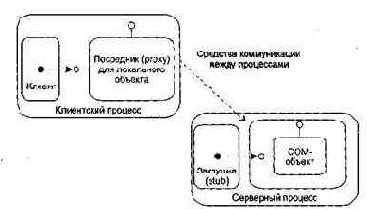
Рис. 13.23. Организация маршалинга и демаршалинга
По прибытии в процесс локального сервера запрос передается заглушке. Заглушка распаковывает параметры запроса и вызывает операцию СОМ-объекта. Эта процедура называется демаршалингом. После завершения СОМ-операции результаты возвращаются в обратном направлении.
Код посредника и заглушки автоматически генерируется компилятором MIDL (Microsoft IDL) по IDL-описанию интерфейса.
Механизмы расширения в UML
UML — развитый язык, имеющий большие возможности, но даже он не может отразить все нюансы, которые могут возникнуть при создании различных моделей. Поэтому UML создавался как открытый язык, допускающий контролируемые рас-. ширения. Механизмами расширения в UML являются:
q ограничения;
q теговые величины;
q стереотипы.
Ограничение (constraint) расширяет семантику строительного UML-блока, позволяя добавить новые правила или модифицировать существующие. Ограничение показывают как текстовую строку, заключенную в фигурные скобки {}. Например, на рис. 10.17 введено простое ограничение на свойство сумма класса Сессия Банкомата — его значение должно быть кратно 20. Кроме того, здесь показано ограничение на два элемента (две ассоциации), оно располагается возле пунктирной линии, соединяющей элементы, и имеет следующий смысл — владельцем конкретного счета не может быть и организация, и персона.

Рис. 10.17. Ограничения
Теговая величина (tagged value) расширяет характеристики строительного UML-блока, позволяя создать новую информацию в спецификации конкретного элемента. Теговую величину показывают как строку в фигурных скобках {}. Строка имеет вид
имя теговой величины = значение.
Иногда (в случае предопределенных тегов) указывается только имя теговой величины.
Отметим, что при работе с продуктом, имеющим много реализаций, полезно отслеживать версию и автора определенных блоков. Версия и автор не принадлежат к основным понятиям UML. Они могут быть добавлены к любому строительному блоку (например, к классу) введением в блок новых теговых величин. Например, на рис. 10.18 класс ТекстовыйПроцессор расширен путем явного указания его версии и автора.

Рис. 10.18. Расширение класса
Стереотип (stereotype) расширяет словарь языка, позволяет создавать новые виды строительных блоков, производные от существующих и учитывающие специфику новой проблемы. Элемент со стереотипом является вариацией существующего элемента, имеющей такую же форму, но отличающуюся по сути.
У него могут быть дополнительные ограничения и теговые величины, а также другое визуальное представление. Он иначе обрабатывается при генерации программного кода. Отображают стереотип как имя, указываемое в двойных угловых скобках (или в угловых кавычках).
Примеры элементов со стереотипами приведены на рис. 10.19. Стереотип «exception» говорит о том, что класс ПотеряЗначимости теперь рассматривается как специальный класс, которому, положим, разрешается только генерация и обработка сигналов исключений. Особые возможности метакласса получил класс ЭлементМодели. Кроме того, здесь показано применение стереотипа «call» к отношению зависимости (у него появился новый смысл).

Рис. 10.19. Стереотипы
Таким образом, механизмы расширения позволяют адаптировать UML под нужды конкретных проектов и под новые программные технологии. Возможно добавление новых строительных блоков, модификация спецификаций существующих блоков и даже изменение их семантики. Конечно, очень важно обеспечить контролируемое введение расширений.
Метод анализа Джексона
Как и метод Варнье-Орра, метод Джексона появился в период революции структурного программирования. Фактически оба метода решали одинаковую задачу: распространить базовые структуры программирования (последовательность, выбор, повторение) на всю область конструирования сложных программных систем. Именно поэтому основные выразительные средства этих методов оказались так похожи друг на друга.
Метод проектирования Джексона
Для иллюстрации проектирования по этому методу продолжим пример с системой обслуживания перевозок.
Метод Джексона включает шесть шагов [39]. Три первых шага относятся к этапу анализа. Это шаги: объект — действие, объект — структура, начальное моделирование. Их мы уже рассмотрели.
Метод структурного проектирования
Исходными данными для метода структурного проектирования являются компоненты модели анализа ПС, которая представляется иерархией диаграмм потоков данных [34], [52], [58], [73], [77]. Результат структурного проектирования — иерархическая структура ПС. Действия структурного проектирования зависят от типа информационного потока в модели анализа.
Методика Джексона
Метод Джексона (1975) включает 6 шагов [39]. Три шага выполняются на этапе анализа, а остальные — на этапе проектирования.
1. Объект-действие. Определяются объекты — источники или приемники информации и действия — события реального мира, воздействующие на объекты.
2. Объект-структура. Действия над объектами представляются диаграммами Джексона.
3. Начальное моделирование. Объекты и действия представляются как обрабатывающая модель. Определяются связи между моделью и реальным миром.
4. Доопределение функций. Выделяются и описываются сервисные функции.
5. Учет системного времени. Определяются и оцениваются характеристики планирования будущих процессов.
6. Реализация. Согласование с системной средой, разработка аппаратной платформы.
Методика тестирования программных систем
Процесс тестирования объединяет различные способы тестирования в спланированную последовательность шагов, которые приводят к успешному построению программной системы (ПС) [3], [13], [64], [69]. Методика тестирования ПС может быть представлена в виде разворачивающейся спирали (рис. 8.1).
В начале осуществляется тестирование элементов (модулей), проверяющее результаты этапа кодирования ПС. На втором шаге выполняется тестирование интеграции, ориентированное на выявление ошибок этапа проектирования ПС. На третьем обороте спирали производится тестирование правильности, проверяющее корректность этапа анализа требований к ПС. На заключительном витке спирали проводится системное тестирование, выявляющее дефекты этапа системного анализа ПС.
Охарактеризуем каждый шаг процесса тестирования.
1. Тестирование элементов. Цель — индивидуальная проверка каждого модуля. Используются способы тестирования «белого ящика».
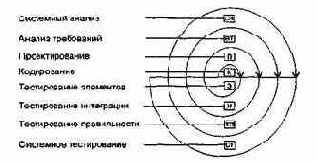
Рис. 8.1. Спираль процесса тестирования ПС
2. Тестирование интеграции. Цель — тестирование сборки модулей в программную систему. В основном применяют способы тестирования «черного ящика».
3. Тестирование правильности. Цель — проверить реализацию в программной системе всех функциональных и поведенческих требований, а также требования эффективности. Используются исключительно способы тестирования «черного ящика».
4. Системное тестирование. Цель — проверка правильности объединения и взаимодействия всех элементов компьютерной системы, реализации всех системных функций.
Организация процесса тестирования в виде эволюционной разворачивающейся спирали обеспечивает максимальную эффективность поиска ошибок. Однако возникает вопрос — когда заканчивать тестирование?
Ответ практика обычно основан на статистическом критерии: «Можно с 95%-ной уверенностью сказать, что провели достаточное тестирование, если вероятность безотказной работы ЦП с программным изделием в течение 1000 часов составляет по меньшей мере 0,995».
Научный подход при ответе на этот вопрос состоит в применении математической модели отказов.
Например, для логарифмической модели Пуассона формула расчета текущей интенсивности отказов имеет вид:

где


С помощью уравнения (8.1) можно предсказать снижение ошибок в ходе тестирования, а также время, требующееся для достижения допустимо низкой интенсивности отказов.
Методы анализа, ориентированные на структуры данных
Элементами проблемной области для любой системы являются потоки, процессы и структуры данных. При структурном анализе активно работают только с потоками данных и процессами.
Методы, ориентированные на структуры данных, обеспечивают:
1) определение ключевых информационных объектов и операций;
2) определение иерархической структуры данных;
3) компоновку структур данных из типовых конструкций — последовательности, выбора, повторения;
4) последовательность шагов для превращения иерархической структуры данных в структуру программы.
Наиболее известны два метода: метод Варнье-Орра и метод Джексона.
В методе Варнье-Орра для представления структур применяют диаграммы Варнье [54].
Для построения диаграмм Варнье используют 3 базовых элемента: последовательность, выбор, повторение (рис. 3.11) [74].

Рис. 3.11. Базовые элементы в диаграммах Варнье
Как показано на рис. 3.12, с помощью этих элементов можно строить информационные структуры с любым количеством уровней иерархии.

Рис. 3.12. Структура газеты в виде диаграммы Варнье
Как видим, для представления структуры газеты здесь используются три уровня иерархии.
Метрические особенности объектно-ориентированных программных систем
Объектно-ориентированные метрики вводятся с целью:
q улучшить понимание качества продукта;
q оценить эффективность процесса конструирования;
q улучшить качество работы на этапе проектирования.
Все эти цели важны, но для программного инженера главная цель — повышение качества продукта. Возникает вопрос — как измерить качество объектно-ориентированной системы?
Для любого инженерного продукта метрики должны ориентироваться на его уникальные характеристики. Например, для электропоезда вряд ли полезна метрика «расход угля на километр пробега». С точки зрения метрик выделяют пять характеристик объектно-ориентированных систем: локализацию, инкапсуляцию, информационную закрытость, наследование и способы абстрагирования объектов. Эти характеристики оказывают максимальное влияние на объектно-ориентированные метрики.
Метрики для объектно-ориентированного тестирования
Рассмотрим проектные метрики, которые, по мнению Р. Байндера (Binder), прямо влияют на тестируемость ОО-систем [17]. Р. Байндер сгруппировал эти метрики в три категории, отражающие важнейшие проектные характеристики.
Метрики для ОО-проектов
Основными задачами менеджера проекта являются планирование, координация, отслеживание работ и управление программным проектом.
Одним из ключевых вопросов планирования является оценка размера программного продукта. Прогноз размера продукта обеспечивают следующие ОО-метрики.
Метрика 8: Количество описаний сценариев NSS (Number of Scenario Scripts)
Это количество прямо пропорционально количеству классов, требуемых для реализации требований, количеству состояний для каждого класса, а также количеству методов, свойств и сотрудничеств. Метрика NSS — эффективный индикатор размера программы.
Рекомендуемое значение NSS — не менее одного сценария на публичный протокол подсистемы, отражающий основные функциональные требования к подсистеме.
Метрика 9: Количество ключевых классов NKC (Number of Key Classes)
Ключевой класс прямо связан с коммерческой проблемной областью, для которой предназначена система. Маловероятно, что ключевой класс может появиться в результате повторного использования существующего класса. Поэтому значение NKC достоверно отражает предстоящий объем разработки. М. Лоренц и Д. Кидд предполагают, что в типовой ОО-системе на долю ключевых классов приходится 20-40% от общего количества классов. Как правило, оставшиеся классы реализуют общую инфраструктуру (GUI, коммуникации, базы данных).
Рекомендуемое значение: если NKC < 0,2 от общего количества классов системы, следует углубить исследование проблемной области (для обнаружения важнейших абстракций, которые нужно реализовать).
Метрика 10: Количество подсистем NSUB (NumberofSUBsystem)
Количество подсистем обеспечивает понимание следующих вопросов: размещение ресурсов, планирование (с акцентом на параллельную разработку), общие затраты на интеграцию.
Рекомендуемое значение: NSUB > 3.
Значения метрик NSS, NKC, NSUB полезно накапливать как результат каждого выполненного ОО-проекта. Так формируется метрический базис фирмы, в который также включаются метрические значения по классами и операциям. Эти исторические данные могут использоваться для вычисления метрик производительности (среднее количество классов на разработчика или среднее количество методов на человеко-месяц). Совместное применение метрик позволяет оценивать затраты, продолжительность, персонал и другие характеристики текущего проекта.
Метрики инкапсуляции
К метрикам инкапсуляции относятся: «Недостаток связности в методах LCOM», «Процент публичных и защищенных PAP (Percent Public and Protected)» и «Публичный доступ к компонентным данным PAD (Public Access to Data members)».
Метрика 1: Недостаток связности в методах LCOM
Чем выше значение LCOM, тем больше состояний надо тестировать, чтобы гарантировать отсутствие побочных эффектов при работе методов.
Метрика 2: Процент публичных и защищенных PAP (Percent Public and Protected)
Публичные свойства наследуются от других классов и поэтому видимы для этих классов. Защищенные свойства являются специализацией и приватны для определенного подкласса. Эта метрика показывает процент публичных свойств класса. Высокие значения РАР увеличивают вероятность побочных эффектов в классах. Тесты должны гарантировать обнаружение побочных эффектов.
Метрика 3: Публичный доступ к компонентным данным PAD (Public Access to Data members)
Метрика показывает количество классов (или методов), которые имеют доступ к свойствам других классов, то есть нарушают их инкапсуляцию. Высокие значения приводят к возникновению побочных эффектов в классах. Тесты должны гарантировать обнаружение таких побочных эффектов.
Метрики Лоренца и Кидда
Коллекция метрик Лоренца и Кидда — результат практического, промышленного подхода к оценке ОО-проектов [45].
Метрики наследования
К метрикам наследования относятся «Количество корневых классов NOR (Number Of Root classes)», «Коэффициент объединения по входу FIN», «Количество детей NOC» и «Высота дерева наследования DIT».
Метрика 4: Количество корневых классов NOR (Number Of Root classes)
Эта метрика подсчитывает количество деревьев наследования в проектной модели. Для каждого корневого класса и дерева наследования должен разрабатываться набор тестов. С увеличением NOR возрастают затраты на тестирование.
Метрика 5: Коэффициент объединения по входу FIN
В контексте О-О-смистем FIN фиксирует множественное наследование. Значение FIN > 1 указывает, что класс наследует свои свойства и операции от нескольких корневых классов. Следует избегать FIN > 1 везде, где это возможно.
Метрика 6: Количество детей NOC
Название говорит само за себя. Метрика заимствована из набора Чидамбера-Кемерера.
Метрика 7: Высота дерева наследования DIT
Метрика заимствована из набора Чидамбера-Кемерера. Методы суперкласса должны повторно тестироваться для каждого подкласса.
В дополнение к перечисленным метрикам Р. Байндер выделил метрики сложности класса (это метрики Чидамбера-Кемерера — WMC, CBO, RFC и метрики для подсчета количества методов), а также метрики полиморфизма.
Метрики, ориентированные на классы
М. Лоренц и Д. Кидд подразделяют метрики, ориентированные на классы, на четыре категории: метрики размера, метрики наследования, внутренние и внешние метрики.
Размерно-ориентированные метрики основаны на подсчете свойств и операций для отдельных классов, а также их средних значений для всей ОО-системы. Метрики наследования акцентируют внимание на способе повторного использования операций в иерархии классов. Внутренние метрики классов рассматривают вопросы связности и кодирования. Внешние метрики исследуют сцепление и повторное использование.
Метрика 1: Размер класса CS (Class Size)
Общий размер класса определяется с помощью следующих измерений:
q общее количество операций (вместе с приватными и наследуемыми экземплярными операциями), которые инкапсулируются внутри класса;
q количество свойств (вместе с приватными и наследуемыми экземплярными свойствами), которые инкапсулируются классом.
Метрика WMC Чидамбера и Кемерера также является взвешенной метрикой размера класса.
Большие значения CS указывают, что класс имеет слишком много обязанностей. Они уменьшают возможность повторного использования класса, усложняют его реализацию и тестирование.
При определении размера класса унаследованным (публичным) операциям и свойствам придают больший удельный вес. Причина — приватные операции и свойства обеспечивают специализацию и более локализованы в проекте.
Могут вычисляться средние количества свойств и операций класса. Чем меньше среднее значение размера, тем больше вероятность повторного использования класса.
Рекомендуемое значение CS

Метрика 2: Количество операций, переопределяемых подклассом, NOO
(Number of Operations Overridden by a Subclass)
Переопределением называют случай, когда подкласс замещает операцию, унаследованную от суперкласса, своей собственной версией.
Большие значения NOO обычно указывают на проблемы проектирования. Ясно, что подкласс должен расширять операции суперкласса.
Расширение проявляется в виде новых имен операций. Если же NOО велико, то разработчик нарушает абстракцию суперкласса. Это ослабляет иерархию классов, усложняет тестирование и модификацию программного обеспечения.
Рекомендуемое значение NOO
Метрика 3: Количество операций, добавленных подклассом, NOA
(Number of Operations Added by a Subclass)
Подклассы специализируются добавлением приватных операций и свойств. С ростом NOA подкласс удаляется от абстракции суперкласса. Обычно при увеличении высоты иерархии классов (увеличении DIT) должно уменьшаться значение NOA на нижних уровнях иерархии.
Для рекомендуемых значений CS = 20 и DIT = 6 рекомендуемое значение NOA
Метрика 4: Индекс специализации SI (Specialization Index)
Обеспечивает грубую оценку степени специализации каждого подкласса. Специализация достигается добавлением, удалением или переопределением операций:
SI = (NOO x уровень) /Mобщ,
где уровень — номер уровня в иерархии, на котором находится подкласс, Мобщ — общее количество методов класса.
Пример расчета индексов специализации приведен на рис. 14.5.
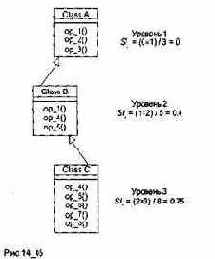
Рис. 14.5. Расчет индексов специализации классов
Чем выше значение SI, тем больше вероятность того, что в иерархии классов есть классы, нарушающие абстракцию суперкласса.
Рекомендуемое значение SI
Метрики полиморфизма
Рассмотрим следующие метрики полиморфизма: «Процентное количество не переопределенных запросов OVR», «Процентное количество динамических запросов DYN», «Скачок класса Bounce-С» и «Скачок системы Bounce-S».
Метрика 8: Процентное количество не переопределенных запросов OVR
Процентное количество от всех запросов в тестируемой системе, которые не приводили к перекрытию модулей. Перекрытие может приводить к непредусмотренному связыванию. Высокое значение OVR увеличивает возможности возникновения ошибок.
Метрика 9: Процентное количество динамических запросов DYN
Процентное количество от всех сообщений в тестируемой системе, чьи приемники определяются в период выполнения. Динамическое связывание может приводить к непредусмотренному связыванию. Высокое значение DYN означает, что для проверки всех вариантов связывания метода потребуется много тестов.
Метрика 10: Скачок класса Bounce-C
Количество скачущих маршрутов, видимых тестируемому классу. Скачущий маршрут — это маршрут, который в ходе динамического связывания пересекает несколько иерархий классов-поставщиков. Скачок может приводить к непредусмотренному связыванию. Высокое значение Bounce-C увеличивает возможности возникновения ошибок.
Метрика 11: Скачок системы Bounce-S
Количество скачущих маршрутов в тестируемой системе. В этой метрике суммируется количество скачущих маршрутов по каждому классу системы. Высокое значение Bounce-S увеличивает возможности возникновения ошибок.
Множественность
Иногда бывает необходимо ограничить количество экземпляров класса:
q задать ноль экземпляров (в этом случае класс превращается в утилиту, которая предлагает свои свойства и операции);
q задать один экземпляр (класс-singleton);
q задать конкретное количество экземпляров;
q не ограничивать количество экземпляров (это случай, предполагаемый по умолчанию).
Количество экземпляров класса называется его множественностью. Выражение множественности записывается в правом верхнем углу значка класса. Например, как показано на рис. 11.4, КонтроллерУглов — это класс-singleton, а для класса ДатчикУгла разрешены три экземпляра.

Рис. 11.4. Множественность
Множественность применима не только к классам, но и к свойствам. Множественность свойства задается выражением в квадратных скобках, записанным после его имени. Например, на рисунке заданы три и более экземпляра свойства Управление (в экземпляре класса КонтроллерУглов).
Модель этапа постархитектуры
Модель этапа постархитектуры используется в период, когда уже сформирована архитектура и выполняется дальнейшая разработка программного продукта.
Основное уравнение постархитектурной модели является развитием уравнения предыдущей модели и имеет следующий вид:
ЗАТРАТЫ = А х К~req х РАЗМЕРB х Мр +3ATPATЫauto [чел.-мес],
где
q коэффициент К~req учитывает возможные изменения в требованиях;
q показатель В отражает нелинейную зависимость затрат от размера проекта (размер выражается в KLOC), вычисляется так же, как и в предыдущей модели;
q в размере проекта различают две составляющие — новый код и повторно используемый код;
q множитель поправки Мр зависит от 17 факторов затрат, характеризующих продукт, аппаратуру, персонал и проект.
Изменчивость требований приводит к повторной работе, требуемой для учета предлагаемых изменений, оценка их влияния выполняется по формуле
К~req =l + (BRAK/100),
где BRAK — процент кода, отброшенного (модифицированного) из-за изменения требований.
Размер проекта и продукта определяют по выражению
РАЗМЕР = PA3MEPnew + PA3MEPreuse [KLOC],
где
q PA3MEPnew — размер нового (создаваемого) программного кода;
q PA3MEPreuse — размер повторно используемого программного кода.
Формула для расчета размера повторно используемого кода записывается следующим образом:
PA3MEPreuse
=KASLOC x ((100 - AT)/ 100) x (AA + SU + 0,4 DM + 0,3 CM + 0,3 IM) /100,
где
q KASLOC — количество строк повторно используемого кода, который должен быть модифицирован (в тысячах строк);
q AT — процент автоматически генерируемого кода;
q DM — процент модифицируемых проектных моделей;
q CM — процент модифицируемого программного кода;
q IM — процент затрат на интеграцию, требуемых для подключения повторно используемого ПО;
q SU — фактор, основанный на стоимости понимания добавляемого ПО; изменяется от 50 (для сложного неструктурированного кода) до 10 (для хорошо написанного объектно-ориентированного кода);
q АА — фактор, который отражает стоимость решения о том, может ли ПО быть повторно используемым; зависит от размера требуемого тестирования и оценивания (величина изменяется от 0 до 8).
Правила выбора этих параметров приведены в руководстве по СОСОМО II.
Для определения множителя поправки Мр основного уравнения используют 17 факторов затрат, которые могут быть разбиты на 4 категории. Перечислим факторы затрат, сгруппировав их по категориям.
Факторы продукта:
1) требуемая надежность ПО — RELY;
2) размер базы данных — DATA;
3) сложность продукта — CPLX;
4) требуемая повторная используемость — RUSE;
5) документирование требований жизненного цикла — DOCU.
Факторы платформы (виртуальной машины):
6) ограничения времени выполнения — TIME;
7) ограничения оперативной памяти — STOR;
8) изменчивость платформы — PVOL.
Факторы персонала:
9) возможности аналитика — АСАР;
10) возможности программиста — РСАР;
11) опыт работы с приложением — АЕХР;
12) опыт работы с платформой — РЕХР;
13) опыт работы с языком и утилитами — LTEX;
14) непрерывность персонала — PCON.
Факторы проекта:
15) использование программных утилит — TOOL;
16) мультисетевая разработка — SITE;
17) требуемый график разработки — SCED.
Для каждого фактора определяется оценка (по 6-балльной шкале). На основе оценки для каждого фактора по таблице Боэма определяется множитель затрат ЕМi. Перемножение всех множителей затрат дает множитель поправки пост-архитектурной модели:

Значение Мр отражает реальные условия выполнения программного проекта и позволяет троекратно увеличить (уменьшить) начальную оценку затрат.
ПРИМЕЧАНИЕ
Трудоемкость работы с факторами затрат минимизируется за счет использования специальных таблиц. Справочный материал для оценки факторов затрат приведен в приложении А.
От оценки затрат легко перейти к стоимости проекта. Переход выполняют по формуле:
СТОИМОСТЬ = ЗАТРАТЫ х РАБ_ КОЭФ,
где среднее значение рабочего коэффициента составляет $15 000 за человеко-месяц.
После определения затрат и стоимости можно оценить длительность разработки. Модель СОСОМО II содержит уравнение для оценки календарного времени TDEV, требуемого для выполнения проекта. Для моделей всех уровней справедливо:
Длительность (TDEV) = [3,0 х (ЗАТРАТЫ)(0,33+0,2(B-1,01))] х SCEDPercentage/100 [мес],
где
q В — ранее рассчитанный показатель степени;
q SCEDPercentage — процент увеличения (уменьшения) номинального графика.
Если нужно определить номинальный график, то принимается SCEDPercentage =100 и правый сомножитель в уравнении обращается в единицу. Следует отметить, что СОСОМО II ограничивает диапазон уплотнения/растягивания графика (от 75 до 160%). Причина проста — если планируемый график существенно отличается от номинального, это означает внесение в проект высокого риска.
Рассмотрим пример. Положим, что затраты на проект равны 20 человеко-месяцев. Примем, что все масштабные факторы номинальны (имеют значения 3), поэтому, в соответствии с табл. 2.20, показатель степени 5=1,16. Отсюда следует, что номинальная длительность проекта равна
TDEV = 3, Ox (20)0,36 = 8,8 мес.
Отметим, что зависимость между затратами и количеством разработчиков носит характер, существенно отличающийся от линейного. Очень часто увеличение количества разработчиков приводит к возрастанию затрат. В чем причина? Ответ прост:
q увеличивается время на взаимодействие и обучение сотрудников, согласование совместных решений;
q возрастает время на определение интерфейсов между частями программной системы.
Удвоение разработчиков не приводит к двукратному сокращению длительности проекта. Модель СОСОМО II явно утверждает, что длительность проекта является функцией требуемых затрат, прямой зависимости от количества сотрудников нет. Другими словами, она устраняет миф нерадивых менеджеров в том, что добавление людей поможет ликвидировать отставание в проекте.
СОСОМО II предостерегает от определения потребного количества сотрудников путем деления затрат на длительность проекта. Такой упрощенный подход часто приводит к срыву работ. Реальная картина имеет другой характер. Количество людей, требуемых на этапе планирования и формирования требований, достаточно мало. На этапах проектирования и кодирования потребность в увеличении команды возрастает, после окончания кодирования и тестирования численность необходимых сотрудников достигает минимума.
