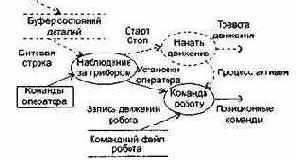
В качестве иллюстрации применения методики оценки, изложенной в разделе «Выполнение оценки проекта на основе LOC- и FP-метрик», рассмотрим конкретный пример. Предположим, что поступил заказ от концерна «СУПЕРАВТО». Необходимо создать ПО для рабочей станции дизайнера автомобиля (РДА). Заказчик определил проблемную область проекта в своей спецификации:
q ПО РДА должно формировать 2- и 3-мерные изображения для дизайнера;
q дизайнер должен вести диалог с РДА и управлять им с помощью стандартизованного графического пользовательского интерфейса;
q геометрические данные и прикладные данные должны содержаться в базе данных РДА;
q модули проектного анализа рабочей станции должны формировать данные для широкого класса дисплеев SVGA;
q ПО РДА должно управлять и вести диалог со следующими периферийными устройствами: мышь, дигитайзер (графический планшет для ручного ввода), плоттер (графопостроитель), сканер, струйный и лазерный принтеры.
Прежде всего надо детализировать проблемную область. Следует выделить базовые функции ПО и очертить количественные границы. Очевидно, нужно определить, что такое «стандартизованный графический пользовательский интерфейс», какими должны быть размер и другие характеристики базы данных РДА и т. д.
Будем считать, что эта работа проделана и что идентифицированы следующие основные функции ПО:
1. Средства управления пользовательским интерфейсом СУПИ.
2. Анализ двухмерной графики А2Г.
3. Анализ трехмерной графики А3Г.
4. Управление базой данных УБД.
5. Средства компьютерной дисплейной графики КДГ.
6. Управление периферией УП.
7. Модули проектного анализа МПА.
Теперь нужно оценить каждую из функций количественно, с помощью LOC-оценки. По каждой функции эксперты предоставляют лучшее, худшее и вероятное значения. Ожидаемую LOC-оценку реализации функции определяем по формуле
Соответственно, затраты на разработку каждой функции будем определять по выражению
ЗАТРАТЫ i = (LOCожi
/ПРОИЗВ i)[чел.-мес].
Теперь мы имеем все необходимые данные для завершения расчетов. Заполним до конца таблицу оценки нашего проекта (табл. 2.24).
Таблица 2.24. Конечная таблица оценки проекта
Функция
Лучш.
Вероят.
Худш.
Ожид. [LOC]
Уд. стоимость [S/LOC]
Предваряющее тестирование при экстремальной разработке
Предваряющее тестирование и рефакторинг (реорганизация) — основной способ разработки при экстремальном программировании.
Обычно рефакторингом называют внесение в код небольших изменений, сохраняющих функциональность и улучшающих структуру программы. Более широко рефакторинг определяют как технику разработки ПО через множество изменений кода, направленных на добавление функциональности и улучшение структуры.
Предваряющее (test-first) тестирование и рефакторинг — это способ создания и последующего улучшения ПО, при котором сначала пишутся тесты, а затем программируется код, который будет подвергаться этим тестам. Программист выбирает задачу, затем пишет тестовые варианты, которые приводят к отказу программы, так как программа еще не выполняет данную задачу. Далее он модифицирует программу так, чтобы тесты проходили и задача выполнялась. Программист продолжает писать новые тестовые варианты и модифицировать программу (для их выполнения) до тех пор, пока программа не будет исполнять все свои обязанности. После этого программист небольшими шагами улучшает ее структуру (проводит рефакторинг), после каждого из шагов запускает все тесты, чтобы убедиться, что программа по-прежнему работает.
Для демонстрации такого подхода рассмотрим пример конкретной разработки. Будем опираться на технику, описанную Робертом Мартином (с любезного разрешения автора)*.
* Robert C. Martin. RUP/XP Guidelines: Test-first Design and Refactoring. - Rational Software White Paper, 2000.
Создадим программу для регистрации посещений кафе-кондитерской. Каждый раз, когда лакомка посещает кафе, вводится количество купленных булочек, их стоимость и текущий вес любителя (любительницы) сладостей. Система отслеживает эти значения и выдает отчеты. Программу будем писать на языке Java.
Для экстремального тестирования удобно использовать среду Junit, авторами которой являются Кент Бек и Эрик Гамма (Kent Beck и Erich Gamma). Прежде всего создадим среду для хранения тестов модулей. Это очень важно для предваряющего тестирования: вначале пишется тестовый вариант, а только потом — код программы.
Необходимый код имеет следующий вид:
Листинг 16.1. ТестЛакомки. java
import junit.framework.*;
public class ТестЛакомки extends TestCase
{
public ТестЛакомки (String name)
{
super(name);
}
}
Видно, что при использовании среды Junit класс-контейнер тестовых вариантов должен быть наследником от класса TestCase. Кстати, условимся весь новый код выделять полужирным шрифтом.
Создадим первый тестовый вариант. Одна из целей создаваемой программы — запись количества посещений кафе. Поэтому должен существовать объект ПосещениеКафе, содержащий нужные данные. Следовательно, надо написать тест, создающий этот объект и опрашивающий его свойства. Тесты будем записывать как тестовые функции (их имена должны начинаться с префикса тест). Введем тестовую функцию тестСоздатьПосещениеКафе (листинг 16.2).
Листинг 16.2. ТестЛакомки.jауа
import junit.framework.*;
public class ТестЛакомки extends TestCase
{
public ТестЛакомки (String name)
{
super(name);
}
public void тестСоздатьПосещениеКафе()
{
ПосещениеКафе v = new-ПосещениеКафе();
}
}
Для компиляции этого фрагмента подключим класс ПосещениеКафе.
Листинг 16.3. ТестЛакомки.jаvа и ПосещениеКафе.jаvа
ТестЛакомки.jаvа
import junit. framework.*;
import ПосещениеКафе;
public class ТестЛакомки extends TestCase
{
public ТестЛакомки (String name)
{
super(name);
}
public void тестСоздатьПосещениеКафе()
{
ПосещениеКафе v = new ПосещениеКафе();
}
}
ПосещениеКафе.java
public class ПосещениеКафе
{
}
Этот код компилируется, тест проходит, и мы готовы добавить необходимую функциональность.
Листинг 16.4. ТестЛакомки.jауа и ПосещениеКафе.jауа
public double получитьБулочки() {return егоБулочки;}
public double получитьСтоимость() {return егоСтоимость;}
public double получитьЦену(){return егоСтоимость/егоБулочки;}
public double получитьВес() {return eroBec;}
}
На этом шаге мы добавили тесты в класс ТестЛакомки, а также добавили методы в класс ПосещениеКафе. Унаследованные методы assertEquals позволяют проводить сравнение ожидаемых и фактических результатов тестирования.
Очевидно, вы удивитесь этому подходу. Неужели нельзя вначале написать весь код класса ПосещениеКафе, а потом создать тесты? Ответ достаточно прост. Написание тестов перед написанием программного кода дает важное преимущество: мы знаем, что весь ранее созданный код компилируется и выполняется. Следовательно, любая ошибка вызывается текущими изменениями, а не более ранним кодом. И значимость этого преимущества усиливается по мере продвижения вперед.
Далее определимся с хранением объектов класса ПосещениеКафе. Очевидно, что свойство егоВес характеризует лакомку. Таким образом, объект ПосещениеКафе записывает часть состояния лакомки па момент посещения кафе. Следовательно, нужно создать объект Лакомка и содержать объекты класса ПосещениеКафе в нем.
Листинг 16.5. ТестЛакомки.java и Лакомка.java
ТестЛакомки.java
import junit.framework.*;
import ПосещениеКафе;
import java.util.Date
public class ТестЛакомки extends TestCase
{
public TecтЛакомки(String name)
{
super(name);
}
…
public void тестСоздатьЛакомку()
{
Лакомка g = new Лакомка();
assertEquals(0, д.получитьЧислоПосещений());
}
}
Лакомка.Java
public class Лакомка
{
public int получитьЧислоПосещений()
{
return 0;
}
}
Листинг 16. 5 показывает начальный шаг. Мы написали новую тестовую функцию тестСоздатьЛакомку. Эта функция создает объект класса Лакомка и затем убеждается, что хранимое количество посещений равно 0. Конечно, реализация метода получитьЧислоПосещений неверна, но она обеспечивает прохождение теста. Это позволит нам в будущем выполнить рефакторинг (для улучшения решения).
Введем в класс Лакомку объект-контейнер, хранящий данные о разных посещениях (как элементы списка в массиве изменяемого размера). Для его создания используем класс-контейнер Array List из библиотеки Java 2. В будущем нам потребуются три метода контейнера: add (добавить элемент в контейнер), get (получить элемент из контейнера), size (вернуть количество элементов в контейнере).
Листинг 16.6. ЛАKOMKА.java
import java.util.ArrayList;
public class Лакомка
{
private ArrayList егоПосещения = new ArrayList();
// создание объекта егоПосещения - контейнера посещений
public int получитьЧислоПосещений ()
{
return егоПосещения.size();
// возврат количества элементов в контейнере
// оно равно количеству посещений кафе
}
}
Отметим, что после каждого изменения мы прогоняем все тесты, а не только функцию тестСоздатьЛакомку. Это дает гарантию, что изменения не испортили уже работающий код.
На следующем шаге следует определить, как к Лакомке добавляется посещение кафе. Так будет выглядеть простейший тестовый вариант:
Листинг 16.7. TecтЛакомки.java
public void тестДобавитьПосещение()
{
double булочки = 7.0; // 7 булочек
double стоимость = 12.5 * 7; // цена 1 булочки = 12.5 руб.
double вес = 60.0; // взвешивание лакомки
double дельта = 0.0001; // точность
Лакомка g = new Лакомка();
g.добавитьПосещениеКафе(булочки, стоимость, вес);
assertEquals(1, g.получитьЧислоПосещений());
}
В этом тесте объект класса ПосещениеКафе не создается. Очевидно, что создавать объект и добавлять его в список должен метод добавитьПосещениеКафе объекта Лакомка.
Листинг 16.8. Лакомка.jауа
public void добавитьПосещениеКафе((double булочки, double стоимость, double вес)
{
ПосещениеКафе v =
new ПосещениеКафе(new Date(), булочки, стоимость, вес);
егоПосещения.add(v);
// добавление эл-та v в контейнер посещений
}
Опять прогоняются все тесты. Анализ программного кода в функциях тестДобавитьПосещение и тестСоздатьПосещениеКафе показывает, что он частично дублируется. Обе функции создают одинаковые локальные переменные и инициализируют их одинаковыми значениями. Чтобы избавиться от дублирования, проведем рефакторинг тестируемой программы и сделаем локальные переменные свойствами класса.
Листинг 16.9. ТестЛакомки.jауа
import junit.framework.*;
import ПосещениеКафе;
import java.util.Date;
public class ТестЛакомки extends TestCase
{
private double булочки - 7.0; // 7 булочек
private double стоимость = 12.5 * 7;
// цена 1 булочки = 12.5 p.
private double вес = 60.0; // взвешивание лакомки
private double дельта = 0.0001; // точность
public ТестЛакомки(String name)
{
super(name);
}
public void тестСоздатьПосещениеКафе()
{
Date дата = new Date();
ПосещениеКафе v = new ПосещениеКафе(дата. булочки.
Еще раз подчеркнем: наличие тестов позволяет определить, что этот рефакторинг ничего не разрушил в программе. Мы будем убеждаться в этом преимуществе постоянно, после очередного применения рефакторинга для реструктуризации программы. Каждый раз после внесения в код изменений запускаются тесты и проверяется работоспособность программы.
Очередная задача — после добавления к Лакомке объектов ПосещениеКафе у Лакомки можно запрашивать генерацию отчетов. Сначала напишем тесты, начнем с простейшего теста.
При создании этого тестового варианта мы обдумали детали генерации отчета. Во-первых, Лакомка должна обладать методом создатьОтчет. Во-вторых, этот метод должен возвращать объект класса с именем Отчет. В-третьих, Отчет должен иметь несколько методов-селекторов.
Значения, возвращаемые методами-селекторами, следует проанализировать. Для вычисления изменения веса (или приращения веса на одну булочку) одного посещения кафе недостаточно. Чтобы вычислить эти значения, необходимы, как минимум, два посещения, С другой стороны, одного визита достаточно, чтобы сосчитать потребление и стоимость булочек.
Разумеется, тестовый вариант не компилируется. Поэтому необходимо добавить соответствующие методы и классы. Сначала добавим код, обеспечивающий компиляцию, но не обеспечивающий выполнение тестов.
Листинг 16.11. Лакомка.java, TecтЛакомки.java и Отчет.jаvа
Код в листинге 16.11 компилируется и запускается, но его недостаточно для того, чтобы прошли тесты. Нужен рефакторинг кода. Для начала сделаем минимально возможные изменения.
Листинг 16.12. Лакомка.java и Отчет.java
Лакомка.java
public Отчет создатьОтчет()
{
Отчет r = new Отчет();
ПосещениеКафе v = (ПосещениеКафе) егоПосещения. Get(0);
// занести в v первый элемент из контейнера посещений
r.устВесНаБулочку(0);
r.устИзменениеВеса(0);
r.устСтоимостьБулочек(v.получитьСтоимость());
r.устПотреблениеБулочек(v.получитьБулочки()):
return r;
}
Отчет.java
public void устВесНаБулочку (double wpb)
{егоВесНаБулочку = wpb;}
public void устИзменениеВес(double kg)
{егоИзменениеВеса = kg;}
public void устСтоимостьБулочек(double ct)
(егоСтоимостьБулочек = ct;}
public void устПотреблениеБулочек (double b)
{егоПотреблениеБулочек = b;}
Предполагаем, что Лакомке разрешено только одно посещение. В этой версии метода создатьОтчет устанавливаются и возвращаются значения свойств Отчета.
Такой способ разработки метода создатьОтчет может показаться странным, ведь его реализация не завершена. Однако преимущество по-прежнему в том, что между каждой компиляцией и тестированием вносятся только контролируемые добавления.
Если что- то отказывает, можно просто вернуться к предыдущей версии и начать сначала, необходимость в сложной отладке отсутствует.
Для завершения кода продумаем тесты для Лакомки без посещений и с несколькими посещениями кафе. Начнем с теста и кода для варианта без посещений.
Мы установили число посещений для Лакомки равным трем. Предполагается, что цена булочки составляет 12,5 руб., а изменение веса — 0,1 кг на одну булочку. Таким образом, за 175 руб. лакомка покупает и съедает 14 булочек, полнея на 1,4 кг.
Но здесь какая-то ошибка. Скорость изменения веса должна определяться коэффициентом 0,1 кг на одну булочку.
А если разделить 4,2 (изменение веса) на 49 (количество булочек), то получаем коэффициент 0,086. В чем причина несоответствия?
После размышлений становится понятно, что вес лакомки регистрируется на выходе из кафе. Поэтому приращение веса и потребление булочек во время первого посещения не учитывается. Изменим исходные данные теста.
Этот тест корректен. Никогда не известно, с чем встретишься при написании тестов. Можно быть уверенным лишь в том, что, определяя понятия дважды (при написании тестов и кода), вы найдете больше ошибок, чем при простом написании кода.
Теперь добавим код, обеспечивающий прохождение теста из листинга 16.15.
Листинг 16.16. Лакомка.java
public Отчет создатьОтчет()
{
Отчет r = new Отчет ();
if (егоПосещения.size() = 0)
{
r.устВесНаБулочку(0);
r.устИзменениеВеса(0);
r.устСтоимостьБулочек(0);
r.устПотреблениеБулочек(0);
}
else if (егоПосещения.size() = 1)
{
ПосещениеКафе v = (ПосещениеКафе) егоПосещения.get(0);
// занести в v первый элемент из контейнера посещений
r.устВесНаБулочку(0);
r.устИзменениеВеса(0);
r.устСтоимостьБулочек(v.получитьСтоимость());
r.устПотреблениеБулочек(v.получитьБулочки());
}
else
{
double первыйЗамер = 0;
double последнийЗамер = 0;
double общаяСтоиность = 0;
double потреблениеБулочек = 0;
for (int i = 0; i < егоПосещения.size(); i++)
// проход по всем элементам контейнера посещений
{
ПосещениеКафе v = (ПосещениеКафе)
егоПосещения.get(i);
// занести в v 1-й элемент из контейнера посещений
if (i = = 0)
{
первыйЗамер = v.получитьВес();
// занести в первыйЗамер вес при 1-м посещении
потреблениеБулочек -= v.получитьБулочки();
}
if (i= = егоПосещения.size()- 1) последнийЗамер =
v.получитьВес();
// занести в последнийЗамер вес при послед, посещении
общаяСтоимость += v.получитьСтоиность();
потреблениеБулочек += v.получитьБулочки();
}
double изменение = последнийЗамер - первыйЗамер;
r.устВесНаБулочкуСизменение/потреблениеБулочек);
r.устИзненениеВеса(иэненение);
r.устСтоиностьБулочек(общаяСтоиность):
r.устПотреблениеБулочек(потреблениеБулочек);
}
return r;
}
Данный код из-за множества специальных случаев выглядит неуклюже. Для устранения специальных случаев нужно провести рефакторинг. Поскольку третий специальный случай наиболее универсален, надо убрать первые два случая.
Когда мы это сделаем, запуск тестового варианта тестОтчетаОдногоПосещения завершится неудачей. Причина в том, что обработка одного посещения включала булочки, купленные только во время первого посещения. А как мы уже обнаружили, если число посещений равно единице, то потребление булочек должно быть равно нулю. Поэтому исправим тестовый вариант и код.
Листинг 16.17. Лакомка.java
public Отчет создатьОтчет()
{
Отчет r = new Отчет();
double первыйЗамер = 0;
double последнийЗамер = 0;
double общаяСтоимость = 0;
double потреблениеБулочек = 0;
for (int i= 0; i< егоПосещения.size(); i++)
// проход по всем элементам контейнера посещений
{
ПосещениеКафе v = (ПосещениеКафе) егоПосещения.get(i);
// занести в v i-й элемент из контейнера посещений
if (i = = 0)
{
первыйЗамер = v. ПолучитьВес();
//занести в первыйЗамер вес при 1-м посещении
потреблениеБулочек -= v.получитьБулочки();
}
if (i= = егоПосещения.size()- 1) последнийЗамер =
v. получитьВес();
// занести в последнийЗамер вес при послед. посещении
общаяСтоимость += v.получитьСтоимость();
потреблениеБулочек += v.получитьБулочки();
}
double изменение = последнийЗамер – первыйЗамер;
r.устВесНаБулочку(изменение/потреблениеБулочек);
r.устИзменениеВеса(изменение);
r.устСтоимостьБулочек(общаяСтоимость);
r.устПотреблениеБулочекСпотреблениеБулочек);
return r;
}
Теперь попытаемся сделать функцию короче и понятнее. Переместим фрагменты кода так, чтобы их можно было вынести в отдельные функции.
Листинг 16.18 иллюстрирует промежуточный шаг в перемещении фрагментов кода. На пути к нему мы выполнили несколько более мелких шагов. Каждый из этих шагов тестировался. И вот теперь тесты стали завершаться успешно. Облегченно вздохнув, мы увидели, как можно улучшить код. Начнем с разбиения единственного цикла на два цикла.
ПосещениеКафе v = (ПосещениеКафе) егоПосещения.get(i);
общаяСтоимость += v.получитьСтоимость();
}
return общаяСтоимость;
}
private double вычПотреблениеБулочек()
{
double потреблениеБулочек = 0;
if (егоПосещения.size() > 0)
{
for (int i = 1; i < егоПосещения.size(); i++)
{
ПосещениеКафе v = (ПосещениеКафе)
егоПосещения.get(i);
потреблениеБулочек += v.получитьБулочки();
}
}
return потреблениеБулочек;
}
Заметим, что функция вычПотреблениеБулочек теперь суммирует потребление булочек, начиная со второго посещения. И опять выполняем тестирование. На следующем шаге выделим функцию для расчета изменения веса.
ПосещениеКафе v = (ПосещениеКафе) егоПосещения.get(i);
общаяСтоимость += v.получитьСтоимость();
}
return общаяСтоимость;
}
private double вычПотреблениеБулочек()
{
double потреблениеБулочек = 0;
if (егоПосещения.size() > 1)
{
for (int i = 1; i < егоПосещения.size(); i++)
{
ПосещениеКафе v = (ПосещениеКафе)
егоПосещения.get(i);
потреблениеБулочек += v.получитьБулочки();
}
}
return потреблениеБулочек;
}
После окончательного прогона тестов констатируем, что цель достигнута — код стал компактным и понятным, обязанности разнесены по отдельным функциям.
Таким образом, в рассмотренном подходе программа считается завершенной не тогда, когда она заработала, а когда она стала максимально простой и ясной.
Преимущества COM
В качестве кратких выводов отметим основные преимущества СОМ.
1. СОМ обеспечивает удобный способ фиксации услуг, предоставляемых разными фрагментами ПО.
2. Общий подход к созданию всех типов программных услуг в СОМ упрощает проблемы разработки.
3. СОМ безразличен язык программирования, на котором пишутся СОМ-объекты и клиенты.
4. СОМ обеспечивает эффективное управление изменением программ — замену текущей версии компонента на новую версию с дополнительными возможностями.
Б.Терминология языка UML и унифицированного процесса
В данном приложении приведен словарь основных терминов языка UML и унифицированного процесса разработки, описываемого в учебнике.
Словарь терминов
Абстрактный класс (abstract class)
Класс, объект которого не может быть создан непосредственно
Агрегат (aggregate)
Класс, описывающий «целое» в отношении агрегации
Агрегация (aggregation)
Специальная форма ассоциации, определяющая отношение «часть-целое» между агрегатом (целым) и частями
Актер (actor)
Связанный набор ролей, исполняемый пользователями при взаимодействии с элементами Use Case
Активация (activation)
Выполнение соответствующего действия
Активный класс (active class)
Класс, экземпляры которого являются активными объектами. См. процесс, задача, поток
Активный объект (active object)
Объект, являющийся владельцем процесса или потока, которые инициируют управляющую деятельность
Артефакт (artifact)
Документ, отчет или выполняемый элемент. Артефакт может вырабатываться, обрабатываться или потребляться
Асинхронное действие (asynchronous action)
Запрос, отправляемый объекту без паузы для ожидания результата
Ассоциация (association)
Семантическое отношение между классификаторами, задающее набор связей между их экземплярами
Бизнес-модель (business model)
Определяет абстракцию организации, для которой создается система
Бинарная ассоциация (binary association)
Ассоциация между двумя классами
Взаимодействие (interaction)
Поведение, заключающееся в обмене набором сообщений между набором объектов (в определенном контексте и для достижения определенной цели)
Видимость (visibility)
Показывает, как может быть увидено и использовано другими данное имя
Временный объект (transient object)
Объект, существующий только во время выполнения задачи или процесса, которые его создали
Действие (action)
Исполняемое атомарное вычисление. Действие инициируется при получении объектом сообщения или изменении значения его свойства. В результате действия изменяется состояние объекта
Делегирование (delegation)
Способность объекта посылать сообщение другому объекту в ответ на прием чужого сообщения
Деятельность (activity)
Состояние, в котором проявляется некоторое поведение
Диаграмма (diagram)
Графическое представление набора элементов, обычно
в виде связного графа, в вершинах которого находятся
предметы, а дуги представляют собой их отношения
Диаграмма Use Case (use case diagram)
Диаграмма, показывающая набор элементов Use Case,
актеров и их отношений. Диаграмма Use Case относится к статическому представлению Use Case, создаваемому для системы
Диаграмма взаимодействия (interaction diagram)
Диаграмма, показывающая взаимодействие, включающее в себя набор объектов и их отношений, а также пересылаемые между объектами сообщения. Диаграммы взаимодействия относятся к динамическому представлению системы. Это общий термин, применяемый к различным видам диаграмм, на которых изображено взаимодействие объектов, включая диаграммы сотрудничества и диаграммы последовательности
Диаграмма деятельности (activity diagram)
Диаграмма, показывающая переходы от одного вида деятельности к другому. Диаграммы деятельности относятся к динамическому представлению системы. Диаграмма деятельности является специальной разновидностью диаграммы схем состояний, в которой все или большинство состояний являются состояниями действий, а все или большинство переходов срабатывают при завершении действий в исходных состояниях
Диаграмма классов (class diagram)
Диаграмма, показывающая набор классов, интерфейсов, коопераций, а также их отношения. Диаграмма классов относится к статическому проектному представлению системы. Эта диаграмма показывает набор декларативных (статических) элементов
Диаграмма объектов (object diagram)
Диаграмма, показывающая набор объектов и их отношений в некоторый момент времени. Диаграмма объектов относится к статическому проектному представлению или статическому представлению процессов системы
Диаграмма последовательности (sequence diagram)
Диаграмма взаимодействия, выделяющая временную последовательность передачи сообщений
Диаграмма размещения (deployment diagram)
Диаграмма, показывающая набор узлов и их отношения. Диаграмма размещения относится к статическому представлению размещения системы
Диаграмма сотрудничества (collaboration diagram)
Диаграмма взаимодействия, которая выделяет структурную организацию объектов, посылающих и принимающих сообщения; диаграмма, которая демонстрирует организацию взаимодействия между экземплярами и их связи друг с другом
Диаграмма схем состояний (statechart diagram)
Диаграмма, показывающая конечный автомат. Диаграммы схем состояний относятся к динамическому представлению системы
Единица дистрибуции (distribution unit)
Набор объектов или компонентов, которые предназначены для выполнения одной задачи или работы на одном процессоре
Зависимость (dependency)
Семантическое отношение между двумя предметами, при котором изменение одного предмета (независимого предмета) влияет на семантику другого предмета (зависимого предмета)
Задача (task )
Единичный путь выполнения программы, динамической модели или другого представления потока управления; нить или процесс
Запустить (fire)
Выполнить переход из состояния в состояние
Иерархия вложенности (containment hierarchy)
Иерархия пространств имен, содержащих элементы и отношения вложенности между ними
Импорт (import)
В контексте пакетов — зависимость, показывающая, на классы какого пакета могут ссылаться классы данного пакета (включая пакеты, рекурсивно вложенные в данный)
Имя (name)
То, как вы называете предмет, отношение или диаграмму; строка, используемая для идентификации элемента
Интерфейс (interface)
Набор операций, используемых для описания услуг класса или компонента
Исполняемый модуль (executable)
Программа, которая может выполняться в узле
Использование (usage)
Зависимость, при которой один элемент (клиент) для корректного функционирования нуждается в присутствии другого элемента (поставщика)
Кардинальное число (cardinality)
Число элементов в наборе
Каркас (framework)
Архитектурный паттерн, предоставляющий расширяемый шаблон приложения в какой-либо предметной области
Класс (class)
Описание набора объектов, имеющих одинаковые свойства, операции, отношения и семантику
Класс-ассоциация (association class)
Элемент моделирования, имеющий одновременно характеристики класса и ассоциации. Класс-ассоциация может рассматриваться как ассоциация, имеющая также характеристики класса, или как класс, обладающий характеристиками ассоциации
Классификатор (classifier)
Механизм описания структурных и поведенческих характеристик. Классификаторами являются интерфейсы, классы, типы данных, компоненты и узлы
Клиент (client)
Классификатор, запрашивающий услуги у другого классификатора
Композит (composite)
Класс, связанный с одним или более классами отношением композиции
Композиция (composition)
Сильная форма агрегации, при которой время жизни частей и целого совпадают. Части не существуют отдельно и при удалении композита должны быть уничтожены
Компонент (component)
Физическая заменяемая часть системы, которая соответствует набору интерфейсов и обеспечивает реализацию набора интерфейсов
Компонентная диаграмма (component diagram)
Диаграмма, показывающая набор компонентов и их отношений. Компонентные диаграммы относятся к статическому компонентному представлению системы
Конечный автомат (state machine)
Поведение, которое определяется последовательностью состояний, через которые проходит объект в течение своей жизни в ответ на поступление сообщений, вместе с его реакцией на эти сообщения
Конкретный класс (concrete class)
Класс, для которого возможно создание экземпляров
Контейнер (container)
Объект, создаваемый для хранения других объектов и предоставляющий операции для доступа к своему содержимому в определенном порядке
Контекст (context)
Набор связанных элементов, ориентированных на достижение определенной цели, например, определение операции
Кооперация (collaboration)
Сообщество классов, интерфейсов и других элементов, работающих вместе с целью реализации некоторого кооперативного поведения. Кооперация больше, чем простая сумма элементов. Описание того, как элементы, такие как элементы Use Case или операции, реализуются набором классификаторов и ассоциаций, играющих определенные роли определенным образом
«Линия жизни» (lifeline)
См. линия жизни объекта
Линия жизни объекта (object lifeline)
Линия на диаграмме последовательности, которая отражает существование объекта в течение некоторого периода времени
Местоположение (location)
Место размещения компонента в узле
Метакласс (metaclass)
Класс, экземпляры которого являются классами
Метод (method)
Реализация операции. Определяет алгоритм или процедуру, обеспечивающую операцию.
Механизм расширения (extensibility mechanism)
Один из трех механизмов (стереотипы, теговые величины и ограничения), который может использоваться для контролируемого расширения UML
Семантическая вариация обобщения, в которой объект может принадлежать более чем одному классу
Множественное наследование (multiple inheritance)
Семантическая вариация обобщения, в которой тип может иметь более одного супертипа
Множественность (multiplicity)
Спецификация диапазона возможных кардинальных чисел набора
Модель (Model)
Семантически ограниченное абстрактное представление системы
Модель Use Case (Use case model)
Определяет функциональные требования к системе
Модель анализа (analysis model)
Интерпретирует требования к системе в терминах проектной модели
Модель области определения (domain model)
Фиксирует контекстное окружение системы
Модель процессов (process model)
Определяет параллелизм в системе и механизмы синхронизации
Модель размещения (deployment model)
Определяет аппаратную топологию, в которой исполняется система
Модель реализации
Определяет части, которые используются для сборки
(implementation model)
и реализации физической системы
Наследование (inheritance)
Механизм, при помощи которого более специализированные элементы включают в себя структуру и поведение более общих элементов
Наследование интерфейса (interface inheritance)
Наследование интерфейса более специализированным элементом, не включает наследования реализации
Нить (thread)
Облегченный поток управления, который может выполняться параллельно с другими нитями того же процесса
Область действия (scope)
Контекст, который придает имени определенный смысл
Обобщение (generalization)
Отношение обобщения/специализации, когда объекты специализированного элемента (подтипа) могут замещать объекты обобщенного элемента (супертипа)
Объект (object )
См. экземпляр
Объект длительного хранения (persistent object)
Объект, сохраняющийся после завершения процесса или задачи, в ходе которой он был создан
Объектный язык ограничений (object constraint language (OCL))
Формальный язык, используемый для создания ограничений, не имеющих побочных эффектов
Обязанность (responsibility)
Контракт или обязательство типа или класса
Ограничение (constraint)
Расширение семантики элемента UML, позволяющее добавлять к нему новые правила или изменять существующие
Одиночное наследование (single inheritance)
Семантический вариант обобщения, при котором каждый тип может иметь только один супертип
Операция (operation)
Обслуживание, которое может запрашиваться у объекта. Операция имеет сигнатуру, которая задает допустимые фактические параметры
Отношение (relationship)
Семантическая связь между элементами
Отношение трассировки (trace)
Зависимость, указывающая на историческую связь или связь обработки между двумя элементами, представляющими одну и ту же концепцию, без определения правил вывода одного элемента из другого
Отправитель (сообщения) (sender)
Объект, посылающий экземпляр сообщения объекту-получателю
Отправление (send)
Посылка экземпляра сообщения от отправителя получателю
Пакет (package)
Механизм общего назначения для группировки элементов
Параллелизм (concurrency)
Осуществление двух или более видов деятельности в один и тот же временной интервал. Параллелизм может быть осуществлен путем квантования процессорного времени или одновременного выполнения двух или более потоков
Параметр (parameter)
Определение переменной, которая может изменяться, передаваться или возвращаться
Паттерн (pattern)
Паттерн является решением типичной проблемы в определенном контексте
Переход (transition)
Отношение между двумя состояниями, показывающее, что объект, находящийся в первом состоянии, в случае некоторого события и выполнения определенных условий совершит некоторые действия и перейдет во второе состояние
Плавательная дорожка (swim lane)
Область на диаграмме деятельности для назначения ответственного за действие
Побуждение (stimulus)
Операция или сигнал
Подсистема (subsystem)
Группировка элементов, в которой каждый элемент содержит описание поведения, предоставляемого другим элементам подсистемы
Подтип (subtype)
В отношении обобщения — специализация другого типа, супертипа
Получатель (receiver)
Объект, обрабатывающий экземпляр сообщения, поступивший от объекта-отправителя
Полюс (конец) ассоциации (association end)
Конечная точка ассоциации, которая связывает ассоциацию с классификатором
Полюс (конец) связи (link end)
Экземпляр полюса (конца) ассоциации
Поставщик (supplier)
Тип, класс или компонент, предоставляющие услуги, используемые другими
Постусловие (postcondition)
Условие, которое должно выполняться после завершения операции
Представление (view)
Проекция модели, рассматриваемая с определенной точки зрения, в которой показаны существенные и опущены несущественные детали
Предусловие (precondition)
Условие, которое должно выполняться при вызове операции
Прием (receive)
Обработка экземпляра сообщения, поступившего от объекта — отправителя
Примечание (comment)
Примечание, добавляемое к элементу или группе элементов
Примечание (note)
Комментарий, добавляемый к элементу или набору элементов
Примитивный тип (primitive type)
Предопределенный базовый тип, например целое число или строка
Проектная модель (design model)
Определяет словарь проблемы и ее решение
Пространство имен (namespace)
Часть модели, в которой могут определяться и использоваться имена. Внутри пространства имен каждое имя имеет единственный смысл
Процесс (process)
Тяжеловесный поток управления, который может выполняться параллельно с другими процессами
Рабочий поток процесса (process workflow)
Логическая группировка действий
Реализация (realization)
Семантическое отношение между классификаторами, когда один классификатор определяет контракт, который другие классификаторы должны гарантированно выполнять
Роль (role)
Определенное поведение сущности в определенном контексте
Свойство (attribute)
Именованная характеристика классификатора, задающая набор возможных значений, которые определяют состояния экземпляров классификатора (например, объектов)
Связывание (binding)
Создание конкретного элемента на основе шаблона (путем сопоставления параметрам шаблона конкретных аргументов)
Связь (link)
Семантическая связь между объектами, экземпляр ассоциации
Сигнал (signal)
Спецификация асинхронного стимула, передаваемого от экземпляра к экземпляру
Сигнатура (signature)
Имя и параметры характеристики поведения
Синхронное действие (synchronous action)
Запрос, при работу, ожидая результата котором отправивший его объект прерывает
Система (system)
Набор подсистем, организованный для достижения определенной цели и описываемый набором моделей с разных точек зрения
Событие (event)
Определение значимого происшествия, ограниченного во времени и пространстве, в контексте конечных автоматов. Событие может запустить переход из одного состояния в другое состояние
Сообщение (message)
Спецификация передачи информации между объектами в ожидании того, что будет обеспечена требуемая деятельность. Получение экземпляра сообщения обычно рассматривается как экземпляр события
Состояние (state)
Условия или ситуация в течение жизни объекта, когда он удовлетворяет некоторому условию, выполняет некоторую деятельность или ждет некоторого события
Состояние действия (action state)
Состояние, которое представляет собой исполнение единичного действия, обычно вызов операции
Спецификация (specification)
Текстовая запись синтаксиса и семантики определенного строительного блока, описание того, что он из себя представляет или что он делает
Стереотип (stereotype)
Расширение словаря UML, позволяющее нам создавать новые типы строительных блоков, порождая их от существующих. Новые блоки специализированы для решения определенных проблем
Сторожевое условие (guard condition)
Условие, которое должно быть выполнено для запуска ассоциированного с ним перехода
Супертип (supertype)
В отношении обобщения — обобщение другого типа, подтипа
Сценарий (scenario)
Определенная последовательность действий, иллюстрирующая поведение
Теговая величина (tagged value)
Расширение характеристик элемента UML, позволяющее помещать в спецификацию элемента новую информацию
Тестовая модель (test model)
Определяет тестовые варианты для проверки системы
Тип (type)
Стереотип класса, используемый для определения предметной области объекта и операций (но не методов), применимых к этому объекту
Тип данных (datatype)
Тип, задающий набор неидентифицированных значений и операций для их обработки. Типы данных включают в себя как простые встроенные типы (такие, как числа и строки), так и перечислимые типы (например, логический тип)
Узел (node)
Физический элемент, существующий во время работы системы и предоставляющий вычислительный ресурс, обычно имеющий память, а часто — и возможность выполнения операций
Украшение (adornment)
Детализация спецификации элемента, добавляемая к его основной графической нотации
Фасад (facade)
Фасад — это стереотипный пакет, не содержащий ничего, кроме ссылок на элементы модели, находящиеся в другом пакете. Он используется для обеспечения «публичного» представления некоторой части содержимого пакета
Фокус управления (focus of control)
Символ на диаграмме последовательности, указывающий период времени, в течение которого объект выполняет действие
Конкретная реализация абстракции, сущность, к которой может быть применен набор операций, она имеет состояние для сохранения результатов применения операций. Синоним объекта
Экспорт (export)
В контексте пакетов — действие, делающее элемент видимым вне его собственного пространства имен
Элемент (element)
Единичная составная часть модели
Этап Конструирование (Construction phase)
Этап построения программного продукта в виде серии инкрементных итераций
Этап Начало (Inception phase)
Этап спецификации представления продукта
Этап Переход (Transition phase)
Этап внедрения программного продукта в среду пользователя (промышленное производство, доставка и применение)
Этап Развитие (Elaboration phase)
Этап планирования необходимых действий и требуемых ресурсов
n-арная ассоциация (n-ary association)
Ассоциация между п классами. Если п равно двум, ассоциация бинарная. См. бинарная ассоциация
Элемент Use Case (use case)
Описание набора, состоящего из нескольких последовательностей действий системы, которые производят для отдельного актера видимый результат
современный язык программирования, имеющий максимальный
Ada 95 — современный язык программирования, имеющий максимальный набор средств описания данных и действий. Его средства обеспечивают все технологические потребности профессионального.программирования. Конструкции языка поддерживают как традиционный, императивный стиль программирования, так и объектно-ориентированный стиль, позволяют создавать как последовательные, так и параллельные процессы.
Типы и объекты данных
Тип данных задает набор возможных значений и набор операций, допустимых над этими значениями. Все типы данных Ada 95 разделяют на две большие группы: элементарные и составные. Данные элементарного типа имеют значения, которые логически неразделимы. Данные составного типа имеют значения, которые составлены из значений компонентов.
В свою очередь, элементарные типы делят на скалярные типы (дискретные и вещественные) и ссылочные типы (чьи значения являются указателями на данные и подпрограммы). Дискретные типы включают целые типы (знаковые и беззнаковые) и перечисляемые типы. Вещественные типы включают типы с плавающей точкой и типы с фиксированной точкой (двоичные и десятичные).
Составные типы данных подразделяются на комбинированные типы (записи), расширения типа запись, регулярные типы (массивы), задачные типы, защищенные типы. Задачные и защищенные типы используются при программировании параллельных процессов.
Описание типа приводится в декларативной части программы. Общая форма объявления типа имеет вид
type <ИмяТипа> is <ОпределениеТипа>;
где в угловых скобках указывается название, которое в реальной программе заменяется конкретной конструкцией (именем, выражением, оператором).
Приведем примеры объявления типов:
q целый знаковый тип
type Temperature is range -70..70:
q модульный целый тип
type Time_of_Day is mod 86400;
type Day_of_Month is mod 32;
q вещественный тип с плавающей точкой — задает значения, представляемые восемью десятичными цифрами
type Distance is digits 8;
q двоичный вещественный тип с фиксированной точкой — задает значения с погрешностью 0,001 в диапазоне от 0.00 до 200.00
type Price is delta 0.001 range 0.00 ..200.00;
q десятичный вещественный тип с фиксированной точкой — задает значения, представляемые восемью десятичными цифрами с погрешностью 0,1 (то есть значения до 9999999,9)
type Miles is delta 0.1 digits 8;
q перечисляемый тип
type Day is ( mon. tue. wed, thu. fri. sat. sun );
type Colour is ( red. blue, green, black );
q тип записи
type Date_Type is
record
Day : Day_Type;
Month : Month_Day;
Year : Year_Type;
end record;
q тип массива
type Week is array ( 1 .. 7 ) of Day:
Некоторые типы в языке предопределены. Предопределенные типы не нужно объявлять в декларативной части программы. К ним относятся:
q целый тип Integer с диапазоном значений -32 767...+32 768;
q вещественный тип с плавающей точкой Float;
q перечисляемые типы Boolean (логический), Character (символьный);
q регулярный тип String (задает массивы из элементов символьного типа).
После того как тип объявлен, можно объявлять экземпляры этого типа. Экземпляры типов называются объектами. Объекты содержат значения. Значения объектов-переменных могут изменяться, значения объектов-констант постоянны.
где в квадратных скобках указаны необязательные элементы, а НачальноеЗначение — некоторое выражение соответствующего типа.
Примеры объявлений объектов-переменных:
q символьный объект с начальным значением
Symbol : Character :- 'A';
ПРИМЕЧАНИЕ
Значение символьного объекта записывается в апострофах.
q строковый объект с начальным значением
Name : String ( 1 .. 9 ) := "Aleksandr";
ПРИМЕЧАНИЕ
Значение строкового объекта записывается в кавычках.
q объект перечисляемого типа
Car_Colour : Colour := red;
q объект модульного типа
Today : Day_of_Month := 31;
ПРИМЕЧАНИЕ
Значение этого объекта может изменяться в диапазоне от 0 до 31. К модульному типу применяется модульная арифметика, поэтому после оператора Today := Today + 1 объект Today получит значение 0.
Примеры объявлений объектов-констант:
Time : constant Time_of_Day := 60;
Best_Colour : constant Colour := blue;
Отметим, что если константа является именованным числом (целого и вещественного типа), то имя типа можно не указывать:
Minute : constant := 60;
Hour : constant := 60 * Minute;
Текстовый и числовой ввод-вывод
Ada 95 — это язык для разработки программ реального мира, программ, которые могут быть очень большими (включать сотни тысяч операторов). При этом желательно, чтобы отдельный программный файл имел разумно малый размер. Для обеспечения такого ограничения Ada 95 построена на идее библиотек и пакетов. В библиотеку, составленную из пакетов, помещаются программные тексты, предназначенные для многократного использования.
Пакеты ввода-вывода
Пакет подключается к программе с помощью указания (спецификатора) контекста, имеющего вид
with <Имя_Пакета>;
Размещение в пакетах процедур ввода-вывода (для величин предопределенных типов) иллюстрирует табл. В.1.
Таблица В.1. Основные пакеты ввода-вывода
Имя пакета
Тип вводимых-выводимых величин
Ada.Text_IO
Ada.lnteger_Text_IO
Ada.Float_Text_IO
Character, String
Integer
Float
Для поддержки ввода-вывода величин других типов, определяемых пользователем, используются шаблоны (заготовки) пакетов — родовые пакеты.
Родовой пакет перед использованием должен быть настроен на конкретный тип.
Как показано в табл. В.2, родовые пакеты ввода-вывода всегда находятся внутри пакета-библиотеки Ada.Text_IO.
Таблица В.2. Внутренние пакеты из пакета-библиотеки Ada.Text_IO
Имя родового пакета
Нужна настройка на тип
Integer_IO
Float_IO
Enumeration_IO
Fixed_IO
Decimal_IO
Modular_IO
Любой целый тип со знаком
Любой вещественный тип с плавающей точкой
Любой перечисляемый тип
Любой двоичный вещественный тип с фиксированной точкой
Любой десятичный вещественный тип с фиксированной точкой
Любой целый тип без знака
Для обращения к внутренним родовым пакетам используют составные имена, например Ada.Text_IO.Modular_IO, Ada.Text_IO.Enumeration _IO.
Процесс настройки родового пакета называют конкретизацией. В результате конкретизации образуется экземпляр родового пакета. Экземпляр помещается в библиотеку и может быть подключен к любой программе.
Конкретизация задается предложением следующего формата:
with <Полное имя родового пакета>;
package <Имя пакета-экземпляра> is
new <Имя родового пакета> (<Имя типа настройки>);
Например, введем перечисляемый тип:
Type Summer is ( may. jun, jul. aug );
Создадим экземпляр пакета для ввода-вывода величин этого типа:
with Ada.Text_IO.Enumeration_IO;
package Summer_IO is new Ada.Text_IO.Enumeration_IO (Summer);
Теперь пакет SummerJO может использоваться в любой программе.
Процедуры ввода
Формат вызова процедуры:
<ИмяПакета> . Get (<ФактическиеАргументы>);
Например, для ввода величины типа Character записывается оператор вызова
Ada.Text_IO.Get (Var);
В результате переменной Var (типа Character) присваивается значение символа, введенного с клавиатуры. Пробел считается символом, нажатие на клавишу Enter не учитывается.
Еще один пример оператор вызова:
Ada.Integer_Text_IO.Get (Var2);
В этом случае в переменную Var2 типа Integer заносится строка числовых символов.
Все ведущие пробелы и нажатия на клавишу Enter игнорируются. Первым символом, отличным от пробела, может быть знак +, - или цифра. Строка данных прекращается при вводе нечислового символа или нажатии на клавишу Enter.
Процедуры вывода
В операторе вызова можно указывать не только фактические параметры, но и сопоставления формальных и фактических параметров в виде
При такой форме порядок записи параметров безразличен.
Например, по оператору вызова
Ada.Text_IO.Put ( Item => Var3 )
значение переменной Var3 (типа Character) отображается на дисплее, а курсор перемещается в следующую позицию.
По оператору вызова
Ada.Integer_Text_IO.Put ( Var4. Width => 4 )
на экране отображается значение целой переменной Var4, используются текущие Width позиций (в примере — 4). Если значение (включая знак) занимает меньше, чем Width, позиций, ему предшествует соответствующее количество пробелов. Если значение занимает больше, чем Width, позиций, то используется реальное количество позиций. Если параметр Width пропущен, то используется ширина, заданная компилятором по умолчанию.
Основные операторы
Оператор присваивания
<ИмяПеременной> := <Выражение>;
предписывает: вычислить значение выражения и присвоить это значение переменной, имя которой указано в левой части.
Условный оператор
if <условие 1> then
<последовательность операторов 1>
elsif <условие 2> then
<последовательность операторов 2>
else
последовательность операторов 3>
end if;
обеспечивает ветвление — выполнение операторов в зависимости от значения условий.
ПРИМЕЧАНИЕ
Возможны сокращенные формы оператора (отсутствует ветвь elsif, ветвь else).
Оператор выбора позволяет сделать выбор из произвольного количества вариантов, имеет вид
case < выражение > is
when <список выбора 1> =>
<последовательность операторов 1>
…
when <список выбора n> =>
<последовательность операторов n>
when others =>
<последовательность операторов n+1>
end case;
Порядок выполнения оператора:
1) вычисляется значение выражения;
2) каждый список выбора ( от первого до последнего) проверяется на соответствие значению;
3) если найдено соответствие, то выполняется соответствующая последовательность операторов, после чего происходит выход из оператора case;
4) если не найдено соответствие, то выполняются операторы, указанные после условия when others.
Элементы списка выбора отделяются друг от друга вертикальной чертой ('|') и могут иметь следующий вид:
q <выражение>;
q <выражение n>..<выражение m>.
Примеры:
case Number is
when 1 | 7 => Put ("Is 1 or 7");
when 5 => Put ("Is 5");
when 25..100 => Put ("Is number between 25 and 100");
when others => Put ("Is unknown number");
end case;
case Answer is
when 'A'..'Z' | 'a'..'z' => Put_Line ("It's a letter!");
when others => Put_Line ("It's not a letter!")
end case;
Оператор блока объединяет последовательность операторов в отдельную структурную единицу, имеет вид
declare
<последовательность объявлений>
begin
<последовательность операторов>
end;
ПРИМЕЧАНИЕ
Объявления из раздела declare действуют только внутри раздела операторов блока.
Пример:
declare
Ch : Character;
begin
Ch := 'A';
Put ( Ch );
end;
Операторы цикла
Оператор цикла loop
loop
<последовательность операторов 1>
exit when <условие выхода>
<последовательность операторов 2>
end loop;
служит для организации циклов с заранее неизвестным количеством повторений.
Порядок выполнения.
1. Выполняется последовательность операторов 1.
2. Вычисляется значение условия выхода. Если значение равно True, происходит выход из цикла.
3. Выполняется последовательность операторов 2. Осуществляется переход к пункту 1.
ПРИМЕЧАНИЕ
Операторы тела повторяются, пока условие равно False. В теле должен быть оператор, влияющий на значение условия, иначе цикл будет выполняться бесконечно. В теле цикла возможно использование безусловного оператора выхода exit или условного оператора выхода exit when <условие>.
Пример:
Count := 1;
loop
Ada.Integer_Text_IO.Put ( Count );
exit when Count = 10;
Count := Count + 1;
end loop:
При выполнении цикла на экран выводится:
12345678910
Аналогичные вычисления можно задать в следующем виде:
Count := 1
loop
Ada.Integer_Text_IO.Put ( Count );
if Count = 10 then
exit;
end if;
Count := Count + 1;
end loop;
Оператор цикла while также позволяет определить цикл с заранее неизвестным количеством повторений, имеет вид
while <условие продолжения> loop
<последовательность операторов>
end loop;
Порядок выполнения.
1. Вычисляется значение условия. Если значение равно True, выполняется переход к пункту 2. В противном случае (при значении False) происходит выход из цикла.
2. Выполняются операторы тела цикла. Осуществляется переход к пункту 1.
Таким образом, это цикл с предусловием.
Перечислим характерные особенности оператора while.
1. Операторы тела могут выполняться нуль и более раз.
2. Операторы тела повторяются, пока условие равно True.
3. В теле должен быть оператор, влияющий на значение условия (для исключения бесконечного повторения).
Пример:
Count :=1;
loop
while Count <= 10 loop
Put ( Count ):
Count := Count + 1;
end loop;
При выполнении цикла на экран выводится:
12345678910
Оператор цикла for обеспечивает организацию циклов с известным количеством повторений. Используются две формы оператора.
Первая форма оператора for имеет вид:
for <параметр цикла> in <дискретный диапазон> loop
<операторы тела цикла>
end loop;
Параметр цикла — это переменная, которая заранее не описывается (в программе). Данная переменная определена только внутри оператора цикла. Параметру цикла последовательно присваиваются значения из дискретного диапазона. Дискретный диапазон всегда записывается в порядке возрастания в виде
min .. max;
Операторы тела повторяются для каждого значения параметра цикла (от минимального до максимального).
Пример:
for Count in 1 .. 10 loop
Put ( Count );
end loop;
При выполнении цикла на экран выводится:
1 2 3 4 5 б 7 8 9 10
Вторая форма оператора for имеет вид
for <параметр цикла> in reverse <дискретный диапазон> loop
<операторы тела цикла>
end loop;
Отличие этой формы состоит в том, что значения параметру присваиваются в порядке убывания (от максимального к минимальному). Диапазон же задается по-прежнему, в порядке возрастания.
Пример:
for Count in reverse 1 .. 10 loop
Put ( Count );
end loop;
При выполнении цикла на экран выводится:
10987654321
ПРИМЕЧАНИЕ
Операторы exit и exit when могут использоваться и в операторах цикла while, for.
Основные программные модули
Ada-программа состоит из одного или нескольких программных модулей. Программным модулем Ada 95 является:
q подпрограмма — определяет действия — подпроцесс (различают две разновидности: процедуру и функцию);
q пакет — определяет набор логически связанных описаний объектов и действий, предназначенных для совместного использования;
q задача — определяет параллельный, асинхронный процесс;
q защищенный модуль — определяет защищенные данные, разделяемые между несколькими задачами;
q родовой модуль — настраиваемая заготовка пакета или подпрограммы.
Родовой модуль имеет формальные родовые параметры, обеспечивающие его настройку в период компиляции. Родовыми параметрами могут быть не только элементы данных (объекты), но и типы, подпрограммы, пакеты.
Поэтому общие модули, рассчитанные на использование многих типов данных, следует оформлять как родовые.
Как правило, модули можно компилировать отдельно. Обычно в модуле две части:
q спецификация (содержит сведения, видимые из других модулей);
q тело (содержит детали реализации, невидимые из других модулей).
Спецификация и тело также могут компилироваться отдельно. Все это дает возможность проектировать, кодировать и тестировать программу как набор слабо зависимых модулей.
Функции
Функция — разновидность подпрограммы, которая возвращает значение результата.
Спецификация функции имеет вид
function <ИмяФункции> (<СписокФормальныхПараметров>)
return <ТипРезультата>;
Список формальных параметров объявляет аргументы, которые принимает функция. Элементы списка отделяются друг от друга точкой с запятой. Каждый элемент (формальный параметр) записывается в виде
function Box_Area (Depth : Float; Width : Float) return Float;
Тело функции включает спецификацию функции, объявления локальных переменных и констант, а также раздел исполняемых операторов. В общем случае тело функции имеет вид
function <ИмяФункции> (<СписокФормальныхПараметров>)
function Box_Area (Depth : Float; Width ; Float) return Float is
Result : Float;
begin
Result := Depth * Width;
return Result: -- возврат вычисленного значения
end Box_Area;
Описание тела функции само по себе действий не производит. Для выполнения функции необходимо ее вызвать. Чтобы вызвать функцию, записывают ее имя и список фактических параметров, запись помещается в правую часть оператора присваивания:
Таким образом, вызов функции является элементом выражения. Фактические параметры в списке вызова отделяются друг от друга запятой.
Пример вызова:
Му_Вох := Вох_Агеа ( 2.0. 4.15 );
Фактические параметры задают фактические значения, то есть значения, обрабатываемые при выполнении функции.
Процедуры
Процедуры, в отличие от функций, не возвращают результат в точку вызова. Спе цификация процедуры задает минимальный набор сведений, необходимый для клиентов процедуры. Она имеет вид
Для записи каждого формального параметра принят следующий формат:
<Имя> : <Вид> <Тип данных>;
где <Вид> указывает направление передачи информации между формальным и фактическим параметрами (in — передача из фактического в формальный параметр, out — из формального в фактический параметр, in out — двунаправленная передача).
ПРИМЕЧАНИЕ
Пометку in разрешается не указывать (она подразумевается по умолчанию), поэтому в спецификации функции вид параметра отсутствует. Для формального параметра вида in разрешается задавать начальное значение, присваиваемое по умолчанию.
Пример спецификации:
procedure Sum ( Opl : in Integer := 0; Op2 : in Integer := 0;
Op3 : in Integer := 0: Res : out Integer );
Тело процедуры в общем случае имеет вид
procedure <ИмяПроцедуры>
(<СписокФормальныхПараметров>) is
<объявления локальных переменных и констант>
begin
<операторы>
end <ИмяПроцедуры>;
Пример тела:
procedure Sum ( Opl : in Integer := 0; Op2 : in Integer := 0;
Op3 : in Integer := 0: Res : out Integer ) is
begin
Res := Opl + Op2;
Res := Res + Op3;
end Sum;
В данной процедуре три формальных параметра имеют значения по умолчанию. Это дает интересные возможности.
Обращаются к процедуре с помощью оператора вызова, он имеет вид
<ИмяПроцедуры> (<СписокФактическихПараметров>);
Примеры операторов вызова:
Sum (4. 8, 12. d); -- переменная d получит значение 24
Sum (4. 8. Res => d); -- переменная d получит значение 12
ПРИМЕЧАНИЕ
В первом операторе вызова задано 4 фактических параметра, во втором операторе — 3 фактических параметра. Во втором операторе использованы как традиционная (позиционная) схема, так и именная схема сопоставления формального и фактического параметров.
Пакеты
Пакет — основное средство для поддержки многократности использования программного текста. При проектировании программ пакеты позволяют применить подход клиент-сервер. Пакет действует как сервер, который предоставляет своим клиентам (программам и другим пакетам) набор услуг.
Спецификация пакета объявляет предлагаемые услуги, а тело содержит реализацию этих услуг.
Спецификация пакета записывается в виде
package <ИмяПакета> is
<объявления типов, переменных, констант>
<спецификации процедур и функций>
end <ИмяПакета>;
Пример спецификации:
package Рисование is
type Точка is array ( 1 .. 2 ) of Integer;
-- описание точки в прямоугольной системе координат
procedure Переход ( из : in Точка; в : in Точка );
-- переход из одной точки в другую точку
procedure Рисовать_Линию (от : in Точка; до : in Точка );
-- рисуется сплошная линия между заданными точками
procedure Рисовать_Пунктирную_Линию (от : in Точка: до ; in Точка );
-- рисуется пунктирная линия
end Рисование;
Данная спецификация предлагает клиентам один тип данных и три процедуры.
Еще раз отметим, что содержание тела пакета клиентам недоступно.
Пример тела:
package body Рисование is
-- локальные объявления
procedure Переход ( из : in Точка: в : in Точка ) is
-- локальные объявления
begin
-- операторы
end Переход;
procedure Рисовать_Линию(от : in Точка: до ; in Точка) is
-- локальные объявления
begin
-- операторы
end Рисовать_Линию;
procedure Рисовать_Пунктирную_Линию ( от : in Точка;
до : in Точка ) is
-- локальные объявления
begin
-- операторы
end Рисовать_Пунктирную_Линию;
end Рисование:
В спецификации пакета может быть полузакрытая (приватная) часть. Эта часть отделяется от обычной (открытой) части служебным словом private. Содержимое приватной части пользователю (клиенту) недоступно. В эту часть помещают скрываемые от пользователя операции и детали описания типов данных. Заметим, что из тела пакета доступно содержание как открытой, так и приватной части спецификации.
Производные типы
Объявление производного типа имеет вид
type <ИмяПроизводногоТипа> is
new <ИмяРодительскогоТипа> [<ОграничениеРодительскогоТипа>];
где ограничение на значения родительского типа могут отсутствовать.
Производный тип наследует у родительского-типа его значения и операции. Набор родительских значений наследуется без права изменения. Наследуемые операции, называемые примитивными операциями, являются подпрограммами, имеющими формальный параметр или результат родительского типа и объявленными в том же пакете, что и родительский тип.
В заголовке каждой из унаследованных операций выполняется автоматическая замена указаний родительского типа на указания производного типа.
Например, пусть сделаны объявления:
type Integer is …; -- определяется реализацией
function "+" ( Left. Right : Integer ) return Integer;
Тогда любой тип, производный от Integer, вместе с реализацией родительского типа автоматически наследует функцию «+»:
type Length is new Integer;
-- function "+" ( Left. Right : Length ) return Length;
Здесь символ комментария (--) показывает, что операция «+» наследуется автоматически, то есть от программиста не требуется ее явное объявление. Любая из унаследованных операций может быть переопределена, то есть может быть обеспечена ее новая реализация. О такой операции говорят, что она перекрыта:
type Угол is new Integer;
function "+" ( Left. Right : Угол ) return Угол;
В этом примере для функции «+» обеспечена новая реализация (учитывается модульная сущность сложения углов).
По своей сути производный тип — это новый тип данных со своим набором значений и операций, а также со своей содержательной ролью. По значениям, операциям производный тип несовместим ни с родительским типом, ни с любым другим типом, производным от этого же родителя.
По сравнению с родительским типом в производном типе:
q набор значений может быть сужен (за счет ограничений при объявлении);
q набор операций может быть расширен (за счет объявления операций в определяющем для производного типа пакете).
Примеры объявления производных типов:
type Год Is new Integer range 0 .. 2099;
type Этаж i s new Integer range 1 .. 100;
Если теперь мы введем два объекта:
А : Год;
В : Этаж;
и попытаемся выполнить присваивание
А := В;
то будет зафиксирована ошибка.
Подтипы
Очень часто для повышения надежности программы приходится ограничивать область значений типов и объектов, не затрагивая при этом допустимые операции. Для такого ограничения удобно использовать понятие подтипа.
Подтип — это сочетание типа и ограничения на допустимые значения этого типа. Объявление подтипа имеет вид
subtype <ИмяПодтипа> is <ИмяТипа> range <Ограничение>;
Характерные особенности подтипов:
q подтип наследует все операции, которые определены для его типа;
q объект подтипа совместим с любым объектом его типа, удовлетворяющим указанному ограничению;
q содержательные роли объектов различных подтипов для одного типа аналогичны.
Таким образом, объекты типа и его подтипов могут свободно смешиваться в арифметических операциях, операциях сравнения и присваивания.
Например, если в программе объявлен перечисляемый тип День_Недели, то можно объявить подтип
subtype Рабочий_День is День_Недели range ПОНЕДЕЛЬНИК..ПЯТНИЦА;
При этом гарантируется, что объекты подтипа Рабочий_День будут совместимы с объектами типа День_Недели.
Расширяемые типы
Основная цель расширяемых типов — обеспечить повторное использование существующих программных элементов (без необходимости перекомпиляции и перепроверки). Они позволяют объявить новый тип, который уточняет существующий родительский тип наследованием, изменением или добавлением как существующих компонентов, так и операций родительского типа. Иначе говоря, идея расширяемого типа — это развитие идеи производного типа. В качестве расширяемых типов используются теговые типы (разновидность комбинированного типа).
Рассмотрим построение иерархии геометрических объектов. На вершине иерархии точка, имеющая два свойства (координаты X и Y):
type Точка Is tagged
record
Х_КоорД : Float;
Y_Koopfl : Float;
end record;
Другие типы объектов можно произвести (прямо или косвенно) от этого типа.
Например, можно ввести новый тип, наследник точки:
type Окружность is new Точка with -- новый теговый тип;
record
Радиус : Float;
end record;
Данный тип имеет три свойства: два свойства (координаты X и Y) унаследованы от типа Точка, а третье свойство (Радиус) нами добавлено. Дочерний тип Окружность наследует все операции родительского типа Точка, причем некоторые операции могут быть переопределены. Кроме того, для дочернего типа могут быть введены новые операции.
диаграммы Use Case
Наибольшие трудности при построении диаграмм Use Case вызывает применение отношений включения и расширения. Очень важно разобраться в отличительных особенностях этих отношений, специфике взаимодействия элементов Use Case, соединяемых с их помощью.
Пример диаграммы Use Case, в которой использованы отношения включения и расширения, приведен на рис. 12.35.
В этой диаграмме один базовый элемент Use Case Сеанс банкомата, который взаимодействует с актером Клиент. К базовому элементу Use Case подключены два расширяющих элемента Use Case (Состояние, Снять) и два включаемых элемента Use Case (Идентификация клиента, Проверка счета). В свою очередь, к элементу Use Case Идентификация клиента подключен включаемый элемент Use Case Проверить достоверность, а к элементу Use Case Снять — расширяющий элемент Use Case Захват карты (он же расширяет элемент Use Case Проверить достоверность).
Видим, что элемент Use Case Сеанс банкомата имеет две точки расширения (диалог возможен, выдача квитанции), а элементы Use Case Снять и Проверить достоверность — по одной точке расширения (проверка снятия и проверка соответственно). В точки расширения возможна вставка поведения из расширяющего элемента Use Case. Вставка происходит, если выполняется условие расширения:
q для расширяющего элемента Use Case Состояние — это условие запрос состояния;
q для расширяющего элемента Use Case Снять — это условие запрос снятия;
q для расширяющего элемента Use Case Захват карты — это условие список подозрений.
Рис. 12.35. Использование включения и расширения
Для расширяемого (базового) элемента Use Case эти условия являются внешними, то есть формируемыми вне его. Иными словами, элементу Use Case Сеанс банкомата ничего не известно об условиях запрос состояния и запрос снятия, а элементам Use Case Снять и Проверить достоверность — об условии список подозрений. Условия расширения являются следствиями событий, происходящих во внешней среде.
Стрелки расширения в диаграмме подписаны. Помимо стереотипа, здесь указаны:
q в круглых скобках — имена точек расширения;
q в квадратных скобках — условие расширения.
Описание расширяющего элемента Use Case разделено на сегменты, каждый сегмент обслуживает одну точку расширения базового элемента Use Case.
Количество сегментов расширяющего элемента Use Case равно количеству точек расширения базового элемента Use Case. Первый сегмент расширяющего элемента Use Case начинается с условия расширения, условие записывается только один раз, его действие распространяется и на все остальные сегменты.
Поведение базового элемента Use Case задается внутренним потоком событий, вплоть до точки расширения. В точке расширения возможно выполнение расширяющего элемента Use Case, после чего возобновляется работа внутреннего потока.
Спецификации элементов Use Case рассматриваемой диаграммы имеют следующий вид:
Элемент Use Case Сеанс банкомата
include (Идентификация клиента)
include (Проверка счета)
(диалог возможен)
напечатать заголовок квитанции
(выдача квитанции)
конец сеанса
//включение
//включение
//первая точка расширения
//вторая точка расширения
Расширяющий элемент Use Case Состояние
сегмент
//начало первого сегмента
принять запрос состояния
//условие расширения
отобразить информацию о состоянии счета
сегмент
//вторая точка расширения
конец сеанса
Расширяющий элемент Use Case Снять
сегмент
//начало первого сегмента
принять запрос снятия
//условие расширения
определить сумму
(проверка снятия)
//точка расширения
сегмент
//начало второго сегмента
напечатать снимаемую сумму
выдать наличные деньги
Расширяющий элемент Use Case Захват карты
сегмент
принять список подозрений
проглотить карту
конец сеанса
//начало единственного сегмента
//условие расширения
<
Включаемый элемент Use Case Идентификация клиента
получить имя клиента
include (Проверить достоверность)
получить номер счета клиента
//включение
Включаемый элемент Use Case Проверка счета
установить соединение с базой данных счетов
получить состояние и ограничения счета
Включаемый элемент Use Case Проверить достоверность
установить соединение с базой данных клиентов
получить параметры клиента
(проверка) //точка расширения
Опишем возможное поведение модели, задаваемое этой диаграммой.
Актер Клиент инициирует действия базового элемента Use Case Сеанс банкомата. На первом шаге запускается включаемый элемент Use Case Идентификация клиента. Этот элемент Use Case получает имя клиента и запускает элемент Use Case Проверить достоверность, в результате чего устанавливается соединение с базой данных клиентов и получаются параметры клиента.
Если к этому моменту исполняется условие расширения список подозрений, то «срабатывает» расширяющий элемент Use Case Захват карты, карта арестовывается и работа системы прекращается.
В противном случае происходит возврат к элементу Use Case Идентификация клиента, который получает номер счета клиента и возвращает управление базовому элементу Use Case.
Базовый элемент Use Case переходит ко второму шагу работы — вызывает включаемый элемент Use Case Проверка счета, который устанавливает соединение с базой данных счетов и получает состояние и ограничения счета.
Управление опять возвращается к базовому элементу Use Case. Базовый элемент Use Case переходит к первой точке расширения диалог возможен. В этой точке возможно подключение одного из двух расширяющих элементов Use Case.
Положим, что к этому моменту выполняется условие расширения запрос состояния, поэтому запускается первый сегмент элемента Use Case Состояние. В результате отображается информация о состоянии счета и управление передается базовому элементу Use Case. В базовом элементе Use Case печатается заголовок квитанции и обеспечивается переход ко второй точке расширения выдача квитанции. Поскольку в активном состоянии продолжает находиться расширяющий элемент Use Case Состояние, запускается его второй сегмент — в квитанции печатается информация о состоянии счета.
В последний раз управление возвращается к базовому элементу Use Case — завершается сеанс работы банкомата.
Пример объектно-ориентированной разработки
Для иллюстрации унифицированного процесса рассмотрим фрагмент разработки, выполненной автором совместно с Ольвией Комашиловой. Поставим задачу — разработать оконный интерфейс пользователя, который будет использоваться прикладными программами.
Примеры диаграмм классов
В качестве первого примера на рис. 11.17 показана диаграмма классов системы управления полетом летательного аппарата.
Рис. 11.17. Диаграмма классов системы управления полетом
Здесь представлен класс ПрограммаПолета, который имеет свойство ТраекторияПолета, операцию-модификатор ВыполнятьПрограмму () и операцию-селектор ПрогнозОкончУправления (). Имеется ассоциация между этим классом и классом Контроллер СУ — экземпляры программы задают параметры движения, которые должны обеспечивать экземпляры контроллера.
Класс Контроллер СУ — агрегат, чьи экземпляры включают по одному экземпляру классов Регулятор скорости и Регулятор углов, а также по шесть экземпляров класса Датчик. Экземпляры Регулятора скорости и Регулятора углов включены в агрегат физически (с помощью отношения композиция), а экземпляры Датчика — по ссылке, то есть экземпляр Контроллера СУ включает лишь указатели на объекты-датчики. Регулятор скорости и Регулятор углов — это подклассы абстрактного суперкласса Регулятор, который передает им в наследство абстрактные операции Включить ( ) и Выключить (). В свою очередь, класс Регулятор использует конкретный класс Порт.
Как видим, ассоциация имеет имя (Определяет полет), роли участников ассоциации явно указаны (Сервер, Клиент). Отношения композиции также имеют имена (Включать), причем на эти отношения наложено ограничение — контроллер не может включать Регулятор скорости и Регулятор углов одновременно.
Для класса Контроллер СУ задано ограничение на множественность — допускается не более трех экземпляров этого класса. Класс Регулятор скорости имеет ограничение другого типа — повторное включение его экземпляра разрешается не раньше, чем через 64 мс.
В качестве второго примера на рис. 11.18 приведена диаграмма классов для информационной системы театра. Эту систему образует 6 классов.
Классы-агрегаты Театр и Труппа имеют операции добавления и удаления своих частей, которые включаются в агрегаты по ссылке. Частями Театра являются Зрители и Труппы, а частями Труппы — Актеры.
Отношения агрегации между классом Театр и классами Труппа и Зритель слегка отличны. Театр может состоять из одной или нескольких трупп, но каждая труппа находится в одном и только одном театре. С другой стороны, в театр может ходить любое количество зрителей (включая нулевое количество), причем зритель может посещать один или несколько театров.
Между классами Труппа и Актер существуют два отношения — агрегация и ассоциация. Агрегация показывает, что каждый актер работает в одной или нескольких труппах, а в каждой труппе должен быть хотя бы один актер. Ассоциация отображает, что каждой труппой управляет только один актер — художественный руководитель, а некоторые актеры не являются руководителями.
Ассоциация между классами Спектакль и Актер фиксирует, что в спектакле должен быть занят хотя бы один актер, впрочем, актер может играть в любом количестве спектаклей (или вообще может ничего не играть).
Между классами Спектакль и Зритель тоже определена ассоциация. Она поясняет, что зритель может смотреть любое число спектаклей, а на каждом спектакле может быть любое число зрителей.
И наконец, на диаграмме отображены два отношения наследования, утверждающие, что и в зрителях, и в актерах есть человеческое начало.
Рис. 11.18. Диаграмма классов информационной системы театра
Принципы объектно-ориентированного представления программных систем
Рассмотрение любой сложной системы требует применения техники декомпозиции — разбиения на составляющие элементы. Известны две схемы декомпозиции: алгоритмическая декомпозиция и объектно-ориентированная декомпозиция.
В основе алгоритмической декомпозиции лежит разбиение по действиям — алгоритмам. Эта схема представления применяется в обычных ПС.
Объектно-ориентированная декомпозиция обеспечивает разбиение по автономным лицам — объектам реального (или виртуального) мира. Эти лица (объекты) — более «крупные» элементы, каждый из них несет в себе и описания действий, и описания данных.
Объектно-ориентированное представление ПС основывается на принципах абстрагирования, инкапсуляции, модульности и иерархической организации. Каждый из этих принципов не нов, но их совместное применение рассчитано на проведение объектно-ориентированной декомпозиции. Это определяет модификацию их содержания и механизмов взаимодействия друг с другом. Обсудим данные принципы [22], [32], [41], [59], [64], [66].
Процедурная связность
При достижении процедурной связности мы попадаем в пограничную область между хорошей сопровождаемостью (для модулей с более высокими уровнями связности) и плохой сопровождаемостью (для модулей с более низкими уровнями связности). Процедурно связный модуль состоит из элементов, реализующих независимые действия, для которых задан порядок работы, то есть порядок передачи управления. Зависимости по данным между элементами нет. Например:
Модуль Вычисление средних значений
используется Таблица-А. Таблица-В
вычислить среднее по Таблица-А
вычислить среднее по Таблица-В
вернуть среднееТабл-А. среднееТабл-В
Конец модуля
Этот модуль вычисляет средние значения для двух полностью несвязанных таблиц Таблица-А и Таблица-В, каждая из которых имеет по 300 элементов.
Теперь представим себе программиста, которому поручили реализовать данный модуль. Соблазнившись возможностью минимизации кода (использовать один цикл в интересах двух обработчиков, ведь они находятся внутри единого модуля!), программист пишет:
Модуль Вычисление средних значений
используется Таблица-А. Таблица-В
суммаТабл-А := 0
суммаТабл-В := 0
для i := 1 до 300
суммаТабл-А := суммаТабл-А + Таблица-А(i)
суммаТабл-В :- суммаТабл-В + Таблица-В(i)
конец для
среднееТабл-А := суммаТабл-А / 300
среднееТабл-В := суммаТабл-В / 300
вернуть среднееТабл-А, среднееТабл-В
Конец модуля
Для процедурной связности этот случай типичен — независимый (на уровне проблемы) код стал зависимым (на уровне реализации). Прошли годы, продукт сдали заказчику. И вдруг возникла задача сопровождения — модифицировать модуль под уменьшение размера таблицы В. Оцените, насколько удобно ее решать.
Процесс оценки
При планировании программного проекта надо оценить людские ресурсы (в человеко-месяцах), продолжительность (в календарных датах), стоимость (в тысячах долларов). Обычно исходят из прошлого опыта. Если новый проект по размеру и функциям похож на предыдущий проект, вполне вероятно, что потребуются такие же ресурсы, время и деньги.
Процесс руководства проектом
Руководство программным проектом — первый слой процесса конструирования ПО. Термин «слой» подчеркивает, что руководство определяет сущность процесса разработки от его начала до конца. Принцип руководства иллюстрирует рис. 2.1.
Рис. 2.1. Руководство в процессе конструирования ПО
На этом рисунке прямоугольник обозначает процесс конструирования, в нем выделены этапы, а вверху, над каждым из этапов, размещен слой деятельности «руководство программным проектом».
Для проведения успешного проекта нужно понять объем предстоящих работ, возможный риск, требуемые ресурсы, предстоящие задачи, прокладываемые вехи, необходимые усилия (стоимость), план работ, которому желательно следовать. Руководство программным проектом обеспечивает такое понимание. Оно начинается перед технической работой, продолжается по мере развития ПО от идеи к реальности и достигает наивысшего уровня к концу работ [32], [64], [69].
Проектирование для потока данных типа «преобразование»
Шаг 1. Проверка основной системной модели. Модель включает: контекстную диаграмму ПДД0, словарь данных и спецификации процессов. Оценивается их согласованность с системной спецификацией.
Шаг 2. Проверки и уточнения диаграмм потоков данных уровней 1 и 2. Оценивается согласованность диаграмм, достаточность детализации преобразователей.
Шаг 3. Определение типа основного потока диаграммы потоков данных. Основной признак потока преобразований — отсутствие переключения по путям действий.
Шаг 4. Определение границ входящего и выходящего потоков, отделение центра преобразований. Входящий поток — отрезок, на котором информация преобразуется из внешнего во внутренний формат представления. Выходящий поток обеспечивает обратное преобразование — из внутреннего формата во внешний. Границы входящего и выходящего потоков достаточно условны. Вариация одного преобразователя на границе слабо влияет на конечную структуру ПС.
Шаг 5. Определение начальной структуры ПС. Иерархическая структура ПС формируется нисходящим распространением управления. В иерархической структуре:
q модули верхнего уровня принимают решения;
q модули нижнего уровня выполняют работу по вводу, обработке и выводу;
q модули среднего уровня реализуют как функции управления, так и функции обработки.
Начальная структура ПС (для потока преобразования) стандартна и включает главный контроллер (находится на вершине структуры) и три подчиненных контроллера:
Данный минимальный набор модулей покрывает все функции управления, обеспечивает хорошую связность и слабое сцепление структуры.
Начальная структура ПС представлена на рис. 5.3.
Диаграмма потоков данных ПДД
Рис. 5.3. Начальная структура ПС для потока «преобразование»
Шаг 6. Детализация структуры ПС. Выполняется отображение преобразователей ПДД в модули структуры ПС. Отображение выполняется движением по ПДД от границ центра преобразования вдоль входящего и выходящего потоков. Входящий поток проходится от конца к началу, а выходящий поток — от начала к концу. В ходе движения преобразователи отображаются в модули подчиненных уровней структуры (рис. 5.4).
Центр преобразования ПДД отображается иначе (рис. 5.5). Каждый преобразователь отображается в модуль, непосредственно подчиненный контроллеру центра.
Проходится преобразуемый поток слева направо.
Возможны следующие варианты отображения:
q 1 преобразователь отображается в 1 модуль;
q 2-3 преобразователя отображаются в 1 модуль;
q 1 преобразователь отображается в 2-3 модуля.
Рис. 5.4. Отображение преобразователей ПДД в модули структуры
Рис. 5.5. Отображение центра преобразования ПДД
Для каждого модуля полученной структуры на базе спецификаций процессов модели анализа пишется сокращенное описание обработки.
Шаг 7. Уточнение иерархической структуры ПС. Модули разделяются и объединяются для:
1) повышения связности и уменьшения сцепления;
2) упрощения реализации;
3) упрощения тестирования;
4) повышения удобства сопровождения.
Проектирование для потока данных типа «запрос»
Шаг 1. Проверка основной системной модели. Модель включает: контекстную диаграмму ПДДО, словарь данных и спецификации процессов. Оценивается их согласованность с системной спецификацией.
Шаг 2. Проверки и уточнения диаграмм потоков данных уровней 1 и 2. Оценивается согласованность диаграмм, достаточность детализации преобразователей.
Шаг 3. Определение типа основного потока диаграммы потоков данных. Основной признак потоков запросов — явное переключение данных на один из путей действий.
Шаг 4. Определение центра запросов и типа для каждого из потоков действия. Если конкретный поток действия имеет тип «преобразование», то для него указываются границы входящего, преобразуемого и выходящего потоков.
Шаг 5. Определение начальной структуры ПС. В начальную структуру отображается та часть диаграммы потоков данных, в которой распространяется поток запросов. Начальная структура ПС для потока запросов стандартна и включает входящую ветвь и диспетчерскую ветвь.
Структура входящей ветви формируется так же, как и в предыдущей методике.
Диспетчерская ветвь включает диспетчер, находящийся на вершине ветви, и контроллеры потоков действия, подчиненные диспетчеру; их должно быть столько, сколько имеется потоков действий.
Проектирование объектно-ориентированных тестовых вариантов
Традиционные тестовые варианты ориентированы на проверку последовательности: ввод исходных данных — обработка — вывод результатов — или на проверку внутренней управляющей (информационной) структуры отдельных модулей. Объектно-ориентированные тестовые варианты проверяют состояния классов. Получение информации о состоянии затрудняют такие объектно-ориентированные характеристики, как инкапсуляция, полиморфизм и наследование.
Инкапсуляция
Информацию о состоянии класса можно получить только с помощью встроенных в него операций, которые возвращают значения свойств класса.
Полиморфизм
При вызове полиморфной операции трудно определить, какая реализация будет проверяться. Пусть нужно проверить вызов функции
y=functionA(x).
В стандартном ПО достаточно рассмотреть одну реализацию поведения, которая обеспечивает вычисление функции. В объектно-ориентированном ПО придется рассматривать поведение реализации Базовый_класс :: functionA(х), Производный_клacc :: functionA(x), Наследиик_Производного_класса :: functionA(х). Здесь двойным двоеточием от имени операции отделяется имя класса, в котором размещена операция (это обозначение UML). Таким образом, в объектно-ориентированном контексте каждый раз при вызове functionA(x) следует рассматривать набор различных поведений. Конечно, подход к тестированию базовых и производных классов в основном одинаков. Разница состоит только в учете используемых системных ресурсов.
Наследование
Наследование также может усложнить проектирование тестовых вариантов. Пусть Родительский_класс содержит операции унаследована() и переопределена(). Дочерний_класс переопределяет операцию переопределена() по-своему. Очевидно, что реализация Дочерний_класс::переопределена() должна повторно тестироваться, ведь ее содержание изменилось. Но надо ли повторно тестировать операцию Дочерний_класс::унаследована()?
Рассмотрим следующий случай. Положим, что операция Дочерний_класс::унаследована() вызывает операцию переопределен(). К чему это приводит? Поскольку реализация операции переопределен() изменена, операция Дочерний_класс::унаследована() может не соответствовать этой новой реализации.
Поэтому нужны новые тесты, хотя содержание операции унаследована() не изменено.
Важно отметить, что для операции Дочерний_класс::унаследована() может проводиться только подмножество тестов. Если часть операции унаследована() не зависит от операции переопределен(), то есть нет ее вызова или вызова любого кода, который косвенно ее вызывает, то ее не надо повторно тестировать в дочернем классе.
Родительский_класс::переопределена() и Дочерний_класс::переопределена() —это две разные операции с различными спецификациями и реализациями. Каждая из них проверяется самостоятельным набором тестов. Эти тесты нацелены на вероятные ошибки: ошибки интеграции, ошибки условий, граничные ошибки и т. д. Однако сами операции, как правило, похожи. Наборы их тестов будут перекрываться. Чем лучше качество объектно-ориентированного проектирования, тем больше перекрытие. Таким образом, новые тесты надо формировать только для тех требований к операции Дочерний_класс::переопределена(), которые не покрываются тестами для операции Родительский_класс::переопределена().
Выводы:
q тесты для операции Родительский_класс::переопределена() частично применимы к операции Дочерний_класс::переопределена();
q входные данные тестов подходят к операциям обоих классов;
q ожидаемые результаты для операции Родительского_класса отличаются от ожидаемых результатов для операции Дочернего_класса.
К операциям класса применимы классические способы тестирования «белого ящика», которые гарантируют проверку каждого оператора и их управляющих связей. При большом количестве операций от тестирования по принципу «белого ящика» приходится отказываться. Меньших затрат потребует тестирование на уровне классов.
Способы тестирования «черного ящика» также применимы к объектно-ориентированным системам. Полезную входную информацию для тестирования «черного ящика» и тестирования состояний обеспечивают элементы Use Case.
Простые циклы
Для проверки простых циклов с количеством повторений п может использоваться один из следующих наборов тестов:
1) прогон всего цикла;
2) только один проход цикла;
3) два прохода цикла;
4) т проходов цикла, где т<п;
5) п - 1, п, п + 1 проходов цикла.
Рабочие потоки процесса
Рабочие потоки процесса имеют следующее содержание:
q Сбор требований — описание того, что система должна делать;
q Анализ — преобразование требований к системе в классы и объекты, выявляемые в предметной области;
q Проектирование — создание статического и динамического представления системы, выполняющего выявленные требования и являющегося эскизом реализации;
q Реализация — производство программного кода, который превращается в исполняемую систему;
q Тестирование — проверка всей системы в целом.
Каждый рабочий поток определяет набор связанных артефактов и действий. Артефакт — это документ, отчет или выполняемый элемент. Артефакт может вырабатываться, обрабатываться или потребляться. Действие описывает задачи — шаги обдумывания, шаги исполнения и шаги проверки. Шаги выполняются участниками процесса (для создания или модификации артефактов).
Между артефактами потоков существуют зависимости. Например, модель Use Case, генерируемая в ходе сбора требований, уточняется моделью анализа из процесса анализа, обеспечивается проектной моделью из процесса проектирования, реализуется моделью реализации из процесса реализации и проверяется тестовой моделью из процесса тестирования.
Работа с элементами Use Case
Элемент Use Case описывает, что должна делать система, но не определяет, как она должна это делать. При моделировании это позволяет отделять внешнее представление системы от ее внутреннего представления.
Поведение элемента Use Case описывается потоком событий. Начальное описание выполняется в текстовой форме, прозрачной для пользователя системы. В потоке событий выделяют:
q основной поток и альтернативные потоки поведения;
q как и когда стартует и заканчивается элемент Use Case;
q когда элемент Use Case взаимодействует с актерами;
q какими данными обмениваются актер и система.
Для уточнения и формализации потоков событий используют диаграммы последовательности. Обычно одна диаграмма последовательности определяет главный поток в элементе Use Case, а другие диаграммы — потоки исключений.
В общем случае один элемент Use Case описывает набор последовательностей, в котором каждая последовательность представляет возможный поток событий. Каждая последовательность называется сценарием. Сценарий — конкретная последовательность действий, которая иллюстрирует поведение. Сценарии являются для элемента Use Case почти тем же, чем являются экземпляры для класса. Говорят, что сценарий — это экземпляр элемента Use Case.
Работа с СОМ-объектами
При работе с СОМ-объектами приходится их создавать, повторно использовать, размещать в других процессах, описывать в библиотеке операционной системы. Рассмотрим каждый из этих вопросов.
Ранжирование риска
Ранжирование заключается в назначении каждому элементу риска приоритета, который пропорционален влиянию элемента на проект. Это позволяет выделить категории элементов риска и определить наиболее важные из них. Например, представленные в табл. 15.1 элементы риска упорядочены по их приоритету.
Для больших проектов количество элементов риска может быть очень велико (30-40 элементов). В этом случае управление риском затруднено. Поэтому к элементам риска применяют принцип Парето 80/20. Опыт показывает, что 80% всего проектного риска приходятся на долю 20% от общего количества элементов риска. В ходе ранжирования определяют эти 20% элементов риска (их называют существенными элементами). В дальнейшем учитывается влияние только существенных элементов риска.
Расширение области применения объектно-ориентированного тестирования
Разработка объектно-ориентированного ПО начинается с создания визуальных моделей, отражающих статические и динамические характеристики будущей системы. Вначале эти модели фиксируют исходные требования заказчика, затем формализуют реализацию этих требований путем выделения объектов, которые взаимодействуют друг с другом посредством передачи сообщений. Исследование моделей взаимодействия приводит к построению моделей классов и их отношений, составляющих основу логического представления системы. При переходе к физическому представлению строятся модели компоновки и размещения системы.
На конструирование моделей приходится большая часть затрат объектно-ориентированного процесса разработки. Если к этому добавить, что цена устранения ошибки стремительно растет с каждой итерацией разработки, то совершенно логично требование тестировать объектно-ориентированные модели анализа и проектирования.
О синтаксической правильности судят по правильности использования языка моделирования (например, UML). О семантической правильности судят по соответствию модели реальным проблемам. Для определения того, отражает ли модель реальный мир, она оценивается экспертами, имеющими знания и опыт в конкретной проблемной области. Эксперты анализируют содержание классов, наследование классов, выявляя пропуски и неоднозначности. Проверяется соответствие отношений классов реалиям физического мира.
О согласованности судят путем рассмотрения противоречий между элементами в модели. Несогласованная модель имеет в одной части представления, которые противоречат представлениям в других частях модели.
Для оценки согласованности нужно исследовать каждый класс и его взаимодействия с другими классами. Для упрощения такого исследования удобно использовать модель Класс— Обязанность— Сотрудничество CRC (Class— Responsibility — Collaboration). Основной элемент этой модели — CRC-карта [9], [76]. Кстати, CRC-карты — любимый инструмент проектирования в ХР-процессах.
По сути, CRC-карта — это расчерченная карточка размером 6 на 10 сантиметров. Она помогает установить задачи класса и выявить его окружение (классы-собеседники). Для каждого класса создается отдельная карта.
В каждой CRC-карте указывается имя класса, его обязанности (операции) и его сотрудничества (другие классы, в которые он посылает сообщения и от которых он зависит при выполнении своих обязанностей). Сотрудничества подразумевают наличие ассоциаций и зависимостей между классами. Они фиксируются в других моделях — диаграмме сотрудничества (последовательности) объектов и диаграмме классов.
CRC-карта намеренно сделана простой, даже ее ограниченный размер имеет определенный смысл: если список обязанностей и сотрудников не помещается на карте, то, наверное, данный класс надо разделить на несколько классов.
Для оценки модели (диаграммы) классов на основе CRC-карт рекомендуются следующие шаги [50].
1. Выполняется перекрестный просмотр CRC-карты и диаграммы сотрудничества (последовательности) объектов. Цель — проверить наличие сотрудников, согласованность информации в обеих моделях.
2. Исследуются обязанности CRC-карты. Цель — определить, предусмотрена ли в карте сотрудника обязанность, которая делегируется ему из данной карты. Например, в табл. 16.1 показана CRC-карта Банкомат. Для этой карты выясняем, выполняется ли обязанность Читать карту клиента, которая требует использования сотрудника Карта клиента. Это означает, что класс Карта клиента должен иметь операцию, которая позволяет ему быть прочитанным.
Таблица 16.1. CRC-карта Банкомат
Имя класса: Банкомат
Обязанности:
Сотрудники:
Читать карту клиента
Идентификация клиента
Проверка счета
Выдача денег
Выдача квитанции
Захват карты
Карта клиента
База данных клиентов
База данных счетов
Блок денег
Блок квитанций
Блок карт
3. Организуется проход по каждому соединению CRC-карты.
Проверяется корректность запросов, выполняемых через соединения. Такая проверка гарантирует, что каждый сотрудник, предоставляющий услугу, получает обоснованный запрос. Например, если произошла ошибка и класс База данных клиентов получает от класса Банкомат запрос на Состояние счета, он не сможет его выполнить — ведь База данных клиентов не знает состояния их счетов.
4. Определяется, требуются ли другие классы, или правильно ли распределены обязанности по классам. Для этого используют проходы по соединениям, исследованные на шаге 3.
5. Определяется, нужно ли объединять часто запрашиваемые обязанности. Например, в любой ситуации используют пару обязанностей — Читать карту клиента и Идентификация клиента. Их можно объединить в новую обязанность Проверка клиента, которая подразумевает как чтение его карты, так и идентификацию клиента.
6. Шаги 1-5 применяются итеративно, к каждому классу и на каждом шаге эволюции объектно-ориентированной модели.
Расширение возможностей управления
Д. Хетли и И. Пирбхаи сосредоточили внимание на аспектах управления программным продуктом [34]. Они выделили системные состояния и механизм перехода из одного состояния в другое. Д. Хетли и И. Пирбхаи предложили не вносить в ПДД элементы управления, такие как потоки управления и управляющие процессы. Вместо этого они ввели диаграммы управляющих потоков (УПД).
q потоки управления и потоки событий (без потоков данных).
Вместо управляющих преобразователей в УПД используются указатели — ссылки на управляющую спецификацию УСПЕЦ. Как показано на рис. 3.7, ссылка изображается как косая пунктирная стрелка, указывающая на окно УСПЕЦ (вертикальную черту).
Рис. 3.7. Изображение ссылки на управляющую спецификацию
УСПЕЦ управляет преобразователями в ПДД на основе события, которое проходит в ее окно (по ссылке). Она предписывает включение конкретных преобразователей как результат конкретного события.
Иллюстрация модели программной системы, использующей описанные средства, приведена на рис. 3.8.
Рис. 3.8. Композиция модели обработки и управления
В модель обработки входит набор диаграмм потоков данных и набор спецификаций процессов. Модель управления образует набор диаграмм управляющих потоков и набор управляющих спецификаций. Модель обработки подключается к модели управления с помощью активаторов процессов. Активаторы включают в конкретной ПДД конкретные преобразователи. Обратная связь модели обработки с моделью управления осуществляется с помощью условий данных. Условия данных формируются в ПДД (когда входные данные преобразуются в события).
Расширения для систем реального времени
Как известно, программное изделие (ПИ) является дискретной моделью проблемной области, взаимодействующей с непрерывными процессами физического мира (рис. 3.3).
Рис. 3.3. Программное изделие как дискретная модель проблемной области
П. Вард и С. Меллор приспособили диаграммы потоков данных к следующим требованиям систем реального времени [73].
1. Информационный поток накапливается или формируется в непрерывном времени.
2. Фиксируется управляющая информация. Считается, что она проходит через систему и связывается с управляющей обработкой.
3. Допускается множественный запрос на одну и ту же обработку (из внешней среды).
Рис. 3.4. Расширения диаграмм для систем реального времени
Новые элементы имеют обозначения, показанные на рис. 3.4.
Приведем два примера использования новых элементов.
Пример 1. Использование потоков, непрерывных во времени.
На рис. 3.5 представлена модель анализа программного изделия для системы слежения за газовой турбиной.
Рис. 3.5. Модель ПО для системы слежения за газовой турбиной
Видим, что здесь наблюдаемая температура измеряется непрерывно до тех пор, пока не будет найдено дискретное значение в наборе эталонов температуры. Преобразователь формирует регулирующие воздействия как непрерывный во времени вывод. Чем полезна эта модель?
Во-первых, инженер делает вывод, что для приема-передачи квазинепрерывных значений нужно использовать аналого-цифровую и цифроаналоговую аппаратуру.
Во-вторых, необходимость организации высокоскоростного управления этой аппаратурой делает критичным требование к производительности системы.
Пример 2. Использование потоков управления.
Рассмотрим компьютерную систему, которая управляет роботом (рис. 3.6).
Рис. 3.6. Модель ПО для управления роботом
Установка в прибор деталей, собранных роботом, фиксируется установкой бита в буфере состояния деталей (он показывает присутствие или отсутствие каждой детали). Информация о событиях, запоминаемых в буфере, посылается в виде строки битов в преобразователь «Наблюдение за прибором». Преобразователь читает команды оператора только тогда, когда управляющая информация (битовая строка) показывает наличие всех деталей. Флаг события (Старт-Стоп) посылается в управляющий преобразователь «Начать движение», который руководит дальнейшей командной обработкой. Потоки данных посылаются в преобразователь команд роботу при наличии события «Процесс активен».
Размерно-ориентированные метрики
Размерно-ориентированные метрики прямо измеряют программный продукт и процесс его разработки. Основываются размерно-ориентированные метрики на LOC-оценках (Lines Of Code). LOC-оценка — это количество строк в программном продукте.
Исходные данные для расчета этих метрик сводятся в таблицу (табл. 2.1).
Таблица 2.1. Исходные данные для расчета LOC-метрик
Проект
Затраты, чел.-мес
Стоимость, тыс. $
KLOC, тыс. LOC
Прогр. док- ты, страниц
Разновидности компонентов
Мир современных компонентов достаточно широк и разнообразен. В языке UML для обозначения новых разновидностей компонентов используют механизм стереотипов. Стандартные стереотипы, предусмотренные в UML для компонентов, представлены в табл. 13.3.
Таблица 13.3. Разновидности компонентов
Стереотип
Описание
«executable»
«library»
«file»
«table»
«document»
Компонент, который может выполняться в физическом узле (имеет расширение .ехе)
Статическая или динамическая объектная библиотека (имеет расширение .dll)
Компонент, который представляет файл, содержащий исходный код или данные (имеет расширение .ini)
Компонент, который представляет таблицу базы данных (имеет расширение .tbl)
Компонент, который представляет документ (имеет расширение .hip)
В языке UML не определены пиктограммы для перечисленных стереотипов, применяемые на практике пиктограммы компонентов показаны на рис. 13.5-13.9.
Разработка в стиле экстремального программирования
Базовые понятия и методы ХР-процесса разработки обсуждались в разделе «ХР-процесс» главы 1. Напомним, что основная область применения ХР — небольшие проекты с постоянно изменяющимися требованиями заказчика [10], [11], [12], [75]. Заказчик может не иметь точного представления о том, что должно быть сделано. Функциональность разрабатываемого продукта может изменяться каждые несколько месяцев. Именно в этих случаях ХР позволяет достичь максимального успеха.
Основным структурным элементом ХР-процесса является ХР-реализация. Рассмотрим ее организацию.
Разрешение и наблюдение риска
Основанием для разрешения и наблюдения является план управления риском. Работы по разрешению и наблюдению производятся с начала и до конца процесса разработки.
Разрешение риска состоит в плановом применении действий по уменьшению риска.
Наблюдение риска гарантирует:
q цикличность процесса слежения за риском;
q вызов необходимых корректирующих воздействий.
Для управления риском используется эффективная методика «Отслеживание 10 верхних элементов риска». Эта методика концентрирует внимание на факторах повышенного риска, экономит много времени, минимизирует «сюрпризы» разработки.
Рассмотрим шаги методики «Отслеживания 10 верхних элементов риска».
1. Выполняется выделение и ранжирование наиболее существенных элементов риска в проекте.
2. Производится планирование регулярных просмотров (проверок) процесса разработки. В больших проектах (в группе больше 20 человек) просмотр должен проводиться ежемесячно, в остальных проектах — чаще.
3. Каждый просмотр начинается с обсуждения изменений в 10 верхних элементах риска (их количество может изменяться от 7 до 12). В обсуждении фиксируется текущий приоритет каждого из 10 верхних элементов риска, его приоритет в предыдущем просмотре, частота попадания элемента в список верхних элементов. Если элемент в списке опустился, он по-прежнему нуждается в наблюдении, но не требует управляющего воздействия. Если элемент поднялся в списке, или только появился в нем, то элемент требует повышенного внимания. Кроме того, в обзоре обсуждается прогресс в разрешении элемента риска (по сравнению с предыдущим просмотром).
4. Внимание участников просмотра концентрируется на любых проблемах в разрешении элементов риска.
Сценарий использования нового микропроцессора
Положим, что заказчик предложил использовать новый, более дешевый МП (дешевле на $1000). К чему это приведет? Опыт работы с его языком и утилитами понижается от номинального до очень низкого и EMLTEX = 1,22, а разработанные для него утилиты (компиляторы, ассемблеры и отладчики) примитивны и ненадежны (в результате фактор TOOL понижается от высокого до очень низкого и EMТООL= 1,24):
Мр = (1,088 / 0,86) х 1,22 x 1,24 = 1,914,
ЗАТРАТЫ = 36х1,914 = 69[чел.-мес],
СТОИМОСТЬ = ЗАТРАТЫ х $6000 = $414000,
Проигрыш_в_стоимости = $180000.
Сценарий наращивания памяти
Положим, что разработчик предложил нарастить память — купить за $1000 чип ОЗУ емкостью 96 Кбайт (вместо 64 Кбайт). Это меняет ограничение памяти (используется не 70%, а 47%), после чего фактор STOR снижается до номинального:
EMSTOR=1-> Мр =1,026,
ЗАТРАТЫ = 36x1,026 = 37 [чел.-мес],
СТОИМОСТЬ = ЗАТРАТЫ х $6000 = $222000,
Выигрыш_ в_стоимости = $ 12 000.
Сценарий понижения зарплаты
Положим, что заказчик решил сэкономить на зарплате разработчиков. Рычаг — понижение квалификации аналитика и программиста. Соответственно, зарплата сотрудников снижается до $5000. Оценки их возможностей становятся номинальными, а соответствующие множители затрат принимают единичные значения:
EMACAP=EMPCAP=1.
Следствием такого решения является возрастание множителя поправки Мр= 1,507, а также затрат и стоимости:
ЗАТРАТЫ = З6х 1,507 = 54 [чел.-мес],
СТОИМОСТЬ = ЗАТРАТЫ х$5000 = $270 000,
Проигрыш_ в_стоимости = $36 000.
Сценарий уменьшения средств на завершение проекта
Положим, что к разработке принят сценарий с наращиванием памяти:
ЗАТРАТЫ = 36 х 1,026 = 37 [чел.-мес],
СТОИМОСТЬ = ЗАТРАТЫ х $6000 = $222000.
Кроме того, предположим, что завершился этап анализа требований, на который было израсходовано $22 000 (10% от бюджета). После этого на завершение проекта осталось $200 000.
Допустим, что в этот момент «коварный» заказчик сообщает об отсутствии у него достаточных денежных средств и о предоставлении на завершение разработки только $170 000 (15%-ное уменьшение оплаты).
Для решения этой проблемы надо установить возможные изменения факторов затрат, позволяющие уменьшить оценку затрат на 15%.
Первое решение: уменьшение размера продукта (за счет исключения некоторых функций). Нам надо определить размер минимизированного продукта. Будем исходить из того, что затраты должны уменьшиться с 37 до 31,45 чел.-мес. Решим уравнение:
2,5 (НовыйРазмер)1,16= 31,45 [чел.-мес].
Очевидно, что
(НовыйРазмер)1,16
= 12,58,
(НовыйРазмер)1,16
= 12,581/1,16 = 8,872 [KLOC].
Другие решения:
q уменьшить требуемую надежность с номинальной до низкой. Это сокращает стоимость проекта на 12% (EMRELY изменяется с 1 до 0,88). Такое решение приведет к увеличению затрат и трудностей при применении и сопровождении;
q повысить требования к квалификации аналитиков и программистов (с высоких до очень высоких). При этом стоимость проекта уменьшается на 15-19%. Благодаря программисту стоимость может уменьшиться на (1 - 0,74/0,87) х 100% = 15%. Благодаря аналитику стоимость может понизиться на (1 - 0,67/0,83) х 100% = 19%. Основная трудность — поиск специалистов такого класса (готовых работать за те же деньги);
q повысить требования к опыту работы с приложением (с номинальных до очень высоких) или требования к опыту работы с платформой (с низких до высоких). Повышение опыта работы с приложением сокращает стоимость проекта на (1- 0,81) х 100% = 19%; повышение опыта работы с платформой сокращает стоимость проекта на (1 - 0,88/1,12) х 100% = 21,4%.
Основная трудность — поиск экспертов (специалистов такого класса);
q повысить уровень мультисетевой разработки с низкого до высокого. При этом стоимость проекта уменьшается на (1 - 0,92/1,1) х 100% = 16,4%;
q ослабить требования к режиму работы в реальном времени. Предположим, что 70%-ное ограничение по времени выполнения связано с желанием заказчика обеспечить обработку одного сообщения за 2 мс. Если же заказчик согласится на увеличение среднего времени обработки с 2 до 3 мс, то ограничение по времени станет равно (2 мс/3 мс) х 70% = 47%, в результате чего фактор TIME уменьшится с высокого до номинального, что приведет к экономии затрат на (1- 1/1,11) х 100%= 10%;
q учет других факторов затрат не имеет смысла. Некоторые факторы (размер базы данных, ограничения оперативной памяти, требуемый график разработки) уже имеют минимальные значения, для других трудно ожидать быстрого улучшения (использование программных утилит, опыт работы с языком и утилитами), третьи имеют оптимальные значения (требуемая повторная используемость, документирование требований жизненного цикла). На некоторые разработчик почти не может повлиять (сложность продукта, изменчивость платформы). Наконец, житейские неожиданности едва ли позволят улучшить принятое значение фактора «непрерывность персонала».
Какое же решение следует выбрать? Наиболее целесообразное решение — исключение отдельных функций продукта. Вторым (по предпочтительности) решением является повышение уровня мультисетевой разработки (все равно это придется сделать в ближайшее время). В качестве третьего решения можно рассматривать ослабление требований к режиму работы в реальном времени. Принятие же других решений зависит от наличия необходимых специалистов или средств разработки. Впрочем, окончательное решение должно выбираться в процессе переговоров с заказчиком, когда учитываются все соображения.
Выводы.
1. Факторы затрат оказывают существенное влияние на выходные параметры программного проекта.
2. Модель СОСОМО II предлагает широкий спектр факторов затрат, учитывающих большинство реальных ситуаций в «жизни» программного проекта.
3. Модель СОСОМО II обеспечивает перевод качественного обоснования решения менеджера на количественные рельсы, тем самым повышая объективность принимаемого решения.
Количественно сцепление измеряется степенью сцепления (СЦ). Выделяют 6 типов сцепления.
1. Сцепление по данным (СЦ=1). Модуль А вызывает модуль В.
Все входные и выходные параметры вызываемого модуля — простые элементы данных (рис. 4.13).
Рис. 4.13. Сцепление поданным
2. Сцепление по образцу (СЦ=3). В качестве параметров используются структуры данных (рис. 4.14).
Рис. 4.14. Сцепление по образцу
3. Сцепление по управлению (СЦ=4). Модуль А явно управляет функционированием модуля В (с помощью флагов или переключателей), посылая ему управляющие данные (рис. 4.15).
Рис. 4.15. Сцепление по управлению
4. Сцепление по внешним ссылкам (СЦ=5). Модули А и В ссылаются на один и тот же глобальный элемент данных.
5. Сцепление по общей области (СЦ=7). Модули разделяют одну и ту же глобальную структуру данных (рис. 4.16).
6. Сцепление по содержанию (СЦ=9). Один модуль прямо ссылается на содержание другого модуля (не через его точку входа). Например, коды их команд перемежаются друг с другом (рис. 4.16).
Рис. 4.16. Сцепление по общей области и содержанию
На рис. 4.16 видим, что модули В и D сцеплены по содержанию, а модули С, Е и N сцеплены по общей области.
Сцепление объектов
В классическом методе Л. Констентайна и Э. Йордана определены шесть типов сцепления, которые ориентированы на процедурное проектирование [77].
Принципиальное преимущество объектно-ориентированного проектирования в том, что природа объектов приводит к созданию слабо сцепленных систем. Фундаментальное свойство объектно-ориентированного проектирования заключается в скрытости содержания объекта. Как правило, содержание объекта невидимо внешним элементам. Степень автономности объекта достаточно высока. Любой объект может быть замещен другим объектом с таким же интерфейсом.
Тем не менее наследование в объектно-ориентированных системах приводит к другой форме сцепления. Объекты, которые наследуют свойства и операции, сцеплены с их суперклассами. Изменения в суперклассах должны проводиться осторожно, так как эти изменения распространяются во все классы, которые наследуют их характеристики.
Таким образом, сами по себе объектно-ориентированные механизмы не гарантируют минимального сцепления. Конечно, классы — мощное средство абстракции данных. Их введение уменьшило поток данных между модулями и, следовательно, снизило общее сцепление внутри системы. Однако количество типов зависимостей между модулями выросло. Появились отношения наследования, делегирования, реализации и т. д. Более разнообразным стал состав модулей в системе (классы, объекты, свободные функции и процедуры, пакеты). Отсюда вывод: необходимость измерения и регулирования сцепления в объектно-ориентированных системах обострилась.
Рассмотрим объектно-ориентированные метрики сцепления, предложенные М. Хитцем и Б. Монтазери [38].
Зависимость изменения между классами
Зависимость изменения между классами CDBC (Change Dependency Between Classes) определяет потенциальный объем изменений, необходимых после модификации класса-сервера SC (server class) на этапе сопровождения. До тех пор, пока реальное количество необходимых изменений класса-клиента СС (client class) неизвестно, CDBC указывает количество методов, на которые влияет изменение SC.
CDBC зависит от:
q области видимости изменяемого класса-сервера внутри класса-клиента ( определяется типом отношения между CS и СС);
q вида доступа СС к CS (интерфейсный доступ или доступ реализации).
Возможные типы отношений приведены в табл. 14.3, где п — количество методов класса СС,
— количество методов СС, потенциально затрагиваемых изменением.
Таблица 14.3. Вклад отношений между клиентом и сервером в зависимость изменения
Тип отношения
SC не используется классом СС
SC — класс экземплярной переменной в классе СС
Локальные переменные типа SC используются внутри /-методов класса СС
SC является суперклассом СС
SC является типом параметра для/-методов класса СС
СС имеет доступ к глобальной переменной класса SC
0
n
j
n
j
n
Конечно, здесь предполагается, что те элементы класса-сервера SC, которые доступны классу-клиенту СС, являются предметом изменений. Авторы исходят из следующей точки зрения: если класс SC является «зрелой» абстракцией, то предполагается, что его интерфейс более стабилен, чем его реализация. Таким образом, многие изменения в реализации SC могут выполняться без влияния на его интерфейс. Поэтому вводится фактор стабильности интерфейса для класса-сервера, он обозначается как к (0 < k < 1). Вклад доступа к интерфейсу в зависимость изменения можно учесть умножением на (1 - k).
Метрика для вычисления степени CDBC имеет вид:
;
CDBC(CC, SC) = min(n, A).
Пути минимизации CDBC:
1) ограничение доступа к интерфейсу класса-сервера;
2) ограничение видимости классов-серверов (спецификаторами доступа public, protected, private).
Локальность данных
Локальность данных LD (Locality of Data) — метрика, отражающая качество абстракции, реализуемой классом. Чем выше локальность данных, тем выше самодостаточность класса. Эта характеристика оказывает сильное влияние на такие внешние характеристики, как повторная используемость и тестируемость класса.
Метрика LD представляется как отношение количества локальных данных в классе к общему количеству данных, используемых этим классом.
Будем использовать терминологию языка C++. Обозначим как Mi(1
i
n) методы класса. В их число не будем включать методы чтения/записи экземплярных переменных. Тогда формулу для вычисления локальности данных можно записать в виде:
,
где:
q Li(1
i
n) — множество локальных переменных, к которым имеют доступ методы Mi (прямо или с помощью методов чтения/записи). Такими переменными являются: непубличные экземплярныё переменные класса; унаследованные защищенные экземплярныё переменные их суперклассов; статические переменные, локально определенные в Mi ;
q Ti(1
i
n) — множество всех переменных, используемых в Mi, кроме динамических локальных переменных, определенных в Mi.
Для обеспечения надежности оценки здесь исключены все вспомогательные переменные, определенные в Mi , — они не играют важной роли в проектировании.
Защищенная экземплярная переменная, которая унаследована классом С, является локальной переменной для его экземпляра (и следовательно, является элементом Li), даже если она не объявлена в классе С. Использование такой переменной методами класса не вредит локальности данных, однако нежелательно, если мы заинтересованы уменьшить значение CDBC.
Серверы СОМ-объектов
Каждый СОМ-объект существует внутри конкретного сервера. Этот сервер содержит программный код реализации операций, а также данные активного СОМ-объекта. Один сервер может обеспечивать несколько объектов и даже несколько СОМ-классов. Как показано на рис. 13.18, используются три типа серверов:
q Сервер «в процессе» (in-process) — объекты находятся в динамически подключаемой библиотеке и, следовательно, выполняются в том же процессе, что и клиент;
q Локальный сервер (out-process) — объекты находятся в отдельном процессе, выполняющемся на том же компьютере, что и клиент;
q Удаленный сервер — объекты находятся в DLL или в отдельном процессе, которые расположены на удаленном от клиента компьютере.
С точки зрения логики, клиенту безразлично, в сервере какого типа находится СОМ-объект — создание объекта, получение указателя на его интерфейсы, вызов его операций и финализация выполняются всегда одинаково. Хотя временные затраты на организацию взаимодействия в каждом из трех случаев, конечно, отличаются друг от друга.
Рис. 13.18. Различные серверы СОМ-объектов
начального моделирования
Начальное моделирование — это шаг к созданию описания системы как модели реального мира. Описание создается с помощью диаграммы системной спецификации.
Элементами диаграммы системной спецификации являются физические процессы (имеют суффикс 0) и их модели (имеют суффикс 1). Как показано на рис. 3.16, предусматриваются 2 вида соединений между физическими процессами и моделями.
Рис. 3.16. Соединения между физическими процессами и их моделями
Соединение потоком данных производится, когда физический процесс передает, а модель принимает информационный поток. Полагают, что поток передается через буфер неограниченной емкости типа FIFO (обозначается овалом).
Соединение по вектору состояний происходит, когда модель наблюдает вектор состояния физического процесса. Вектор состояния обозначается ромбиком.
Диаграмма системной спецификации для системы обслуживания перевозок приведена на рис. 3.17.
ПРИМЕЧАНИЕ
При нажатии кнопки формируется импульс, который может быть передан в модель как элемент данных, поэтому для кнопки выбрано соединение потоком данных.
Датчики, регистрирующие прибытие и убытие транспорта, не формируют импульса, они воздействуют на электронный переключатель. Состояние переключателя может быть оценено. Поэтому для транспорта выбрано соединение по вектору состояний.
Рис. 3.17. Диаграмма системной спецификации для системы обслуживания перевозок
Для фиксации особенностей процессов-моделей Джексон предлагает специальное описание — структурный текст. Например, структурный текст для модели КНОПКА-1 имеет вид
КНОПКА-1
читать BD;
НАЖАТЬ цикл ПОКА BD
нажать;
читать ВD;
конец НАЖАТЬ;
конец КНОПКА-1;
Структура модели КНОПКА-1 отличается от структуры физического процесса КНОПКА-0 добавлением оператора для чтения буфера ВD, который соединяет физический мир с моделью.
Прежде чем написать структурный текст для модели ТРАНСПОРТ-1, мы должны сделать ряд замечаний.
Во-первых, состояние транспорта будем отслеживать по переменным ПРИБЫЛ, УБЫЛ.
Они отражают состояние электронного переключателя физического транспорта.
Во-вторых, для учета инерционности процессов в физическом транспорте в модель придется ввести дополнительные операции:
q ЖДАТЬ (ожидание в изменении состояния физического транспорта);
q ТРАНЗИТ (операция задержки в модели на перемещение транспорта между остановками).
С учетом замечаний структурная диаграмма модели примет вид, изображенный на рис. 3.18.
Соответственно, структурный текст модели записывается в форме
ТРАНСПОРТ-1
опрос TSV;
ЖДАТЬ цикл ПОКА ПРИБЫЛ(1)
опрос TSV;
конец ЖДАТЬ;
покинуть(1);
ТРАНЗИТ цикл ПОКА УБЫЛ(1)
опрос TSV;
конец ТРАНЗИТ;
ТРАНСПОРТ цикл
ОСТАНОВКА
прибыть(i);
ЖДАТЬ цикл ПОКА ПРИБЫЛ(i)
опрос TSV;
конец ЖДАТЬ;
покинуть(i);
ТРАНЗИТ цикл ПОКА УБЫЛ(i)
опрос TSV;
конец ТРАНЗИТ;
конец ОСТАНОВКА;
конец ТРАНСПОРТ;
прибыть(1);
конец ТРАНСПОРТ-1;
Рис. 3.18. Структурная диаграмма модели транспорта
объект-действие
Начинается с определения проблемы на естественном языке.
Пример:
Разработать компьютерную систему для обслуживания университетских перевозок. Университет размещается на двух территориях. Для перемещения студентов используется один транспорт. Он перемещается между двумя фиксированными остановками. На каждой остановке имеется кнопка вызова.
При нажатии кнопки:
q если транспорт на остановке, то студенты заходят в него и перемещаются на другую остановку;
q если транспорт в пути, то студенты ждут прибытия на другую остановку, приема студентов и возврата на текущую остановку;
q если транспорт на другой остановке, то он ее покидает, прибывает на текущую остановку и принимает студентов, нажавших кнопку.
Транспорт должен стоять на остановке до появления запроса на обслуживание.
Описание исследуется для выделения объектов. Производится грамматический разбор. Возможны следующие кандидаты в объекты: территория, студенты, транспорт, остановка, кнопка. У нас нет нужды прямо использовать территорию, студентов, остановку — все они лежат вне области модели и отвергаются как возможные объекты. Таким образом, мы выбираем объекты транспорт и кнопка.
Для выделения действий исследуются все глаголы описания.
Кандидатами действий являются: перемещаться, прибывает, нажимать, принимать, покидать. Мы отвергаем перемещаться, принимать потому, что они относятся к студентам, а студенты не выделены как объект. Мы выбираем действия: прибывает, нажимать, покидать.
Заметим, что при выделении объектов и действий возможны ошибки. Например, отвергнув студентов, мы лишились возможности исследовать загрузку транспорта. Впрочем, список объектов и действий может модифицироваться в ходе дальнейшего анализа.
объект-структура
Структура объектов описывает последовательность действий над объектами (в условном времени).
Для представления структуры объектов Джексон предложил 3 типа структурных диаграмм. Они показаны на рис. 3.13. В первой диаграмме к объектам применяется такое действие, как последовательность, во второй — выбор, в третьей — повторение.
Рассмотрим объектную структуру для транспорта (см. рис. 3.14). Условимся, что начало и конец истории транспорта — у первой остановки. Действиями, влияющими на объект, являются Покинуть и Прибыть.
Рис. 3.13. Три типа структурных диаграмм Джексона
Рис. 3.14. Объектная структура для транспорта
Диаграмма показывает, что транспорт начинает работу у остановки 1, тратит основное время на перемещение между остановками 1 и 2 и окончательно возвращается на остановку 1. Прибытие на остановку, следующее за отъездом с другой остановки, представляется как пара действий Прибыть(i) и Покинуть(i). Заметим, что диаграмму можно сопровождать комментариями, которые не могут прямо представляться средствами метода. Например, «значение г в двух последовательных остановках должно быть разным».
Структурная диаграмма для объекта Кнопка показывает (рис. 3.15), что к нему многократно применяется действие Нажать.
Рис. 3.15. Структурная диаграмма для объекта Кнопка
В заключение заметим, что структурная диаграмма — время-ориентированное описание действий, выполняемых над объектом. Она создается для каждого объекта модели.
и способа тестирования базового пути
Для иллюстрации шагов данного способа используем конкретную программу — процедуру вычисления среднего значения:
процедура сред;
1 i := 1;
1 введено := 0;
1 колич := 0;
1 сум := 0;
вып пока 2 -вел( i ) <> stop и введено <=500 - 3
4 введено:= введено + 1;
если 5 -вел( i ) >= мин и вел( i ) <= макс - 6
7 то колич := колич + 1;
7 сум := сум + вел( i );
8 конец если;
8 i := i + 1;
9 конец вып;
10 если колич > 0
11 то сред := сум / колич;
12 иначе сред := stop;
13 конец если;
13 конец сред;
Заметим, что процедура содержит составные условия (в заголовке цикла и условном операторе). Элементы составных условий для наглядности помещены в рамки.
Шаг 1. На основе текста программы формируется потоковый граф:
q нумеруются операторы текста (номера операторов показаны в тексте процедуры);
q производится отображение пронумерованного текста программы в узлы и вершины потокового графа (рис. 6.7).
Рис. 6.7. Потоковый граф процедуры вычисления среднего значения
Шаг 2. Определяется цикломатическая сложность потокового графа — по каждой из трех формул:
1) V(G) = 6 регионов;
2) V(G) = 17 дуг - 13 узлов + 2 = 6;
3) V(G) = 5 предикатных узлов + 1 = 6.
Шаг 3. Определяется базовое множество независимых линейных путей:
Путь 1: 1-2-10-11-13; /вел=stор, колич>0.
Путь 2: 1-2-10-12-13;/вел=stop, колич=0.
Путь 3: 1-2-3-10-11-13; /попытка обработки 501-й величины.
Путь 4: 1-2-3-4-5-8-9-2-... /вел<мин.
Путь 5: 1-2-3-4-5-6-8-9-2-... /вел>макс.
Путь 6: 1-2-3-4-5-6-7-8-9-2-... /режим нормальной обработки.
ПРИМЕЧАНИЕ
Для удобства дальнейшего анализа по каждому пути указаны условия запуска.
Точки в конце путей 4, 5, 6 указывают, что допускается любое продолжение через остаток управляющей структуры графа.
Шаг 4. Подготавливаются тестовые варианты, инициирующие выполнение каждого пути.
Каждый тестовый вариант формируется в следующем виде:
Исходные данные (ИД):
Ожидаемые результаты (ОЖ.РЕЗ.):
Исходные данные должны выбираться так, чтобы предикатные вершины обеспечивали нужные переключения — запуск только тех операторов, которые перечислены в конкретном пути, причем в требуемом порядке.
Определим тестовые варианты, удовлетворяющие выявленному множеству независимых путей.
Тестовый вариант для пути 1 ТВ1:
ИД: вел(k) = допустимое значение, где k < i; вел(i) = stop, где 2 < i < 500.
ОЖ.РЕЗ.: корректное усреднение основывается на k величинах и правильном подсчете.
ПРИМЕЧАНИЕ
Путь не может тестироваться самостоятельно, а должен тестироваться как часть путей 4, 5, 6 (трудности проверки 11-го оператора).
Тестовый вариант для пути 2 ТВ2:
ИД: вел(1)=stор.
ОЖ.РЕЗ.: сред=stор, другие величины имеют начальные значения.
Тестовый вариант для пути 3 ТВЗ:
ИД: попытка обработки 501-й величины, первые 500 величин должны быть правильными.
ОЖ.РЕЗ.: корректное усреднение основывается на k величинах и правильном подсчете.
Тестовый вариант для пути 4 ТВ4:
ИД: вел(i)=допустимое значение, где i ? 500; вел(k) < мин, где k < i.
ОЖ.РЕЗ.: корректное усреднение основывается на k величинах и правильном подсчете.
Тестовый вариант для пути 5 ТВ5:
ИД: вел(i)=допустимое значение, где i ? 500; вел(k) > макс, где k < i.
ОЖ.РЕЗ.: корректное усреднение основывается на п величинах и правильном подсчете.
Тестовый вариант для пути 6 ТВ6:
ИД: вел(i)=допустимое значение, где i ? 500.
ОЖ.РЕЗ.: корректное усреднение основывается на п величинах и правильном подсчете.
Реальные результаты каждого тестового варианта сравниваются с ожидаемыми результатами. После выполнения всех тестовых вариантов гарантируется, что все операторы программы выполнены по меньшей мере один раз. Важно отметить, что некоторые независимые пути не могут проверяться изолированно. Такие пути должны проверяться при тестировании другого пути (как часть другого тестового варианта).
Системное тестирование
Системное тестирование подразумевает выход за рамки области действия программного проекта и проводится не только программным разработчиком. Классическая проблема системного тестирования — указание причины. Она возникает, когда разработчик одного системного элемента обвиняет разработчика другого элемента в причине возникновения дефекта. Для защиты от подобного обвинения разработчик программного элемента должен:
1) предусмотреть средства обработки ошибки, которые тестируют все вводы информации от других элементов системы;
2) провести тесты, моделирующие неудачные данные или другие потенциальные ошибки интерфейса ПС;
3) записать результаты тестов, чтобы использовать их как доказательство невиновности в случае «указания причины»;
4) принять участие в планировании и проектировании системных тестов, чтобы гарантировать адекватное тестирование ПС.
В конечном счете системные тесты должны проверять, что все системные элементы правильно объединены и выполняют назначенные функции. Рассмотрим основные типы системных тестов [13], [52].
Сложность программной системы
В простейшем случае сложность системы определяется как сумма мер сложности ее модулей. Сложность модуля может вычисляться различными способами.
Например, М. Холстед (1977) предложил меру длины N модуля [33]:
N » n1log2 (n1) + n2log2(n2),
где n1 — число различных операторов, п2 — число различных операндов.
В качестве второй метрики М. Холстед рассматривал объем V модуля (количество символов для записи всех операторов и операндов текста программы):
V = N x log2 (n1 + n2).
Вместе с тем известно, что любая сложная система состоит из элементов и системы связей между элементами и что игнорировать внутрисистемные связи неразумно.
Том МакКейб (1976) при оценке сложности ПС предложил исходить из топологии внутренних связей [49]. Для этой цели он разработал метрику цикломатической сложности:
V(G) = E-N + 2,
где Е — количество дуг, a.N — количество вершин в управляющем графе ПС. Это был шаг в нужном направлении. Дальнейшее уточнение оценок сложности потребовало, чтобы каждый модуль мог представляться как локальная структура, состоящая из элементов и связей между ними.
Таким образом, при комплексной оценке сложности ПС необходимо рассматривать меру сложности модулей, меру сложности внешних связей (между модулями) и меру сложности внутренних связей (внутри модулей) [28], [56]. Традиционно со внешними связями сопоставляют характеристику «сцепление», а с внутренними связями — характеристику «связность».
Вопросы комплексной оценки сложности обсудим в следующем разделе.
Создание диаграммы классов
Объекты из диаграмм последовательности группируются в классы. Основываясь на нашей диаграмме последовательности, мы можем идентифицировать следующие объекты и классы:
q registration form является объектом класса RegForm;
q manager является объектом класса Manager;
q math 101 является объектом класса Course;
q section 1 является объектом класса CourseOffering;
q bill является интерфейсом к внешней учетной системе, поэтому мы будем использовать имя BillingSystem как имя его класса.
Классы создаются в логическом представлении системы (рис. 17.17).
1. В окне браузера щелкните правой кнопкой по значку пакета Logical View.
2. В появившемся контекстном меню выберите команду New:Class. В результате в дерево окна браузера будет добавлен класс с именем NewClass.
3. Пока значок класса остается выделенным, введите имя RegForm.
4. Повторите предыдущие шаги для добавления других классов: Manager, Course, CourseOffering и BillingSystem.
После создания классов они описываются (документируются). Описания добавляются с помощью Documentation Window (рис. 17.18).
1. В окне браузера щелкните по значку класса CourseOffering.
2. Введите описание класса в Documentation Window.
Процесс построения сценариев и нахождения классов продолжается до тех пор, пока вы не скажете: «Больше находить нечего — нет ни новых классов, ни новых сообщений».
Следующий шаг — построение диаграммы классов. Откроем главную диаграмму (рис. 17.19) классов и добавим в нее классы.
1. Для открытия диаграммы выполним двойной щелчок по значку Main в окне браузера.
2. В главном меню выберем команду Query:Add Classes.
3. Для добавления всех классов нажмем кнопку АИ» (выбрать все).
4. Для закрытия окна и добавления классов в диаграмму нажмем кнопку ОК.
5. Переупорядочим классы в диаграмме (выделяя конкретный класс и перетаскивая, его на новое место).
ПРИМЕЧАНИЕ
Классы можно добавлять в диаграмму перетаскиванием их из окна браузера (по одному классу в единицу времени).
Для создания новых типов моделирующих элементов в UML используется понятие стереотипа. С помощью стереотипа можно «нагрузить» элемент новым смыслом. Используем предопределенный стереотип Interface для класса BillingSystem (рис. 17.20), так как этот класс определяет только интерфейс к внешней учетной системе (billing system).
Рис. 17.20. Класс Billing System
1. В главной диаграмме классов выполним двойной щелчок по значку класса BillingSystem. В результате появляется окно спецификации класса (Class Specification).
2. Щелкнем по стрелке раскрывающегося списка Stereotype.
3. Наберем на клавиатуре слово-стереотип Interface.
4. Закроем окно спецификации, нажав кнопку ОК.
Для определения взаимодействия объектов нужно указать отношения между классами. Для того чтобы увидеть, как объекты должны разговаривать друг с другом, исследуются диаграммы последовательности. Если объекты должны разговаривать, то должен быть путь для коммуникации между их классами. Двумя типами структурных отношений являются ассоциации и агрегации.
Ассоциация определяет соединение между классами. Исследуя диаграмму последовательности Add a Course, мы можем определить существование следующих ассоциаций: от RegForm к Manager, от Manager к Course и от Manager к BHHngSystem (рис. 17.21).
Рис. 17.21. Ассоциации между классами
1. На панели инструментов щелкните по значку однонаправленной ассоциации (стрелке).
2. Щелкните по классу RegForm и перетащите линию ассоциации на класс Manager.
3. Повторите предыдущие шаги для ввода следующих отношений:
q от Manager к Course;
q от Manager к BillingSystem.
Ассоциации задают пути между объектами-партнерами одинакового уровня.
Агрегация фиксирует неравноправные связи. Она показывает отношение между целым и его частями. Создадим отношение агрегации между классом Course и классом CourseOffering (рис. 11.22), так как предложение Курса CourseOfferings является частью агрегата — класса Course.
1. На панели инструментов щелкните по значку агрегации (линии с ромбиком).
2. Щелкните по классу, представляющему целое — Course.
3. Перетащите линию агрегации на класс, представляющий часть — CourseOffering.
Рис. 17.22. Отношение агрегации
Рис. 17.23. Индикаторы мощности
Для отображения того, «как много» объектов участвует в отношении, к ассоциациям и агрегациям диаграммы могут добавляться индикаторы мощности (рис. 17.23).
1. Щелкните правой кнопкой по линии агрегации возле класса CourseOffering.
2. Из контекстного меню выберите команду Multipticity:0ne or More.
3. Щелкните правой кнопкой по линии агрегации возле класса Course.
4. Из контекстного меню выберите команду Multiplicity:1.
Вспомним, что задание имени — это первый из трех шагов определения класса. Любой класс должен инкапсулировать в себе структуру данных и поведение, которое определяет возможности обработки этой структуры. Примем, что на фиксацию структуры ориентируется второй шаг, а на фиксацию поведения — третий шаг.
Структура класса представляется набором его свойств. Структура находится путем исследования проблемных требований и соглашений между разработчиками и заказчиками.
В нашей модели каждое предложение курса (CourseOffering) является свойством (attribute) класса-агрегата Course.
Конечно, класс CourseOffering тоже имеет свойства (рис. 17.24). Определим одно из них — количество студентов.
Рис. 17.24. Свойства
1. В диаграмме классов щелкните правой кнопкой по классу CourseOffering.
2. Из контекстного меню выберите команду Insert New Attribute. Это приведет к добавлению в класс свойства.
3. Пока новое свойство остается выделенным, введите его имя — numberStudents.
Итак, два шага формирования класса сделаны. Перейдем к третьему шагу — заданию поведения класса.
Поведение класса представляется набором его операций. Исходная информация об операциях класса находится в диаграммах последовательности. В операции отображаются сообщения из диаграмм последовательности.
Первое действие этого шага заключается в привязке объектов (из диаграмм последовательности) к конкретным классам. Выполним такую привязку для нашей модели (рис. 17.25).
Рис. 17.25. Привязка объектов к классам
1. Для открытия диаграммы последовательности Add a Course выполним двукратный щелчок по ее значку в окне браузера.
2. В окне браузера щелкнем по значку класса CourseOffering.
3. Перетащим класс CourseOffering на объект section 1.
Вот и все. Видим, что имя объекта удлинилось, в нем появились две части, разделенные двоеточием. Слева от двоеточия записывается имя объекта, а справа — имя класса.
После назначения объекта классу выполняется второе действие — наполнение класса операциями. Как правило, в операции класса превращаются сообщения, получаемые его объектом. При этом обычно сообщения переименовываются — производится согласование имени сообщения и имени операции (рис. 17.26). Причины переименования просты и понятны. Во-первых, имя операции должно отражать ее принадлежность к классу (а не к источнику соответствующего сообщения).
Во-вторых, имя операции должно указывать на ее обязанность, а не на способ ее реализации. В-третьих, имя должно быть допустимым с точки зрения синтаксиса языка программирования, который будет использоваться для кодирования класса.
Рис. 17.26. Новая операция
1. Щелкните правой кнопкой по сообщению «add Joe». В результате станет видимым контекстное меню.
2. Выберите команду new operation. В результате станет видимой спецификация операции Operation Specification.
3. Введите имя новой операции — add.
4. Перейдите на вкладку Detail.
5. Щелкните правой кнопкой мышки по полю Arguments.
6. Выберите в контекстном меню команду Insert. В появившейся рамке наберите имя аргумента — Joe. Щелкните вне рамки.
7. Закройте окно спецификации, нажав кнопку ОК.
Вы создали новую операцию класса и связали с ней сообщение — оно автоматически поменяло свое имя. Несмотря на переименование, это прямое действие — отталкиваясь от имени сообщения, получить имя операции.
Возможно и обратное действие — отталкиваясь от имени операции, получить имя сообщения. При этом реализуется такая последовательность: отдельно создается новая операция класса, а затем она отображается на существующее сообщение (рис. 17.27).
1. Щелкните правой кнопкой по классу в браузере.
2. В появившемся контекстном меню выберите команду New: Operation. Появляется рамка с надписью opname.
3. Вместо надписи opname наберите имя новой операции класса — offeringOpen.
4. На диаграмме последовательности щелкните правой кнопкой по сообщению «accepting students?». В результате станет видимым контекстное меню.
5. В меню выберите операцию offeringOpen() —сообщение переименовывается (на него отображается операция класса).
Рис. 17.27. Отображение операции на сообщение
Следующий шаг разработки состоит в настройке описаний классов на конкретный язык программирования. Сам язык выбирается по команде Tools:0ptions. В появившемся диалоговом окне переходят на вкладку Notation. Название языка выбирается из раскрывающегося списка Default Language. Для нашего примера используем язык Ada 95.
Итак, в ходе анализа и проектирования в визуальную модель добавляются проектные решения (рис. 17.28). После выбора языка программирования для свойств определяют типы данных, а для операций конкретизируют сигнатуры — имена и типы параметров, типы возвращаемых значений.
1. Выполним двукратный щелчок по значку класса CourseOffering в окне браузера или диаграмме классов. В результате станет видимым окно спецификации класса.
2. Выберите страницу Attributes (свойства).
3. Щелкните по полю Туре. В результате станет видимым раскрывающийся список.
4. Введите требуемый тип данных (Integer).
5. Закройте окно спецификации, нажав кнопку ОК.
Рис. 17.28. Добавление проектных решений
ПРИМЕЧАНИЕ
Типы данных для свойств можно устанавливать, используя спецификацию Attribute или вводя их в строчке отображения свойства на диаграмме классов (формат attribute:data type).
Теперь зададим тип возвращаемого результата для операции offeringOpen (рис. 17.29).
1. Выполним двукратный щелчок по значку класса CourseOffering в окне браузера или диаграмме классов. В результате станет видимым окно спецификации класса.
2. Выберите страницу Operations.
3. Щелкните по полю Return type.
В результате станет видимым раскрывающийся список.
4. Введите требуемый возвращаемый тип (Integer).
5. Закройте окно спецификации, нажав кнопку ОК.
ПРИМЕЧАНИЕ
Аргументы операции устанавливают с помощью диалогового окна Operation Specification. Для перехода к этому окну нужно на вкладке (странице) Operations щелкнуть правой кнопкой по имени операции и в появившемся контекстном меню выбрать команду Specification. Далее в появившемся диалоговом окне следует перейти на вкладку Detail.
Аргументы операции и возвращаемый тип можно также установить, вводя их в строчке отображения операции на диаграмме классов (формат operation(argument name:data type):return type).
Рис. 17.29. Определение типа возвращаемого результата
Создание диаграммы последовательности
Функциональность элемента Use Case отображается графически в диаграмме последовательности (Sequence Diagram). Эта диаграмма отображает один из возможных путей в потоках событий элемента Use Case — например, добавление студента к курсу. Диаграммы последовательности содержат объекты и сообщения между объектами, которые показывают реализацию поведения. Рассмотрим диаграмму последовательности Add a Course для элемента Use Case Register for Courses (рис. 17.10).
1. В окне браузера щелкните правой кнопкой по элементу Use Case Register for Courses.
2. В появившемся контекстном меню выберите команду New:Sequence Diagram.
3. В результате в дерево окна браузера будет добавлена диаграмма последовательности с именем New Diagram.
4. Пока значок новой диаграммы остается выделенным, введите имя Add a Course.
Рис. 17.10. Создание диаграммы последовательности Add a Course
Теперь мы будем добавлять в диаграмму такие объекты и сообщения, которые реализуют необходимую функциональность. Для открытия диаграммы два раза щелкнем по ее значку в окне браузера. Поскольку сценарий инициируется актером Student, перетащим этого актера в диаграмму (рис. 17.11). Экземпляру актера можно присвоить конкретное имя. Назовем нашего студента Joe.
1. Для открытия диаграммы последовательности выполним двойной щелчок по ее значку в окне браузера.
2. Щелкнем по значку актера Student в браузере и перетащим его в диаграмму последовательности.
3. Щелкнем по значку актера в диаграмме последовательности и введем его имя — Joe.
Сценарий, который мы собираемся формализовать с помощью диаграммы последовательности, уже существует — он является фрагментом текста, который содержит спецификация элемента Use Case Register for Courses.
В этом сценарии студент должен заполнить информацией (fill in info) регистрационную форму (registration form), а затем форма предъявляется на рассмотрение (submitted).
Очевидно, что необходим объект registration form, который принимает информацию от студента (рис. 17.12). Создадим форму и добавим два сообщения, «fillin info» и «submit».
1. На панели инструментов щелкните по значку объекта (прямоугольнику).
2. Для добавления объекта в диаграмму щелкните в нужном месте диаграммы.
3. Пока объект остается выделенным, введите имя registration form.
4. На панели инструментов щелкните по значку объектного сообщения (стрелке).
5. Щелкните по пунктирной линии под актером Student и перетащите стрелку на пунктирную линию под объектом registration form.
6. Пока стрелка остается выделенной, введите имя сообщения — fill in information.
7. Повторите шаги 4-6 для создания сообщения submit.
Рис. 17.11. Диаграмма последовательности — Joe
Рис. 17.12. Диаграмма последовательности — Registration Form
Очевидно, что объект регистрационная форма является промежуточным звеном в цепи передачи информации. Следующее звено — объект-менеджер. Его надо добавить в диаграмму.
Далее форма должна послать сообщение менеджеру (manager) (рис. 17.13). Таким образом менеджер узнает, что студент должен быть добавлен к курсу, — положим, что Joe хочет получить курс math 101.
1. На панели инструментов щелкните по значку объекта (прямоугольнику).
2. Для добавления объекта в диаграмму щелкните в нужном месте диаграммы.
3. Пока объект остается выделенным, введите имя manager.
4. На панели инструментов щелкните по значку объектного сообщения (стрелке).
5. Щелкните по пунктирной линии под объектом registration form и перетащите стрелку на пунктирную линию под объектом manager.
6. Пока стрелка остается выделенной, введите имя сообщения — add Joe to Math 101.
Менеджер — один из объектов системы, который взаимодействует как с регистрационной формой, так и с набором объектов — учебных курсов. Для обслуживания нашего студента должен быть объект Math 101. Если такой объект существует, то Менеджер обязан передать объекту-курсу Math 101, что Joe должен быть добавлен к курсу (рис. 17.14).
1. На панели инструментов щелкните по значку объекта (прямоугольнику).
2. Для добавления объекта в диаграмму щелкните в нужном месте диаграммы.
3. Пока объект остается выделенным, введите имя math 101.
4. На панели инструментов щелкните по значку объектного сообщения (стрелке).
5. Щелкните по пунктирной линии под объектом manager и перетащите стрелку на пунктирную линию под объектом math 101.
6. Пока стрелка остается выделенной, введите имя сообщения — add Joe.
Рис. 17.14. Диаграмма последовательности — Math 101
Объект-курс не принимает самостоятельных решений о возможности добавления студентов. Этим занимается экземпляр класса Предложение курса (course offering). Назовем такой экземпляр (объект) Section 1.
Объект-курс обращается к объекту Section 1, если он открыт (в этом сценарии — ответ «да») с предложением добавить студента Joe (рис. 17.15).
1. На панели инструментов щелкните по значку объекта (прямоугольнику).
2. Для добавления объекта в диаграмму щелкните в нужном месте диаграммы.
3. Пока объект остается выделенным, введите имя — section 1.
4. На панели инструментов щелкните по значку объектного сообщения (стрелке).
5. Щелкните по пунктирной линии под объектом math 101 и перетащите стрелку на пунктирную линию под объектом section 1.
6. Пока стрелка остается выделенной, введите имя сообщения — accepting students?
7. Повторите шаги 4-6 для создания сообщения add Joe.
Рис. 17.16. Диаграмма последовательности — Billing System
Конечно, за учебу надо платить. Вопросами оплаты занимается Учетная система, а уведомляет ее о необходимости выписки счета менеджер. После того как менеджер удостоверился, что студенту Joe предоставляется возможность изучать курс math 101 (на диаграмме рис. 17.16 это не показано), уведомляется Учетная система (billing system).
1. На панели инструментов щелкните по значку объекта (прямоугольнику).
2. Для добавления объекта в диаграмму щелкните в нужном месте диаграммы.
3. Пока объект остается выделенным, введите имя — bill.
4. На панели инструментов щелкните по значку объектного сообщения (стрелке).
5. Щелкните по пунктирной линии под объектом manager и перетащите стрелку на пунктирную линию под объектом bill.
6. Пока стрелка остается выделенной, введите имя сообщения — send bill for Math 101 to Joe.
Создание диаграммы Use Case
Моделирование проблемы регистрации курсов начнем с создания диаграммы Use Case. Этот тип диаграммы представляется актерами, элементами Use Case и отношениями между ними. Откроем главную диаграмму Use Case (рис. 17.6).
1. В окне браузера щелкнем по значку + слева от пакета Use Case View.
2. Для открытия диаграммы выполним двойной щелчок по значку Main.
Первый шаг построения этой диаграммы состоит в определении актеров, фиксирующих роли внешних объектов, взаимодействующих с системой. В нашей проблемной области можно выделить 4 актера — Student (Студент), Professor (Профессор), Registrar (Регистратор) и Billing System (Учетная система) (рис. 17.7).
1. На панели инструментов щелкните по значку актера.
2. Для добавления актера в диаграмму щелкните в нужном месте диаграммы.
3. Пока актер остается выделенным, введите имя Student (Студент).
Рис. 17.6. Главная диаграмма Use Case
Рис. 17.7. Четыре актера
4. Повторите предыдущие шаги для ввода трех других актеров (Professor, Registrar и Billing System — Профессор, Регистратор, Учетная система).
Далее для каждого актера нужно определить соответствующие элементы Use Case. Элемент Use Case представляет определенную часть функциональности, обеспечиваемой системой. Вы можете идентифицировать элементы Use Case путем рассмотрения каждого актера и его взаимодействия с системой. В нашей модели актер Student хочет регистрироваться на курсы (Register for Courses). Актер Billing System получает информацию о регистрации. Актер Professor хочет запросить список курса (Request a Course Roster). Наконец, актер Registrar должен управлять учебным планом (Manage Curriculum) (рис. 17.8).
Рис. 17.8. Элементы Use Case для актеров
1. На панели инструментов щелкните по значку элемента Use Case.
2. Для добавления элемента Use Case в диаграмму щелкните в нужном месте диаграммы.
3. Пока элемент Use Case остается выделенным, введите имя Register for Courses.
4. Повторите предыдущие шаги для ввода других элементов Use Case (Request Course Roster, Manage Curriculum).
Далее между актерами и элементами Use Case рисуются отношения. Чтобы показать направление взаимодействия (кто инициирует взаимодействие), используются однонаправленные стрелки (uni-directional arrows). В системе регистрации курсов актер Student инициирует элемент Use Case Register for Courses, который, в свою очередь, взаимодействует с актером Billing System. Актер Professor инициирует элемент Use Case Request Course Roster. Актер Registrar инициирует элемент Use Case Manage Curriculum (рис. 17.9).
Рис. 17.9. Отношения между актерами и элементами Use Case
1. На панели инструментов щелкните по значку однонаправленной ассоциации (стрелке).
2. Щелкните по актеру Student и перетащите линию на элемент Use Case Register for Courses.
3. На панели инструментов щелкните по значку однонаправленной ассоциации (стрелке).
4. Щелкните по элементу Use Case Register for Courses и перетащите линию на актера Billing System.
5. Повторите предыдущие шаги для ввода других отношений (от актера Professor к элементу Use Case Request Course Roster и от актера Registrar к элементу Use Case Manage Curriculum).
Создание компонентной диаграммы
Допустим, что наступил момент, когда нужно генерировать коды для классов модели. Для определения компонентов исходного кода используют компонентное представление (Component View) (рис. 17.30). Среда Rational Rose автоматически создает главную компонентную диаграмму.
1. В окне браузера щелкнем по значку + слева от пакета Component View.
2. Для открытия главной компонентной диаграммы выполним двойной щелчок по значку Main.
В общем случае каждому классу должны соответствовать два компонента — компонент спецификации и компонент реализации. В будущем каждому компоненту будет соответствовать свой файл. Например, в языке C++ классу соответствуют два файла-компонента: h-файл (файл спецификации) и срр-файл (файл реализации).
В нашей модели мы создадим один компонент для представления файла спецификации по классу CourseOffering и один компонент для представления файла реализации по классу CourseOffering (рис. 17.31).
Эти файлы будут иметь расширения .ads и .adb соответственно. Файл .ads имеет стереотип Package Specification. Файл .adb имеет стереотип Package Body.
1. На панели инструментов щелкните по значку спецификации пакета Package Specification.
2. Для добавления компонента в диаграмму щелкните в нужном месте диаграммы.
3. Пока новый компонент остается выделенным, введите его имя — CourseOffering.
4. Повторите предыдущие шаги с использованием значка тела пакета Package Body.
5. На панели инструментов щелкните по значку отношения зависимости.
6. Щелкните по компоненту, представляющему .adb-файл (тело пакета), и перетащите стрелку на компонент, представляющий .ads-файл (спецификация пакета).
Рис. 17.30. Компонентное представление — Component View
Рис. 17.31. Компонентное представление
После создания компонентов им должны быть назначены классы модели (рис. 17.32).
1. Выполним двукратный щелчок по значку компонента CourseOffering, представляющего .ads-файл (спецификацию пакета), в окне браузера или компонентной диаграмме. В результате станет видимым окно спецификации компонента.
2. Выберите страницу (вкладку) Realizes. Вы увидете список классов модели.
3. Щелкните правой кнопкой по классу CourseOffering. В результате станет видимым контекстное меню.
4. Выберите команду Assign.
5. Закройте окно спецификации, нажав кнопку ОК.
6. Выполните аналогичные действия для тела пакета, представляющего .adb-файл.
Рис. 17.32. Назначение классов компоненту
Создание СОМ-объектов
Создание СОМ-объекта базируется на использовании функций библиотеки СОМ. Библиотека СОМ:
q содержит функции, предлагающие базовые услуги объектам и их клиентам;
q предоставляет клиентам возможность запуска серверов СОМ-объектов.
Доступ к услугам библиотеки СОМ выполняется с помощью вызовов обычных функций. Чаще всего имена функций библиотеки СОМ начинаются с префикса «Со». Например, в библиотеке имеется функция CoCreateInstance.
Для создания СОМ-объекта клиент вызывает функцию библиотеки СОМ CoCreateInstance. В качестве параметров этой функции посылаются идентификатор класса объекта CLSID и IID интерфейса, поддерживаемого объектом. С помощью CLSID библиотека ищет сервер класса (это делает диспетчер управления сервисами SCM — Service Control Manager). Поиск производится в системном реестре (Registry), отображающем CLSID в адрес исполняемого кода сервера. В системном реестре должны быть зарегистрированы классы всех СОМ-объектов.
Закончив поиск, библиотека СОМ запускает сервер класса. В результате создается неинициализированный СОМ-объект, то есть объект, данные которого не определены. Описанный процесс иллюстрирует рис. 13.19.
Как правило, после получения указателя на созданный СОМ-объект клиент предлагает объекту самоинициализироваться, то есть загрузить себя конкретными значениями данных. Эту процедуру обеспечивают стандартные СОМ-интерфейсы IPersistFile, IPersistStorage и IPersistStream.
Рис. 13.19. Создание одиночного СОМ-объекта: 1 —клиент вызывает CoCreatelnstance
(CLSID M, IID А); 2 — библиотека СОМ находит сервер и запускает его;
3 — библиотека СОМ возвращает указатель на интерфейс А;
4 — теперь клиент может вызывать операции СОМ-объекта
Параметры функции CoCreateInstance, используемой клиентом, позволяют также задать тип сервера, который нужно запустить (например, «в процессе» или локальный).
В более общем случае клиент может создать несколько СОМ-объектов одного и того же класса.
Для этого клиент использует фабрику класса (class factory) — СОМ-объект, способный генерировать объекты одного конкретного класса.
Фабрика класса поддерживает интерфейс IClassfactory, включающий две операции. Операция Createlnstance создает СОМ-объект — экземпляр конкретного класса, имеет параметр — идентификатор интерфейса, указатель на который надо вернуть клиенту. Операция LockServer позволяет сохранять сервер фабрики загруженным в память.
Клиент вызывает фабрику с помощью функции библиотеки COM CoGetClassObject:
В качестве третьего параметра функции можно задать тип запускаемого сервера.
Библиотека СОМ запускает фабрику класса и возвращает указатель на интерфейс IClassFactory этой фабрики. Дальнейший порядок работы с помощью фабрики иллюстрирует рис. 13.20.
Рис. 13.20. Создание СОМ-объекта с помощью фабрики класса: 1 — клиент вызывает
IClassFactory :: Createlnstance (IID A); 2 — фабрика класса создает СОМ-объект и получает
указатель на его интерфейс; 3 — фабрика класса возвращает указатель на интерфейс А
СОМ-объекта; 4 — теперь клиент может вызывать операции СОМ-объекта
Клиент вызывает операцию IClassFactory::CreateInstance фабрики, в качестве параметра которой задает идентификатор необходимого интерфейса объекта (IID). В ответ фабрика класса создает СОМ-объект и возвращает указатель на заданный интерфейс. Теперь клиент применяет возвращенный указатель для вызова операций СОМ-объекта.
Очень часто возникает следующая ситуация — существующий СОМ-класс заменили другим, поддерживающим как старые, так и дополнительные интерфейсы и имеющим другой CLSID. Появляется задача — обеспечить использование нового СОМ-класса старыми клиентами. Обычным решением является запись в системный реестр соответствия между старым и новым CLSID. Запись выполняется с помощью библиотечной функции CoTreatAsClass:
CoTreatAsClass (<старый CLSID>, <новый CLSID>).
Спецификация элементов Use Case
Спецификация элемента Use Case — основной источник информации для выполнения анализа и проектирования системы. Очень важно, чтобы содержание спецификации было представлено в полной и конструктивной форме. В общем случае спецификация включает главный поток, подпотоки и альтернативные потоки поведения. В качестве шаблона спецификации представим описание элемента Use Case «Покупать авиабилет» для модели информационной системы авиакассы.
Предусловие: перед началом этого элемента Use Case должен быть выполнен элемент Use Case «Заполнить базу данных авиарейсов».
Спиральная модель
Спиральная модель — классический пример применения эволюционной стратегии конструирования.
Спиральная модель (автор Барри Боэм, 1988) базируется на лучших свойствах классического жизненного цикла и макетирования, к которым добавляется новый элемент — анализ риска, отсутствующий в этих парадигмах [19].
Как показано на рис. 1.6, модель определяет четыре действия, представляемые четырьмя квадрантами спирали.
1. Планирование — определение целей, вариантов и ограничений.
2. Анализ риска — анализ вариантов и распознавание/выбор риска.
3. Конструирование — разработка продукта следующего уровня.
4. Оценивание — оценка заказчиком текущих результатов конструирования.
Интегрирующий аспект спиральной модели очевиден при учете радиального измерения спирали. С каждой итерацией по спирали (продвижением от центра к периферии) строятся все более полные версии ПО.
В первом витке спирали определяются начальные цели, варианты и ограничения, распознается и анализируется риск. Если анализ риска показывает неопределенность требований, на помощь разработчику и заказчику приходит макетирование (используемое в квадранте конструирования). Для дальнейшего определения проблемных и уточненных требований может быть использовано моделирование. Заказчик оценивает инженерную (конструкторскую) работу и вносит предложения по модификации (квадрант оценки заказчиком). Следующая фаза планирования и анализа риска базируется на предложениях заказчика. В каждом цикле по спирали результаты анализа риска формируются в виде «продолжать, не продолжать». Если риск слишком велик, проект может быть остановлен.
В большинстве случаев движение по спирали продолжается, с каждым шагом продвигая разработчиков к более общей модели системы. В каждом цикле по спирали требуется конструирование (нижний правый квадрант), которое может быть реализовано классическим жизненным циклом или макетированием. Заметим, что количество действий по разработке (происходящих в правом нижнем квадранте) возрастает по мере продвижения от центра спирали.
Достоинства спиральной модели:
1) наиболее реально (в виде эволюции) отображает разработку программного обеспечения;
2) позволяет явно учитывать риск на каждом витке эволюции разработки;
3) включает шаг системного подхода в итерационную структуру разработки;
4) использует моделирование для уменьшения риска и совершенствования программного изделия.
3) трудности контроля и управления временем разработки.
Список литературы
1. Боэм Б. У. Инженерное проектирование программного обеспечения. М.: Радио и связь, 1985. 511 с.
2. Липаев В. В. Отладка сложных программ: Методы, средства, технология. М.: Энергоатомиздат, 1993. 384 с.
3. Майерс Г. Искусство тестирования программ. М.: Финансы и статистика, 1982. 176с.
4. Орлов С. А. Принципы объектно-ориентированного и параллельного программирования на языке Ada 95. Рига: TSI, 2001. 327 с.
5. Чеппел Д. Технологии ActiveX и OLE. M.: Русская редакция, 1997. 320 с.
6. Abreu, F. В., Esteves, R., Goulao, M. The Design of Eiffel Programs: Quantitative Evaluation Using the MOOD metrics. Proceedings of the TOOLS'96. Santa Barbara, California 20 pp. July 1996.
7. Albrecht, A. J. Measuring Application Development Productivity. Proc. IBM Application Development Symposium, Oct. 1979, pp. 83-92.
8. Ambler, S. W. The Object Primer. 2nd ed. Cambrige University Press, 2001. 541 pp.
9. Beck, K., and Cunningham, W. A Laboratory for Teaching Object-oriented Thinking. SIGPLAN Notices vol. 24 (10), October 1989, pp 1-7.
10. Beck, K. Embracing Change with Extreme Programming. IEEE Computer, Vol. 32, No. 10, October 1999, pp. 70-77.
11. Beck, K. Extreme Programming Explained. Embrace Change. Addison-Wesley, 1999.211pp.
ed. New York: International Thomson Computer Press, 1990. 503 pp.
14. Beizer, B. Black-Box Testing: Techniques for Functional Testing of Software and Systems. New York: John Wiley & Sons, 1995. 320 pp.
15. Bieman, J. M. and Kang, B-K. Cohesion and Reuse in an Object-Oriented System. Proc. ACM Symposium on Software Reusability (SSR'95), pp. 259-262, April 1995.
16. Binder, R. V. Testing object-oriented systems: a status report. American Programmer 7 (4), April 1994, pp. 22-28.
17. Binder, R. V. Design for Testability in Object-Oriented Systems. Communications of the ACM, vol. 37, No 9, September 1994, pp. 87-101.
18. Binder, R. V. Testing Object-Oriented Systems. Models, Patterns, and Tools. Ad-dison-Wesley, 1999. 1298 pp.
19. Boehm, B. W. A spiral model of software development and enhancement. IEEE Computer, 21 (5), 1988, pp. 61-72.
20. Boehm, B. W. Software Risk Management: Principles and Practices. IEEE Software, January 1991: pp. 32-41.
21. Boehm, B. W. etal. Software Cost Estimation with Cocomo II. Prentice Hall, 2001. 502 pp.
22. Booch, G. Object-Oriented analysis and design. 2nd Edition. Addison-Wesley, 1994. 590 pp.
23. Booch, G., Rumbaugh, J., Jacobcon, I. The Unified Modeling Language User Guide. Addison-Wesley, 1999. 483 pp.
24. Chidamber, S. R. and Kemerer, C. F. A Metrics Suite for Object Oriented Design. IEEE Transactions on Software Engineering, vol. 20: 476-493. No. 6, June 1994.
25. Cockburn, A. Agile Software Development. Addison-Wesley, 2001. 220 pp.
26. Coplien, J. O. Multi-Paradigm Design for C++. Addison-Wesley, 1999. 297 pp.
27. DeMarco, Т.. Structured Analysis and System Specification. Englewood Cliffs, NJ: Prentice-Hall, 1979.
28. Fenton, N. E., Pfleeger S. L. Software Metrics: A Rigorous & Practical Approach. 2nd Edition. International Thomson Computer Press, 1997. 647 pp.
29. Fowler, M. The New Methodology http://www.martinfowler.com, 2001.
30. Fowler, M. Is Design Dead? Proceedings of the XP 2000 conference, the Mediterranean island of Sardinia, 11 pp., June 2000.
31. Gamma, E., Helm, R., Johnson, R., Vlissides, J. Design Patterns. Elements of Reusable Object-Oriented Software. Addison-Wesley, 1995. 410 pp.
32. Graham, I. Object-Oriented Methods. Principles & Practice. 3rd Edition.
Addison-Wesley, 2001. 853 pp.
33. Halstead, M. H. Elements of Software Science. New York, Elsevier North-Holland, 1977.
34. Hatley, D., and Pirbhai, I. Strategies for Real-Time System Specification. New York, NY: Dorset House, 1988.
35. Henry, S. and Kafura, D. Software Structure Metrics Based on Information Flow. IEEE Transactions on Software Engineering, vol. 7, No. 5,pp. 510-518, Sept. 1981.
36. Highsmith, J. A. Adaptive Software Development: A Collaborative Approach to Managing Complex Systems. Dorset House Publishing, 2000. 392 pp.
37. Highsmith, J. A. Extreme programming, e-business Application Delivery, vol. XII, No. 2; February 2000, pp 1-16.
38. Hitz, M., Montazeri, В. Measuring Coupling in Object-Oriented Systems. Object Currents, vol. 2: 17 pp., No 4, Apr 1996.
39. Jackson, M. A. Principles of Program Design. London: Academic Press, 1975.
40. Jacobcon, I., Booch, G., Rumbaugh, J. The Unified Software Development Process. Addison-Wesley, 1999. 463 pp.
41. Jacobcon, I., Christerson, M., Jonsson, P., Overgaard, G. J. Object-Oriented Software Engineering. Addison-Wesley, 1993. 528 pp.
42. Jorgensen, P. C. and Erickson, C. Object Oriented Integration. Communications of the ACM, vol. 37, No 9, September 1994, pp. 30-38.
43. Kirani, S. and Tsai, W. T. Specification and Verification of Object-Oriented programs, Technical Report TR 94-64 Computer Science Department University of Minnesota, December 1994. 99 pp.
44. Kruchten, Phillipe B. The 4+1 View Model of Architecture. IEEE Software, Vol. 12 (6), November 1995, pp. 42-50.
45. Lorenz, M. and Kidd, J. Object-Oriented Software Metrics. Prentice Hall, 1994. 146pp.
46. Marick, B. Notes on Object-Oriented Testing. Part 1: Fault-Based Test Design. Testing Foundations Inc., 1995. 7 pp.
47. Marick, B. Notes on Object-Oriented Testing Part 2: Scenario-Based Test Design. Testing Foundations Inc., 1995. 4 pp.
48. Martin, Robert C.
RUP/XP Guidelines: Test- first Design and Refactoring. Rational Software White Paper, 2000.
49. McCabe, T. J. A Complexity Measure. IEEE Transactions on Software Engineering, vol. 2: pp. 308-320. No.4, Apr 1976.
50. McGregor, J.D. and Korson, T.D. Integrated Object Oriented testing and Development Processes. Communications of the ACM, vol. 37, No 9, September 1994, pp. 59-77.
51. McGregor, J. D., Sykes, D. A. A Practical Guide to Testing Object-Oriented Software. Addison-Wesley, 2001. 407 pp.
52. Myers, G. Composite Structured Design. New York, NY: Van Nostrand Reinhold, 1978.
53. OMG Unified Modeling Language Specification. Version 1.4. Object Management Group, Inc., 2001.566pp.
54. Orr, K. T. Structured Systems Analysis. Englewood Cliffs, NJ: Yourdon Press, 1977.
55. Ott, L., Bieman, J. M., Kang, B-K., Mehra, B. Developing Measures of Class Cohesion for Object-Oriented Software. Proc. Annual Oregon Workshop on Software Merics (AOWSM'95). 11 pp., June 1995.
56. Oviedo, E. I. Control Flow, Data Flow and Program Complexity. Proc. IEEE COMPSAC,Nov. 1980, pp. 146-152.
57. Quatrani, T. Visual Modeling with Rational Rose and UML. Addison-Wesley, 1998. 222pp.
58. Page-Jones, M. The Practical Guide to Structured Systems Design. Englewood Cliffs, NY: Yourdon Press, 1988.
59. Page-Jones, M. Fundamentals of Object-Oriented Design in UML. Addison - Wesley, 2001. 479 pp.
60. Parnas, D. On the Criteria to the Be Used in Decomposing Systems into Modules. Communications of the ACM vol. 15 (12), December, 1972, pp. 1053-1058.
61. Paulk, M. C., B. Curtis, M. B. Chrissis, and C. V. Weber. Capability Maturity Model, Version 1.1. IEEE Software, 10, 4, July 1993, pp. 18-27.
62. Paulk, M. C. Extreme Programming from a CMM Perspective. XP Universe, Raleigh, NC, 23-25 July 2001, 8 pp.
63. Poston, R. M. Automated Testing from Object Models. Communications of the ACM, vol. 37, No 9, September 1994, pp. 48-58.
64. Pressman, R. S. Software Engineering: A Practioner's Approach. 5th ed. McGraw-Hill, 2000. 943 pp.
65. Royce, Walker W. Managing the development of large software systems: concepts and techniques. Proc. IEEE WESTCON, Los Angeles, August 1970, pp. 1-9.
66. Rumbaugh J., Blaha M., Premerlani W., Eddy F. and Lorensen W. Object Oriented Modeling and Design. Prentice Hall, 1991. 500 pp.
67. Rumbaugh, J., Jacobcon, I., Booch, G., The Unified Modeling Language Reference Manual. Addison-Wesley, 1999. 567 pp.
68. Shalloway, A., Trott, J. R. Design Patterns Explained. A New Perspective on Object-Oriented Design. Addison - Wesley, 2002. 361 pp.
69. Sommerville, I. Software Engineering. 6th
ed. Addison-Wesley, 2001. 713 pp.
70. Stevens, W., Myers, G., and Constantine, L. 1979. Structured Design. IBM Systems Journal, Vol. 13(2), 1974, pp. 115-139.
71. Vliet, J. C. van. Software Engineering: Principles and Practice. John Wiley & Sons, 1993.558pp.
72. Tai, K., and Su, H. Test Generation for Boolean Expressions. Proc. COMPSAC'87, October 1987, pp. 278-283.
73. Ward, P., and Mellor, S. Structured Development for Real-Time Systems: Introduction and Tools. Vols. 1, 2, and 3. Englewood Cliffs, NJ: Yourdon Press, 1985.
74. Warnier, J. D. Logical Construction of Programs. New York: Van Nostrand Rein-hold, 1974.
75. Wells, J. D. Extreme Programming: A gentle introduction, http:// www.extreme-programming.org, 2001.
76. Wirfs-Brock, R., Wilkerson, В., and Wiener, L. Designing Object-oriented Software. Englewood Cliffs, New Jersey: Prentice Hall, 1990. 341 pp.
77. Yourdon, E., and Constantine, L. Structured Design: fundamentals of a discipline of computer program and systems design. Englewood Cliffs, NJ: Prentice-Hall, 1979.
Как правило, большая часть ошибок происходит на границах области ввода, а не в центре. Анализ граничных значений заключается в получении тестовых вариантов, которые анализируют граничные значения [3], [14], [69]. Данный способ тестирования дополняет способ разбиения по эквивалентности.
Основные отличия анализа граничных значений от разбиения по эквивалентности:
1) тестовые варианты создаются для проверки только ребер классов эквивалентности;
2) при создании тестовых вариантов учитывают не только условия ввода, но и область вывода.
Сформулируем правила анализа граничных значений.
1. Если условие ввода задает диапазон п...т, то тестовые варианты должны быть построены:
q для значений п и т;
q для значений чуть левее п и чуть правее т на числовой оси.
Например, если задан входной диапазон -1,0...+1,0, то создаются тесты для значений - 1,0, +1,0, - 1,001, +1,001.
2. Если условие ввода задает дискретное множество значений, то создаются тестовые варианты:
q для проверки минимального и максимального из значений;
q для значений чуть меньше минимума и чуть больше максимума.
Так, если входной файл может содержать от 1 до 255 записей, то создаются тесты для О, 1, 255, 256 записей.
3. Правила 1 и 2 применяются к условиям области вывода.
Рассмотрим пример, когда в программе требуется выводить таблицу значений. Количество строк и столбцов в таблице меняется. Задается тестовый вариант для минимального вывода (по объему таблицы), а также тестовый вариант для максимального вывода (по объему таблицы).
4. Если внутренние структуры данных программы имеют предписанные границы, то разрабатываются тестовые варианты, проверяющие эти структуры на их границах.
5. Если входные или выходные данные программы являются упорядоченными множествами (например, последовательным файлом, линейным списком, таблицей), то надо тестировать обработку первого и последнего элементов этих множеств.
Большинство разработчиков используют этот способ интуитивно. При применении описанных правил тестирование границ будет более полным, в связи с чем возрастет вероятность обнаружения ошибок.
Рассмотрим применение способов разбиения по эквивалентности и анализа граничных значений на конкретном примере. Положим, что нужно протестировать программу бинарного поиска. Нам известна спецификация этой программы. Поиск выполняется в массиве элементов М, возвращается индекс I элемента массива, значение которого соответствует ключу поиска Key.
Предусловия:
1) массив должен быть упорядочен;
2) массив должен иметь не менее одного элемента;
3) нижняя граница массива (индекс) должна быть меньше или равна его верхней границе.
Постусловия:
1) если элемент найден, то флаг Result=True, значение I — номер элемента;
2) если элемент не найден, то флаг Result=False, значение I не определено.
Для формирования классов эквивалентности (и их ребер) надо произвести разбиение области ИД — построить дерево разбиений. Листья дерева разбиений дадут нам искомые классы эквивалентности. Определим стратегию разбиения. На первом уровне будем анализировать выполнимость предусловий, на втором уровне — выполнимость постусловий. На третьем уровне можно анализировать специальные требования, полученные из практики разработчика. В нашем примере мы знаем, что входной массив должен быть упорядочен. Обработка упорядоченных наборов из четного и нечетного количества элементов может выполняться по-разному. Кроме того, принято выделять специальный случай одноэлементного массива. Следовательно, на уровне специальных требований возможны следующие эквивалентные разбиения:
1) массив из одного элемента;
2) массив из четного количества элементов;
3) массив из нечетного количества элементов, большего единицы.
Наконец на последнем, 4-м уровне критерием разбиения может быть анализ ребер классов эквивалентности. Очевидно, возможны следующие варианты:
1) работа с первым элементом массива;
2) работа с последним элементом массива;
3) работа с промежуточным (ни с первым, ни с последним) элементом массива.
Структура дерева разбиений приведена на рис. 7.3.
Рис. 7.3. Дерево разбиений области исходных данных бинарного поиска
Это дерево имеет 11 листьев. Каждый лист задает отдельный тестовый вариант. Покажем тестовые варианты, основанные на проведенных разбиениях.
Тестовый вариант 1 (единичный массив, элемент найден) ТВ1:
ИД: М=15; Кеу=15.
ОЖ.РЕЗ.: Resutt=True; I=1.
Тестовый вариант 2 (четный массив, найден 1-й элемент) ТВ2:
ИД: М=15, 20, 25,30,35,40; Кеу=15.
ОЖ.РЕЗ.: Result=True; I=1.
Тестовый вариант 3 (четный массив, найден последний элемент) ТВЗ:
ИД: М=15, 20, 25, 30, 35, 40; Кеу=40.
ОЖ.РЕЗ:. Result=True; I=6.
Тестовый вариант 4 (четный массив, найден промежуточный элемент) ТВ4:
ИД: М=15,20,25,30,35,40; Кеу=25.
ОЖ.РЕЗ.: Result-True; I=3.
Тестовый вариант 5 (нечетный массив, найден 1-й элемент) ТВ5:
ИД: М=15, 20, 25, 30, 35,40, 45; Кеу=15.
ОЖ.РЕЗ.: Result=True; I=1.
Тестовый вариант 6 (нечетный массив, найден последний элемент) ТВ6:
ИД: М=15, 20, 25, 30,35, 40,45; Кеу=45.
ОЖ.РЕЗ.: Result=True; I=7.
Тестовый вариант 7 (нечетный массив, найден промежуточный элемент) ТВ7:
ИД: М=15, 20, 25, 30,35, 40, 45; Кеу=30.
ОЖ.РЕЗ.: Result=True; I=4.
Тестовый вариант 8 (четный массив, не найден элемент) ТВ8:
ИД: М=15, 20, 25, 30, 35,40; Кеу=23.
ОЖ.РЕЗ.: Result=False; I=?
Тестовый вариант 9 (нечетный массив, не найден элемент) ТВ9;
ИД: М=15, 20, 25, 30, 35, 40, 45; Кеу=24.
ОЖ.РЕЗ:. Result=False; I=?
Тестовый вариант 10 (единичный массив, не найден элемент) ТВ10:
ИД: М=15; Кеу=0.
ОЖ.РЕЗ.: Result=False; I=?
Тестовый вариант 11 (нарушены предусловия) ТВ11:
ИД: М=15, 10, 5, 25, 20, 40, 35; Кеу=35.
ОЖ.РЕЗ.: Аварийное донесение: Массив не упорядочен.
Способ диаграмм причин-следствий
Диаграммы причинно-следственных связей — способ проектирования тестовых вариантов, который обеспечивает формальную запись логических условий и соответствующих действий [3], [64]. Используется автоматный подход к решению задачи.
Шаги способа:
1) для каждого модуля перечисляются причины (условия ввода или классы эквивалентности условий ввода) и следствия (действия или условия вывода). Каждой причине и следствию присваивается свой идентификатор;
2) разрабатывается граф причинно-следственных связей;
3) граф преобразуется в таблицу решений;
4) столбцы таблицы решений преобразуются в тестовые варианты.
Изобразим базовые символы для записи графов причин и следствий (cause-effect graphs).
2) каждый узел графа может находиться в состоянии 0 или 1 (0 — состояние отсутствует, 1 — состояние присутствует).
Функция тождество (рис. 7.4) устанавливает, что если значение с1 есть 1, то и значение е1
есть 1; в противном случае значение е1 есть 0.
Рис. 7.4. Функция тождество
Функция не (рис. 7.5) устанавливает, что если значение с1 есть 1, то значение e1 есть 0; в противном случае значение е1
есть 1.
Рис. 7.5. Функция не
Функция или (рис. 7.6) устанавливает, что если с1 или с2 есть 1, то е1 есть 1, в противном случае e1 есть 0.
Рис. 7.6. Функция или
Функция и (рис. 7.7) устанавливает, что если и с1 и с2 есть 1, то е1
есть 1, в противном случае е1 есть 0.
Часто определенные комбинации причин невозможны из-за синтаксических или внешних ограничений. Используются перечисленные ниже обозначения ограничений.
Рис. 7.7. Функция и
Ограничение Е (исключает, Exclusive, рис. 7.8) устанавливает, что Е должно быть истинным, если хотя бы одна из причин — а или b — принимает значение 1 (а и b не могут принимать значение 1 одновременно).
Рис. 7.8. Ограничение Е (исключает, Exclusive)
Ограничение I (включает, Inclusive, рис. 7.9) устанавливает, что по крайней мере одна из величин, а, b, или с, всегда должна быть равной 1 (а, b и с не могут принимать значение 0 одновременно).
Рис. 7.9. Ограничение I (включает, Inclusive)
Ограничение О (одно и только одно, Only one, рис. 7.10) устанавливает, что одна и только одна из величин а или b должна быть равна 1.
Рис. 7.10. Ограничение О (одно и только одно, Only one)
Ограничение R (требует, Requires, рис. 7.11) устанавливает, что если а принимает значение 1, то и b должна принимать значение 1 (нельзя, чтобы а было равно 1, a b - 0).
Рис. 7.11. Ограничение R (требует, Requires)
Часто возникает необходимость в ограничениях для следствий.
Ограничение М (скрывает, Masks, рис. 7.12) устанавливает, что если следствие а имеет значение 1, то следствие b должно принять значение 0.
Рис. 7.12. Ограничение М (скрывает, Masks)
Для иллюстрации использования способа рассмотрим пример, когда программа выполняет расчет оплаты за электричество по среднему или переменному тарифу.
При расчете по среднему тарифу:
q при месячном потреблении энергии меньшем, чем 100 кВт/ч, выставляется фиксированная сумма;
q при потреблении энергии большем или равном 100 кВт/ч применяется процедура А планирования расчета.
При расчете по переменному тарифу:
q при месячном потреблении энергии меньшем, чем 100 кВт/ч, применяется процедура А планирования расчета;
q при потреблении энергии большем или равном 100 кВт/ч применяется процедура В планирования расчета.
Шаг 1. Причинами являются:
1) расчет по среднему тарифу;
2) расчет по переменному тарифу;
3) месячное потребление электроэнергии меньшее, чем 100 кВт/ч;
4) месячное потребление электроэнергии большее или равное 100 кВт/ч.
На основе различных комбинаций причин можно перечислить следующие следствия:
q 101 — минимальная месячная стоимость;
q 102 — процедура А планирования расчета;
q 103 — процедура В планирования расчета.
Шаг 2. Разработка графа причинно-следственных связей (рис. 7.13).
Узлы причин перечислим по вертикали у левого края рисунка, а узлы следствий — у правого края рисунка. Для следствия 102 возникает необходимость введения вторичных причин — 11 и 12, — их размещаем в центральной части рисунка.
Рис. 7.13. Граф причинно-следственных связей
Шаг 3. Генерация таблицы решений. При генерации причины рассматриваются как условия, а следствия — как действия.
Порядок генерации.
1. Выбирается некоторое следствие, которое должно быть в состоянии «1».
2. Находятся все комбинации причин (с учетом ограничений), которые устанавливают это следствие в состояние «1». Для этого из следствия прокладывается обратная трасса через граф.
3. Для каждой комбинации причин, приводящих следствие в состояние «1», строится один столбец.
4. Для каждой комбинации причин доопределяются состояния всех других следствий. Они помещаются в тот же столбец таблицы решений.
5. Действия 1-4 повторяются для всех следствий графа.
Таблица решений для нашего примера показана в табл. 7.1.
Шаг 4. Преобразование каждого столбца таблицы в тестовый вариант. В нашем примере таких вариантов четыре.
Тестовый вариант 1 (столбец 1) ТВ1:
ИД: расчет по среднему тарифу; месячное потребление электроэнергии 75 кВт/ч.
ОЖ.РЕЗ.: минимальная месячная стоимость.
Тестовый вариант 2 (столбец 2) ТВ2:
ИД: расчет по переменному тарифу; месячное потребление электроэнергии 90 кВт/ч.
ОЖ.РЕЗ.: процедура A планирования расчета.
Тестовый вариант 3 (столбец 3) ТВЗ:
ИД: расчет по среднему тарифу; месячное потребление электроэнергии 100 кВт/ч.
ОЖ.РЕЗ.: процедура А планирования расчета.
Тестовый вариант 4 (столбец 4) ТВ4:
ИД: расчет по переменному тарифу; месячное потребление электроэнергии 100 кВт/ч.
ОЖ.РЕЗ.: процедура В планирования расчета.
Таблица 7.1. Таблица решений для расчета оплаты за электричество
Номера столбцов — >
1
2
3
4
Условия
Причины
1
1
0
1
0
2
0
1
0
1
3
1
1
0
0
4
0
0
1
1
Вторичные причины
11
0
0
1
0
12
0
1
0
0
Действия
Следствия
101
1
0
0
0
102
0
1
1
0
103
0
0
0
1
Способ разбиения по эквивалентности
Разбиение по эквивалентности — самый популярный способ тестирования «черного ящика» [3], [14].
В этом способе входная область данных программы делится на классы эквивалентности. Для каждого класса эквивалентности разрабатывается один тестовый вариант.
Класс эквивалентности — набор данных с общими свойствами. Обрабатывая разные элементы класса, программа должна вести себя одинаково. Иначе говоря, при обработке любого набора из класса эквивалентности в программе задействуется один и тот же набор операторов (и связей между ними).
На рис. 7.2 каждый класс эквивалентности показан эллипсом. Здесь выделены входные классы эквивалентности допустимых и недопустимых исходных данных, а также классы результатов.
Классы эквивалентности могут быть определены по спецификации на программу.
Рис. 7.2. Разбиение по эквивалентности
Например, если спецификация задает в качестве допустимых входных величин 5-разрядные целые числа в диапазоне 15 000...70 000, то класс эквивалентности допустимых ИД (исходных данных) включает величины от 15 000 до 70 000, а два класса эквивалентности недопустимых ИД составляют:
q числа меньшие, чем 15 000;
q числа большие, чем 70 000.
Класс эквивалентности включает множество значений данных, допустимых или недопустимых по условиям ввода.
Условие ввода может задавать:
1) определенное значение;
2) диапазон значений;
3) множество конкретных величин;
4) булево условие.
Сформулируем правила формирования классов эквивалентности.
1. Если условие ввода задает диапазон п...т, то определяются один допустимый и два недопустимых класса эквивалентности:
q V_Class={n.. .т} — допустимый класс эквивалентности;
q Inv_С1аss1={x|для любого х: х < п} — первый недопустимый класс эквивалентности;
q Inv_С1аss2={y|для любого у: у > т} — второй недопустимый класс эквивалентности.
2. Если условие ввода задает конкретное значение а, то определяется один допустимый и два недопустимых класса эквивалентности:
q V_Class={a};
q Inv_Class1 ={х|для
любого х: х < а};
q Inv_С1аss2={y|для любого у: у > а}.
3. Если условие ввода задает множество значений {а, b, с}, то определяются один допустимый и один недопустимый класс эквивалентности:
q V_Class={a, b, с};
q Inv_С1аss={x|для любого х: (х
а)&(х
b)&(х
с)}.
4. Если условие ввода задает булево значение, например true, то определяются один допустимый и один недопустимый класс эквивалентности:
q V_Class={true};
q Inv_Class={false}.
После построения классов эквивалентности разрабатываются тестовые варианты. Тестовый вариант выбирается так, чтобы проверить сразу наибольшее количество свойств класса эквивалентности.
Способ тестирования базового пути
Тестирование базового пути — это способ, который основан на принципе «белого ящика». Автор этого способа — Том МакКейб (1976) [49].
Способ тестирования базового пути дает возможность:
q получить оценку комплексной сложности программы;
q использовать эту оценку для определения необходимого количества тестовых вариантов.
Тестовые варианты разрабатываются для проверки базового множества путей (маршрутов) в программе. Они гарантируют однократное выполнение каждого оператора программы при тестировании.
Способ тестирования потоков данных
В предыдущих способах тесты строились на основе анализа управляющей структуры программы. В данном способе анализу подвергается информационная структура программы.
Работу любой программы можно рассматривать как обработку потока данных, передаваемых от входа в программу к ее выходу.
Рассмотрим пример.
Пусть потоковый граф программы имеет вид, представленный на рис. 6.8. В нем сплошные дуги — это связи по управлению между операторами в программе. Пунктирные дуги отмечают информационные связи (связи по потокам данных). Обозначенные здесь информационные связи соответствуют следующим допущениям:
q в вершине 1 определяются значения переменных а, b;
q значение переменной а используется в вершине 4;
q значение переменной b используется в вершинах 3, 6;
q в вершине 4 определяется значение переменной с, которая используется в вершине 6.
Рис. 6.8. Граф программы с управляющими и информационными связями
В общем случае для каждой вершины графа можно записать:
q множество определений данных
DEF(i) = { х | i -я вершина содержит определение х};
q множество использований данных:
USE (i) = { х | i -я вершина использует х}.
Под определением данных понимают действия, изменяющие элемент данных. Признак определения — имя элемента стоит в левой части оператора присваивания:
x:=f(…).
Использование данных — это применение элемента в выражении, где происходит обращение к элементу данных, но не изменение элемента. Признак использования — имя элемента стоит в правой части оператора присваивания:
#:=f(x).
Здесь место подстановки другого имени отмечено прямоугольником (прямоугольник играет роль метки-заполнителя).
Назовём DU-цепочкой (цепочкой определения-использования) конструкцию [х, i,j], где i,j — имена вершин; х определена в i-й вершине (х
DЕF(i)) и используется в j -й вершине (х
USE(j)).
В нашем примере существуют следующие DU-цепочки:
[а,1,4],[b, 1,3], [b, 1,6], [с, 4, 6].
Способ DU-тестирования требует охвата всех DU-цепочек программы. Таким образом, разработка тестов здесь проводится на основе анализа жизни всех данных программы.
Очевидно, что для подготовки тестов требуется выделение маршрутов — путей выполнения программы на управляющем графе. Критерий для выбора пути — покрытие максимального количества DU-цепочек.
Шаги способа DU-тестирования:
1) построение управляющего графа (УГ) программы;
2) построение информационного графа (ИГ);
3) формирование полного набора DU-цепочек;
4) формирование полного набора отрезков путей в управляющем графе (отображением набора DU-цепочек информационного графа, рис. 6.9);
Рис. 6.9. Отображение DU-цепочки в отрезок пути
5) построение маршрутов — полных путей на управляющем графе, покрывающих набор отрезков путей управляющего графа;
6) подготовка тестовых вариантов.
Достоинства DU-тестирования:
q простота необходимого анализа операционно-управляющей структуры программы;
q простота автоматизации.
Недостаток DU-тестирования: трудности в выборе минимального количества максимально эффективных тестов.
Область использования DU-тестирования: программы с вложенными условными операторами и операторами цикла.
Способы тестирования содержания класса
Описываемые ниже способы ориентированы на отдельный класс и операции, которые инкапсулированы классом.
Способы тестирования условий
Цель этого семейства способов тестирования — строить тестовые варианты для проверки логических условий программы. При этом желательно обеспечить охват операторов из всех ветвей программы.
Рассмотрим используемую здесь терминологию.
Простое условие — булева переменная или выражение отношения.
Выражение отношения имеет вид
Е1 <оператор отношения> E2,
где El, Е2 — арифметические выражения, а в качестве оператора отношения используется один из следующих операторов: <, >, =,
,
.
Составное условие состоит из нескольких простых условий, булевых операторов и круглых скобок. Будем применять булевы операторы OR, AND (&), NOT. Условия, не содержащие выражений отношения, называют булевыми выражениями.
Таким образом, элементами условия являются: булев оператор, булева переменная, пара скобок (заключающая простое или составное условие), оператор отношения, арифметическое выражение. Эти элементы определяют типы ошибок в условиях.
Если условие некорректно, то некорректен по меньшей мере один из элементов условия. Следовательно, в условии возможны следующие типы ошибок:
Способ тестирования условий ориентирован на тестирование каждого условия в программе. Методики тестирования условий имеют два достоинства. Во-первых, достаточно просто выполнить измерение тестового покрытия условия. Во-вторых, тестовое покрытие условий в программе — это фундамент для генерации дополнительных тестов программы.
Целью тестирования условий является определение не только ошибок в условиях, но и других ошибок в программах. Если набор тестов для программы А эффективен для обнаружения ошибок в условиях, содержащихся в А, то вероятно, что этот набор также эффективен для обнаружения других ошибок в А.
Кроме того, если методика тестирования эффективна для обнаружения ошибок в условии, то вероятно, что эта методика будет эффективна для обнаружения ошибок в программе.
Существует несколько методик тестирования условий.
Простейшая методика — тестирование ветвей. Здесь для составного условия С проверяется:
q каждое простое условие (входящее в него);
q Тruе-ветвь;
q False-ветвь.
Другая методика — тестирование области определения. В ней для выражения отношения требуется генерация 3-4 тестов. Выражение вида
Е1 <оператор отношения> Е2
проверяется тремя тестами, которые формируют значение Е1 большим, чем Е2, равным Е2 и меньшим, чем Е2.
Если оператор отношения неправилен, а Е1 и Е2 корректны, то эти три теста гарантируют обнаружение ошибки оператора отношения.
Для определения ошибок в Е1 и Е2 тест должен сформировать значение Е1 большим или меньшим, чем Е2, причем обеспечить как можно меньшую разницу между этими значениями.
Для булевых выражений с п переменными требуется набор из 2n
тестов. Этот набор позволяет обнаружить ошибки булевых операторов, переменных и скобок, но практичен только при малом п. Впрочем, если в булево выражение каждая булева переменная входит только один раз, то количество тестов легко уменьшается.
Обсудим способ тестирования условий, базирующийся на приведенных выше методиках.