Модель композиции приложения
Модель композиции используется на ранней стадии конструирования ПО, когда:
q рассматривается макетирование пользовательских интерфейсов;
q обсуждается взаимодействие ПО и компьютерной системы;
q оценивается производительность;
q определяется степень зрелости технологии.
Модель композиции приложения ориентирована на применение объектных указателей.
Объектный указатель — средство косвенного измерения ПО, для его расчета определяется количество экранов (как элементов пользовательского интерфейса), отчетов и компонентов, требуемых для построения приложения. Как показано в табл. 2.15, каждый объектный экземпляр (экран, отчет) относят к одному из трех уровней сложности. Здесь места подстановки измеренных и вычисленных значений отмечены прямоугольниками (прямоугольник играет роль метки-заполнителя). В свою очередь, сложность является функцией от параметров клиентских и серверных таблиц данных (см. табл. 2.16 и 2.17), которые требуются для генерации экрана и отчета, а также от количества представлений и секций, входящих в экран или отчет.
Таблица 2.15. Оценка количества объектных указателей
| Тип объекта | Количество | Вес | Итого | ||||||||
| Простой | Средний | Сложный | |||||||||
| Экран | 0 | х1 | х2 | х3 | = 0 | ||||||
| Отчет | 0 | х2 | х5 | х8 | = 0 | ||||||
| 3GL компонент | 0 | х10 | = 0 | ||||||||
| Объектные указатели | = 0 |
Таблица 2.16. Оценка сложности экрана
| Экраны | Количество серверных (срв) и клиентских (клт) таблиц данных | ||||||
| Количество представлений | Всего < 4
(< 2 срв, <3клт) | Всего < 8
(2-3 срв, 3-5 клт) | Всего > 8
(>3срв, >5клт) | ||||
| <3 | Простой | Простой | Средний | ||||
| 3-7 | Простой | Средний | Сложный | ||||
| >8 | Средний | Сложный | Сложный |
Таблица 2.17. Оценка сложности отчета
| Отчеты | Количество серверных (срв) и клиентских (клт) таблиц данных | ||||||
| Количество представлений | Всего < 4
(< 2 срв, < 3 клт) | Всего < 8
(2-3 срв, 3-5 клт) | Всего > 8
(>3срв, > 5 клт) | ||||
| 0 или 1 | Простой | Простой | Средний | ||||
| 2 или 3 | Простой | Средний | Сложный | ||||
| >4 | Средний | Сложный | Сложный |
После определения сложности количество экранов, отчетов и компонентов взвешивается в соответствии с табл. 2.15. Количество объектных указателей определяется перемножением исходного числа объектных экземпляров на весовые коэффициенты и последующим суммированием промежуточных результатов.
Для учета реальных условий разработки вычисляется процент повторного использования программных компонентов %REUSE и определяется количество новых объектных указателей NOP:
NOP = (Объектные указатели) х [(100 - %REUSE) /100].
Для оценки затрат, основанной на величине NOP, надо знать скорость разработки продукта PROD. Эту скорость определяют по табл. 2.18, учитывающей уровень опытности разработчиков и зрелость среды разработки.
Проектные затраты оцениваются по формуле
ЗАТРАТЫ = NOP /PROD [чел.-мес],
где PROD — производительность разработки, выраженная в терминах объектных указателей.
Таблица 2.18. Оценка скорости разработки
|
Опытность / возможности разработчика |
Зрелость / возможности среды разработки |
PROD |
|
Очень низкая |
Очень низкая |
4 |
|
Низкая |
Низкая |
7 |
|
Номинальная |
Номинальная |
13 |
|
Высокая |
Высокая |
25 |
|
Очень высокая |
Очень высокая |
50 |
Модель раннего этапа проектирования
Модель раннего этапа проектирования используется в период, когда стабилизируются требования и определяется базисная программная архитектура.
Основное уравнение этой модели имеет следующий вид:
ЗАТРАТЫ = А х РАЗМЕРв х Ме + ЗАТРАТЫаuto[чел.-мес],
где:
q масштабный коэффициент А = 2,5;
q показатель В отражает нелинейную зависимость затрат от размера проекта (размер системы РАЗМЕР выражается в тысячах LOC);
q множитель поправки Мe зависит от 7 формирователей затрат, характеризующих продукт, процесс и персонал;
q слагаемое 3ATPATЫauto отражает затраты на автоматически генерируемый программный код.
Значение показателя степени В изменяется в диапазоне 1,01... 1,26, зависит от пяти масштабных факторов Wi и вычисляется по формуле

Общая характеристика масштабных факторов приведена в табл. 2.19, а табл. 2.20 позволяет определить оценки этих факторов. Оценки принимают 6 значений: от очень низкой (5) до сверхвысокой (0).
Таблица 2.19. Характеристика масштабных факторов
| Масштабный фактор (Wi) | Пояснение | ||
| Предсказуемость PREC | Отражает предыдущий опыт организации в реализации проектов этого типа. Очень низкий означает отсутствие опыта. Сверхвысокий означает, что организация полностью знакома с этой прикладной областью | ||
| Гибкость разработки FLEX
Разрешение архитектуры /риска RESL Связность группы TEAM Зрелость процесса РМАТ | Отражает степень гибкости процесса разработки. Очень низкий означает, что используется заданный процесс. Сверхвысокий означает, что клиент установил только общие цели
Отражает степень выполняемого анализа риска. Очень низкий означает малый анализ. Сверхвысокий означает полный и сквозной анализ риска Отражает, насколько хорошо разработчики группы знают друг друга и насколько удачно они совместно работают. Очень низкий означает очень трудные взаимодействия. Сверхвысокий, означает интегрированную группу, без проблем взаимодействия Означает зрелость процесса в организации. Вычисление этого фактора может выполняться по вопроснику СММ |
В качестве иллюстрации рассмотрим компанию, которая берет проект в малознакомой проблемной области. Положим, что заказчик не определил используемый процесс разработки и не допускает выделения времени на всесторонний анализ риска. Для реализации этой программной системы нужно создать новую группу разработчиков. Компания имеет возможности, соответствующие 2-му уровню зрелости согласно модели СММ. Возможны следующие значения масштабных факторов:
q предсказуемость. Это новый проект для компании — значение Низкий (4);
q гибкость разработки. Заказчик требует некоторого согласования — значение Очень высокий (1);
q разрешение архитектуры/риска. Не выполняется анализ риска, как следствие, малое разрешение риска — значение Очень низкий (5);
q связность группы. Новая группа, нет информации — значение Номинальный (3);
q зрелость процесса. Имеет место некоторое управление процессом — значение Номинальный (3).
Таблица 2.20. Оценка масштабных факторов
|
Масштабный фактор (Wi) |
Очень низкий 5 |
Низкий 4 |
|
PRЕС |
Полностью непредсказуемый проект |
Главным образом, в значительной степени непредсказуемый |
|
FLEX |
Точный, строгий процесс разработки |
Редкое расслабление в работе |
|
RESL |
Малое разрешение риска (20%) |
Некоторое (40%) |
|
TEAM |
Очень трудное взаимодействие |
Достаточно трудное взаимодействие |
|
PREC |
Полностью непредсказуемый проект |
В значительной степени непредсказуемый |
|
РМАТ |
Взвешенное среднее значение от количества ответов «Yes» на вопросник СММ Maturity |
Для каждого формирователя затрат определяется оценка (по 6-балльной шкале), где 1 соответствует очень низкому значению, а 6 — сверхвысокому значению.
На основе оценки для каждого формирователя по таблице Боэма определяется множитель затрат EMi Перемножение всех множителей затрат формирует множитель поправки:

Слагаемое 3ATPATbIauto используется, если некоторый процент программного кода генерируется автоматически. Поскольку производительность такой работы значительно выше, чем при ручной разработке кода, требуемые затраты вычисляются отдельно, по следующей формуле:
ЗАТРАТЫаuto = (КALOC x (AT /100)) / ATPROD,
где:
q KALOC — количество строк автоматически генерируемого кода (в тысячах строк);
q AT — процент автоматически генерируемого кода (от всего кода системы);
q ATPROD — производительность автоматической генерации кода.
Сомножитель AT в этой формуле позволяет учесть затраты на организацию взаимодействия автоматически генерируемого кода с оставшейся частью системы.
Далее затраты на автоматическую генерацию добавляются к затратам, вычисленным для кода, разработанного вручную.
|
Номинальный 3 |
Высокий 2 |
Очень высокий 1 |
Сверхвысокий 0 |
|
Отчасти |
Большей частью |
В значительной |
Полностью знакомый |
|
непредсказуемый |
знакомый |
степени знакомый |
|
|
Некоторое расслабление в работе |
Большей частью согласованный процесс |
Некоторое согласование процесса |
Заказчик определил только общие цели |
|
Частое (60%) |
Большей частью (75%) |
Почти всегда (90%) |
Полное (100%) |
|
Среднее |
Главным образом |
Высокая |
Безукоризненное |
|
взаимодействие |
кооперативность |
кооперативность |
взаимодействие |
|
Отчасти непредсказуемый |
Большей частью знакомый |
В значительной степени знакомый |
Полностью знакомый |
|
Взвешенное среднее значение от количества ответов «Yes» на вопросник СММ Maturity |
Таблица 2.21. Формирователи затрат для раннего этапа проектирования
|
Обозначение |
Название |
|
PERS RCPX RUSE PDIF PREX FСIL SCED |
Возможности персонала (Personnel Capability) Надежность и сложность продукта (Product Reliability and Complexity) Требуемое повторное использование (Required Reuse) Трудность платформы (Platform Difficulty) Опытность персонала (Personnel Experience) Средства поддержки (Facilities) График (Schedule) |
Модель системы регулирования давления космического корабля
Обсудим модель системы регулирования давления космического корабля, представленную на рис. 3.9.
Начнем с диаграммы потоков данных. Основной процесс в ПДД — Слежение и регулирование давления. На его входы поступают: измеренное Давление в кабине и Мах давление: На выходе процесса — поток данных Изменение давления. Содержание процесса описывается в его спецификации ПСПЕЦ.
Спецификация процесса ПСПЕЦ может включать:
1) поясняющий текст (обязательно);
2) описание алгоритма обработки;
3) математические уравнения;
4) таблицы;
5) диаграммы.
Элементы со второго по пятый не обязательны.
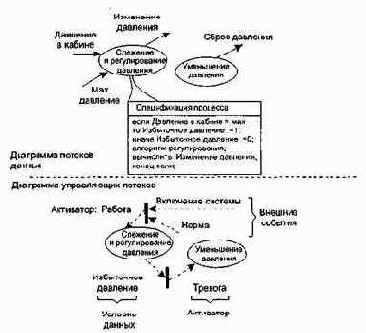
Рис. 3.9. Модель системы регулирования давления космического корабля
С помощью ПСПЕЦ разработчик создает описание для каждого преобразователя, которое рассматривается как:
q первый шаг создания спецификации требований к программному изделию;
q руководство для проектирования программ, которые будут реализовывать процессы.
В нашем примере спецификация процесса имеет вид
если Давление в кабине > мах
то Избыточное давление:=11;
иначе Избыточное давление:=0;
алгоритм регулирования;
выч.Изменение давления;
конец если;
Таким образом, когда давление в кабине превышает максимум, генерируется управляющее событие Избыточное давление. Оно должно быть показано на диаграмме управляющих потоков УПД. Это событие входит в окно управляющей спецификации УСПЕЦ.
Управляющая спецификация моделирует поведение системы. Она содержит:
q таблицу активации процессов (ТАП);
q диаграмму переходов-состояний (ДПС).
Таблица активации процессов показывает, какие процессы будут вызываться (активироваться) в потоковой модели в результате конкретных событий.
ТАП включает три раздела — Входные события, Выходные события, Активация процессов. Логика работы ТАП такова: входное событие вызывает выходное событие, которое активирует конкретный процесс.
Для нашей модели ТАП имеет вид, представленный в табл. 3.1.
Таблица 3.1. Таблица активации процессов
|
Входные события: |
|||
|
Включение системы |
1 |
0 |
0 |
|
Избыточное давление |
0 |
1 |
0 |
|
Норма |
0 |
0 |
1 |
|
Выходные события: |
|||
|
Тревога |
0 |
1 |
0 |
|
Работа |
1 |
0 |
1 |
|
Активация процессов: |
|||
|
Слежение и регулирование давления |
1 |
0 |
1 |
|
Уменьшение давления |
0 |
1 |
0 |
Другой элемент УСПЕЦ — Диаграмма переходов-состояний. ДПС отражает состояния системы и показывает, как она переходит из одного состояния в другое.
ДПС для нашей модели показана на рис. 3.10.
Системные состояния показаны прямоугольниками. Стрелки показывают переходы между состояниями. Стрелки переходов подписывают следующим образом: в числителе — событие, которое вызывает переход, в знаменателе — процесс, запускаемый как результат события.

Изучая ДПС, разработчик может анализировать поведение модели и установить, нет ли «дыр» в определении поведения.
Модели
Модель — наиболее важная разновидность артефакта. Модель упрощает реальность, создается для лучшего понимания разрабатываемой системы. Предусмотрены девять моделей, вместе они покрывают все решения по визуализации, спецификации, конструированию и документированию программных систем:
q бизнес-модель. Определяет абстракцию организации, для которой создается система;
q модель области определения. Фиксирует контекстное окружение системы;
q модель Use Case. Определяет функциональные требования к системе;
q модель анализа. Интерпретирует требования к системе в терминах проектной модели;
q проектная модель. Определяет словарь проблемы и ее решение;
q модель размещения. Определяет аппаратную топологию, в которой исполняется система;
q модель реализации. Определяет части, которые используются для сборки и реализации физической системы;
q тестовая модель. Определяет тестовые варианты для проверки системы;
q модель процессов. Определяет параллелизм в системе и механизмы синхронизации.
Модели качества процессов конструирования
В современных условиях, условиях жесткой конкуренции, очень важно гарантировать высокое качество вашего процесса конструирования ПО. Такую гарантию дает сертификат качества процесса, подтверждающий его соответствие принятым международным стандартам. Каждый такой стандарт фиксирует свою модель обеспечения качества. Наиболее авторитетны модели стандартов ISO 9001:2000, ISO/ IEC 15504 и модель зрелости процесса конструирования ПО (Capability Maturity Model — СММ) Института программной инженерии при американском университете Карнеги-Меллон.
Модель стандарта ISO 9001:2000 ориентирована на процессы разработки из любых областей человеческой деятельности. Стандарт ISO/IEC 15504 специализируется на процессах программной разработки и отличается более высоким уровнем детализации. Достаточно сказать, что объем этого стандарта превышает 500 страниц. Значительная часть идей ISO/IEC 15504 взята из модели СММ.
Базовым понятием модели СММ считается зрелость компании [61], [62]. Незрелой называют компанию, где процесс конструирования ПО и принимаемые решения зависят только от таланта конкретных разработчиков. Как следствие, здесь высока вероятность превышения бюджета или срыва сроков окончания проекта.
Напротив, в зрелой компании работают ясные процедуры управления проектами и построения программных продуктов. По мере необходимости эти процедуры уточняются и развиваются. Оценки длительности и затрат разработки точны, основываются на накопленном опыте. Кроме того, в компании имеются и действуют корпоративные стандарты на процессы взаимодействия с заказчиком, процессы анализа, проектирования, программирования, тестирования и внедрения программных продуктов. Все это создает среду, обеспечивающую качественную разработку программного обеспечения.
Таким образом, модель СММ фиксирует критерии для оценки зрелости компании и предлагает рецепты для улучшения существующих в ней процессов. Иными словами, в ней не только сформулированы условия, необходимые для достижения минимальной организованности процесса, но и даются рекомендации по дальнейшему совершенствованию процессов.
Основное отличие от уровня 4 заключается в том, что технология создания и сопровождения программных продуктов планомерно и последовательно совершенствуется.
Каждый уровень СММ характеризуется областью ключевых процессов (ОКП), причем считается, что каждый последующий уровень включает в себя все характеристики предыдущих уровней. Иначе говоря, для 3-го уровня зрелости рассматриваются ОКП 3-го уровня, ОКП 2-го уровня и ОКП 1-го уровня. Область ключевых процессов образуют процессы, которые при совместном выполнении приводят к достижению определенного набора целей. Например, ОКП 5-го уровня образуют процессы:
q предотвращения дефектов;
q управления изменениями технологии;
q управления изменениями процесса.
Если все цели ОКП достигнуты, компании присваивается сертификат данного уровня зрелости. Если хотя бы одна цель не достигнута, то компания не может соответствовать данному уровню СММ.
Моделирование поведения программной системы
Для моделирования поведения системы используют:
q автоматы;
q взаимодействия.
Автомат (State machine) описывает поведение в терминах последовательности состояний, через которые проходит объект в течение своей жизни. Взаимодействие (Interaction) описывает поведение в терминах обмена сообщениями между объектами.
Таким образом, автомат задает поведение системы как цельной, единой сущности; моделирует жизненный цикл единого объекта. В силу этого автоматный подход удобно применять для формализации динамики отдельного трудного для понимания блока системы.
Взаимодействия определяют поведение системы в виде коммуникаций между его частями (объектами), представляя систему как сообщество совместно работающих объектов. Именно поэтому взаимодействия считают основным аппаратом для фиксации полной динамики системы.
Автоматы отображают с помощью:
q диаграмм схем состояний;
q диаграмм деятельности.
Взаимодействия отображают с помощью:
q диаграмм сотрудничества (кооперации);
q диаграмм последовательности.
Моделирование программного текста системы
При разработке сложных систем программный текст (исходный код) разбросан по многим файлам исходного кода. При использовании Java исходный код сохраняется в .java-файлах, при использовании C++ — в заголовочных файлах (.h-фай-лах) и телах (.срр-файлах), при использовании Ada 95 — в спецификациях (.ads-файлах) и реализациях (.adb-файлах).
Между файлами существуют многочисленные зависимости компиляции. Если к этому добавить, что по мере разработки рождаются новые версии файлов, то становится очевидной необходимость управления конфигурацией системы, визуализации компиляционных зависимостей.
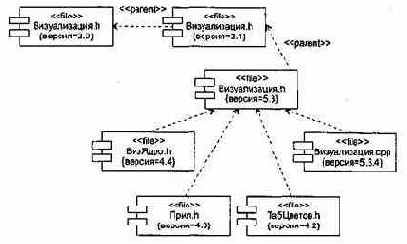
Рис. 13.10. Моделирование исходного кода

Рис. 13.11. Моделирование исходного кода с использованием пиктограмм
В качестве примера на рис. 13.10 приведена компонентная диаграмма, где изображены файлы исходного кода, используемые для построения библиотеки Визуализация.dll. Имеются четыре заголовочных файла (Визуализация.h, ВизЯдро.h, Прил.h, ТабЦветов.h), которые представляют исходный код для спецификации определенных классов. Файл реализации здесь один (Визуализация.срр), он является реализацией одного из заголовков. Отметим, что для каждого файла явно указана его версия, причем для файла Визуализация.h показаны три версии и история их появления. На рис. 13.11 повторяется та же диаграмма, но здесь для обозначения компонентов использованы специальные пиктограммы.
Моделирование реализации системы
Реализация системы может включать большое количество разнообразных компонентов:
q исполняемых элементов;
q динамических библиотек;
q файлов данных;
q справочных документов;
q файлов инициализации;
q файлов регистрации;
q сценариев;
q файлов установки.
Моделирование этих компонентов, отношений между ними — важная часть управления конфигурацией системы.
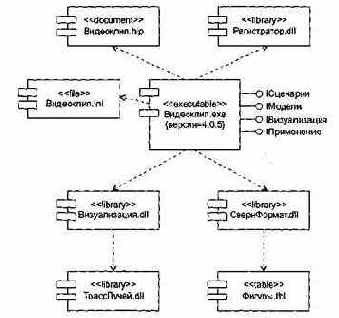
Рис. 13.12. Моделирование реализации системы
Например, на рис. 13.12 показана часть реализации системы, группируемая вокруг исполняемого элемента Видеоклип.ехе. Здесь изображены четыре библиотеки (Регистратор.dll, СвернФормат.dll, Визуализация.dll, ТрассЛучей.dll), один документ (Видеоклип.hlp), один простой файл (Видеоклип.ini),атакже таблица базы данных (Фигуры.tbl). В диаграмме указаны отношения зависимости, существующие между компонентами.
Для исполняемого компонента Видеоклип.ехе указан номер версии (с помощью пгеговой величины), представлены его экспортируемые интерфейсы (IСценарии, IВизуализация, IМодели, IПрименение). Эти интерфейсы образуют API компонента «интерфейс прикладного программирования).
На рис. 13.13 повторяется та же диаграмма, моделирующая реализацию, но здесь для обозначения компонентов использованы специальные пиктограммы.
Рис. 13.13. Моделирование реализации с использованием пиктограмм
Моделирование управления
Известны два типа моделей управления:
q модель централизованного управления;
q модель событийного управления.
В модели централизованного управления одна подсистема выделяется как системный контроллер. Ее обязанности — руководить работой других подсистем. Различают две разновидности моделей централизованного управления: модель вызов-возврат (рис. 4.7) и Модель менеджера (рис. 4.8), которая используется в системах параллельной обработки.
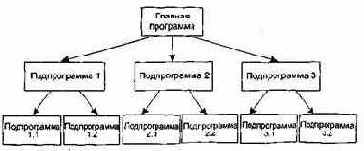
Рис. 4.7. Модель вызов-возврат
В модели событийного управления системой управляют внешние события. Используются две разновидности модели событийного управления: широковещательная модель и модель, управляемая прерываниями.
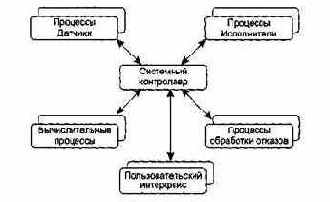
Рис. 4.8. Модель менеджера
В широковещательной модели (рис. 4.9) каждая подсистема уведомляет обработчика о своем интересе к конкретным событиям. Когда событие происходит, обработчик пересылает его подсистеме, которая может обработать это событие. Функции управления в обработчик не встраиваются.

Рис. 4.9. Широковещательная модель
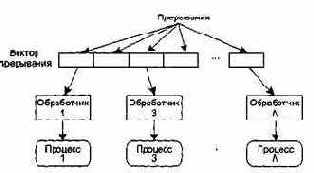
Рис. 4.10. Модель, управляемая прерываниями
В модели, управляемой прерываниями (рис. 4.10), все прерывания разбиты на группы — типы, которые образуют вектор прерываний. Для каждого типа прерывания есть свой обработчик. Каждый обработчик реагирует на свой тип прерывания и запускает свой процесс.
Модульность
Модуль — фрагмент программного текста, являющийся строительным блоком для физической структуры системы. Как правило, модуль состоит из интерфейсной части и части-реализации.
Модульность — свойство системы, которая может подвергаться декомпозиции на ряд внутренне связанных и слабо зависящих друг от друга модулей.
По определению Г. Майерса, модульность — свойство ПО, обеспечивающее интеллектуальную возможность создания сколь угодно сложной программы [52]. Проиллюстрируем эту точку зрения.
Пусть С(х) — функция сложности решения проблемы х, Т(х) — функция затрат времени на решение проблемы х. Для двух проблем р1 и р2 из соотношения С(р1) > С(р2) следует, что
T(pl)>T(p2). (4.1)
Этот вывод интуитивно ясен: решение сложной проблемы требует большего времени.
Далее. Из практики решения проблем человеком следует:
С(р1+ р2)>С(р1) + С(р2).
Отсюда с учетом соотношения (4.1) запишем:
T(pl+p2)>T(pl) + T(p2). (4.2)
Соотношение (4.2) — это обоснование модульности. Оно приводит к заключению «разделяй и властвуй» — сложную проблему легче решить, разделив ее на управляемые части. Результат, выраженный неравенством (4.2), имеет важное значение для модульности и ПО. Фактически, это аргумент в пользу модульности.
Однако здесь отражена лишь часть реальности, ведь здесь не учитываются затраты на межмодульный интерфейс. Как показано на рис. 4.11, с увеличением количества модулей (и уменьшением их размера) эти затраты также растут.
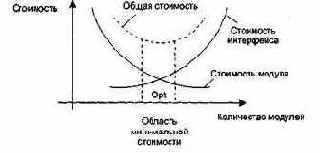
Рис. 4.11. Затраты на модульность
Таким образом, существует оптимальное количество модулей Opt, которое приводит к минимальной стоимости разработки. Увы, у нас нет необходимого опыта для гарантированного предсказания Opt. Впрочем, разработчики знают, что оптимальный модуль должен удовлетворять двум критериям:
q снаружи он проще, чем внутри;
q его проще использовать, чем построить.
В языках C++, Object Pascal, Ada 95 абстракции классов и объектов формируют логическую структуру системы. При производстве физической структуры эти абстракции помещаются в модули. В больших системах, где классов сотни, модули помогают управлять сложностью. Модули служат физическими контейнерами, в которых объявляются классы и объекты логической разработки.
Модульность определяет способность системы подвергаться декомпозиции на ряд сильно связанных и слабо сцепленных модулей.
Общая цель декомпозиции на модули: уменьшение сроков разработки и стоимости ПС за счет выделения модулей, которые проектируются и изменяются независимо. Каждая модульная структура должна быть достаточно простой, чтобы быть полностью понятой. Изменение реализации модулей должно проводиться без знания реализации других модулей и без влияния на их поведение.
Определение классов и объектов выполняется в ходе логической разработки, а определение модулей — в ходе физической разработки системы. Эти действия сильно взаимосвязаны, осуществляются итеративно.
В Ada 95 мощным средством обеспечения модульности является пакет.
Пример: пусть имеется несколько программ управления полетом летательного аппарата (ЛА) — программа угловой стабилизации ЛА и программа управления движением центра масс ЛА. Нужно создать модуль, чье назначение — собрать все эти программы. Возможны два способа.
1. Присоединение с помощью указателей контекста:
with Класс_УгловСтабил, Класс_ДвиженЦентраМасс;
use Класс_УгловСтабил, Класс_ДвиженЦентраМасс;
Package Класс_УпрПолетом is
…
2. Встраивание программ управления непосредственно в объединенный модуль:
Package Класс_УпрПолетом is
type УгловСтабил is tagged private;
type ДвиженЦентраМасс is tagged private;
-------------------------
Набор метрик Чидамбера и Кемерера
В 1994 году С. Чидамбер и К. Кемерер (Chidamber и Кетегег) предложили шесть проектных метрик, ориентированных на классы [24]. Класс — фундаментальный элемент объектно-ориентированной (ОО) системы. Поэтому измерения и метрики для отдельного класса, иерархии классов и сотрудничества классов бесценны для программного инженера, который должен оценить качество проекта.
Набор Чидамбера-Кемерера наиболее часто цитируется в программной индустрии и научных исследованиях. Рассмотрим каждую из метрик набора.
Метрика 1: Взвешенные методы на класс WMC (Weighted Methods Per Class)
Допустим, что в классе С определены п методов со сложностью с1...,c2,..., сn. Для оценки сложности может быть выбрана любая метрика сложности (например, цикломатическая сложность). Главное — нормализовать эту метрику так, чтобы номинальная сложность для метода принимала значение 1. В этом случае

Количество методов и их сложность являются индикатором затрат на реализацию и тестирование классов. Кроме того, чем больше методов, тем сложнее дерево наследования (все подклассы наследуют методы их родителей). С ростом количества методов в классе его применение становится все более специфическим, тем самым ограничивается возможность многократного использования. По этим причинам метрика WMC должна иметь разумно низкое значение.
Очень часто применяют упрощенную версию метрики. При этом полагают Сi= 1, и тогда WMC — количество методов в классе.
Оказывается, что подсчитывать количество методов в классе достаточно сложно. Возможны два противоположных варианта учета.
1. Подсчитываются только методы текущего класса. Унаследованные методы игнорируются. Обоснование — унаследованные методы уже подсчитаны в тех классах, где они определялись. Таким образом, инкрементность класса — лучший показатель его функциональных возможностей, который отражает его право на существование. Наиболее важным источником информации для понимания того, что делает класс, являются его собственные операции.
Если класс не может отреагировать на сообщение (например, в нем отсутствует собственный метод), тогда он пошлет сообщение родителю.
2. Подсчитываются методы, определенные в текущем классе, и все унаследованные методы. Этот подход подчеркивает важность пространства состояний в понимании класса (а не инкрементности класса).
Существует ряд промежуточных вариантов. Например, подсчитываются текущие методы и методы, прямо унаследованные от родителей. Аргумент в пользу данного подхода — на поведение дочернего класса наиболее сильно влияет специализация родительских классов.
На практике приемлем любой из описанных вариантов. Главное — не менять вариант учета от проекта к проекту. Только в этом случае обеспечивается корректный сбор метрических данных.
Метрика WMC дает относительную меру сложности класса. Если считать, что все методы имеют одинаковую сложность, то это будет просто количество методов в классе. Существуют рекомендации по сложности методов. Например, М. Лоренц считает, что средняя длина метода должна ограничиваться 8 строками для Smalltalk и 24 строками для C++ [45]. Вообще, класс, имеющий максимальное количество методов среди классов одного с ним уровня, является наиболее сложным; скорее всего, он специфичен для данного приложения и содержит наибольшее количество ошибок.
Метрика 2: Высота дерева наследования DIT (Depth of Inheritance Tree)
DIT определяется как максимальная длина пути от листа до корня дерева наследования классов. Для показанной на рис. 14.3 иерархии классов метрика DIT равна 3.

Рис. 14.3. Дерево наследования классов
Соответственно, для отдельного класса DIT, это длина максимального пути от данного класса до корневого класса в иерархии классов.
По мере роста DIT вероятно, что классы нижнего уровня будут наследовать много методов. Это приводит к трудностям в предсказании поведения класса. Высокая иерархия классов (большое значение DIT) приводит к большей сложности проекта, так как означает привлечение большего количества методов и классов.
Вместе с тем, большое значение DIT подразумевает, что многие методы могут использоваться многократно.
Метрика 3: Количество детей NOC (Number of children)
Подклассы, которые непосредственно подчинены суперклассу, называются его детьми. Значение NOC равно количеству детей, то есть количеству непосредственных наследников класса в иерархии классов. На рис. 14.3 класс С2 имеет двух детей — подклассы С21 и С22.
С увеличением NOC возрастает многократность использования, так как наследование — это форма повторного использования.
Однако при возрастании NOC ослабляется абстракция родительского класса. Это означает, что в действительности некоторые из детей уже не являются членами родительского класса и могут быть неправильно использованы.
Кроме того, количество детей характеризует потенциальное влияние класса на проект. По мере роста NOC возрастает количество тестов, необходимых для проверки каждого ребенка.
Метрики DIT и NOC — количественные характеристики формы и размера структуры классов. Хорошо структурированная объектно-ориентированная система чаще бывает организована как лес классов, чем как сверхвысокое дерево. По мнению Г. Буча, следует строить сбалансированные по высоте и ширине структуры наследования: обычно не выше, чем 7 ± 2 уровня, и не шире, чем 7 + 2 ветви [22].
Метрика 4: Сцепление между классами объектов СВО (Coupling between object classes)
СВО — это количество сотрудничеств, предусмотренных для класса, то есть количество классов, с которыми он соединен. Соединение означает, что методы данного класса используют методы или экземплярные переменные другого класса.
Другое определение метрики имеет следующий вид: СВО равно количеству сцеплений класса; сцепление образует вызов метода или свойства в другом классе.
Данная метрика характеризует статическую составляющую внешних связей классов.
С ростом СВО многократность использования класса, вероятно, уменьшается. Очевидно, что чем больше независимость класса, тем легче его повторно использовать в другом приложении.
Высокое значение СВО усложняет модификацию и тестирование, которое следует за выполнением модификации. Понятно, что, чем больше количество сцеплений, тем выше чувствительность всего проекта к изменениям в отдельных его частях. Минимизация межобъектных сцеплений улучшает модульность и содействует инкапсуляции проекта.
СВО для каждого класса должно иметь разумно низкое значение. Это согласуется с рекомендациями по уменьшению сцепления стандартного программного обеспечения.
Метрика 5: Отклик для класса RFC (Response For a Class)
Введем вспомогательное определение. Множество отклика класса RS — это множество методов, которые могут выполняться в ответ на прибытие сообщений в объект этого класса. Формула для определения RS имеет вид

где {Ri} — множество методов, вызываемых методом г, {М} — множество всех методов в классе.
Метрика RFC равна количеству методов во множестве отклика, то есть равна мощности этого множества:
RFC – card{RS}.
Приведем другое определение метрики: RFC — это количество методов класса плюс количество методов других классов, вызываемых из данного класса.
Метрика RFC является мерой потенциального взаимодействия данного класса с другими классами, позволяет судить о динамике поведения соответствующего объекта в системе. Данная метрика характеризует динамическую составляющую внешних связей классов.
Если в ответ на сообщение может быть вызвано большое количество методов, то усложняются тестирование и отладка класса, так как от разработчика тестов требуется больший уровень понимания класса, растет длина тестовой последовательности.
С ростом RFC увеличивается сложность класса. Наихудшая величина отклика может использоваться при определении времени тестирования.
Метрика 6: Недостаток связности в методах LСOM (Lack of Cohesion in Methods)
Каждый метод внутри класса обращается к одному или нескольким свойствам (экземплярным переменным). Метрика LCOM показывает, насколько методы не связаны друг с другом через свойства (переменные).
Если все методы обращаются к одинаковым свойствам, то LCOM = 0.
Введем обозначения:
q НЕ СВЯЗАНЫ — количество пар методов без общих экземплярных переменных;
q СВЯЗАНЫ — количество пар методов с общими экземплярными переменными.
q Ij— набор экземплярных переменных, используемых методом Мj
Очевидно, что
НЕ СВЯЗАНЫ = card {Iij | Ii

СВЯЗАНЫ = card {Iij | Ii

Тогда формула для вычисления недостатка связности в методах примет вид

Можно определить метрику по-другому: LCOM — это количество пар методов, не связанных по свойствам класса, минус количество пар методов, имеющих такую связь.
Рассмотрим примеры применения метрики LCOM.
Пример 1: В классе имеются методы: M1, M2, М3, М4. Каждый метод работает со своим набором экземплярных переменных:
I1={a, b}; I2={а, с}; I3={х, у}; I4={т, п}.
В этом случае
НЕ СВЯЗАНЫ = card (I13, I14, I23, I24, I34) = 5; СВЯЗАНЫ = card (I12) = 1.
LCOM = 5-1=4.
Пример 2: В классе используются методы: M1, M2, М3. Для каждого метода задан свой набор экземплярных переменных:
I1 = {a,b};I2={a,c};I3={x,y},
НЕ СВЯЗАНЫ = card (I13, I23) = 2; СВЯЗАНЫ = card (I12) = 1,
LCOM = 2- 1 = 1.
Связность методов внутри класса должна быть высокой, так как это содействует инкапсуляции. Если LCOM имеет высокое значение, то методы слабо связаны друг с другом через свойства. Это увеличивает сложность, в связи с чем возрастает вероятность ошибок при проектировании.
Высокие значения LCOM означают, что класс, вероятно, надо спроектировать лучше (разбиением на два или более отдельных класса). Любое вычисление LCOM помогает определить недостатки в проектировании классов, так как эта метрика характеризует качество упаковки данных и методов в оболочку класса.
Вывод: связность в классе желательно сохранять высокой, то есть следует добиваться низкого значения LCOM.
Набор метрик Чидамбера-Кемерера — одна из пионерских работ по комплексной оценке качества ОО-проектирования.
Известны многочисленные предложения по усовершенствованию, развитию данного набора. Рассмотрим некоторые из них.
Недостатком метрики WMC является зависимость от реализации. Приведем пример. Рассмотрим класс, предлагающий операцию интегрирования. Возможны две реализации:
1) несколько простых операций:
Set_interval (min. max)
Setjnethod (method)
Set_precision (precision)
Set_function_to_integrate (function)
Integrate;
2) одна сложная операция:
Integrate (function, min, max. method, precision)
Для обеспечения независимости от этих реализаций можно определить метрику WMC2:

Для нашего примера WMC2 = 5 и для первой, и для второй реализации. Заметим, для первой реализации WMC = 5, а для второй реализации WMC = 1.
Дополнительно можно определить метрику Среднее число аргументов метода ANAM (Average Number of Arguments per Method):
ANAM = WMC2/WMC.
Полезность метрики ANAM объяснить еще легче. Она ориентирована на принятые в ОО-проектировании решения — применять простые операции с малым количеством аргументов, а несложные операции — с многочисленными аргументами.
Еще одно предложение — ввести метрику, симметричную метрике LCOM. В то время как формула метрики LCOM имеет вид:
LCOM = max (0, НЕ СВЯЗАНЫ - СВЯЗАНЫ),
симметричная ей метрика Нормализованная NLСОМ вычисляется по формуле:
NLCOM = СВЯЗАНЫ/(НЕ СВЯЗАНЫ + СВЯЗАНЫ).
Диапазон значений этой метрики: 0

В наборе Чидамбера-Кемерера отсутствует метрика для прямого измерения информационной закрытости класса. В силу этого была предложена метрика Поведенческая закрытость информации BIH (Behaviourial Information Hiding):
BIH - (WEOC/WIEOC),
где WEOC — взвешенные внешние операции на класс (фактически это WMC);
WIEOC — взвешенные внутренние и внешние операции на класс.
WIEОС вычисляется так же, как и WMC, но учитывает полный набор операций, реализуемых классом. Если BIH = 1, класс показывает другим классам все свои возможности. Чем меньше ВIM, тем меньше видимо поведение класса.BIH может рассматриваться и как мера сложности. Сложные классы, вероятно, будут иметь малые значения BIH, а простые классы — значения, близкие к 1. Если класс с высокой WMC имеет значение BIH, близкое к 1, следует выяснить, почему он настолько видим извне.
Набор метрик Фернандо Абреу
Набор метрик MOOD (Metrics for Object Oriented Design), предложенный Ф. Абреу в 1994 году, — другой пример академического подхода к оценке качества ОО-проектирования [6]. Основными целями MOOD-набора являются:
1) покрытие базовых механизмов объектно-ориентированной парадигмы, таких как инкапсуляция, наследование, полиморфизм, посылка сообщений;
2) формальное определение метрик, позволяющее избежать субъективности измерения;
3) независимость от размера оцениваемого программного продукта;
4) независимость от языка программирования, на котором написан оцениваемый продукт.
Набор MOOD включает в себя следующие метрики:
1) фактор закрытости метода (МНF);
2) фактор закрытости свойства (AHF);
3) фактор наследования метода (MIF);
4) фактор наследования свойства (AIF);
5) фактор полиморфизма (POF);
6) фактор сцепления (СОF).
Каждая из этих метрик относится к основному механизму объектно-ориентированной парадигмы: инкапсуляции (МНF и АНF), наследованию (MIF и AIF), полиморфизму (POF) и посылке сообщений (СОF). В определениях MOOD не используются специфические конструкции языков программирования.
Метрика 1: Фактор закрытости метода MHF (Method Hiding Factor)
Введем обозначения:
q Мv (Сi) — количество видимых методов в классе Сi (интерфейс класса);
q Мh (Сi) — количество скрытых методов в классе Сi (реализация класса);
q Мd (Сi) = Мv (Сi) + Мh (Сi) — общее количество методов, определенных в классе С, (унаследованные методы не учитываются).
Тогда формула метрики МНF примет вид:

где ТС — количество классов в системе.
Если видимость т-го метода i-го класса из j-го класса вычислять по выражению:

a процентное количество классов, которые видят m-й метод i-го класса, определять по соотношению:

то формулу метрики МНF можно
представить в виде:

В числителе этой формулы МНF — сумма закрытости всех методов во всех классах. Закрытость метода — процентное количество классов, из которых данный метод невидим. Знаменатель МНF — общее количество методов, определенных в рассматриваемой системе.
С увеличением МНF уменьшаются плотность дефектов в системе и затраты на их устранение. Обычно разработка класса представляет собой пошаговый процесс, при котором к классу добавляется все больше и больше деталей (скрытых методов). Такая схема разработки способствует возрастанию как значения МНF, так и качества класса.
Метрика 2: Фактор закрытости свойства AHF (Attribute Hiding Factor)
Введем обозначения:
q Аv (Сi) — количество видимых свойств в классе Сi (интерфейс класса);
q Ah(Ci) — количество скрытых свойств в классе Сi (реализация класса);
q Ad(Ci) = Аv (Сi) + Ah(Ci) — общее количество свойств, определенных в классе Сi (унаследованные свойства не учитываются).
Тогда формула метрики AHF примет вид:

где ТС — количество классов в системе.
Если видимость т-го свойства i-го класса из j-ro класса вычислять по выражению:

а процентное количество классов, которые видят т-е свойство i-ro класса, определять по соотношению:

то формулу метрики AHFможно представить в виде:

В числителе этой формулы AHF — сумма закрытости всех свойств во всех классах. Закрытость свойства — процентное количество классов, из которых данное свойство невидимо. Знаменатель AHF — общее количество свойств, определенных в рассматриваемой системе.
В идеальном случае все свойства должны быть скрыты и доступны только для методов соответствующего класса (AHF = 100%).
Метрика 3: Фактор наследования метода MIF (Method Inheritance Factor)
Введем обозначения:
q M i (Сi ) — количество унаследованных и не переопределенных методов в классе Сi;
q M 0(Сi ) — количество унаследованных и переопределенных методов в классе Сi;
q M n(Сi ) — количество новых (не унаследованных и переопределенных) методов в классе Сi;
q M d(Сi )=
M n(Сi ) +
M 0(Сi ) — количество методов, определенных в классе Сi;
q M a(Сi )=
M d(Сi )+
M i (Сi ) — общее количество методов, доступных в классе Сi.
Тогда формула метрики MIF примет вид:

Числителем MIF является сумма унаследованных (и не переопределенных) методов во всех классах рассматриваемой системы. Знаменатель MIF — это общее количество доступных методов (локально определенных и унаследованных) для всех классов.
Значение MIF = 0 указывает, что в системе отсутствует эффективное наследование, например, все унаследованные методы переопределены.
С увеличением MIF уменьшаются плотность дефектов и затраты на исправление ошибок. Очень большие значения MIF (70-80%) приводят к обратному эффекту, но этот факт нуждается в дополнительной экспериментальной проверке. Сформулируем «осторожный» вывод: умеренное использование наследования — подходящее средство для снижения плотности дефектов и затрат на доработку.
Метрика 4: Фактор наследования свойства AIF (Attribute Inheritance Factor)
Введем обозначения:
q Аi (Сi) — количество унаследованных и не переопределенных свойств в классе Сi;
q А0(Сi) — количество унаследованных и переопределенных свойств в классе Сi;
q An(Ci) — количество новых (не унаследованных и переопределенных) свойств в классе Сi;
q Аd(Сi) = An(Ci) + А0(Сi) — количество свойств, определенных в классе Сi;
q Аa(Сi) = Аd(Сi)+ Аi (Сi) — общее количество свойств, доступных в классе Сi.
Тогда формула метрики AIF примет вид:

Числителем AIF является сумма унаследованных (и не переопределенных) свойств во всех классах рассматриваемой системы. Знаменатель AIF — это общее количество доступных свойств (локально определенных и унаследованных) для всех классов.
Метрика 5: Фактор полиморфизма POF (Polymorphism Factor)
Введем обозначения:
q M0(Сi) — количество унаследованных и переопределенных методов в классе Сi;
q Mn(Сi) — количество новых (не унаследованных и переопределенных) методов в классе Сi;
q DC(Сi) — количество потомков класса Сi;
q Md(Сi) = Mn(Сi) + M0(Сi) — количество методов, определенных в классе Сi.
Тогда формула метрики POF примет вид:

Числитель POF фиксирует реальное количество возможных полиморфных ситуаций. Очевидно, что сообщение, посланное в класс Сi связывается (статически или динамически) с реализацией именуемого метода. Этот метод, в свою очередь, может или представляться несколькими «формами», или переопределяться (в потомках Сi).
Знаменатель POF представляет максимальное количество возможных полиморфных ситуаций для класса Сi. Имеется в виду случай, когда все новые методы, определенные в Сi, переопределяются во всех его потомках.
Умеренное использование полиморфизма уменьшает как плотность дефектов, так и затраты на доработку. Однако при POF > 10% возможен обратный эффект.
Метрика 6: Фактор сцепления COF (Coupling Factor)
В данном наборе сцепление фиксирует наличие между классами отношения «клиент-поставщик» (client-supplier). Отношение «клиент-поставщик» (Сc =>Cs) здесь означает, что класс-клиент содержит но меньшей мере одну не унаследованную ссылку на свойство или метод класса-поставщика.

Если наличие отношения «клиент-поставщик» определять по выражению:

то формула для вычисления метрики COF примет вид:
Знаменатель COF соответствует максимально возможному количеству сцеплений в системе с ТС-классами (потенциально каждый класс может быть поставщиком для других классов).Из рассмотрения исключены рефлексивные отношения — когда класс является собственным поставщиком. Числитель COF фиксирует реальное количество сцеплений, не относящихся к наследованию.
С увеличением сцепления классов плотности дефектов и затрат на доработку также возрастают. Сцепления отрицательно влияют на качество ПО, их нужно сводить к минимуму. Практическое применение этой метрики доказывает, что сцепление увеличивает сложность, уменьшает инкапсуляцию и возможности повторного использования, затрудняет понимание и усложняет сопровождение ПО.
Начало проекта
Перед планированием проекта следует:
q установить цели и проблемную область проекта;
q обсудить альтернативные решения;
q выявить технические и управленческие ограничения.
Наследование
Наследование — это отношение, при котором один класс разделяет структуру и поведение, определенные в одном другом (простое наследование) или во многих других (множественное наследование) классах.
Между п классами наследование определяет иерархию «является» («is а»), при которой подкласс наследует от одного или нескольких более общих суперклассов. Говорят, что подкласс является специализацией его суперкласса (за счет дополнения или переопределения существующей структуры или поведения).
Пример: дана система для записи параметров полета в «черный ящик», установленный в самолете. Организуем систему в виде иерархии классов, построенной на базе наследования. Абстракция «верхнего» класса иерархии имеет вид
with ...;...
use ...; ...
Package Класс_ПараметрыПолета is
type ПараметрыПолета is tagged private;
function Инициировать return ПараметрыПолета;
procedure Записывать (the: in out ПараметрыПолета);
function ТекущВремя (the: ПараметрыПолета)
return БортовоеВремя;
private
type ПараметрыПолета is tagged record
Имя: integer;
ОтметкаВремени: БортовоеВремя;
end record;
end Класс_ПараметрыПолета;
Запись параметров кабины самолета может обеспечиваться следующим классом:
with Класс_ПараметрыПолета; ...
use Класс_ПараметрыПолета; ...
Package Класс_Кабина is
type Кабина is new ПараметрыПолета with private;
function Инициировать (Д:Давление; К:Кислород;
Т:Температура) return Кабина;
procedure Записывать (the: in out Кабина);
function ПерепадДавления (the: Кабина) return Давление;
private
type Кабина is new ПараметрыПолета
with record
параметр1: Давление;
параметр2: Кислород;
параметр3: Температура
end record;
end Класс_Кабина;
Этот класс наследует структуру и поведение класса ПараметрыПолета, но наращивает его структуру (вводит три новых элемента данных), переопределяет его поведение (процедура Записывать) и дополняет его поведение (функция ПерепадДавления).
Иерархическая структура классов системы для записи параметров полета, находящихся в отношении наследования, показана на рис. 9.12.

Рис. 9.12. Иерархия простого наследования
Здесь ПараметрыПолета — базовый (корневой) суперкласс, подклассами которого являются Экипаж, ПараметрыДвижения, Приборы, Кабина. В свою очередь, класс ПараметрыДвижения является суперклассом для его подклассов Координаты, Скорость, Ориентация.
Наследование — механизм, обеспечивающий тиражирование обязанностей одного класса в другие классы. Наследование распространяется через все уровни иерархии классов. Стандартные ПС не поддерживают эту характеристику.
Поскольку наследование — основная характеристика объектно-ориентированных систем, на ней фокусируются многие объектно-ориентированные метрики (количество детей — потомков класса, количество родителей, высота класса в иерархии наследования).
Неструктурированные циклы
Неструктурированные циклы тестированию не подлежат. Этот тип циклов должен быть переделан с помощью структурированных программных конструкций.
Нисходящее тестирование интеграции
В данном подходе модули объединяются движением сверху вниз по управляющей иерархии, начиная от главного управляющего модуля. Подчиненные модули добавляются в структуру или в результате поиска в глубину, или в результате поиска в ширину.
Рассмотрим пример (рис. 8.4). Интеграция поиском в глубину будет подключать все модули, находящиеся на главном управляющем пути структуры (по вертикали). Выбор главного управляющего пути отчасти произволен и зависит от характеристик, определяемых приложением. Например, при выборе левого пути прежде всего будут подключены модули Ml, М2, М5. Следующим подключается модуль М8 или Мб (если это необходимо для правильного функционирования М2). Затем строится центральный или правый управляющий путь.
При интеграции поиском в ширину структура последовательно проходится по уровням-горизонталям. На каждом уровне подключаются модули, непосредственно подчиненные управляющему модулю — начальнику. В этом случае прежде всего подключаются модули М2, М3, М4. На следующем уровне — модули М5, Мб и т. д.
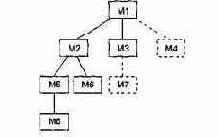
Рис. 8.4. Нисходящая интеграция системы
Опишем возможные шаги процесса нисходящей интеграции.
1. Главный управляющий модуль (находится на вершине иерархии) используется как тестовый драйвер. Все непосредственно подчиненные ему модули временно замещаются заглушками.
2. Одна из заглушек заменяется реальным модулем. Модуль выбирается поиском в ширину или в глубину.
3. После подключения каждого модуля (и установки на нем заглушек) проводится набор тестов, проверяющих полученную структуру.
4. Если в модуле-драйвере уже нет заглушек, производится смена модуля-драйвера (поиском в ширину или в глубину).
5. Выполняется возврат на шаг 2 (до тех пор, пока не будет построена целая структура).
Достоинство нисходящей интеграции: ошибки в главной, управляющей части системы выявляются в первую очередь.
Недостаток: трудности в ситуациях, когда для полного тестирования на верхних уровнях нужны результаты обработки с нижних уровней иерархии.
Существуют 3 возможности борьбы с этим недостатком:
1) откладывать некоторые тесты до замещения заглушек модулями;
2) разрабатывать заглушки, частично выполняющие функции модулей;
3) подключать модули движением снизу вверх.
Первая возможность вызывает сложности в оценке результатов тестирования.
Для реализации второй возможности выбирается одна из следующих категорий заглушек:
q заглушка А — отображает трассируемое сообщение;
q заглушка В — отображает проходящий параметр;
q заглушка С — возвращает величину из таблицы;
q заглушка D — выполняет табличный поиск по ключу (входному параметру) и возвращает связанный с ним выходной параметр.

Рис. 8.5. Категории заглушек
Категории заглушек представлены на рис. 8.5.
Очевидно, что заглушка А наиболее проста, а заглушка D наиболее сложна в реализации.
Этот подход работоспособен, но может привести к существенным затратам, так как заглушки становятся все более сложными.
Третью возможность обсудим отдельно.
Низкий
Номинальный Высокий Очень высокий Сверхвысокий АСАР 15% 35% 55% 75% 90%
Таблица А.11. Возможности программиста (Programmer Capability) PCAP
| Фактор | Очень низкий | Низкий | Номинальный | Высокий | Очень высокий | Сверхвысокий | |||||||
| РСАР | 15% | 35% | 55% | 75% | 90% |
Таблица А. 12. Опыт работы с приложением (Applications Experience) AEXP
| Фактор | Очень низкий | Низкий | Номинальный | Высокий | Очень высокий | Сверхвысокий | |||||||
| АЕХР | 2 месяца | 6 месяцев | 1 год | 3 года | 6 лет |
Таблица А. 13. Опыт работы с платформой (Platform Experience) PEXP
| Фактор | Очень низкий | Низкий | Номинальный | Высокий | Очень высокий | Сверхвысокий | |||||||
| РЕХР | 2 месяца | 6 месяцев | 1 год | 3 года | 6 лет |
Таблица А. 14. Опыт работы с языком и утилитами (Language and Tool Experience) LTEX
| Фактор | Очень низкий | Низкий | Номинальный | Высокий | Очень высокий | Сверхвысокий | |||||||
| LTEX | 2 месяца | 6 месяцев | 1 год | Згода | 6 лет |
Таблица А. 15. Непрерывность персонала (Personnel Continuity) PCON
| Фактор | Очень низкий | Низкий | Номинальный | Высокий | Очень высокий | Сверхвысокий | |||||||
| PCON | 48%/год | 24%/год | 12%/год | 6%/год | 3%/год |
ПРИМЕЧАНИЕ
С помощью фактора PCON учитывается процент смены персонала.
Факторы проекта
Таблица А. 16. Использование программных утилит (Use of Software Tools) TOOL
| Фактор | Очень низкий | Низкий | Номинальный | Высокий | Очень высокий | Сверхвысокий | |||||||
| TOOL | Редактирование, кодирование, отладка | Простая входная, выходная CASE-утилита, малая интеграция | Базовые утилиты жизненного цикла, умеренная интеграция | Развитые утилиты жизненного цикла, умеренная интеграция | Развитые утилиты жизненного цикла, хорошо интегрированные с процессами, методами, повторным использованием |
Таблица А. 17. Мультисетевая разработка (Multisite Development) SITE
|
Фактор |
Очень низкий |
Низкий |
Номинальный |
Высокий |
Очень высокий |
Сверхвысокий |
|
SITE: комму-никации |
Один телефон, почта |
Индивидуаль-ные телефоны, FAX |
Узкополосный e- mail |
Широкопо-лосные электронные коммуника-ции |
Широкополо- сные электронные коммуникации, видеоконференции от случая к случаю |
Интерактивные мультимедиа |
Таблица А. 18. Требуемый график разработки (Required Development Schedule) SCED
|
Фактор |
Очень низкий |
Низкий |
Номинальный |
Высокий |
Очень высокий |
Сверхвысокий |
|
SCED |
75% от номинального срока |
85% |
100% |
130% |
160% |
|
Таблица А. 19. Числовые значения множителей затрат
|
Фактор |
Очень низкий |
Низкий |
Номинальный |
Высокий |
Очень высокий |
Сверхвысокий |
|
RELY |
Легкое беспокойство 0,75 |
Низкая, легко восстанавливаемые потери 0,88 |
Умеренная, легко восстанавливаемые потери 1,00 |
Высокая, финансовые потери 1,15 |
Риск для человеческой жизни 1,39 |
|
|
DATA |
|
байты БД/LOС прогр. <10 0,93 |
10 |
100 |
D/P  |
|
|
CPLX |
0,75 |
0,88 |
1,00 |
1,15 |
1,30 |
1,66 |
|
RUSE |
|
Нет |
На уровне |
На уровне |
На уровне |
На уровне |
|
|
|
0,91 |
проекта |
программы |
семейства |
нескольких |
|
|
|
|
1,00 |
1,14 |
продуктов |
семейств |
|
|
|
|
|
|
1,29 |
продуктов |
|
|
|
|
|
|
|
1,49 |
|
DOCU |
Многие |
Некоторые |
Оптимизирова- |
Избыточны |
Очень |
|
|
|
требования |
требования |
ны |
по |
избыточны |
|
|
|
жизненного |
жизненного |
к требованиям |
отношению к |
по отношению |
|
|
|
цикла |
цикла |
жизненного |
требованиям |
к требованиям |
|
|
|
не учтены |
не учтены |
цикла |
жизненного |
жизненного |
|
|
|
0,89 |
0,95 |
1,00 |
цикла |
цикла |
|
|
|
|
|
|
1,06 |
1,13 |
|
|
TIME |
|
|
Используется |
70% |
85% |
95% |
|
|
|
|
< 50% |
1,11 |
1,31 |
1,67 |
|
|
|
|
возможного |
|
|
|
|
|
|
|
времени |
|
|
|
|
|
|
|
выполнения |
|
|
|
|
|
|
|
1,00 |
|
|
|
|
STOR |
|
|
Используется |
70% |
85% |
95% |
|
|
|
|
< 50% |
1,06 |
1,21 |
1,57 |
|
|
|
|
доступной |
|
|
|
|
|
|
|
памяти |
|
|
|
|
|
|
|
1,00 |
|
|
|
|
PVOL |
|
Значительные |
Значительные— |
Значительные |
Значтельные — |
|
|
|
|
изменения — |
через 6 мес.; |
—через 2 |
через 2 нед. |
|
|
|
|
через 1 год; |
незначительные |
мес.; незначи- |
незначительные |
|
|
|
|
незначитель |
— через |
тельные — |
— через 2 дня |
|
|
|
|
ные — |
2 недели |
через 1 |
1,30 |
|
|
|
|
через 1 мес. |
1,00 |
неделю |
|
|
|
|
|
0,87 |
|
1,15 |
|
|
|
ACAP |
15% |
35% |
55% |
75% |
90% |
|
|
|
1,50 |
1,22 |
1,00 |
0,83 |
0,67 |
|
|
PCAP |
15% |
35% |
55% |
75% |
90% |
|
|
|
1,37 |
1,16 |
1,00 |
0,87 |
0,74 |
|
|
PCON |
48%/год |
24%/год |
12%/год |
6%/год |
3%/год |
|
|
|
1,24 |
1,10 |
1,00 |
0,92 |
0,84 |
|
|
AEXP |
?2 месяцев |
6 месяцев |
1 год |
3 года |
6 лет |
|
|
|
1,22 |
1,10 |
1,00 |
0,89 |
0,81 |
|
|
PEXP |
? 2 месяцев |
6 месяцев |
1 год |
Згода |
6 лет |
|
|
|
1,25 |
1,12 |
1,00 |
0,88 |
0,81 |
|
|
LTEX |
?2 месяцев |
6 месяцев |
1 год |
3 года |
6 лет |
|
|
|
1,22 |
1,10 |
1,00 |
0,91 |
0,84 |
|
|
TOOL |
Редактирование, |
Простая |
Базовые |
Развитые |
Развитые |
|
|
|
кодирование, |
входная, |
утилиты |
утилиты |
утилиты |
|
|
|
отладка |
выходная |
жизненного |
жизненного |
жизненного |
|
|
|
1,24 |
CASE |
цикла, |
цикла, |
цикла, хорошо |
|
|
|
утилита, малая |
умеренная |
умеренная |
интегрированы |
|
|
|
|
интеграция |
интеграция |
интеграция |
с процессами, |
|
|
|
|
|
1,12 |
1,00 |
0,86 |
методами, |
|
|
|
|
|
|
повторным |
|
|
|
|
|
|
|
|
использованием |
|
|
|
|
|
|
|
0,72 |
|
|
SITE |
Один телефон, |
Индивиду- |
Узкополосный |
Широкополое |
Широко- |
Интерактивные |
|
комму- |
почта |
альные |
e-mail |
коммуника- |
полосные |
мультимедиа |
|
ника- |
1,25 |
телефоны, |
1,00 |
ции |
коммуникации, |
0,78 |
|
ции |
FAX |
|
0,92 |
иногда |
||
|
|
|
1,10 |
|
|
видеокон- |
|
|
|
|
|
|
|
ференции |
|
|
|
|
|
|
|
0,84 |
|
|
SCED |
75% |
85% |
100% |
130% |
160% |
|
|
|
от номин. |
1,10 |
1,00 |
1,00 |
1,00 |
|
|
|
1,29 |
|
|
|
|
|
Объединенные циклы
Если каждый из циклов независим от других, то используется техника тестирования простых циклов. При наличии зависимости (например, конечное значение счетчика первого цикла используется как начальное значение счетчика второго цикла) используется методика для вложенных циклов.
Объектно-ориентированное тестирование правильности
При проверке правильности исчезают подробности отношений классов. Как и традиционное подтверждение правильности, подтверждение правильности объектно-ориентированного ПО ориентировано на видимые действия пользователя и распознаваемые пользователем выводы из системы.
Для упрощения разработки тестов используются элементы Use Case, являющиеся частью модели требований. Каждый элемент Use Case задает сценарий, который позволяет обнаруживать ошибки во взаимодействии пользователя с системой.
Для подтверждения правильности может проводиться обычное тестирование «черного ящика».
Полезную для формирования тестов правильности информацию содержат диаграммы взаимодействия, диаграммы деятельности, а также диаграммы схем состояний.
Объекты
Рассмотрим более пристально объекты — конкретные сущности, которые существуют во времени и пространстве.
Общая характеристика CASE-системы Rational Rose
Rational Rose — это CASE-система для визуального моделирования объектно-ориентированных программных продуктов. Визуальное моделирование — процесс графического описания разрабатываемого программного обеспечения. Экран среды Rational Rose показан на рис. 17.1.
В его составе выделим шесть элементов: строку инструментов, панель «инструменты диаграммы», окно диаграммы, браузер, окно спецификации, окно документации.
Как показано на рис. 17.2, кнопки строки инструментов позволяют выполнять стандартные и специальные действия.
Содержание панели инструментов диаграммы меняется в зависимости от активной диаграммы. Окно активной диаграммы имеет синюю строку заголовка (рис. 17.3).
В окне диаграммы можно создавать, отображать и изменять диаграмму на языке UML.
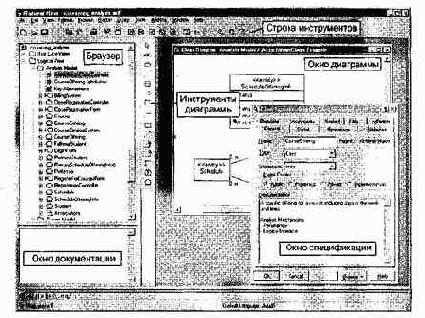
Рис. 17.1. Экран среды Rational Rose

Рис. 17.2. Кнопки строки инструментов Rational Rose
Браузер Rational Rose является инструментом иерархической навигации, позволяющим просматривать названия и пиктограммы, отображающие диаграммы и элементы визуальной модели (рис. 17.4).
Знак плюс (+) рядом с папкой означает, что внутри папки находятся дополнительные элементы. Для «разворачивания» папки надо нажать на знак +. Если папка «развернута», то слева от нее появляется знак минус (-). Для «сворачивания» структуры папки нажимается знак минус.
Окно спецификации позволяет задавать характеристики элемента диаграммы (рис. 17.5).
В поле Documentation этого окна вводится словесное описание данного элемента. Это же описание можно вводить в Окно документации Rational Rose (когда данный элемент выделен в диаграмме).
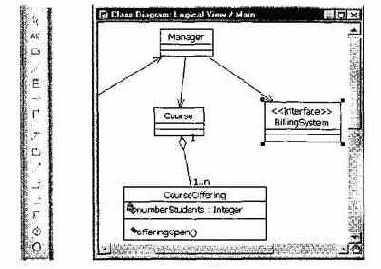
Рис. 17.3. Панель инструментов и окно активной диаграммы

Рис. 17.4. Браузер Rational Rose
В качестве примера работы с Rational Rose рассмотрим построение модели университетской системы для регистрации учебных курсов (классический пример компании Rational), автор которой — Терри Кватрани [57].
Эта система используется:
q профессором — для задания читаемого курса;
q студентом — для выбора изучаемого курса;
q регистратором — для формирования учебного плана и расписания;
q учетной системой — для определения денежных затрат.

Рис. 17.5. Окно спецификации и окно документации Rational Rose
Общая характеристика классов
Класс — описание множества объектов, которые разделяют одинаковые свойства, операции, отношения и семантику (смысл). Любой объект — просто экземпляр класса.
Как показано на рис. 9.9, различают внутреннее представление класса (реализацию) и внешнее представление класса (интерфейс).
Интерфейс объявляет возможности (услуги) класса, но скрывает его структуру и поведение. Иными словами, интерфейс демонстрирует внешнему миру абстракцию класса, его внешний облик. Интерфейс в основном состоит из объявлений всех операций, применимых к экземплярам класса. Он может также включать объявления типов, переменных, констант и исключений, необходимых для полноты данной абстракции.
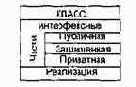
Рис. 9.9. Структуре представления класса
Интерфейс может быть разделен на 3 части:
1) публичную (public), объявления которой доступны всем клиентам;
2) защищенную (protected), объявления которой доступны только самому классу, его подклассам и друзьям;
3) приватную (private), объявления которой доступны только самому классу и его друзьям.
Другом класса называют класс, который имеет доступ ко всем частям этого класса (публичной, защищенной и приватной). Иными словами, от друга у класса нет секретов.
ПРИМЕЧАНИЕ
Другом класса может быть и свободная подпрограмма.
Реализация класса описывает секреты поведения класса. Она включает реализации всех операций, определенных в интерфейсе класса.
Общая характеристика объектов
Объект — это конкретное представление абстракции. Объект обладает индивидуальностью, состоянием и поведением. Структура и поведение подобных объектов определены в их общем классе. Термины «экземпляр класса» и «объект» взаимозаменяемы. На рис. 9.1 приведен пример объекта по имени Стул, имеющего определенный набор свойств и операций.
Индивидуальность — это характеристика объекта, которая отличает его от всех других объектов.
Состояние объекта характеризуется перечнем всех свойств объекта и текущими значениями каждого из этих свойств (рис. 9.1).
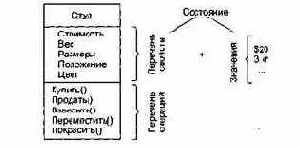
Рис. 9.1. Представление объекта с именем Стул
Объекты не существуют изолированно друг от друга. Они подвергаются воздействию или сами воздействуют на другие объекты.
Поведение характеризует то, как объект воздействует на другие объекты (или подвергается воздействию) в терминах изменений его состояния и передачи сообщений. Поведение объекта является функцией как его состояния, так и выполняемых им операций (Купить, Продать, Взвесить, Переместить, Покрасить). Говорят, что состояние объекта представляет суммарный результат его поведения.
Операция обозначает обслуживание, которое объект предлагает своим клиентам. Возможны пять видов операций клиента над объектом:
1) модификатор (изменяет состояние объекта);
2) селектор (дает доступ к состоянию, но не изменяет его);
3) итератор (доступ к содержанию объекта по частям, в строго определенном порядке);
4) конструктор (создает объект и инициализирует его состояние);
5) деструктор (разрушает объект и освобождает занимаемую им память). Примеры операций приведены в табл. 9.1.
Таблица 9.1. Разновидности операций
| Вид операции | Пример операции | ||
| Модификатор Селектор Итератор Конструктор Деструктор | Пополнеть (кг)
КакойВес ( ) : integer ПоказатьАссортиментТоваров ( ) : string СоздатьРобот (параметры) УничтожитьРобот ( ) |
В чистых объектно- ориентированных языках программирования операции могут объявляться только как методы — элементы классов, экземплярами которых являются объекты. Гибридные языки (C++, Ada 95) позволяют писать операции как свободные подпрограммы (вне классов). Соответствующие примеры показаны на рис. 9.2.
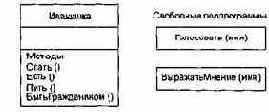
Рис. 9.2. Методы и свободные подпрограммы
В общем случае все методы и свободные подпрограммы, ассоциированные с конкретным объектом, образуют его протокол. Таким образом, протокол определяет оболочку допустимого поведения объекта и поэтому заключает в себе цельное (статическое и динамическое) представление объекта.
Большой протокол полезно разделять на логические группировки поведения. Эти группировки, разделяющие пространство поведения объекта, обозначают роли, которые может играть объект. Принцип выделения ролей иллюстрирует рис. 9.3.
С точки зрения внешней среды важное значение имеет такое понятие, как обязанности объекта. Обязанности означают обязательства объекта обеспечить определенное поведение. Обязанностями объекта являются все виды обслуживания, которые он предлагает клиентам. В мире объект играет определенные роли, выполняя свои обязанности.
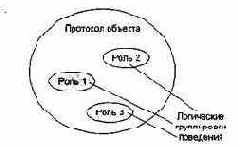
Рис. 9.3. Пространство поведения объекта
В заключение отметим: наличие у объекта внутреннего состояния означает, что порядок выполнения им операций очень важен. Иначе говоря, объект может представляться как независимый автомат. По аналогии с автоматами можно выделять активные и пассивные объекты (рис. 9.4).
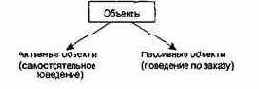
Рис.9.4.
Активные и пассивные объекты
Активный объект имеет собственный канал (поток) управления, пассивный — нет. Активный объект автономен, он может проявлять свое поведение без воздействия со стороны других объектов. Пассивный объект, наоборот, может изменять свое состояние только под воздействием других объектов.
Оценка качества проектирования
Качество проектирования оценивают с помощью объектно-ориентированных метрик, введенных в главе 14.
Этап РАЗВИТИЕ
Качество логического представления архитектуры оценивают по метрикам:
q WMC — взвешенные методы на класс;
q NOC — количество детей;
q DIT — высота дерева наследования;
q NOM — суммарное количество методов, определенных во всех классах системы;
q NC — общее количество классов в системе.
Метрики WMC, NOC вычисляются для каждого класса, кроме того, формируются их средние значения в системе. Метрики DIT, NOM, NC вычисляются для всей системы.
Этап КОНСТРУИРОВАНИЕ
На каждой итерации конструирования продукта вычисляются метрики:
q WMC — взвешенные методы на класс;
q NOC — количество детей;
q СВО — сцепление между классами объектов;
q RFC — отклик для класса;
q LCOM — недостаток связности в методах;
q CS — размер класса;
q NOO — количество операций, переопределяемых подклассом;
q NOA — количество операций, добавленных подклассом;
q SI — индекс специализации;
q OSavg — средний размер операции;
q NPavg — среднее количество параметров на операцию;
q NC — общее количество классов в системе;
q LOC

q DIT — высота дерева наследования;
q NOM — суммарное количество методов в системе.
Метрики WMC, NOC, СВО, RFC, LCOM, CS, NOO, NOA, SI, OSAVG, NPAVG вычисляются для каждого класса, кроме того, формируются их средние значения в системе. Метрики DIT, NOM, NC, LOCS вычисляются для всей системы.
На последней итерации дополнительно вычисляется набор метрик MOOD, предложенный Абреу:
q МНF — фактор закрытости метода;
q AHF — фактор закрытости свойства;
q MIF — фактор наследования метода;
q AIF — фактор наследования свойства;
q POF — фактор полиморфизма;
q СОF — фактор сцепления.
Операции
Общий синтаксис представления операции имеет вид
Видимость Имя (Список Параметров): ВозвращаемыйТип {Характеристики}
Примеры объявления операций:
| записать
+ записать зарегистрировать) и: Имя, ф: Фамилия) балансСчета ( ) : Integer нагревать ( ) (guarded) | Только имя
Видимость и имя Имя и параметры Имя и возвращаемый тип Имя и характеристика |
В сигнатуре операции можно указать ноль или более параметров, форма представления параметра имеет следующий синтаксис:
Направление Имя : Тип = ЗначениеПоУмолчанию
Элемент Направление может принимать одно из следующих значений:
| in
out inout | Входной параметр, не может модифицироваться
Выходной параметр, может модифицироваться для передачи информации в вызывающий объект Входной параметр, может модифицироваться |
Допустимо применение следующих характеристик операций:
| leaf
isQuery sequential guarded concurrent | Конечная операция, операция не может быть полиморфной и не может переопределяться (в цепочке наследования)
Выполнение операции не изменяет состояния объекта В каждый момент времени в объект поступает только один вызов операций. Как следствие, в каждый момент времени выполняется только одна операция объекта. Другими словами, допустим только один поток вызовов (поток управления) Допускается одновременное поступление в объект нескольких вызовов, но в каждый момент времени обрабатывается только один вызов охраняемой операции. Иначе говоря, параллельные потоки управления исполняются последовательно (за счет постановки вызовов в очередь) В объект поступает несколько потоков вызовов операций (из параллельных потоков управления). Разрешается параллельное (и множественное) выполнение операции. Подразумевается, что такие операции являются атомарными |
Операционно-ориентированные метрики
Эта группа метрик ориентирована на оценку операций в классах. Обычно методы имеют тенденцию быть небольшими как по размеру, так и по логической сложности. Тем не менее реальные характеристики операций могут быть полезны для глубокого понимания системы.
Метрика 5: Средний размер операции OSAVG (Average Operation Size)
В качестве индикатора размера может использоваться количество строк программы, однако LOC-оценки приводят к известным проблемам. Альтернативный вариант — «количество сообщений, посланных операцией».
Рост значения метрики означает, что обязанности размещены в классе не очень удачно. Рекомендуемое значение OSAVG
Метрика 6: Сложность операции ОС (Operation Complexity
Сложность операции может вычисляться с помощью стандартных метрик сложности, то есть с помощью LOC- или FP-оценок, метрики цикломатической сложности, метрики Холстеда.
М. Лоренц и Д. Кидд предлагают вычислять ОС суммированием оценок с весовыми коэффициентами, приведенными в табл. 14.5.
Таблица 14.5. Весовые коэффициенты для метрики ОС
| Параметр | Вес | ||
| Вызовы функций API | 5,0 | ||
| Присваивания | 0,5 | ||
| Арифметические операции | 2,0 | ||
| Сообщения с параметрами | 3,0 | ||
| Вложенные выражения | 0,5 | ||
| Параметры | 0,3 | ||
| Простые вызовы | 7,0 | ||
| Временные переменные | 0,5 | ||
| Сообщения без параметров | 1,0 |
Поскольку операция должна быть ограничена конкретной обязанностью, желательно уменьшать ОС.
Рекомендуемое значение ОС
Метрика 7: Среднее количество параметров на операцию NPAVG
(Average Number of Parameters per operation)
Чем больше параметров у операции, тем сложнее сотрудничество между объектами. Поэтому значение NPAVG
должно быть как можно меньшим.
Рекомендуемое значение NPAVG = 0,7.
Описание потоков данных и процессов
Базовые средства диаграммы не обеспечивают полного описания требований к программному изделию. Очевидно, что должны быть описаны стрелки — потоки данных — и преобразователи — процессы. Для этих целей используются словарь требований (данных) и спецификации процессов.
Словарь требований (данных) содержит описания потоков данных и хранилищ данных. Словарь требований является неотъемлемым элементом любой CASE-утилиты автоматизации анализа. Структура словаря зависит от особенностей конкретной CASE-утилиты. Тем не менее можно выделить базисную информацию типового словаря требований.
Большинство словарей содержит следующую информацию.
1. Имя (основное имя элемента данных, хранилища или внешнего объекта).
2. Прозвище (Alias) — другие имена того же объекта.
3. Где и как используется объект — список процессов, которые используют данный элемент, с указанием способа использования (ввод в процесс, вывод из процесса, как внешний объект или как память).
4. Описание содержания — запись для представления содержания.
5. Дополнительная информация — дополнительные сведения о типах данных, допустимых значениях, ограничениях и т. д.
Спецификация процесса — это описание преобразователя. Спецификация поясняет: ввод данных в преобразователь, алгоритм обработки, характеристики производительности преобразователя, формируемые результаты.
Количество спецификаций равно количеству преобразователей диаграммы.
Определение связности модуля
Приведем алгоритм определения уровня связности модуля.
1. Если модуль — единичная проблемно-ориентированная функция, то уровень связности — функциональный; конец алгоритма. В противном случае перейти к пункту 2.
2. Если действия внутри модуля связаны, то перейти к пункту 3. Если действия внутри модуля никак не связаны, то перейти к пункту 6.
3. Если действия внутри модуля связаны данными, то перейти к пункту 4. Если действия внутри модуля связаны потоком управления, перейти к пункту 5.
4. Если порядок действий внутри модуля важен, то уровень связности — информационный. В противном случае уровень связности — коммуникативный. Конец алгоритма.
5. Если порядок действий внутри модуля важен, то уровень связности — процедурный. В противном случае уровень связности — временной. Конец алгоритма.
6. Если действия внутри модуля принадлежат к одной категории, то уровень связности — логический. Если действия внутри модуля не принадлежат к одной категории, то уровень связности — по совпадению. Конец алгоритма.
Возможны более сложные случаи, когда с модулем ассоциируются несколько уровней связности. В этих случаях следует применять одно из двух правил:
q правило параллельной цепи. Если все действия модуля имеют несколько уровней связности, то модулю присваивают самый сильный уровень связности;
q правило последовательной цепи. Если действия в модуле имеют разные уровни связности, то модулю присваивают самый слабый уровень связности.
Например, модуль может содержать некоторые действия, которые связаны процедурно, а также другие действия, связные по совпадению. В этом случае применяют правило последовательной цепи и в целом модуль считают связным по совпадению.
Определение технологии конструирования программного обеспечения
Технология конструирования программного обеспечения (ТКПО) — система инженерных принципов для создания экономичного ПО, которое надежно и эффективно работает в реальных компьютерах [64], [69], [71].
Различают методы, средства и процедуры ТКПО.
Методы обеспечивают решение следующих задач:
q планирование и оценка проекта;
q анализ системных и программных требований;
q проектирование алгоритмов, структур данных и программных структур;
q кодирование;
q тестирование;
q сопровождение.
Средства (утилиты) ТКПО обеспечивают автоматизированную или автоматическую поддержку методов. В целях совместного применения утилиты могут объединяться в системы автоматизированного конструирования ПО. Такие системы принято называть CASE-системами. Аббревиатура CASE расшифровывается как Computer Aided Software Engineering (программная инженерия с компьютерной поддержкой).
Процедуры являются «клеем», который соединяет методы и утилиты так, что они обеспечивают непрерывную технологическую цепочку разработки. Процедуры определяют:
q порядок применения методов и утилит;
q формирование отчетов, форм по соответствующим требованиям;
q контроль, который помогает обеспечивать качество и координировать изменения;
q формирование «вех», по которым руководители оценивают прогресс.
Процесс конструирования программного обеспечения состоит из последовательности шагов, использующих методы, утилиты и процедуры. Эти последовательности шагов часто называют парадигмами ТКПО.
Применение парадигм ТКПО гарантирует систематический, упорядоченный подход к промышленной разработке, использованию и сопровождению ПО. Фактически, парадигмы вносят в процесс создания ПО организующее инженерное начало, необходимость которого трудно переоценить.
Рассмотрим наиболее популярные парадигмы ТКПО.
Организация интерфейса СОМ
Каждый интерфейс объекта СОМ — контракт между этим объектом и его клиентами. Они обязуются: объект — поддерживать операции интерфейса в точном соответствии с его определениями, а клиент — корректно вызывать операции. Для обеспечения контракта надо задать:
q идентификацию каждого интерфейса;
q описание операций интерфейса;
q реализацию интерфейса.
Идентификация интерфейса
У каждого интерфейса СОМ два имени. Простое, символьное имя предназначено для людей, оно не уникально (допускается, чтобы это имя было одинаковым у двух интерфейсов). Другое, сложное имя предназначено для использования программами. Программное имя уникально, это позволяет точно идентифицировать интерфейс.
Принято, чтобы символьные имена СОМ-интерфейсов начинались с буквы I (от Interface). Например, упомянутый нами интерфейс для работы с файлами должен называться IРаботаСФайлами, а интерфейс преобразования их форматов — IПреобразованиеФорматов.
Программное имя любого интерфейса образуется с помощью глобально уникального идентификатора (globally unique identifier — GUID). GUID интерфейса считается идентификатором интерфейса (interface identifier — IID). GUID — это 16-байтовая величина (128-битовое число), генерируемая автоматически.
Уникальность во времени достигается за счет включения в каждый GUID метки времени, указателя момента создания. Уникальность в пространстве обеспечивается цифровыми параметрами компьютера, который использовался для генерации GUID.
Описание интерфейса
Для определения интерфейсов применяют специальный язык — язык описания интерфейсов (Interface Definition Language — IDL). Например, IDL-описание интерфейса для работы с файлами 1РаботаСФайлами имеет вид
[ object.
uuid(E7CDODOO-1827-11CF-9946-444553540000) ]
interface IРаботаСФайлами: IUnknown {
import "unknown.idl"
HRESULT ОткрытьФайп ([in] OLECHAR имя [31]);
HRESULT ЗаписатьФайл ([in] OLECHAR имя [31]);
HRESULT ЗакрытьФайл ([in] OLECHAR имя [31]);
}
Описание интерфейса начинается со слова object, отмечающего, что будут использоваться расширения, добавленные СОМ к оригинальному IDL. Далее записывается программное имя (IID интерфейса), оно начинается с ключевого слова uuid (Universal Unique Identifier — универсально уникальный идентификатор). UUID является синонимом термина GUID.
В третьей строке записывается имя интерфейса — РаботаСФайлами, за ним — двоеточие и имя другого интерфейса — IUnknown. Такая запись означает, что интерфейс РаботаСФайлами наследует все операции, определенные для интерфейса IUnknown, то есть клиент, у которого есть указатель на интерфейс IРаботаСФайлами, может вызывать и операции интерфейса IUnknown. IUnknown является главным интерфейсом для СОМ, все остальные интерфейсы — его наследники.
В четвертой строке указывается оператор import. Поскольку данный интерфейс наследует от IUnknown, может потребоваться IDL-описание для IUnknown. Аргумент оператора import указывает, в каком файле находится нужное описание.
Ниже в описании интерфейса приводятся имена и параметры трех операций — ОткрытьФайл, ЗаписатьФайл и ЗакрытьФайл. Все они возвращают величину типа HRESULT, указывающую корректность обработки вызова. Для каждого параметра в IDL приводится направление передачи (в данном примере in), тип и название.
Считается, что такого описания достаточно для заключения контракта между объектом СОМ и его клиентом.
По правилам СОМ запрещается любое изменение интерфейса (после его публикации). Для реализации изменений нужно вводить новый интерфейс. Такой интерфейс может быть наследником старого интерфейса, но отличен от него и имеет другое уникальное имя.
Значение правила запрета на изменение интерфейса трудно переоценить. Оно — залог стабильности работы в среде, где множество клиентов взаимодействует с множеством СОМ-объектов и где независимая модификация СОМ-объектов — обычное дело. Именно это правило позволяет клиентам старых версий не пострадать при введении новых версий СОМ-объектов.
Новая версия обязана поддерживать и старый СОМ-интерфейс.
Реализация интерфейса
СОМ задает стандартный двоичный формат, который должен реализовать каждый СОМ-объект и для каждого интерфейса. Стандарт гарантирует, что любой клиент может вызывать операции любого объекта, причем независимо от языков программирования, на которых написаны клиент и объект.
Структуру интерфейса IРаботаСФайлами, соответствующую двоичному формату, «поясняет рис. 13.16.
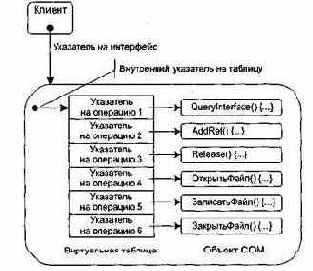
Рис. 13.16. Внутренняя структура интерфейса IРаботаСФайлами
Внешний указатель на интерфейс (указатель клиента) ссылается на внутренний указатель объекта СОМ. Внутренний указатель — это адрес виртуальной таблицы. Виртуальная таблица содержит указатели на все операции интерфейса.
Первые три элемента виртуальной таблицы являются указателями на операции, унаследованные от интерфейса IUnknown. Видно, что на собственные операции интерфейса IРаботаСФайлами указывают 4-, 5- и 6-й элементы виртуальной таблицы. Такая ситуация типична для любого СОМ-интерфейса.
Обработка клиентского вызова выполняется в следующем порядке:
q с помощью указателя на виртуальную таблицу извлекается указатель на требуемую операцию интерфейса;
q указатель на операцию обеспечивает доступ к ее реализации;
q исполнение кода операции обеспечивает требуемую услугу.
Организация свойств и операций
Известно, что пиктограмма класса включает три секции (для имени, для свойств и для операций). Пустота секции не означает, что у класса отсутствуют свойства или операции, просто в данный момент они не показываются. Можно явно определить наличие у класса большего количества свойств или атрибутов. Для этого в конце показанного списка проставляются три точки. Как показано на рис. 11.3, в длинных списках свойств и операций разрешается группировка — каждая группа начинается со своего стереотипа.

Рис. 11.3. Стереотипы для характеристик класса
Ошибки
Люди ааа01 24 168 12,1 365 29 3 bbb02 62 440 27,2 1224 86 5 ссс03 43 314 20,2 1050 64 6
<
Таблица содержит данные о проектах за последние несколько лет. Например, запись о проекте aaa01 показывает: 12 100 строк программы были разработаны за 24 человеко-месяца и стоили $168 000. Кроме того, по проекту aaa01 было разработано 365 страниц документации, а в течение первого года эксплуатации было зарегистрировано 29 ошибок. Разрабатывали проект aaa01 три человека.
На основе таблицы вычисляются размерно-ориентированные метрики производительности и качества (для каждого проекта):




Достоинства размерно-ориентированных метрик:
1) широко распространены;
2) просты и легко вычисляются.
Недостатки размерно-ориентированных метрик:
1) зависимы от языка программирования;
2) требуют исходных данных, которые трудно получить на начальной стадии проекта;
3) не приспособлены к непроцедурным языкам программирования.
Основные понятия и принципы тестирования ПО
Тестирование — процесс выполнения программы с целью обнаружения ошибок. Шаги процесса задаются тестами.
Каждый тест определяет:
q свой набор исходных данных и условий для запуска программы;
q набор ожидаемых результатов работы программы.
Другое название теста — тестовый вариант. Полную проверку программы гарантирует исчерпывающее тестирование. Оно требует проверить все наборы исходных данных, все варианты их обработки и включает большое количество тестовых вариантов. Увы, но исчерпывающее тестирование во многих случаях остается только мечтой — срабатывают ресурсные ограничения (прежде всего, ограничения по времени).
Хорошим считают тестовый вариант с высокой вероятностью обнаружения еще не раскрытой ошибки. Успешным называют тест, который обнаруживает до сих пор не раскрытую ошибку.
Целью проектирования тестовых вариантов является систематическое обнаружение различных классов ошибок при минимальных затратах времени и стоимости.
Важен ответ на вопрос: что может тестирование?
Тестирование обеспечивает:
q обнаружение ошибок;
q демонстрацию соответствия функций программы ее назначению;
q демонстрацию реализации требований к характеристикам программы;
q отображение надежности как индикатора качества программы.
А чего не может тестирование? Тестирование не может показать отсутствия дефектов (оно может показывать только присутствие дефектов). Важно помнить это (скорее печальное) утверждение при проведении тестирования.
Рассмотрим информационные потоки процесса тестирования. Они показаны на рис. 6.1.
Рис. 6.1. Информационные потоки процесса тестирования
На входе процесса тестирования три потока:
q текст программы;
q исходные данные для запуска программы;
q ожидаемые результаты.
Выполняются тесты, все полученные результаты оцениваются. Это значит, что реальные результаты тестов сравниваются с ожидаемыми результатами. Когда обнаруживается несовпадение, фиксируется ошибка — начинается отладка. Процесс отладки непредсказуем по времени. На поиск места дефекта и исправление может потребоваться час, день, месяц. Неопределенность в отладке приводит к большим трудностям в планировании действий.
После сбора и оценивания результатов тестирования начинается отображение качества и надежности ПО. Если регулярно встречаются серьезные ошибки, требующие проектных изменений, то качество и надежность ПО подозрительны, констатируется необходимость усиления тестирования. С другой стороны, если функции ПО реализованы правильно, а обнаруженные ошибки легко исправляются, может быть сделан один из двух выводов:
q качество и надежность ПО удовлетворительны;
q тесты не способны обнаруживать серьезные ошибки.
В конечном счете, если тесты не обнаруживают ошибок, появляется сомнение в том, что тестовые варианты достаточно продуманы и что в ПО нет скрытых ошибок. Такие ошибки будут, в конечном итоге, обнаруживаться пользователями и корректироваться разработчиком на этапе сопровождения (когда стоимость исправления возрастает в 60-100 раз по сравнению с этапом разработки).
Результаты, накопленные в ходе тестирования, могут оцениваться и более формальным способом. Для этого используют модели надежности ПО, выполняющие прогноз надежности по реальным данным об интенсивности ошибок.
Существуют 2 принципа тестирования программы:
q функциональное тестирование (тестирование «черного ящика»);
q структурное тестирование (тестирование «белого ящика»).
Основы компонентной объектной модели
Компонентная объектная модель (СОМ) — фундамент компонентно-ориентированных средств для всего семейства операционных систем Windows. Рассмотрение этой модели является иллюстрацией комплексного подхода к созданию и использованию компонентного программного обеспечения [5].
СОМ определяет стандартный механизм, с помощью которого одна часть программного обеспечения предоставляет свои услуги другой части. Общая архитектура предоставления услуг в библиотеках, приложениях, системном и сетевом программном обеспечении позволяет СОМ изменить подход к созданию программ.
СОМ устанавливает понятия и правила, необходимые для определения объектов и интерфейсов; кроме того, в ее состав входят программы, реализующие ключевые функции.
В СОМ любая часть ПО реализует свои услуги с помощью объектов СОМ. Каждый объект СОМ поддерживает несколько интерфейсов. Клиенты могут получить доступ к услугам объекта СОМ только через вызовы операций его интерфейсов — у них нет непосредственного доступа к данным объекта.
Представим объект СОМ с интерфейсом РаботаСФайлами. Пусть в этот интерфейс входят операции ОткрытьФайл, ЗаписатьФайл и ЗакрытьФайл. Если разработчик захочет ввести в объект СОМ поддержку преобразования форматов, то объекту потребуется еще один интерфейс ПреобразованиеФорматов, возможно, с единственной операцией ПреобразоватьФормат. Операции каждого из интерфейсов сообща предоставляют связанные друг с другом услуги: либо работу с файлами, либо преобразование их форматов.
Как показано на рис. 13.14, объект СОМ всегда реализуется внутри некоторого сервера. Сервер может быть либо динамически подключаемой библиотекой (DLL), подгружаемой во время работы приложения, либо отдельным самостоятельным процессом (ЕХЕ). Отметим, что здесь мы не будем применять графику языка UML, а воспользуемся принятыми в СОМ обозначениями.
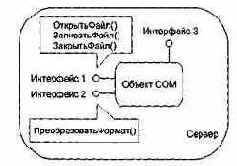
Рис. 13.14. Организация объекта СОМ
Для вызова операции интерфейса клиент объекта СОМ должен получить указатель на его интерфейс. Клиенту требуется отдельный указатель для каждого интерфейса, операции которого он намерен вызывать.
Например, как показано на рис. 13.15, клиенту нашего объекта СОМ нужен один указатель интерфейса для вызова операций интерфейса РаботаСФайлами, а другой — для вызова операций интерфейса ПреобразованиеФорматов.
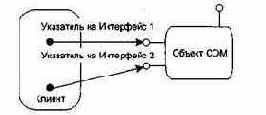
Рис. 13.15. Доступ клиента к интерфейсам объекта СОМ
Получив указатель на нужный интерфейс, клиент может использовать услуги объекта, вызывая операции этого интерфейса. С точки зрения программиста, вызов операции аналогичен вызову локальной процедуры или функции. Но на самом деле исполняемый при этом код может быть частью или библиотеки, или отдельного процесса, или операционной системы (он даже может располагаться на другом компьютере).
Благодаря СОМ клиентам нет нужды учитывать эти отличия — доступ ко всему осуществляется единообразно. Другими словами, в СОМ для доступа к услугам, предоставляемым любыми типами ПО, используется одна общая модель.
Особенности этапа проектирования
Проектирование — итерационный процесс, при помощи которого требования к ПС транслируются в инженерные представления ПС. Вначале эти представления дают только концептуальную информацию (на высоком уровне абстракции), последующие уточнения приводят к формам, которые близки к текстам на языках программирования.
Обычно в проектировании выделяют две ступени: предварительное проектирование и детальное проектирование. Предварительное проектирование формирует абстракции архитектурного уровня, детальное проектирование уточняет эти абстракции, добавляет подробности алгоритмического уровня. Кроме того, во многих случаях выделяют интерфейсное проектирование, цель которого — сформировать графический интерфейс пользователя (GUI). Схема информационных связей процесса проектирования приведена на рис. 4.2.
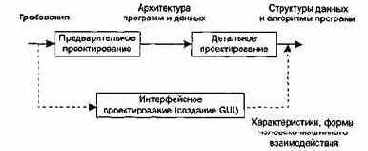
Рис. 4.2. Информационные связи процесса проектирования
Предварительное проектирование обеспечивает:
q идентификацию подсистем;
q определение основных принципов управления подсистемами, взаимодействия подсистем.
Предварительное проектирование включает три типа деятельности:
1. Структурирование системы. Система структурируется на несколько подсистем, где под подсистемой понимается независимый программный компонент. Определяются взаимодействия подсистем.
2. Моделирование управления. Определяется модель связей управления между частями системы.
3. Декомпозиция подсистем на модули. Каждая подсистема разбивается на модули. Определяются типы модулей и межмодульные соединения.
Рассмотрим вопросы структурирования, моделирования и декомпозиции более подробно.
Особенности процесса синтеза программных систем
Известно, что технологический цикл конструирования программной системы (ПС) включает три процесса — анализ, синтез и сопровождение.
В ходе анализа ищется ответ на вопрос: «Что должна делать будущая система?». Именно на этой стадии закладывается фундамент успеха всего проекта. Известно множество неудачных реализаций из-за неполноты и неточностей в определении требований к системе.
В процессе синтеза формируется ответ на вопрос: «Каким образом система будет реализовывать предъявляемые к ней требования?». Выделяют три этапа синтеза: проектирование ПС, кодирование ПС, тестирование ПС (рис. 4.1).
Рассмотрим информационные потоки процесса синтеза.
Этап проектирования питают требования к ПС, представленные информационной, функциональной и поведенческой моделями анализа. Иными словами, модели анализа поставляют этапу проектирования исходные сведения для работы. Информационная модель описывает информацию, которую, по мнению заказчика, должна обрабатывать ПС. Функциональная модель определяет перечень функций обработки. Поведенческая модель фиксирует желаемую динамику системы (режимы ее работы). На выходе этапа проектирования — разработка данных, разработка архитектуры и процедурная разработка ПС.
Разработка данных — это результат преобразования информационной модели анализа в структуры данных, которые потребуются для реализации программной системы.
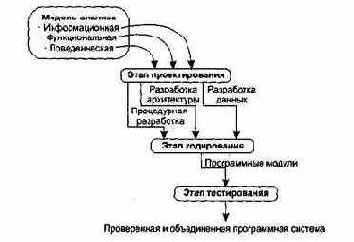
Рис. 4.1. Информационные потоки процесса синтеза ПС
Разработка архитектуры выделяет основные структурные компоненты и фиксирует связи между ними.
Процедурная разработка описывает последовательность действий в структурных компонентах, то есть определяет их содержание.
Далее создаются тексты программных модулей, проводится тестирование для объединения и проверки ПС. На проектирование, кодирование и тестирование приходится более 75% стоимости конструирования ПС. Принятые здесь решения оказывают решающее воздействие на успех реализации ПС и легкость, с которой ПС будет сопровождаться.
Следует отметить, что решения, принимаемые в ходе проектирования, делают его стержневым этапом процесса синтеза. Важность проектирования можно определить одним словом — качество. Проектирование — этап, на котором «выращивается» качество разработки ПС. Справедлива следующая аксиома разработки: может быть плохая ПС при хорошем проектировании, но не может быть хорошей ПС при плохом проектировании. Проектирование обеспечивает нас такими представлениями ПС, качество которых можно оценить. Проектирование — единственный путь, обеспечивающий правильную трансляцию требований заказчика в конечный программный продукт.
Особенности тестирования «белого ящика»
Обычно тестирование «белого ящика» основано на анализе управляющей структуры программы [2], [13]. Программа считается полностью проверенной, если проведено исчерпывающее тестирование маршрутов (путей) ее графа управления.
В этом случае формируются тестовые варианты, в которых:
q гарантируется проверка всех независимых маршрутов программы;
q проходятся ветви True, False для всех логических решений;
q выполняются все циклы (в пределах их границ и диапазонов);
q анализируется правильность внутренних структур данных.
Недостатки тестирования «белого ящика»:
1. Количество независимых маршрутов может быть очень велико. Например, если цикл в программе выполняется k раз, а внутри цикла имеется п ветвлений, то количество маршрутов вычисляется по формуле

При п = 5 и k = 20 количество маршрутов т = 1014. Примем, что на разработку, выполнение и оценку теста по одному маршруту расходуется 1 мс. Тогда при работе 24 часа в сутки 365 дней в году на тестирование уйдет 3170 лет.
2. Исчерпывающее тестирование маршрутов не гарантирует соответствия программы исходным требованиям к ней.
3. В программе могут быть пропущены некоторые маршруты.
4. Нельзя обнаружить ошибки, появление которых зависит от обрабатываемых данных (это ошибки, обусловленные выражениями типа if abs (a-b) < eps..., if(a+b+c)/3=a...).
Достоинства тестирования «белого ящика» связаны с тем, что принцип «белого ящика» позволяет учесть особенности программных ошибок:
1. Количество ошибок минимально в «центре» и максимально на «периферии» программы.
2. Предварительные предположения о вероятности потока управления или данных в программе часто бывают некорректны. В результате типовым может стать маршрут, модель вычислений по которому проработана слабо.
3. При записи алгоритма ПО в виде текста на языке программирования возможно внесение типовых ошибок трансляции (синтаксических и семантических).
4. Некоторые результаты в программе зависят не от исходных данных, а от внутренних состояний программы.
Каждая из этих причин является аргументом для проведения тестирования по принципу «белого ящика». Тесты «черного ящика» не смогут реагировать на ошибки таких типов.
Особенности тестирования «черного ящика»
Тестирование «черного ящика» (функциональное тестирование) позволяет получить комбинации входных данных, обеспечивающих полную проверку всех функциональных требований к программе [14]. Программное изделие здесь рассматривается как «черный ящик», чье поведение можно определить только исследованием его входов и соответствующих выходов. При таком подходе желательно иметь:
q набор, образуемый такими входными данными, которые приводят к аномалиям поведения программы (назовем его IT);
q набор, образуемый такими выходными данными, которые демонстрируют дефекты программы (назовем его ОТ).
Как показано на рис. 7.1, любой способ тестирования «черного ящика» должен:
q выявить такие входные данные, которые с высокой вероятностью принадлежат набору IT;
q сформулировать такие ожидаемые результаты, которые с высокой вероятностью являются элементами набора ОТ.
Во многих случаях определение таких тестовых вариантов основывается на предыдущем опыте инженеров тестирования. Они используют свое знание и понимание области определения для идентификации тестовых вариантов, которые эффективно обнаруживают дефекты. Тем не менее систематический подход к выявлению тестовых данных, обсуждаемый в данной главе, может использоваться как полезное дополнение к эвристическому знанию.
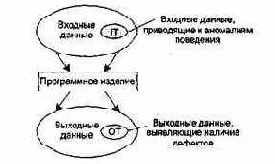
Рис. 7.1. Тестирование «черного ящика»
Принцип «черного ящика» не альтернативен принципу «белого ящика». Скорее это дополняющий подход, который обнаруживает другой класс ошибок.
Тестирование «черного ящика» обеспечивает поиск следующих категорий ошибок:
1) некорректных или отсутствующих функций;
2) ошибок интерфейса;
3) ошибок во внешних структурах данных или в доступе к внешней базе данных;
4) ошибок характеристик (необходимая емкость памяти и т. д.);
5) ошибок инициализации и завершения.
Подобные категории ошибок способами «белого ящика» не выявляются.
В отличие от тестирования «белого ящика», которое выполняется на ранней стадии процесса тестирования, тестирование «черного ящика» применяют на поздних стадиях тестирования. При тестировании «черного ящика» пренебрегают управляющей структурой программы. Здесь внимание концентрируется на информационной области определения программной системы.
Техника «черного ящика» ориентирована на решение следующих задач:
q сокращение необходимого количества тестовых вариантов (из-за проверки не статических, а динамических аспектов системы);
q выявление классов ошибок, а не отдельных ошибок.
Особенности тестирования объектно-ориентированных «модулей»
При рассмотрении объектно-ориентированного ПО меняется понятие модуля. Наименьшим тестируемым элементом теперь является класс (объект). Класс содержит несколько операций и свойств. Поэтому сильно изменяется содержание тестирования модулей.
В данном случае нельзя тестировать отдельную операцию изолированно, как это принято в стандартном подходе к тестированию модулей. Любую операцию приходится рассматривать как часть класса.
Например, представим иерархию классов, в которой операция ОР() определена для суперкласса и наследуется несколькими подклассами. Каждый подкласс использует операцию ОР(), но она применяется в контексте его приватных свойств и операций. Этот контекст меняется, поэтому операцию ОР() надо тестировать в контексте каждого подкласса. Таким образом, изолированное тестирование операции ОР(), являющееся традиционным подходом в тестировании модулей, не имеет смысла в объектно-ориентированной среде.
Выводы:
q тестированию модулей традиционного ПО соответствует тестирование классов объектно-ориентированного ПО;
q тестирование традиционных модулей ориентировано на поток управления внутри модуля и поток данных через интерфейс модуля;
q тестирование классов ориентировано на операции, инкапсулированные в классе, и состояния в пространстве поведения класса.
От издательства
Ваши замечания, предложения, вопросы вы можете отправить по адресу электронной почты comp@piter.com (издательство «Питер», компьютерная редакция). Мы будем рады узнать ваше мнение.
Все исходные тексты, приведенные в книге, вы можете найти по адресу http:// www.piter.com/download.
На web-сайте издательства www.piter.com вы найдете подробную информацию о наших книгах.
Отношения в диаграммах классов
Отношения, используемые в диаграммах классов, показаны на рис. 11.5.
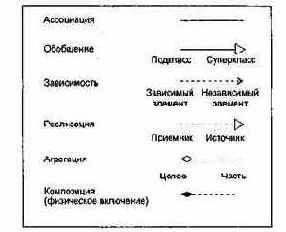
Рис. 11.5. Отношения в диаграммах классов
Ассоциации отображают структурные отношения между экземплярами классов, то есть соединения между объектами. Каждая ассоциация может иметь метку — имя, которое описывает природу отношения. Как показано на рис. 11.6, имени можно придать направление — достаточно добавить треугольник направления, который указывает направление, заданное для чтения имени.

Рис. 11.6. Имена ассоциаций
Когда класс участвует в ассоциации, он играет в этом отношении определенную роль. Как показано на рис. 11.7, роль определяет, каким представляется класс на одном конце ассоциации для класса на противоположном конце ассоциации.

Рис. 11.7. Роли
Один и тот же класс в разных ассоциациях может играть разные роли. Часто важно знать, как много объектов может соединяться через экземпляр ассоциации. Это количество называется ложностью роли в ассоциации, записывается в виде выражения, задающего диапазон величин или одну величину (рис. 11.8).
Запись мощности на одном конце ассоциации определяет количество объектов, соединяемых с каждым объектом на противоположном конце ассоциации. Например, можно задать следующие варианты мощности:
q 5 — точно пять;
q * — неограниченное количество;
q 0..* — ноль или более;
q 1..* — один или более;
q 3..7 — определенный диапазон;
q 1..3, 7 — определенный диапазон или число.

Рис. 11. 8. Мощность
Достаточно часто возникает следующая проблема — как для объекта на одном конце ассоциации выделить набор объектов на противоположном конце? Например, рассмотрим взаимодействие между банком и клиентом — вкладчиком. Как показано на рис. 11.9, мы устанавливаем ассоциацию между классом Банк и классом Клиент. В контексте Банка мы имеем НомерСчета, который позволяет идентифицировать конкретного Клиента.
В этом смысле НомерСчета является атрибутом ассоциации. Он не является характеристикой Клиента, так как Клиенту не обязательно знать служебные параметры его счета. Теперь для данного экземпляра Банка и данного значения НомераСчета можно выявить ноль или один экземпляр Клиента. В UML для решения этой проблемы вводится квалификатор — атрибут ассоциации, чьи значения выделяют набор объектов, связанных с объектом через ассоциацию. Квалификатор изображается маленьким прямоугольником, присоединенным к концу ассоциации. В прямоугольник вписывается свойство — атрибут ассоциации.
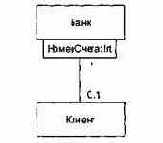
Рис. 11.9. Квалификация
Кроме того, роли в ассоциациях могут иметь пометки видимости. Например, на рис. 11.10 показаны ассоциации между Начальником и Женщиной, а также между Женщиной и Загадкой. Для данного экземпляра Начальника можно определить соответствующие экземпляры Женщины. С другой стороны, Загадка приватна для Женщины, поэтому она недоступна извне. Как показано на рисунке, из объекта Начальника можно перемещаться к экземплярам Женщины (и наоборот), но нельзя видеть экземпляры Загадки для объектов Женщины.

Рис. 11.10. Видимость
На конце ассоциации можно задать три уровня видимости, добавляя символ видимости к имени роли:
q по умолчанию для роли задается публичная видимость;
q приватная видимость указывает, что объекты на данном конце недоступны любым объектам вне ассоциации;
q защищенная видимость (protected) указывает, что объекты на данном конце недоступны любым объектам вне ассоциации, за исключением потомков того класса, который указан на противоположном конце ассоциации.
В языке UML ассоциации могут иметь свойства. Как показано на рис, 11.11, такие возможности отображаются с помощью классов-ассоциаций. Эти классы присоединяются к линии ассоциации пунктирной линией и рассматриваются как классы со свойствами ассоциаций или как ассоциации со свойствами классов.

Рис. 11.11. Класс-ассоциация
Свойства класса-ассоциации характеризуют не один, а пару объектов, в данном случае — пару экземпляров, Профессор и Университет.
Отношения агрегации и композиции в языке UML считаются разновидностями ассоциации, применяемыми для отображения структурных отношений между «целым» (агрегатом) и его «частями». Агрегация показывает отношение по ссылке (в агрегат включены только указатели на части), композиция — отношение физического включения (в агрегат включены сами части).
Зависимость является отношением использования между клиентом (зависимым элементом) и поставщиком (независимым элементом). Обычно операции клиента:
q вызывают операции поставщика;
q имеют сигнатуры, в которых возвращаемое значение или аргументы принадлежат классу поставщика.
Например, на рис. 11.12 показана зависимость класса Заказ от класса Книга, так как Книга используется в операциях проверкаДоступности, добавить и удалить класса Заказ.
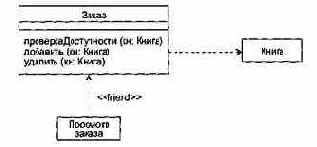
Рис. 11.12. Отношения зависимости
На этом рисунке изображена еще одна зависимость, которая показывает, что класс Просмотр Заказа использует класс Заказ. Причем Заказ ничего не знает о Просмотре Заказа. Данная зависимость помечена стереотипом «friend», который расширяет простую зависимость, определенную в языке. Отметим, что отношение зависимости очень разнообразно — в настоящее время язык предусматривает 17 разновидностей зависимости, различаемых по стереотипам.
Обобщение — отношение между общим предметом (суперклассом) и специализированной разновидностью этого предмета (подклассом). Подкласс может иметь одного родителя (один суперкласс) или несколько родителей (несколько суперклассов). Во втором случае говорят о множественном наследовании.
Как показано на рис. 11.13, подкласс Летающий шкаф является наследником суперклассов Летающий предмет и Хранилище вещей. Этому подклассу достаются в наследство все свойства и операции двух классов-родителей.
Множественное наследование достаточно сложно и коварно, имеет много «подводных камней». Например, подкласс Яблочный_Пирог не следует производить от суперклассов Пирог и Яблоко. Это типичное неправильное использование множественного наследования: потомок наследует все свойства от его родителя, хотя обычно не все свойства применимы к потомку. Очевидно, что Яблочный_Пирог является Пирогом, но не является Яблоком, так как пироги не растут на деревьях.

Рис. 11.13. Множественное наследование
Еще более сложные проблемы возникают при наследовании от двух классов, имеющих общего родителя. Говорят, что в результате образуется ромбовидная решетка наследования (рис. 11.14).

Рис. 11.14. Ромбовидная решетка наследования
Полагаем, что в подклассах Официант и Певец операция работать суперкласса Работник переопределена в соответствии с обязанностью подкласса (работа официанта состоит в обслуживании едой, а певца — в пении). Возникает вопрос — какую версию операции работать унаследует Поющий_официант? А что делать со свойствами, доставшимися в наследство от родителей и общего прародителя? Хотим ли мы иметь несколько копий свойства или только одну?
Все эти проблемы увеличивают сложность реализации, приводят к введению многочисленных правил для обработки особых случаев.
Реализация — семантическое отношение между классами, в котором класс-приемник выполняет реализацию операций интерфейса класса-источника. Например, на рис. 11.15 показано, что класс Каталог должен реализовать интерфейс Обработчик каталога, то есть Обработчик каталога рассматривается как источник, а Каталог — как приемник.
Рис. 11.15. Реализация интерфейса
Интерфейс Обработчик каталога позволяет клиентам взаимодействовать с объектами класса Каталог без знания той дисциплины доступа, которая здесь реализована (LIFO — последний вошел, первый вышел; FIFO — первый вошел, первый вышел и т. д.).
Отношения в диаграммах Use Case
Между актером и элементом Use Case возможен только один вид отношения — ассоциация, отображающая их взаимодействие (рис. 12.28). Как и любая другая ассоциация, она может быть помечена именем, ролями, мощностью.

Рис. 12.28. Отношение ассоциации
Между актерами допустимо отношение обобщения (рис. 12.29), означающее, что экземпляр потомка может взаимодействовать с такими же разновидностями экземпляров элементов Use Case, что и экземпляр родителя.
Рис. 12.29. Отношение обобщения между актерами
Между элементами Use Case определены отношение обобщения и две разновидности отношения зависимости — включения и расширения.
Отношение обобщения (рис. 12.30) фиксирует, что потомок наследует поведение родителя. Кроме того, потомок может дополнить или переопределить поведение родителя. Элемент Use Case, являющийся потомком, может замещать элемент Use Case, являющийся родителем, в любом месте диаграммы.

Рис. 12.30. Отношение обобщения между элементами Use Case
Отношение включения (рис. 12.31) между элементами Use Case означает, что базовый элемент Use Case явно включает поведение другого элемента Use Case в точке, которая определена в базе. Включаемый элемент Use Case никогда не используется самостоятельно — его конкретизация может быть только частью другого, большего элемента Use Case. Отношение включения является примером отношения делегации. При этом в отдельное место (включаемый элемент Use Case) помещается определенный набор обязанностей системы. Далее остальные части системы могут агрегировать в себя эти обязанности (при необходимости).

Рис. 12.31. Отношение включения между элементами Use Case
Отношение расширения (рис. 12.32) между элементами Use Case означает, что базовый элемент Use Case неявно включает поведение другого элемента Use Case в точке, которая определяется косвенно расширяющим элементом Use Case. Базовый элемент Use Case может быть автономен, но при определенных условиях его поведение может расширяться поведением из другого элемента Use Case.
Базовый элемент Use Case может расширяться только в определенных точках — точках расширения. Отношение расширения применяется для моделирования выбираемого поведения системы. Таким способом можно отделить обязательное поведение от необязательного поведения. Например, можно использовать отношение расширения для отдельного подпотока, который выполняется только при определенных условиях, находящихся вне поля зрения базового элемента Use Case. Наконец, можно моделировать отдельные потоки, вставка которых в определенную точку управляется актером.
Рис. 12.32. Отношение расширения между элементами Use Case
Рис. 12.33. Простейшая диаграмма Use Case для банка

Рис. 12.34. Диаграмма Use Case для обслуживания заказчика
Пример простейшей диаграммы Use Case, в которой использованы отношения включения и расширения, приведен на рис. 12.33.
Как показано на рис. 12.34, внутри элемента Use Case может быть дополнительная секция с заголовком Extention points. В этой области перечисляются точки расширения. В указанную здесь точку дополнительные запросы вставляется последовательность действий от расширяющего элемента Use Case Запрос каталога. Для справки отмечено, что точка расширения размещена после действий, обеспечивающих создание заказа. На этом же рисунке отображены отношения наследования между элементами Use Case. Видно, что элементы Use Case Оплата наличными и Оплата в кредит наследуют поведение элемента Use Case Произвести оплату и являются его специализациями.
Отношения в UML
В UML имеются четыре разновидности отношений:
1) зависимость;
2) ассоциация;
3) обобщение;
4) реализация.
Эти отношения являются базовыми строительными блоками отношений. Они используются при написании моделей.
1. Зависимость — семантическое отношение между двумя предметами, в котором изменение в одном предмете (независимом предмете) может влиять на семантику другого предмета (зависимого предмета). Как показано на рис. 10.13, зависимость изображается в виде пунктирной линии, возможно направленной на независимый предмет и иногда имеющей метку.
Рис. 10.13. Зависимости
2. Ассоциация — структурное отношение, которое описывает набор связей, являющихся соединением между объектами. Агрегация — это специальная разновидность ассоциации, представляющая структурное отношение между целым и его частями. Как показано на рис. 10.14, ассоциация изображается в виде сплошной линии, возможно направленной, иногда имеющей метку и часто включающей другие «украшения», такие как мощность и имена ролей.

Рис. 10.14. Ассоциации
3. Обобщение — отношение специализации/обобщения, в котором объекты специализированного элемента (потомка, ребенка) могут заменять объекты обобщенного элемента (предка, родителя). Иначе говоря, потомок разделяет структуру и поведение родителя. Как показано на рис. 10.15, обобщение изображается в виде сплошной стрелки с полым наконечником, указывающим на родителя.

Рис. 10.15. Обобщения
4. Реализация — семантическое отношение между классификаторами, где один классификатор определяет контракт, который другой классификатор обязуется выполнять (к классификаторам относят классы, интерфейсы, компоненты, элементы Use Case, кооперации). Отношения реализации применяют в двух случаях: между интерфейсами и классами (или компонентами), реализующими их; между элементами Use Case и кооперациями, которые реализуют их. Как показано на рис. 10.16, реализация изображается как нечто среднее между обобщением и зависимостью.

Рис. 10.16. Реализации
Паттерн Команда
Паттерн Команда (Command) выполняет преобразование запроса в объект, обеспечивая:
q параметризацию клиентов с различными запросами;
q постановку запросов в очередь и их регистрацию;
q поддержку отмены операций.
Проблема. Достаточно часто нужно посылать запрос, не зная, выполнение какой конкретной операции запрошено и кто является получателем запроса. В этих случаях следует отделить объект, инициирующий запрос, от объекта, способного выполнить запрос. В результате обеспечивается высокая гибкость разработки пользовательского интерфейса — можно связывать различные пункты меню с определенной функцией, динамически подменять команды и т. д. Паттерн Команда применяется в следующих случаях:
q объекты параметризируются действием. В процедурных языках параметризация осуществляется при помощи функции обратного вызова, которая регистрируется для последующего вызова. Паттерн Команда предлагает объектно-ориентированную замену функций обратного вызова;
q необходимо обеспечить отмену операций. Это возможно благодаря хранению истории выполнения операций;
q необходимо регистрировать изменения состояния для восстановления системы в случае аварийного отказа;
q необходимо создание сложных операций, которые строятся на основе примитивных операций.
Решение. Основным элементом решения является абстрактный класс Команда, обеспечивающий одну абстрактную операцию Выполнять(). Конкретные подклассы этого класса реализуют операцию Выполнять(). Они задают пару получатель-действие. Получатель запоминается в экземплярной переменной подкласса. Запрос получателю посылается в ходе исполнения конкретной операции Выполнять().
Структурная составляющая паттерна Команда показана на рис. 12.54. Классы этой структуры имеют следующие обязанности:
q Команда объявляет интерфейс для выполнения операции;
q КонкрКоманда определяет связь между экземпляром класса Получатель и действием, реализует Выполнять(), вызывая нужную операцию получателя;
q Клиент создает объект класса КонкрКоманда и устанавливает его получателя;
q Инициатор просит команду выполнить запрос;
q Получатель умеет выполнять запрашиваемые операции.
Рис. 12.54. Структурная составляющая паттерна Команда
В качестве конкретной команды могут выступать команда Открыть, команда Вставить. Инициатором может быть Пункт Меню, а получателем — Документ.
Объекты этого паттерна осуществляют следующие взаимодействия:
q клиент создает объект класса КонкрКоманда и задает его получателя;
q объект класса Инициатор сохраняет объект класса КонкрКоманда;
q инициатор вызывает операцию Выполнять() объекта класса КонкрКоманда;
q объект класса КонкрКоманда вызывает операцию своего получателя для исполнения запроса.
Результаты. Применение паттерна Команда приводит к следующему:
q объект, запрашивающий операцию, отделяется от объекта, умеющего выполнять запрос;
q объекты-команды являются полноценными объектами. Их можно использовать и расширять обычным способом;
q из простых команд легко компонуются составные команды;
q легко добавляются новые команды (изменять существующие классы при этом не требуется).
Обозначение паттерна Команда приведено на рис. 12.55, где показано, что у него четыре параметра настройки — клиент, команда, инициатор и получатель.
Рис. 12.55. Обозначение паттерна Команда
Настройку паттерна на приложение с графическим меню иллюстрирует рис. 12.56.
Рис. 12.56. Настройка паттерна Команда
Очевидно, что в получаемой кооперации конкретный класс Редактор играет роль клиента, классы КомандаОткрыть и КомандаВставить становятся классами Конкретных Команд (и подклассами абстрактного класса Команда), класс ПунктМеню замещает класс Инициатор паттерна, а конкретный класс Документ замещает класс Получатель паттерна.
Паттерн Компоновщик
Паттерн Компоновщик (Composite) обеспечивает представление иерархий часть-целое, объединяя объекты в древовидные структуры.
Проблема. Очень часто возникает необходимость создавать маленькие компоненты (примитивы), объединять их в более крупные компоненты (контейнеры), более крупные компоненты соединять в большие компоненты, большие компоненты — в огромные и т. д. При этом клиентам приходится различать компоненты-примитивы и компоненты-контейнеры, работать с ними по-разному. Это усложняет приложение. Паттерн Компоновщик позволяет ликвидировать это различие, его можно применять в следующих случаях:
q необходимо построить иерархию объектов вида часть-целое;
q нужно унифицировать использование как составных, так и индивидуальных объектов.
Решение. Ключевым элементом решения является абстрактный класс Компонент, который является одновременно и примитивом, и контейнером. В нем объявлены:
q абстрактная операция примитива Работать( );
q абстрактные операции контейнера — управления примитивами-потомками Добавить(Компонент) и Удалить(Компонент), а также доступа к потомку Получить-Потомка().
Структурная составляющая паттерна Компоновщик представлена на рис. 12.51.
Рис. 12.51. Структурная составляющая паттерна Компоновщик
Из рисунка видно, что с помощью паттерна организуется рекурсивная композиция.
Класс Компонент служит простым элементом дерева, класс Компоновщик является рекурсивным элементом, а класс Лист — конечным элементом дерева. Класс Компонент служит родителем классов Лист и Компоновщик. Отметим, что класс Компоновщик является агрегатом составных частей — экземпляров класса Компонент (таким образом задается рекурсия).
Клиенты используют интерфейс класса Компонент для взаимодействия с объектами дерева. Если получателем запроса клиента является объект-лист, то он и обрабатывает запрос. Если же получателем является составной объект-компоновщик, то он перенаправляет запрос своим потомкам, возможно выполняя дополнительные действия до или после перенаправления.
Результаты. Паттерн определяет иерархии, состоящие из классов-примитивов и классов-контейнеров, облегчает добавление новых разновидностей компонентов. Он упрощает организацию клиентов (клиент не должен учитывать специфику адресуемого объекта). Недостаток применения паттерна — трудность в наложении ограничений на объекты, которые можно включать в композицию.
Обозначение паттерна Компоновщик приведено на рис. 12.52, где показано, что у него три параметра настройки — компонент, компоновщик и лист.
Настройку паттерна на графическое приложение иллюстрирует рис. 12.53.

Рис. 12.52. Обозначение паттерна Компоновщик
Рис. 12.53. Настройка паттерна Компоновщик
В этом случае основной операцией приложения становится операция Рисовать(). Подразумевается, что такая операция входит в состав каждого из подключаемых классов, то есть классов Рисунок, Прямоугольник и Графический элемент. Операции Рисовать() должны заместить операции Работать() в классах паттерна.
Паттерн Наблюдатель
Паттерн Наблюдатель (Observer) задает между объектами такую зависимость «один-ко-многим», при которой изменение состояния одного объекта приводит к оповещению и автоматическому обновлению всех зависящих от него объектов.
Проблема. При разбиении системы на набор совместно работающих объектов появляется необходимость поддерживать их согласованное состояние. При этом желательно минимизировать сцепление, так как высокое сцепление уменьшает возможности повторного использования. Например, во многих случаях требуется отображение данных состояния в различных графических формах и форматах. При этом объекту, формирующему состояние, не нужно знать о формах его отображения — отсутствие такого интереса благотворно влияет на необходимое сцепление. Паттерн Наблюдатель можно применять в следующих случаях:
q когда необходимо организовать непрямое взаимодействие объектов уровня логики приложения с интерфейсом пользователя. Таким образом достигается низкое сцепление между уровнями;
q когда при изменении состояния одного объекта должны изменить свое состояние все зависимые объекты, причем количество зависимых объектов заранее неизвестно;
q когда один объект должен рассылать сообщения другим объектам, не делая о них никаких предположений. За счет этого образуется низкое сцепление между объектами.
Решение. Принцип решения иллюстрирует рис. 12.46. Ключевыми элементами решения являются субъект и наблюдатель. У субъекта может быть любое количество зависимых от него наблюдателей. Когда происходят изменения в состоянии субъекта, наблюдатели автоматически об этом уведомляются. Получив уведомление, наблюдатель опрашивает субъекта, синхронизуя с ним свое отображение состояния.

Рис. 12.46. Различные графические отображения состояния субъекта
Такое взаимодействие между элементами соответствует схеме издатель-подписчик. Издатель рассылает сообщения об изменении своего состояния, не имея никакой информации о том, какие объекты являются подписчиками.
На получение таких уведомлений может подписаться любое количество наблюдателей.
Структурная составляющая паттерна Наблюдатель представлена на рис. 12.47. В ней определены два абстрактных класса, Субъект и Наблюдатель. Кроме того, здесь показаны два конкретных класса, КонкрСубъект и КонкрНаблюдатель, которые наследуют свойства и операции абстрактных классов. Они подключаются к паттерну в процессе его настройки. Состояние формируется Конкретным субъектом, который унаследовал от Субъекта операции, позволяющие ему добавлять и удалять Конкретных наблюдателей, а также уведомлять их об изменении своего состояния. Конкретный наблюдатель автоматически отображает состояние и реализует абстрактную операцию Обновить() Наблюдателя, обеспечивающую обновление отображаемого состояния.
ПРИМЕЧАНИЕ
Курсивом в данном абзаце отображены имена абстрактных классов и операций (это требование языка UML).
Динамическая составляющая паттерна Наблюдатель показана на рис. 12.48. На рисунке представлено поведение паттерна при взаимодействии субъекта с двумя наблюдателями.

Рис. 12.47. Структурная составляющая паттерна Наблюдатель
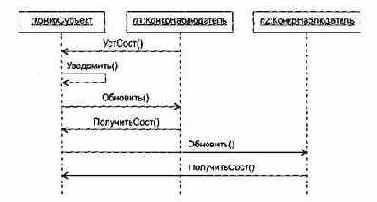
Рис. 12.48. Динамическая составляющая паттерна Наблюдатель
Результаты. Субъекту известно только об абстрактном наблюдателе, он ничего не знает о конкретных наблюдателях. В результате между этими объектами устанавливается минимальное сцепление (это достоинство). Изменения в субъекте могут привести к неоправданно большому количеству обновлений наблюдателей — ведь наблюдателю неизвестно, что именно изменилось в субъекте, затрагивают ли его произошедшие изменения (это недостаток).
Обозначение паттерна Наблюдатель приведено на рис. 12.49, где показано, что у него два параметра настройки — субъект и наблюдатель.
Рис. 12.49. Обозначение паттерна Наблюдатель
Эти параметры обозначают роли, которые будут играть конкретные классы, используемые при настройке паттерна на конкретное применение. Например, настройку паттерна на отображение текущего фильма кинофестиваля иллюстрирует рис. 12.50.
Рис. 12.50. Настройка паттерна Наблюдатель
Видим, что подключаемые конкретные классы (Кинопрограмма, Текущий фильм) соединяются с символом паттерна пунктирными линиями. Каждая пунктирная линия подписана ролью (именем параметра), которую играет конкретный класс в формируемой кооперации. Таким образом, в данном случае класс Кинопрограмма становится подклассом абстрактного класса Субъект в паттерне, а класс Текущий фильм — подклассом абстрактного класса Наблюдатель в паттерне.
Планирование
Определяется набор проектных задач. Устанавливаются связи между задачами, оценивается сложность каждой задачи. Определяются людские и другие ресурсы. Создается сетевой график задач, проводится его временная разметка.
Планирование проектных задач
Основной задачей при планировании является определение WBS — Work Breakdown Structure (структуры распределения работ). Она составляется с помощью утилиты планирования проекта. Типовая WBS приведена на рис. 2.2.
Первыми выполняемыми задачами являются системный анализ и анализ требований. Они закладывают фундамент для последующих параллельных задач.
Системный анализ проводится с целью:
1) выяснения потребностей заказчика;
2) оценки выполнимости системы;
3) выполнения экономического и технического анализа;
4) распределения функций по элементам компьютерной системы (аппаратуре, программам, людям, базам данных и т. д.);
5) определения стоимости и ограничений планирования;
6) создания системной спецификации.
В системной спецификации описываются функции, характеристики системы, ограничения разработки, входная и выходная информация.
Анализ требований дает возможность:
1) определить функции и характеристики программного продукта;
2) обозначить интерфейс продукта с другими системными элементами;
3) определить проектные ограничения программного продукта;
4) построить модели: процесса, данных, режимов функционирования продукта;
5) создать такие формы представления информации и функций системы, которые можно использовать в ходе проектирования.

Результаты анализа сводятся в спецификацию требований к программному продукту.
Как видно из типовой структуры, задачи по проектированию и планированию тестов могут быть распараллелены. Благодаря модульной природе ПО для каждого модуля можно предусмотреть параллельный путь для детального (процедурного) проектирования, кодирования и тестирования. После получения всех модулей ПО решается задача тестирования интеграции — объединения элементов в единое целое. Далее проводится тестирование правильности, которое обеспечивает проверку соответствия ПО требованиям заказчика.
Ромбиками на рис. 2.2 обозначены вехи — процедуры контроля промежуточных результатов. Очень важно, чтобы вехи были расставлены через регулярные интервалы (вдоль всего процесса разработки ПО).
Это даст руководителю возможность регулярно получать информацию о текущем положении дел. Вехи распространяются и на документацию как на один из результатов успешного решения задачи.
Параллельность действий повышает требования к планированию. Так как параллельные задачи выполняются асинхронно, планировщик должен определить межзадачные зависимости. Это гарантирует «непрерывность движения к объединению». Кроме того, руководитель проекта должен знать задачи, лежащие на критическом пути. Для того чтобы весь проект был выполнен в срок, необходимо выполнять в срок все критические задачи.
Основной рычаг в планирующих методах — вычисление границ времени выполнения задачи.
Обычно используют следующие оценки:
1. Раннее время начала решения задачи

2. Позднее время начала решения задачи

3. Раннее время конца решения задачи


4. Позднее время конца решения задачи


5. Общий резерв — количество избытков и потерь планирования задач во времени, не приводящих к увеличению длительности критического пути Тк.п.
Все эти значения позволяют руководителю (планировщику) количественно оценить успех в планировании, выполнении задач.
Рекомендуемое правило распределения затрат проекта — 40-20-40:
q на анализ и проектирование приходится 40% затрат (из них на планирование и системный анализ — 5%);
q на кодирование — 20%;
q на тестирование и отладку — 40%.
Планирование управления риском
Цель планирования — сформировать набор функций управления каждым элементом риска. Введем необходимые определения.
В планировании используют понятие эталонного уровня риска. Обычно выбирают три эталонных уровня риска: превышение стоимости, срыв планирования, упадок производительности. Они могут быть причиной прекращения проекта. Если комбинация проблем, создающих риск, станет причиной превышения любого из этих уровней, работа будет остановлена. В фазовом пространстве риска эталонному уровню риска соответствует эталонная точка. В эталонной точке решения « продолжать проект» и «прекратить проект» имеют одинаковую силу. На рис. 15.3 показана кривая останова, составленная из эталонных точек.
Рис. 15.3. Кривая останова проекта
Ниже кривой располагается рабочая область проекта, выше кривой — запретная область (при попадании в эту область проект должен быть прекращен).
Реально эталонный уровень редко представляется как кривая, чаще это сфера, в которой есть области неопределенности (в них принять решение невозможно).
Теперь рассмотрим последовательность шагов планирования.
1. Исходными данными для планирования является набор четверок [Ri Pi, Li, REi], где Ri — 2-й элемент риска, Pi — вероятность i-го элемента риска, Li — потеря по i-му элементу риска, REi — влияние i-го элемента риска.
2. Определяются эталонные уровни риска в проекте.
3. Разрабатываются зависимости между каждой четверкой [Ri Pi, Li, REi] и каждым эталонным уровнем.
4. Формируется набор эталонных точек, образующих сферу останова. В сфере останова предсказываются области неопределенности.
5. Для каждого элемента риска разрабатывается план управления. Предложения плана составляются в виде ответов на вопросы «зачем, что, когда, кто, где, как и сколько».
6. План управления каждым элементом риска интегрируется в общий план программного проекта.
Подпотоки
S-1: создать заказ авиабилета. Система отображает диалоговое окно, содержащее поля для пункта назначения и даты полета. Покупатель вводит пункт назначения и дату полета (Е-2). Система отображает параметры авиарейсов (Е-3). Покупатель выбирает авиарейс. Система связывает покупателя с выбранным авиарейсом (Е-4). Возврат к началу элемента Use Case.
S-2: удалить заказ авиабилета. Система отображает параметры заказа. Покупатель подтверждает решение о ликвидации заказа (Е-5). Система удаляет связь с покупателем (Е-6). Возврат к началу элемента Use Case.
S-3: проверить заказ авиабилета. Система выводит (Е-7) и отображает параметры заказа авиабилета: номер рейса, пункт назначения, дата, время, место, цену. Когда покупатель указывает, что он закончил проверку, выполняется возврат к началу элемента Use Case.
S-4: реализовать заказ авиабилета. Система запрашивает параметры кредитной карты покупателя. Покупатель вводит параметры своей кредитной карты (Е-8). Возврат к началу элемента Use Case.
Полиморфизм
Полиморфизм — возможность с помощью одного имени обозначать операции из различных классов (но относящихся к общему суперклассу). Вызов обслуживания по полиморфному имени приводит к исполнению одной из некоторого набора операций.
Рассмотрим различные реализации процедуры Записывать. Для класса ПараметрыПолета реализация имеет вид
procedure Записывать (the: in out ПараметрыПолета) is
begin
-- записывать имя параметра
-- записывать отметку времени
end Записывать;
В классе Кабина предусмотрена другая реализация процедуры:
procedure Записывать (the: in out Кабина) is
begin
Записывать (ПараметрыПолета (the)); -- вызов метода
-- суперкласса
-- записывать значение давления
-- записывать процентное содержание кислорода
-- записывать значение температуры
end Записывать;
Предположим, что мы имеем по экземпляру каждого из этих двух классов:
Вполете: ПараметрыПолета:= Инициировать;
Вкабине: Кабина:= Инициировать (768. 21. 20);
Предположим также, что имеется свободная процедура:
procedure СохранятьНовДанные (d: in out
ПараметрыПолета'class; t: БортовоеВремя) is
begin
if ТекущВремя(d) >= t then
Записывать (d): -- диспетчирование с помощью тега
end if;
end СохранятьНовДанные;
Что случится при выполнении следующих операторов?
q СохранятьНовДанные (Вполете, БортовоеВремя (60));
q СохранятьНовДанные (Вкабине, БортовоеВремя (120));
Каждый из операторов вызывает операцию Записывать нужного класса. В первом случае диспетчеризация приведет к операции Записывать из класса ПараметрыПолета. Во втором случае будет выполняться операция из класса Кабина. Как видим, в свободной процедуре переменная d может обозначать объекты разных классов, значит, здесь записан вызов полиморфной операции.
Построение модели требований
Напомним, что основное назначение диаграмм Use Case — определение требований заказчика к будущему программному приложению. Обсудим разработку ПО для машины утилизации, которая принимает использованные бутылки, банки, ящики. Для определения элементов Use Case, которые должны выполняться в системе, вначале определяют актеров.
Выбор актеров
Поиск актеров — большая работа. Сначала выделяют первичных актеров, использующих систему по прямому назначению. Каждый из первичных актеров участвует в выполнении одной или нескольких главных задач системы. В нашем примере первичным актером является Потребитель. Потребитель кладет в машину бутылки, получает квитанцию от машины.
Кроме первичных, существуют и вторичные актеры. Они наблюдают и обслуживают систему. Вторичные актеры существуют только для того, чтобы первичные актеры могли использовать систему. В нашем примере вторичным актером является Оператор. Оператор обслуживает машину и получает дневные отчеты о ее работе. Мы не будем нуждаться в операторе, если не будет потребителей.
Таким образом, внешняя среда машины утилизации имеет вид, представленный на рис. 12.36.

Рис. 12.36. Внешняя среда машины утилизации
Деление актеров на первичных и вторичных облегчает выбор системной архитектуры в терминах основного функционального назначения. Системную структуру определяют в основном первичные актеры. Именно от них в систему приходят главные изменения. Поэтому полное выделение первичных актеров гарантирует, что архитектура системы будет настроена на большинство важных пользователей.
Определение элементов Use Case
После выбора внешней среды можно выявить внутренние функциональные возможности системы. Для этого определяются элементы Use Case.
Каждый элемент Use Case задает некоторый путь использования системы, выполнение некоторой части функциональных возможностей. Полная совокупность элементов Use Case определяет все существующие пути использования системы.
Элемент Use Case — это последовательность взаимодействий в диалоге, выполняемом актером и системой.
Запускается элемент Use Case актером, поэтому удобно выявлять элементы Use Case с помощью актеров.
Рассматривая каждого актера, мы решаем, какие элементы Use Case он может выполнять. Для этого изучается описание системы (с точки зрения актера) или проводится обсуждение с теми, кто будет действовать как актер.
Перейдем к примеру. Потребитель — первичный актер, поэтому начнем с этой роли. Этот актер должен выполнять возврат утилизируемых элементов. Так формируется элемент Use Case Возврат элемента. Приведем его текстовое описание:
Начинается, когда потребитель начинает возвращать банки, бутылки, ящики. Для каждого элемента, помещенного в машину утилизации, система увеличивает количество элементов, принятых от Потребителя, и общее количество элементов этого типа за день.
После сдачи всех элементов Потребитель нажимает кнопку квитанции, чтобы получить квитанцию, на которой напечатаны названия возвращенных элементов и общая сумма возврата.
Следующий актер — Оператор. Он получает дневной отчет об элементах, сданных за день. Это образует элемент Use Case Создание дневного отчета. Его описание:
Начинается оператором, когда он хочет получить информацию об элементах, сданных за день.
Система печатает количество элементов каждого типа и общее количество элементов, полученных за день.
Доя подготовки к созданию нового дневного отчета сбрасывается в ноль параметр Общее количество.
Кроме того, актер Оператор может изменять параметры сдаваемых элементов. Назовем соответствующий элемент Use Case Изменение элемента. Его описание:
Могут изменяться цена и размер каждого возвращаемого элемента. Могут добавляться новые типы элементов.
После выявления всех элементов диаграмма Use Case для системы принимает вид, показанный на рис. 12.37.

Рис. 12.37. Диаграмма Use Case для машины утилизации
Чаще всего полные описания элементов Use Case формируются за несколько итераций. На каждом шаге в описание вводятся дополнительные детали. Например, окончательное описание Возврата элемента может иметь следующий вид:
Когда потребитель возвращает сдаваемый элемент, элемент измеряется системой. Измерения позволяют определить тип элемента. Если тип допустим, то увеличивается количество элементов этого типа, принятых от Потребителя, и общее количество элементов этого типа за день.
Если тип недопустим, то на панели машины высвечивается «недействительно».
Когда Потребитель нажимает кнопку квитанции, принтер печатает дату. Производятся вычисления. По каждому типу принятых элементов печатается информация: название, принятое количество, цена, итого для типа. В конце печатается сумма, которую должен получить потребитель.
Не всегда очевидно, как распределить функциональные возможности по отдельным элементам Use Case и что является вариантом одного и того же элемента Use Case. Основной критерий выбора — сложность элемента Use Case. При анализе вариантов поведения рассматривают их различия. Если различия малы, варианты встраивают в один элемент Use Case. Если различия велики, то варианты описываются как отдельные элементы Use Case.
Обычно элемент Use Case задает одну основную и несколько альтернативных последовательностей событий.
Каждый элемент Use Case выделяет частный аспект функциональных возможностей системы. Поэтому элементы Use Case обеспечивают инкрементную схему анализа функций системы. Можно независимо разрабатывать элементы Use Case для разных функциональных областей, а позднее соединить их вместе (для формирования полной модели требований).
Вывод: на основе элементов Use Case в каждый момент времени можно концентрировать внимание на одной частной проблеме, что позволяет вести параллельную разработку.
Расширение функциональных возможностей
Для добавления в элемент Use Case новых действий удобно применять отношение расширения. С его помощью базовый элемент Use Case может быть расширен новым элементом Use Case.
В нашем примере поведение системы не определено для случая, когда сдаваемый элемент застрял. Введем элемент Use Case Элемент Застрял, который будет расширять базовый элемент Use Case Возврат Элемента (рис. 12.38).
Рис 12.38. Расширение элемента Use Case возврат элемента
Описание элемента Use Case Элемент застрял может иметь следующий вид:
Если элемент застрял, для вызова Оператора вырабатывается сигнал тревоги. После удаления застрявшего элемента Оператор сбрасывает сигнал тревоги. В результате Потребитель может продолжить сдачу элементов. Величина ИТОГО сохраняет правильное значение. Цена застрявшего элемента не засчитывается.
Таким образом, описание базового элемента остается прежним, простым. Еще один пример приведен на рис. 12.39.
Здесь мы видим только один базовый элемент Use Case Сеанс работы. Все остальные элементы Use Case могут добавляться как расширения. Базовый элемент Use Case при этом остается почти без изменений.

Рис. 12.39. Применение отношения расширения
Отношение расширения определяет прерывание базового элемента Use Case, которое происходит для вставки другого элемента Use Case. Базовый элемент Use Case не знает, будет выполняться прерывание или нет. Вычисление условий прерывания находится вне компетенции базового элемента Use Case.
В расширяющем элементе Use Case указывается ссылка на то место базового элемента Use Case, куда он будет вставляться (при прерывании). После выполнения расширяющего элемента Use Case продолжается выполнение базового элемента Use Case.
Обычно расширения используют:
q для моделирования вариантных частей элементов Use Case;
q для моделирования сложных и редко выполняемых альтернативных последовательностей;
q для моделирования подчиненных последовательностей, которые выполняются только в определенных случаях;
q для моделирования систем с выбором на основе меню.
Главное, что следует помнить: решение о выборе, подключении варианта на основе расширения принимается вне базового элемента Use Case. Если же вы вводите в базовый элемент Use Case условную конструкцию, конструкцию выбора, то придется применять отношение включения.
Это случай, когда «штурвал управления» находится в руках базового элемента Use Case.
Уточнение модели требований
Уточнение модели сводится к выявлению одинаковых частей в элементах Use Case и извлечению этих частей. Любые изменения в такой части, выделенной в отдельный элемент Use Case, будут автоматически влиять на все элементы Use Case, которые используют ее совместно.
Извлеченные элементы Use Case называют абстрактными. Они не могут быть конкретизированы сами по себе, применяются для описания одинаковых частей в других, конкретных элементах Use Case. Таким образом, описания абстрактных элементов Use Case используются в описаниях конкретных элементов Use Case. Говорят, что конкретный элемент Use Case находится в отношении «включает» с абстрактным элементом Use Case.
Вернемся к нашему примеру. В этом примере два конкретных элемента Use Case Возврат элемента и Создание дневного отчета имеют общую часть — действия, обеспечивающие печать квитанции. Поэтому, как показано на рис. 12.40, можно выделить абстрактный элемент Use Case Печать. Этот элемент Use Case будет специализироваться на выполнении распечаток.
Рис. 12.40. Применение отношения включения
В свою очередь, абстрактные элементы Use Case могут использоваться другими абстрактными элементами Use Case. Так образуется иерархия. При построении иерархии абстрактных элементов Use Case руководствуются правилом: выделение элементов Use Case прекращается при достижении уровня отдельных операций над объектами.
Выделение абстрактных элементов Use Case можно упростить с помощью абстрактных актеров.
Абстрактный актер — это общий фрагмент роли в нескольких конкретных актерах. Абстрактный актер выражает подобия в элементах Use Case. Конкретные актеры находятся в отношении наследования с абстрактным актером. Так, в машине утилизации конкретные актеры имеют одно общее поведение: они могут получать квитанцию. Поэтому можно определить одного абстрактного актера — Получателя квитанции. Как показано на рис. 12.41, наследниками этого актера являются Потребитель и Оператор.
Рис. 12.41. Выделение абстрактного актера
Выводы:
1. Абстрактные элементы Use Case находят извлечением общих последовательностей из различных элементов Use Case.
2. Отношение «включает» применяется, если несколько элементов Use Case имеют общее поведение. Цель: устранить повторения, ликвидировать избыточность.
3. Кроме того, это отношение часто используют для ограничения сложности большого элемента Use Case.
4. Отношение «расширяет» применяется, когда описывается вариация, дополняющая нормальное поведение.
Потоковый граф
Для представления программы используется потоковый граф. Перечислим его особенности.
1. Граф строится отображением управляющей структуры программы. В ходе отображения закрывающие скобки условных операторов и операторов циклов (end if; end loop) рассматриваются как отдельные (фиктивные) операторы.
2. Узлы (вершины) потокового графа соответствуют линейным участкам программы, включают один или несколько операторов программы.
3. Дуги потокового графа отображают поток управления в программе (передачи управления между операторами). Дуга — это ориентированное ребро.
4. Различают операторные и предикатные узлы. Из операторного узла выходит одна дуга, а из предикатного — две дуги.
4. Предикатные узлы соответствуют простым условиям в программе. Составное условие программы отображается в несколько предикатных узлов. Составным называют условие, в котором используется одна или несколько булевых операций (OR, AND).
5. Например, фрагмент программы
if a OR b
then x
else у
end if;
вместо прямого отображения в потоковый граф вида, показанного на рис. 6.4, отображается в преобразованный потоковый граф (рис. 6.5).
Рис. 6.4. Прямое отображение в потоковый граф
Рис. 6.5. Преобразованный потоковый граф
6. Замкнутые области, образованные дугами и узлами, называют регионами.
7. Окружающая граф среда рассматривается как дополнительный регион. Например, показанный здесь граф имеет три региона — Rl, R2, R3.
Пример 1. Рассмотрим процедуру сжатия:
процедура сжатие
1 выполнять пока нет EOF
1 читать запись;
2 если запись пуста
3 то удалить запись:
4 иначе если поле а >= поля b
5 то удалить b;
6 иначе удалить а;
7а конец если;
7а конец если;
7b конец выполнять;
8 конец сжатие;
Рис. 6.6. Преобразованный потоковый граф процедуры сжатия
Она отображается в потоковый граф, представленный на рис. 6.6. Видим, что этот потоковый граф имеет четыре региона.
Повторное использование СОМ-объектов
Известно, что основным средством повторного использования существующего кода является наследование реализации (новый класс наследует реализацию операций существующего класса). СОМ не поддерживает это средство. Причина — в типовой СОМ-среде базовые объекты и объекты-наследники создаются, выпускаются и обновляются независимо. В этих условиях изменения базовых объектов могут вызвать непредсказуемые последствия в объектах-наследниках их реализации. СОМ предлагает другие средства повторного использования — включение и агрегирование.
Применяются следующие термины:
q внутренний объект — это базовый объект;
q внешний объект — это объект, повторно использующий услуги внутреннего объекта.
При включении (делегировании) внешний объект является обычным клиентом внутреннего объекта. Как показано на рис. 13.21, когда клиент вызывает операцию внешнего объекта, эта операция, в свою очередь, вызывает операцию внутреннего объекта.
Рис. 13.21. Повторное использование СОМ-объекта с помощью включения
При этом внутренний объект ничего не замечает.
Достоинство включения — простота. Недостаток — низкая эффективность при длинной цепочке «делегирующих» объектов.
Недостаток включения устраняет агрегирование. Оно позволяет внешнему объекту обманывать клиентов — представлять в качестве собственных интерфейсы, реализованные внутренним объектом. Как показано на рис. 13.22, когда клиент запрашивает у внешнего объекта указатель на такой интерфейс, ему возвращается указатель на внутренний, агрегированный интерфейс. Клиент об агрегировании ничего не знает, зато внутренний объект обязательно должен знать о том, что он агрегирован.
Рис. 13.22. Повторное использование СОМ-объекта с помощью агрегирования
Зачем требуется такое знание? В чем причина? Ответ состоит в необходимости особой реализации внутреннего объекта. Она должна обеспечить правильный подсчет ссылок и корректную работу операции Querylnterface.
Представим две практические задачи:
q запрос клиентом у внутреннего объекта (с помощью операции Querylnterface) указателя на интерфейс внешнего объекта;
q изменение клиентом счетчика ссылок внутреннего объекта (с помощью операции AddRef) и информирование об этом внешнего объекта.
Ясно, что при автономном и независимом внутреннем объекте их решить нельзя. В противном же случае решение элементарно — внутренний объект должен отказаться от собственного интерфейса IUnknown и применять только операции IUnknown внешнего объекта. Иными словами, адрес собственного IUnknown должен быть замещен адресом IUnknown агрегирующего объекта. Это указывается при создании внутреннего объекта (за счет добавления адреса как параметра операции CoCreatelnstance или операции IClassFactory::CreateInstance).
Предметы в UML
В UML имеются четыре разновидности предметов:
q структурные предметы;
q предметы поведения;
q группирующие предметы;
q поясняющие предметы.
Эти предметы являются базовыми объектно-ориентированными строительными блоками. Они используются для написания моделей.
Структурные предметы являются существительными в UML-моделях. Они представляют статические части модели — понятийные или физические элементы. Перечислим восемь разновидностей структурных предметов.
1. Класс — описание множества объектов, которые разделяют одинаковые свойства, операции, отношения и семантику (смысл). Класс реализует один или несколько интерфейсов. Как показано на рис. 10.1, графически класс отображается в виде прямоугольника, обычно включающего секции с именем, свойствами (атрибутами) и операциями.

Рис. 10.1. Классы
2. Интерфейс — набор операций, которые определяют услуги класса или компонента. Интерфейс описывает поведение элемента, видимое извне. Интерфейс может представлять полные услуги класса или компонента или часть таких услуг. Интерфейс определяет набор спецификаций операций (их сигнатуры), а не набор реализаций операций. Графически интерфейс изображается в виде кружка с именем, как показано на рис. 10.2. Имя интерфейса обычно начинается с буквы «I». Интерфейс редко показывают самостоятельно. Обычно его присоединяют к классу или компоненту, который реализует интерфейс.
3. Кооперация (сотрудничество) определяет взаимодействие и является совокупностью ролей и других элементов, которые работают вместе для обеспечения коллективного поведения более сложного, чем простая сумма всех элементов. Таким образом, кооперации имеют как структурное, так и поведенческое измерения. Конкретный класс может участвовать в нескольких кооперациях. Эти кооперации представляют реализацию паттернов (образцов), которые формируют систему.
Как показано на рис. 10.3, графически кооперация изображается как пунктирный эллипс, в который вписывается ее имя.
Рис. 10.3. Кооперации
4. Актер — набор согласованных ролей, которые могут играть пользователи при взаимодействии с системой (ее элементами Use Case). Каждая роль требует от системы определенного поведения. Как показано на рис. 10.4, актер изображается как проволочный человечек с именем.

Рис. 10.4. Актеры
5. Элемент Use Case (Прецедент) — описание последовательности действий (или нескольких последовательностей), выполняемых системой в интересах отдельного актера и производящих видимый для актера результат. В модели элемент Use Case применяется для структурирования предметов поведения. Элемент Use Case реализуется кооперацией. Как показано на рис. 10.5, элемент Use Case изображается как эллипс, в который вписывается его имя.

Рис. 10.5. Элементы Use Case
6. Активный класс — класс, чьи объекты имеют один или несколько процессов (или потоков) и поэтому могут инициировать управляющую деятельность. Активный класс похож на обычный класс за исключением того, что его объекты действуют одновременно с объектами других классов. Как показано на рис. 10.6, активный класс изображается как утолщенный прямоугольник, обычно включающий имя, свойства (атрибуты) и операции.

Рис. 10.6. Активные классы
7. Компонент — физическая и заменяемая часть системы, которая соответствует набору интерфейсов и обеспечивает реализацию этого набора интерфейсов. В систему включаются как компоненты, являющиеся результатами процесса разработки (файлы исходного кода), так и различные разновидности используемых компонентов (СОМ+-компоненты, Java Beans). Обычно компонент — это физическая упаковка различных логических элементов (классов, интерфейсов и сотрудничеств). Как показано на рис. 10.7, компонент изображается как прямоугольник с вкладками, обычно включающий имя.

Рис. 10.7. Компоненты
8. Узел — физический элемент, который существует в период работы системы и представляет ресурс, обычно имеющий память и возможности обработки. В узле размещается набор компонентов, который может перемещаться от узла к узлу. Как показано на рис. 10.8, узел изображается как куб с именем.
Рис. 10.8. Узлы
Предметы поведения — динамические части UML-моделей. Они являются глаголами моделей, представлением поведения во времени и пространстве. Существует две основные разновидности предметов поведения.
1. Взаимодействие — поведение, заключающее в себе набор сообщений, которыми обменивается набор объектов в конкретном контексте для достижения определенной цели. Взаимодействие может определять динамику как совокупности объектов, так и отдельной операции. Элементами взаимодействия являются сообщения, последовательность действий (поведение, вызываемое сообщением) и связи (соединения между объектами). Как показано на рис. 10.9, сообщение изображается в виде направленной линии с именем ее операции.

Рис. 10.9. Сообщения
2. Конечный автомат — поведение, которое определяет последовательность состояний объекта или взаимодействия, выполняемые в ходе его существования в ответ на события (и с учетом обязанностей по этим событиям). С помощью конечного автомата может определяться поведение индивидуального класса или кооперации классов. Элементами конечного автомата являются состояния, переходы (от состояния к состоянию), события (предметы, вызывающие переходы) и действия (реакции на переход). Как показано на рис. 10.10, состояние изображается как закругленный прямоугольник, обычно включающий его имя и его подсостояния (если они есть).

Рис. 10.10. Состояния
Эти два элемента — взаимодействия и конечные автоматы — являются базисными предметами поведения, которые могут включаться в UML-модели. Семантически эти элементы ассоциируются с различными структурными элементами (прежде всего с классами, сотрудничествами и объектами).
Группирующие предметы — организационные части UML-моделей. Это ящики, по которым может быть разложена модель. Предусмотрена одна разновидность группирующего предмета — пакет.
Пакет — общий механизм для распределения элементов по группам. В пакет могут помещаться структурные предметы, предметы поведения и даже другие группировки предметов. В отличие от компонента (который существует в период выполнения), пакет — чисто концептуальное понятие. Это означает, что пакет существует только в период разработки. Как показано на рис. 10.11, пакет изображается как папка с закладкой, на которой обозначено его имя и, иногда, его содержание.

Рис. 10.11. Пакеты
Поясняющие предметы — разъясняющие части UML-моделей. Они являются замечаниями, которые можно применить для описания, объяснения и комментирования любого элемента модели. Предусмотрена одна разновидность поясняющего предмета — примечание.
Примечание — символ для отображения ограничений и замечаний, присоединяемых к элементу или совокупности элементов. Как показано на рис. 10.12, примечание изображается в виде прямоугольника с загнутым углом, в который вписывается текстовый или графический комментарий.

Рис. 10.12. Примечания
