Способы тестирования взаимодействия классов
Для тестирования сотрудничества классов могут использоваться различные способы [43]:
q стохастическое тестирование;
q тестирование разбиений;
q тестирование на основе сценариев;
q тестирование на основе состояний.
В качестве примера рассмотрим программную модель банковской системы, в состав которой входят классы Банк, Банкомат, ИнтерфейсБанкомата, Счет, Работа с наличными, ПодтверждениеПравильности, имеющие следующие операции:
| Банк: | |||||
| ПроверитьСчет( ); | ЗапросДепозита ( ); | РазрешитьКарту( ); | |||
| ПроверитьРIN( ); | ИнфоСчета( ); | СнятьРазрешен( ); | |||
| ПроверитьПолис( ); | ОткрытьСчет( ); | ЗакрытьСчет( ). | |||
| ЗапросСнятия( ); | НачальнДепозит( ); | ||||
| Банкомат: | |||||
| КартаВставлена( ); | Положить( ); | СостояниеСчета( ); | |||
| Пароль( ); | Снять( ); | Завершить( ). | |||
| ИнтерфейсБанкомата: | |||||
| ПроверитьСостояние( ); | ВыдатьНаличные( ); | ЧитатьИнфоКарты( ); | |||
| СостояниеПоложить( ); | ПечатьСостСчета( ); | ПолучитьКолвоНалич( ). | |||
| Счет: | |||||
| ОграничКредит( ); | Остаток) ); | Положить( ); | |||
| ТипСчета( ); | Снять( ); | Закрыть( ). | |||
| ПодтверждениеПравильности: | |||||
| ПодтвРIN( ); | ПодтвСчет( ). |
Диаграмма сотрудничества объектов банковской системы представлена на рис. 16.1. На этой диаграмме отображены связи между объектами, стрелки передачи сообщений подписаны именами вызываемых операций.
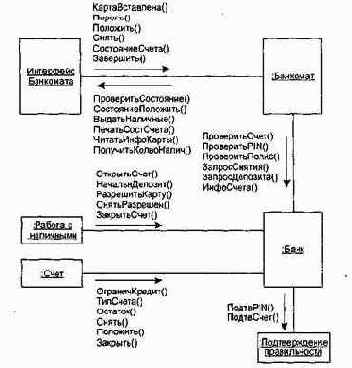
Рис. 16.1. Диаграмма сотрудничества банковской системы
Сравнение нисходящего и восходящего тестирования интеграции
Нисходящее тестирование:
1) основной недостаток— необходимость заглушек и связанные с ними трудности тестирования;
2) основное достоинство — возможность раннего тестирования главных управляющих функций.
Восходящее тестирование:
1) основной недостаток — система не существует как объект до тех пор, пока не будет добавлен последний модуль;
2) основное достоинство — упрощается разработка тестовых вариантов, отсутствуют заглушки.
Возможен комбинированный подход. В нем для верхних уровней иерархии применяют нисходящую стратегию, а для нижних уровней — восходящую стратегию тестирования [3], [13].
При проведении тестирования интеграции очень важно выявить критические модули. Признаки критического модуля:
1) реализует несколько требований к программной системе;
2) имеет высокий уровень управления (находится достаточно высоко в программной структуре);
3) имеет высокую сложность или склонность к ошибкам (как индикатор может использоваться цикломатическая сложность — ее верхний разумный предел составляет 10);
4) имеет определенные требования к производительности обработки.
Критические модули должны тестироваться как можно раньше. Кроме того, к ним должно применяться регрессионное тестирование (повторение уже выполненных тестов в полном или частичном объеме).
Стохастическое тестирование
Стохастические тестовые варианты генерируются следующей последовательностью шагов.
1. Для создания тестов используют списки операций каждого класса-клиента. Операции будут посылать сообщения в классы-серверы.
2. Для каждого созданного сообщения определяется класс-сотрудник и соответствующая операция в классе-сервере.
3. Для каждой операции в классе-сервере, которая вызывается сообщением из класса-клиента, определяются сообщения, которые она, в свою очередь, посылает.
4. Для каждого из сообщений определяется следующий уровень вызываемых операций; они вставляются в тестовую последовательность.
В качестве примера приведем последовательность операций для класса Банк, вызываемых классом Банкомат:
ПроверитьСчет >ПроверитьРIN >[[ПроверитьПолис >
ЗапросСнятия]?ЗапросДепозита?ИнфоСчета]n.
ПРИМЕЧАНИЕ
Здесь приняты следующие обозначения: стрелка означает операцию следования, точка — операцию И/ИЛИ, пара квадратных скобок — группировку операций классов, показатель степени — количество повторений группировки из операций классов.
Случайный тестовый вариант для класса Банк может иметь вид
Тестовый вариант N: ПроверитьСчет >ПроверитьРШ >ЗапросДепозита.
Для выявления сотрудников, включенных в этот тест, рассматриваются сообщения, связанные с каждой операцией, записанной в ТВ N. Для выполнения заданий ПроверитьСчет и ПроверитьРТМ Банк должен сотрудничать с классом ПодтверждениеПравильности. Для выполнения задания ЗапросДепозита Банк должен сотрудничать с классом Счет. Отсюда новый ТВ, который проверяет отмеченные сотрудничества:
Тестовый вариант М: ПроверитьСчетБанк >(ПодтвСчетПодтвПрав) >ПроверитьРINБанк >(ПодтвРШПодтвПрав) >ЗапросДепозитаБанк >(ПоложитьСчет).
В этой последовательности операции классов-сотрудников Банка помещены в круглые скобки, индексы отображают принадлежность операций к конкретным классам.
Стохастическое тестирование класса
При стохастическом тестировании исходные данные для тестовых вариантов генерируются случайным образом. Обсудим методику, предложенную С. Кирани и В.Тсай[43].
Рассмотрим класс Счет, который имеет следующие операции: Открыть, Установить, Положить, Снять, Остаток, Итог, ОграничитьКредит, Закрыть.
Каждая из этих операций применяется при определенных ограничениях:
q счет должен быть открыт перед применением других операций;
q счет должен быть закрыт после завершения всех операций.
Даже с этими ограничениями существует множество допустимых перестановок операций. Минимальная работа экземпляра Счета включает следующую последовательность операций:
Открыть > Установить > Положить > Снять > Закрыть.
Здесь стрелка обозначает операцию следования. Иначе говоря, здесь записано, что экземпляр Счета сначала выполняет операцию открытия, затем установки и т. д. Эта последовательность является минимальным тестовым вариантом для Счета. Впрочем, в эту последовательность можно встроить группировку, обеспечивающую создание других вариантов поведения:
Открыть > Установить > Положить > [Остаток?Снять?Итог?ОграничитьКредит?Положить]n > Снять > Закрыть.
Здесь приняты дополнительные обозначения: точка означает операцию И/ИЛИ, пара квадратных скобок — группировку, а показатель степени — количество повторений группировки.
Набор различных последовательностей может генерироваться случайным образом:
Тестовый вариант N:
Открыть > Установить > Положить > Остаток > Снять >Итог > Снять > Закрыть.
Тестовый вариант М:
Открыть > Установить > Положить > Итог > ОграничитьКредит > Снять > Остаток > Снять > Закрыть.
Эти и другие тесты случайных последовательностей проводятся для проверки различных вариантов жизни объектов.
Стоимость
[$]
Произв. [LOC/ чел.-мес] Затраты [чел-мес] СУПИ 1800 2400 2650 2340 14 32760 315 7,4 А2Г 4100 5200 7400 5380 20 107600 245 21,9 A3Г 4600 6900 8600 6800 20 136000 194 35,0 УБД 2950 3400 3600 3350 18 60300 240 13,9 КДГ 4050 4900 6200 4950 22 108900 200 24,7 УП 2000 2100 2450 2140 28 59920 140 15,2 МПА 6600 8500 9800 8400 18 151200 300 28,0 Итого 33360 656680 146Учитывая важность полученных результатов, проверим расчеты с помощью FP-указателей. На данном этапе оценивания разумно допустить, что все информационные характеристики имеют средний уровень сложности. В этом случае результаты экспертной оценки принимают вид, представленный в табл. 2.25, 2.26.
Таблица 2.25. Оценка информационных характеристик проекта
| Характеристика | Лучш. | Вероят. | Худш. | Ожид. | Сложность | Количество | |||||||
| Вводы | 20 | 24 | 30 | 24 | х 4 | 96 | |||||||
| Выводы | 12 | 15 | 22 | 16 | х 5 | 80 | |||||||
| Запросы | 16 | 22 | 28 | 22 | х 4 | 88 | |||||||
| Логические файлы | 4 | 4 | 5 | 4 | х 10 | 40 | |||||||
| Интерфейсные файлы | 2 | 2 | 3 | 2 | х 7 | 14 | |||||||
| Общее количество | 318 |
Таблица 2.26. Оценка системных параметров проекта
| Коэффициент регулировки сложности | Оценка | ||||
| F1 | Передачи данных | 2 | |||
| F2 | Распределенная обработка данных | 0 | |||
| F3 | Производительность | 4 | |||
| F4 | Распространенность используемой конфигурации | 3 | |||
| F5 | Скорость транзакций | 4 | |||
| F6 | Оперативный ввод данных | 5 | |||
| F7 | Эффективность работы конечного пользователя | 5 | |||
| F8 | Оперативное обновление | 3 | |||
| F9 | Сложность обработки | 5 | |||
| F10 | Повторная используемость | 4 | |||
| F11 | Легкость инсталляции | 3 | |||
| F12 | Легкость эксплуатации | 4 | |||
| F13 | Разнообразные условия размещения | 5 | |||
| F14 | Простота изменений | 5 |
Таким образом, получаем:
FР = Общее количество х (0,65+ 0,01 х

Используя значение производительности, взятое в метрическом базисе фирмы,
Производительность = 2,55 [FP / чел.-мес],
вычисляем значения затрат и стоимости:
Затраты = FP / Производительность = 145,9 [чел.-мес],
Стоимость = Затраты х $4500 = $656500.
Итак, результаты проверки показали хорошую достоверность результатов. Но мы не будем останавливаться на достигнутом и организуем еще одну проверку, с помощью модели СОСОМО II.
Примем, что все масштабные факторы и факторы затрат имеют номинальные значения. В силу этого показатель степени В = 1,16, а множитель поправки Мp= 1. Кроме того, будем считать, что автоматическая генерация кода и повторное использование компонентов не предусматриваются. Следовательно, мы вправе применить формулу
ЗАТРАТЫ = A х РАЗМЕРB[чел.-мес]
и получаем:
ЗАТРАТЫ = 2,5(33,3)1,16 =145,87 [чел.-мес].
Соответственно, номинальная длительность проекта равна
Длительность = [3,0 х (ЗАТРАТЫ)(0,33+0,2(B-1,01))]=3(145,87)0,36 = 18[мес].
Подведем итоги. Выполнена предварительная оценка программного проекта. Для минимизации риска оценивания использованы три методики, доказавшие корректность полученных результатов.
Стоимость изменения и проектирование
В основе организации прогнозирующих (тяжеловесных) процессов конструирования лежит утверждение об экспоненциальной кривой стоимости изменения. Согласно этой кривой, по мере развития проекта стоимость внесения изменений экспоненциально возрастает (рис. 15.20) — то, что на этапе формирования требований стоит единицу, на этапе сопровождения будет стоить тысячу.
В основе адаптивного (облегченного) ХР-процесса лежит предположение, что экспоненциальную кривую можно сгладить (рис. 15.21) [25], [30], [36], [37], [62]. Такое сглаживание, с одной стороны, возникает при применении методологии ХР, а с другой стороны, оно же в ней и применяется. Это еще раз подчеркивает тесную взаимосвязь между методами ХР: нельзя использовать методы, которые опираются на сглаживание, не используя другие методы, которые это сглаживание производят.
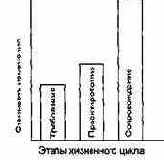
Рис. 15.20. Экспонента стоимости изменения в прогнозирующем процессе

Рис. 15.21. Сглаживание стоимости изменения в адаптивном процессе
К числу основных методов, осуществляющих сглаживание, относят:
q тотальное тестирование;
q непрерывную интеграцию;
q реорганизацию (рефакторинг).
Повторим — надежность кода, которую обеспечивает сквозное тестирование, создает базис успеха, обеспечивает остальные возможности ХР-разработки. Непрерывная интеграция необходима для синхронной работы всех сотрудников, так чтобы любой разработчик мог вносить в систему свои изменения и не беспокоиться об интеграции с остальными членами команды. Совместные усилия этих двух методов оказывают существенное воздействие на кривую стоимости изменений в программной системе.
О влиянии реорганизации (рефакторинга) очень интересно пишет Джим Хайсмит (Jim Highsmith) [37]. Он приводит аналогию с весами (см. рис. 15.22 и 15.23). На одной чаше весов лежит предварительное проектирование, на другой — реорганизация. В прогнозирующих процессах разработки перевешивает предварительное проектирование, поскольку скорость изменений низкая (на рисунке скорость иллюстрируется положением точки равновесия).
В адаптивных, облегченных процессах перевешивает реорганизация, так как скорость изменений высокая. Это не означает отказа от предварительного проектирования. Однако теперь можно говорить о существовании баланса между двумя подходами к проектированию, из которых можно выбрать наиболее подходящий подход.
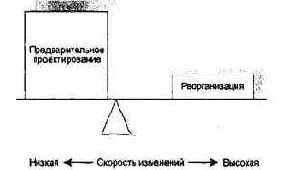
Рис. 15.22. Балансировка проектирования и реорганизации при прогнозе
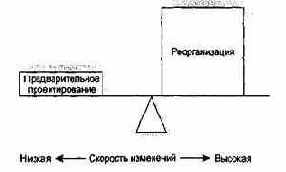
Рис. 15.23. Балансировка проектирования и реорганизации при адаптации
Итак, в адаптивных процессах вообще и в ХР-процессе в частности приветствуется простое проектирование.
Простое проектирование основывается на двух принципах:
q это вам не понадобится;
q ищите самое простое решение, которое может сработать.
Что означает первый принцип? Кажется, что все понятно — не надо сегодня писать код, который понадобится завтра. И все же сложности возникают, например, при создании гибких элементов (повторно используемых компонентов и паттернов), — ведь при этом вы смотрите в будущее, заранее добавляете к общей стоимости работ стоимость нужного проектирования и рассчитываете впоследствии вернуть эти деньги.
Тем не менее ХР не советует заниматься созданием гибких элементов заранее. Лучше, если они будут добавляться по мере необходимости. Если сегодня нужен класс Арифметика, который выполняет только сложение, то сегодня я буду встраивать в этот класс именно сложение. Даже если я уверен, что уже на следующей итерации понадобится умножение и мне легко реализовать его сейчас, все равно следует отложить эту работу до следующей итерации — когда в ней появится реальная необходимость.
Экономически такое поведение оправданно — незапланированная работа всегда крадет ресурсы у запланированной. Кроме того, отклонение от плана — это нарушение соглашений с заказчиком. К тому же появляется риск сорвать выполнение текущей работы. И даже если появилось свободное время, решение о его заполнении принимает заказчик («он сверху видит все, ты так и знай!»).
И еще одно оправдание — возможность ошибиться, ведь у нас еще нет подробных требований заказчика. А чем раньше мы введем в проект ошибочное решение, тем хуже.
Теперь о простоте решения. ХР-идеолог Кент Бек приводит четыре критерия простой системы:
q система успешно проходит все тесты;
q код системы ясно раскрывает все изначальные замыслы;
q в ней отсутствует дублирование кода;
q используется минимально возможное количество классов и методов.
Успешное тестирование — довольно понятный критерий. Отсутствие дублирования кода, минимальное количество классов/методов — тоже ясные требования. А как расшифровать слова «раскрывает изначальные замыслы»?
ХР всячески подчеркивает, что хороший код — это Код, который можно легко прочесть и понять. Если вы хотите сделать комплимент ХР-разработчику и скажете, что он пишет «умный код», будьте уверены — вы оскорбили человека.
Словом, сложную конструкцию труднее осмыслить. Понятно, что будущие модификации продукта приведут к его усложнению. Так зачем же усложнять заранее?
Такой стиль работы абсурден, если внедрять его в прогнозирующий, обычный процесс и игнорировать остальные методы ХР. В комплексе с остальными ХР-причудами он может стать действительно полезным.
Стратегии конструирования ПО
Существуют 3 стратегии конструирования ПО:
q однократный проход (водопадная стратегия) — линейная последовательность этапов конструирования;
q инкрементная стратегия. В начале процесса определяются все пользовательские и системные требования, оставшаяся часть конструирования выполняется в виде последовательности версий. Первая версия реализует часть запланированных возможностей, следующая версия реализует дополнительные возможности и т. д., пока не будет получена полная система;
q эволюционная стратегия. Система также строится в виде последовательности версий, но в начале процесса определены не все требования. Требования уточняются в результате разработки версий.
Характеристики стратегий конструирования ПО в соответствии с требованиями стандарта IEEE/EIA 12207.2 приведены в табл. 1.1.
Таблица 1.1. Характеристики стратегий конструирования
| Стратегия конструирования | В начале процесса определены все требования? | Множество циклов конструирования? | Промежуточное ПО распространяется? | ||||
| Однократный проход
Инкрементная (запланированное улучшение продукта) Эволюционная | Да
Да Нет | Нет
Да Да | Нет
Может быть Да |
Стрессовое тестирование
На предыдущих шагах тестирования способы «белого» и «черного ящиков» обеспечивали полную оценку нормальных программных функций и качества функционирования. Стрессовые тесты проектируются для навязывания программам ненормальных ситуаций. В сущности, проектировщик стрессового теста спрашивает, как сильно можно расшатать систему, прежде чем она откажет?
Стрессовое тестирование производится при ненормальных запросах на ресурсы системы (по количеству, частоте, размеру-объему).
Примеры:
q генерируется 10 прерываний в секунду (при средней частоте 1,2 прерывания в секунду);
q скорость ввода данных увеличивается прямо пропорционально их важности (чтобы определить реакцию входных функций);
q формируются варианты, требующие максимума памяти и других ресурсов;
q генерируются варианты, вызывающие переполнение виртуальной памяти;
q проектируются варианты, вызывающие чрезмерный поиск данных на диске.
По существу, испытатель пытается разрушить систему. Разновидность стрессового тестирования называется тестированием чувствительности. В некоторых ситуациях (обычно в математических алгоритмах) очень малый диапазон данных, содержащийся в границах правильных данных системы, может вызвать ошибочную обработку или резкое понижение производительности. Тестирование чувствительности обнаруживает комбинации данных, которые могут вызвать нестабильность или неправильность обработки.
Структурирование системы
Известны четыре модели системного структурирования:
q модель хранилища данных;
q модель клиент-сервер;
q трехуровневая модель;
q модель абстрактной машины.
В модели хранилища данных (рис. 4.3) подсистемы разделяют данные, находящиеся в общей памяти. Как правило, данные образуют БД. Предусматривается система управления этой базой.
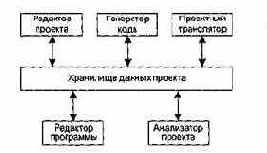
Рис. 4.3. Модель хранилища данных
Модель клиент-сервер используется для распределенных систем, где данные распределены по серверам (рис. 4.4). Для передачи данных применяют сетевой протокол, например TCP/IP.
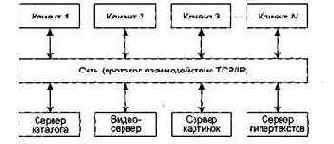
Рис. 4.4. Модель клиент-сервер
Трехуровневая модель является развитием модели клиент-сервер (рис. 4.5).
Рис. 4.5. Трехуровневая модель
Уровень графического интерфейса пользователя запускается на машине клиента. Бизнес-логику образуют модули, осуществляющие функциональные обязанности системы. Этот уровень запускается на сервере приложения. Реляционная СУБД хранит данные, требуемые уровню бизнес-логики. Этот уровень запускается на втором сервере — сервере базы данных.
Преимущества трехуровневой модели:
q упрощается такая модификация уровня, которая не влияет на другие уровни;
q отделение прикладных функций от функций управления БД упрощает оптимизацию всей системы.
Модель абстрактной машины отображает многослойную систему (рис. 4.6).
Каждый текущий слой реализуется с использованием средств, обеспечиваемых слоем-фундаментом.

Рис. 4.6. Модель абстрактной машины
Структурный анализ
Структурный анализ — один из формализованных методов анализа требований к ПО. Автор этого метода — Том Де Марко (1979) [27]. В этом методе программное изделие рассматривается как преобразователь информационного потока данных. Основной элемент структурного анализа — диаграмма потоков данных.
Связи
Связь — это физическое или понятийное соединение между объектами. Объект сотрудничает с другими объектами через соединяющие их связи. Связь обозначает соединение, с помощью которого:
q объект-клиент вызывает операции объекта-поставщика;
q один объект перемещает данные к другому объекту.
Можно сказать, что связи являются рельсами между станциями-объектами, по которым ездят «трамвайчики сообщений».
Связи между объектами показаны на рис. 9.5 с помощью соединительных линий. Связи представляют возможные пути для передачи сообщений. Сами сообщения показаны стрелками, отмечающими их направления, и помечены именами вызываемых операций.
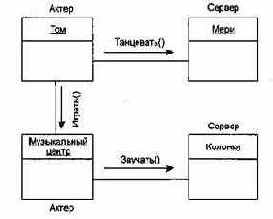
Рис. 9.5. Связи между объектами
Как участник связи объект может играть одну из трех ролей:
q актер — объект, который может воздействовать на другие объекты, но никогда не подвержен воздействию других объектов;
q сервер — объект, который никогда не воздействует на другие объекты, он только используется другими объектами;
q агент — объект, который может как воздействовать на другие объекты, так и использоваться ими. Агент создается для выполнения работы от имени актера или другого агента.
На рис. 9.5 Том — это актер, Мери, Колонки — серверы, Музыкальный центр — агент.
Приведем пример. Допустим, что нужно обеспечить следующий график разворота первой ступени ракеты по углу тангажа, представленный на рис. 9.6.
Запишем абстракцию графика разворота:
with Класс_ДатчикУглаТангажа;
use Класс_ДатчикУглаТангажа;
Package Класс_ГрафикРазворота is
subtype Секунда is Natural range ...
type ГрафикРазворота is tagged private;
procedure Очистить (the: in out ГрафикРазворота);
procedure Связать (the: In out ГрафикРазворота;
teta: Угол: si: Секунда: s2: Секунда);
function УголНаМомент (the: ГрафикРазворота;
s: Секунда) return Угол;
private
…
end Класс_ГрафикРазворота;
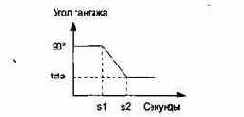
Рис. 9.6. График разворота первой ступени ракеты
Для решения задачи надо обеспечить сотрудничество трех объектов: экземпляра класса ГрафикРазворота, РегулятораУгла и КонтроллераУгла.
Описание класса КонтроллерУгла может иметь следующий вид:
with Класс_ГрафикРазворота. Класс_РегуляторУгла;
use Класс_ГрафикРазворота. Класс_РегуляторУгла;
Package Класс_КонтроллерУгла is
type укз_наГрафик is access all ГрафикРазворота;
type КонтроллерУгла is tagged private;
procedure Обрабатывать (the: in out КонтроллерУгла;
уг: укз_наГрафик);
function Запланировано (the: КонтроллерУгла;
уг: укз_наГрафик) return Секунда;
private
type КонтроллерУгла is tagged record
регулятор: РегуляторУгла := НовРегуляторУгла
(1.1.10);
…
end Класс_КонтроллерУгла:
ПРИМЕЧАНИЕ
Операция Запланировано позволяет клиентам запросить у экземпляра Контроллера-Угла время обработки следующего графика.
И наконец, описание класса РегуляторУгла представим в следующей форме:
with Класс_ДатчикУгла. Класс_Порт;
use Класс_ДатчикУгла. Класс_Порт;
Package Класс_РегуляторУгла is
type Режим is (Увеличение. Уменьшение);
subtype Размещение is Natural range ...
type РегуляторУгла is tagged private;
function НовРегуляторУгла (номер: Размещение;
напр: Направление: порт: Порт)
return РегуляторУгла;
procedure Включить(the: in out РегуляторУгла);
procedure Выключить(the: in out РегуляторУгла);
procedure УвеличитьУгол(№е: in out
РегуляторУгла);
procedure УменьшитьУгол(the: in out
РегуляторУгла);
function ОпросСостояния(the: РегуляторУгла)
return Режим:
private
type укз_наПорт is access all Порт;
type РегуляторУгла is tagged record
Номер: Размещение;
Состояние: Режим;
Управление: укз_наПорт;
end record;
end Класс_РегуляторУгла;
Теперь, когда сделаны необходимые приготовления, объявим нужные экземпляры классов, то есть объекты:
РабочийГрафик: aliased ГрафикРазворота;
РабочийКонтроллер: aliased Контроллеругла;
Далее мы должны определить конкретные параметры графика разворота
Связать (РабочийГрафик. 30. 60. 90);
а затем предложить объекту-контроллеру выполнить этот график:
Обрабатывать (РабочийКонтроллер. РабочийГрафикАссеss);
Рассмотрим отношение между объектом РабочийГрафик и объектом РабочийКонтроллер. РабочийКонтроллер — это агент, отвечающий за выполнение графика разворота и поэтому использующий объект РабочийГрафик как сервер. В данном отношении объект РабочийКонтроллер использует объект РабочийГрафик как аргумент в одной из своих операций.
Связность модуля
Связность модуля (Cohesion) — это мера зависимости его частей [58], [70], [77]. Связность — внутренняя характеристика модуля. Чем выше связность модуля, тем лучше результат проектирования, то есть тем «черней» его ящик (капсула, защитная оболочка модуля), тем меньше «ручек управления» на нем находится и тем проще эти «ручки».
Для измерения связности используют понятие силы связности (СС). Существует 7 типов связности:
1. Связность по совпадению (СС=0). В модуле отсутствуют явно выраженные внутренние связи.
2. Логическая связность (СС=1). Части модуля объединены по принципу функционального подобия. Например, модуль состоит из разных подпрограмм обработки ошибок. При использовании такого модуля клиент выбирает только одну из подпрограмм.
Недостатки:
q сложное сопряжение;
q большая вероятность внесения ошибок при изменении сопряжения ради одной из функций.
3. Временная связность (СС=3). Части модуля не связаны, но необходимы в один и тот же период работы системы.
Недостаток: сильная взаимная связь с другими модулями, отсюда — сильная чувствительность внесению изменений.
4. Процедурная связность (СС=5). Части модуля связаны порядком выполняемых ими действий, реализующих некоторый сценарий поведения.
5. Коммуникативная связность (СС=7). Части модуля связаны по данным (работают с одной и той же структурой данных).
6. Информационная (последовательная) связность (СС=9). Выходные данные одной части используются как входные данные в другой части модуля.
7. Функциональная связность (СС=10). Части модуля вместе реализуют одну функцию.
Отметим, что типы связности 1,2,3 — результат неправильного планирования архитектуры, а тип связности 4 — результат небрежного планирования архитектуры приложения.
Общая характеристика типов связности представлена в табл. 4.1.
Таблица 4.1. Характеристика связности модуля
| Тип связности | Сопровождаемость | Роль модуля | |||
| Функциональная | «Черный ящик» | ||||
| Информационная
( последовательная ) | Лучшая сопровождаемость | Не совсем «черный ящик» | |||
| Кэммуникативная | «Серый ящик» | ||||
| Процедурная | «Белый» или «просвечивающий ящик» | ||||
| Временная | Худшая сопровождаемость | ||||
| Логическая | «Белый ящик» | ||||
| По совпадению |
Связность объектов
В классическом методе Л. Констентайна и Э. Йордана определены семь типов связности.
1. Связность по совпадению. В модуле отсутствуют явно выраженные внутренние связи.
2. Логическая связность. Части модуля объединены по принципу функционального подобия.
3. Временная связность. Части модуля не связаны, но необходимы в один и тот же период работы системы.
4. Процедурная связность. Части модуля связаны порядком выполняемых ими действий, реализующих некоторый сценарий поведения.
5. Коммуникативная связность. Части модуля связаны по данным (работают с одной и той же структурой данных).
6. Информационная (последовательная) связность. Выходные данные одной части используются как входные данные в другой части модуля.
7. Функциональная связность. Части модуля вместе реализуют одну функцию.
Этот метод функционален по своей природе, поэтому наибольшей связностью здесь объявлена функциональная связность. Вместе с тем одним из принципиальных преимуществ объектно-ориентированного подхода является естественная связанность объектов.
Максимально связанным является объект, в котором представляется единая сущность и в который включены все операции над этой сущностью. Например, максимально связанным является объект, представляющий таблицу символов компилятора, если в него включены все функции, такие как «Добавить символ», «Поиск в таблице» и т. д.
Следовательно, восьмой тип связности можно определить так:
8. Объектная связность. Каждая операция обеспечивает функциональность, которая предусматривает, что все свойства объекта будут модифицироваться, отображаться и использоваться как базис для предоставления услуг.
Высокая связность — желательная характеристика, так как она означает, что объект представляет единую часть в проблемной области, существует в едином пространстве.
При изменении системы все действия над частью инкапсулируются в едином компоненте. Поэтому для производства изменения нет нужды модифицировать много компонентов.
Если функциональность в объектно-ориентированной системе обеспечивается наследованием от суперклассов, то связность объекта, который наследует свойства и операции, уменьшается. В этом случае нельзя рассматривать объект как отдельный модуль — должны учитываться все его суперклассы. Системные средства просмотра содействуют такому учету. Однако понимание элемента, который наследует свойства от нескольких суперклассов, резко усложняется.
Обсудим конкретные метрики для вычисления связности классов.
Метрики связности по данным
Л. Отт и Б. Мехра разработали модель секционирования класса [55]. Секционирование основывается на экземплярных переменных класса. Для каждого метода класса получают ряд секций, а затем производят объединение всех секций класса. Измерение связности основывается на количестве лексем данных (data tokens), которые появляются в нескольких секциях и «склеивают» секции в модуль. Под лексемами данных здесь понимают определения констант и переменных или ссылки на константы и переменные.
Базовым понятием методики является секция данных. Она составляется для каждого выходного параметра метода. Секция данных — это последовательность лексем данных в операторах, которые требуются для вычисления этого параметра.
Например, на рис. 14.1 представлен программный текст метода SumAndProduct. Все лексемы, входящие в секцию переменной SumN, выделены рамками. Сама секция для SumN записывается как следующая последовательность лексем:
N1 • SumN1
• I1 • SumN2 • O1 • I2 • 12
• N2 • SumN3 SumN4 • I3.
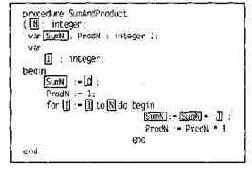
Рис. 14.1. Секция данных для переменной SumN
Заметим, что индекс в «12» указывает на второе вхождение лексемы «1» в текст метода. Аналогичным образом определяется секция для переменной ProdN:
N1 • ProdN1 • I1 • ProdN2 •11 • I2 • 12 • N2 • ProdN3 • ProdN4 • I4
Для определения отношений между секциями данных можно показать профиль секций данных в методе.
Для нашего примера профиль секций данных приведен в табл. 14.1.
Таблица 14.1. Профиль секций данных для метода SumAndProduct
|
SumN |
ProdN |
Оператор |
|
|
|
procedure SumAndProduct |
|
1 |
1 |
(Niinteger; |
|
1 |
1 |
varSumN, ProdNiinteger) |
|
|
|
var |
|
1 |
1 |
l:integer; |
|
|
|
begin |
|
2 |
|
SumN:=0 |
|
|
2 |
ProdN:=1 |
|
3 |
3 |
for l:=1 to N do begin |
|
3 |
|
SumN:=SumN+l |
|
|
3 |
ProdN:=ProdN*l |
|
|
|
end |
|
|
|
end; |
Еще одно базовое понятие методики — секционированная абстракция. Секционированная абстракция — это объединение всех секций данных метода. Например, секционированная абстракция метода SumAndProduct имеет вид
SA(SumAndProduct) = {N1
• SumN1 • I1 • SumN2 • 01 • I2 • I2 • N2
• SumN3 • SumN4 • I3,
N1
• ProdN1 • I1 • ProdN2
• I1 • I2 • I2 • N2
• ProdN3 • ProdN4 • I4}.
Введем главные определения.
Секционированной абстракцией класса (Class Slice Abstraction) CSA(C) называют объединение секций всех экземплярных переменных класса. Полный набор секций составляют путем обработки всех методов класса.
Склеенными лексемами называют те лексемы данных, которые являются элементами более чем одной секции данных.
Сильно склеенными лексемами называют те склеенные лексемы, которые являются элементами всех секций данных.
Сильная связность по данным (StrongData Cohesion) — это метрика, основанная на количестве лексем данных, входящих во все секции данных для класса. Иначе говоря, сильная связность по данным учитывает количество сильно склеенных лексем в классе С, она вычисляется по формуле:

где SG(CSA(C)) — объединение сильно склеенных лексем каждого из методов класса С, лексемы(С) — множество всех лексем данных класса С.
Таким образом, класс без сильно склеенных лексем имеет нулевую сильную связность по данным.
Слабая связность по данным (Weak Data Cohesion) — метрика, которая оценивает связность, базируясь на склеенных лексемах.
Склеенные лексемы не требуют связывания всех секций данных, поэтому данная метрика определяет более слабый тип связности. Слабая связность по данным вычисляется по формуле:

где G(CSA(C)) — объединение склеенных лексем каждого из методов класса. Класс без склеенных лексем не имеет слабой связности по данным. Наиболее точной метрикой связности между секциями данных является клейкость данных (Data Adhesiveness). Клейкость данных определяется как отношение суммы из количеств секций, содержащих каждую склеенную лексему, к произведению количества лексем данных в классе на количество секций данных. Метрика вычисляется по формуле:

Приведем пример. Применим метрики к классу, профиль секций которого показан в табл. 14.2.
Таблица 14.2. Профиль секций данных для класса Stack
|
array top size |
Класс Stack |
|
|
class Stack {int *array, top, size; |
|
|
public: |
|
|
Stack (int s) { |
|
2 2 |
size=s; |
|
2 2 |
array=new int [size]; |
|
2 |
top=0;} |
|
|
int IsEmpty () { |
|
2 |
return top==0}; |
|
|
int Size (){ |
|
2 |
return size}; |
|
|
intVtop(){ |
|
3 3 |
return array [top-1]; } |
|
|
void Push (int item) { |
|
2 2 2 |
if (top= =size) |
|
|
printf ("Empty stack. \n"); |
|
|
else |
|
3 3 3 |
array [top++]=item;} |
|
|
int Pop () { |
|
1 |
if (IsEmpty ()) |
|
|
printf ("Full stack. \n"); |
|
|
else |
|
1 |
--top;} |
|
|
}; |
Расчеты по рассмотренным метрикам дают следующие значения:
SDC(CSA(Stack)) = 5/19 = 0,26
WDC(CSA(Stack)) = 12/19 = 0,63
DA(CSA(Stack)) =(7*2 + 5*3)/(19*3) = 0,51
Метрики связности по методам
Д. Биемен и Б. Кенг предложили метрики связности класса, которые основаны на прямых и косвенных соединениях между парами методов [15]. Если существуют общие экземплярные переменные (одна или несколько), используемые в паре методов, то говорят, что эти методы соединены прямо.
Пара методов может быть соединена косвенно, через другие прямо соединенные методы.
На рис. 14.2 представлены отношения между элементами класса Stack. Прямоугольниками обозначены методы класса, а овалами — экземплярные переменные. Связи показывают отношения использования между методами и переменными.
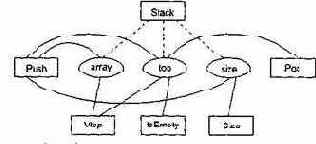
Рис. 14. 2. Отношения между элементами класса Stack
Из рисунка видно, что экземплярная переменная top используется методами Stack, Push, Pop, Vtop и IsEmpty. Таким образом, все эти методы попарно прямо соединены. Напротив, методы Size и Pop соединены косвенно: Size соединен прямо с Push, который, в свою очередь, прямо соединен с Pop. Метод Stack является конструктором класса, то есть функцией инициализации. Обычно конструктору доступны все экземплярные переменные класса, он использует эти переменные совместно со всеми другими методами. Следовательно, конструкторы создают соединения и между такими методами, которые никак не связаны друг с другом. Поэтому ни конструкторы, ни деструкторы здесь не учитываются. Связи между конструктором и экземплярными переменными на рис. 14.2 показаны пунктирными линиями.
Для формализации модели вводятся понятия абстрактного метода и абстрактного класса.
Абстрактный метод АМ(М) — это представление реального метода М в
виде множества экземплярных переменных, которые прямо или косвенно используются методом.
Экземплярная переменная прямо используется методом М, если она появляется в методе как лексема данных. Экземплярная переменная может быть определена в том же классе, что и М, или же в родительском классе этого класса. Множество экземплярных переменных, прямо используемых методом М, обозначим как DU(M).
Экземплярная переменная косвенно используется методом М, если: 1) экземплярная переменная прямо используется другим методом М', который вызывается (прямо или косвенно) из метода М; 2) экземплярная переменная, прямо используемая методом М', находится в том же объекте, что и М.
Множество экземплярных переменных, косвенно используемых методом М, обозначим как IU(М).
Количественно абстрактный метод формируется по выражению:
AM (М) = DU (М)

Абстрактный класс АС(С) — это представление реального класса С в виде совокупности абстрактных методов, причем каждый абстрактный метод соответствует видимому методу класса С. Количественно абстрактный класс формируется по выражению:
АС (С) = [[AM (M) | M

где V(C) — множество всех видимых методов в классе С
и в классах — предках для С.
Отметим, что АМ-представления различных методов могут совпадать, поэтому в АС могут быть дублированные элементы. В силу этого АС записывается в форме мультимножества (двойные квадратные скобки рассматриваются как его обозначение).
Локальный абстрактный класс LAC(C) — это совокупность абстрактных методов, где каждый абстрактный метод соответствует видимому методу, определенному только внутри класса С. Количественно абстрактный класс формируется по выражению:
LAC(C)=[[AM(M)|M
где LV(C) — множество всех видимых методов, определенных в классе С.
Абстрактный класс для стека, приведенного в табл. 14.2, имеет вид:
AC (Stack) = [[{top}, {size}, {array, top}, {array, top, size}, {pop}]].
Поскольку класс Stack не имеет суперкласса, то справедливо:
AC (Stack) = LAC (Stack)
Пусть NP(C) — общее количество пар абстрактных методов в AC(C). NP определяет максимально возможное количество прямых или косвенных соединений в классе. Если в классе С имеются N методов, тогда NP(C) = N*(N- l)/2. Обозначим:
q NDC(C) — количество прямых соединений AC(Q;
q NIC(C) — количество косвенных соединений в АС(С).
Тогда метрики связности класса можно представить в следующем виде:
q сильная связность класса (Tight Class Cohesion (ТСС)) определяется относительным количеством прямо соединенных методов:
ТСС (С) = NDC (С) / NP (С);
q слабая связность класса (Loose Class Cohesion (LCC)) определяется относительным количеством прямо или косвенно соединенных методов:
LCC (С) = (NDC (С) + NIC (С)) / NP (С).
Очевидно, что всегда справедливо следующее неравенство:
LCC(C)>=TCC(C).
Для класса Stack метрики связности имеют следующие значения:
TCC(Stack)=7/10=0,7
LCC(Stack)=10/10=l
Метрика ТСС показывает, что 70% видимых методов класса Stack соединены прямо, а метрика LCC показывает, что все видимые методы класса Stack соединены прямо или косвенно.
Метрики ТСС и LCC индицируют степень связанности между видимыми методами класса. Видимые методы либо определены в классе, либо унаследованы им. Конечно, очень полезны метрики связности для видимых методов, которые определены только внутри класса — ведь здесь исключается влияние связности суперкласса. Очевидно, что метрики локальной связности класса определяются на основе локального абстрактного класса. Отметим, что для локальной связности экземплярные переменные и вызываемые методы могут включать унаследованные переменные.
Связность по совпадению
Элементы связного по совпадению модуля вообще не имеют никаких отношений друг с другом:
Модуль Разные функции (какие-то параметры)
поздравить с Новым годом (...)
проверить исправность аппаратуры (...)
заполнить анкету героя (...)
измерить температуру (...)
вывести собаку на прогулку (...)
запастись продуктами (...)
приобрести «ягуар» (...)
Конец модуля
Связный по совпадению модуль похож на логически связный модуль. Его элементы-действия не связаны ни потоком данных, ни потоком управления. Но в логически связном модуле действия, по крайней мере, относятся к одной категории; в связном по совпадению модуле даже это не так. Словом, связные по совпадению модули имеют все недостатки логически связных модулей и даже усиливают их. Применение таких модулей вселяет ужас, поскольку один параметр используется для разных целей.
Чтобы клиент мог воспользоваться модулем Разные функции, этот модуль (подобно всем связным по совпадению модулям) должен быть «белым ящиком», чья реализация полностью видима. Такие модули делают системы менее понятными и труднее сопровождаемыми, чем системы без модульности вообще!
К счастью, связность по совпадению встречается редко. Среди ее причин можно назвать:
q бездумный перевод существующего монолитного кода в модули;
q необоснованные изменения модулей с плохой (обычно временной) связностью, приводящие к добавлению флажков.
Общий синтаксис представления свойства имеет
Общий синтаксис представления свойства имеет вид
Видимость Имя [Множественность]: Тип = НачальнЗначение {Характеристики}
Рассмотрим видимость и характеристики свойств.
В языке UML определены три уровня видимости:
|
public protected private |
Любой клиент класса может использовать свойство (операцию), обозначается символом + Любой наследник класса может использовать свойство (операцию), обозначается символом # Свойство (операция) может использоваться только самим классом, обозначается символом - |
ПРИМЕЧАНИЕ
Если видимость не указана, считают, что свойство объявлено с публичной видимостью.
Определены три характеристики свойств:
|
changeable addOnly frozen |
Нет ограничений на модификацию значения свойства Для свойств с множественностью, большей единицы; дополнительные значения могут быть добавлены, но после создания значение не может удаляться или изменяться После инициализации объекта значение свойства не изменяется |
ПРИМЕЧАНИЕ
Если характеристика не указана, считают, что свойство объявлено с характеристикой changeable.
Примеры объявления свойств:
|
начало + начало начало : Координаты имяфамилия [0..1] : String левыйУгол : Координаты=(0, 10) сумма : Integer {frozen} |
Только имя Видимость и имя Имя и тип Имя, множественность, тип Имя, тип, начальное значение Имя и характеристика |
Технические артефакты
Технические артефакты подразделяются на четыре основных набора:
q набор требований. Описывает, что должна делать система;
q набор проектирования. Описывает, как должна быть сконструирована система;
q набор реализации. Описывает сборку разработанных программных компонентов;
q набор размещения. Обеспечивает всю информацию о поставляемой конфигурации.
Набор требований группирует всю информацию о том, что система должна делать. Он может включать модель Use Case, модель нефункциональных требований, модель области определения, модель анализа, а также другие формы выражения нужд пользователя.
Набор проектирования группирует всю информацию о том, как будет конструироваться система при учете всех ограничений (времени, бюджета, традиций, повторного использования, качества и т.д.).
Он может включать проектную модель, тестовую модель и другие формы выражения сущности системы (например, макеты).
Набор реализации группирует все данные о программных элементах, образующих систему (программный код, файлы конфигурации, файлы данных, программные компоненты, информацию о сборке системы).
Набор размещения группирует всю информацию об упаковке, отправке, установке и запуске системы.
Тестирование «белого ящика»
Известна: внутренняя структура программы.
Исследуются: внутренние элементы программы и связи между ними (рис. 6.3).
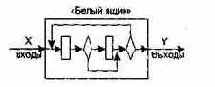
Рис. 6.3. Тестирование «белого ящика»
Объектом тестирования здесь является не внешнее, а внутреннее поведение программы. Проверяется корректность построения всех элементов программы и правильность их взаимодействия друг с другом. Обычно анализируются управляющие связи элементов, реже — информационные связи. Тестирование по принципу «белого ящика» характеризуется степенью, в какой тесты выполняют или покрывают логику (исходный текст) программы. Исчерпывающее тестирование также затруднительно. Особенности этого принципа тестирования рассмотрим отдельно.
Тестирование безопасности
Компьютерные системы очень часто являются мишенью незаконного проникновения. Под проникновением понимается широкий диапазон действий: попытки хакеров проникнуть в систему из спортивного интереса, месть рассерженных служащих, взлом мошенниками для незаконной наживы.
Тестирование безопасности проверяет фактическую реакцию защитных механизмов, встроенных в систему, на проникновение.
В ходе тестирования безопасности испытатель играет роль взломщика. Ему разрешено все:
q попытки узнать пароль с помощью внешних средств;
q атака системы с помощью специальных утилит, анализирующих защиты;
q подавление, ошеломление системы (в надежде, что она откажется обслуживать других клиентов);
q целенаправленное введение ошибок в надежде проникнуть в систему в ходе восстановления;
q просмотр несекретных данных в надежде найти ключ для входа в систему.
Конечно, при неограниченном времени и ресурсах хорошее тестирование безопасности взломает любую систему. Задача проектировщика системы — сделать цену проникновения более высокой, чем цена получаемой в результате информации.
Тестирование «черного ящика»
Известны: функции программы.
Исследуется: работа каждой функции на всей области определения.
Как показано на рис. 6.2, основное место приложения тестов «черного ящика» — интерфейс ПО.

Рис. 6.2. Тестирование «черного ящика»
Эти тесты демонстрируют:
q как выполняются функции программ;
q как принимаются исходные данные;
q как вырабатываются результаты;
q как сохраняется целостность внешней информации.
При тестировании «черного ящика» рассматриваются системные характеристики программ, игнорируется их внутренняя логическая структура. Исчерпывающее тестирование, как правило, невозможно. Например, если в программе 10 входных величин и каждая принимает по 10 значений, то потребуется 1010 тестовых вариантов. Отметим также, что тестирование «черного ящика» не реагирует на многие особенности программных ошибок.
Тестирование циклов
Цикл — наиболее распространенная конструкция алгоритмов, реализуемых в ПО. Тестирование циклов производится по принципу «белого ящика», при проверке циклов основное внимание обращается на правильность конструкций циклов.
Различают 4 типа циклов: простые, вложенные, объединенные, неструктурированные. Структура циклов приведена на рис. 6.10.
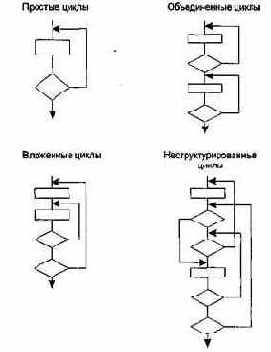
Рис. 6.10. Типовые структуры циклов
Тестирование интеграции
Тестирование интеграции поддерживает сборку цельной программной системы.
Цель сборки и тестирования интеграции: взять модули, протестированные как элементы, и построить программную структуру, требуемую проектом [3].
Тесты проводятся для обнаружения ошибок интерфейса. Перечислим некоторые категории ошибок интерфейса:
q потеря данных при прохождении через интерфейс;
q отсутствие в модуле необходимой ссылки;
q неблагоприятное влияние одного модуля на другой;
q подфункции при объединении не образуют требуемую главную функцию;
q отдельные (допустимые) неточности при интеграции выходят за допустимый уровень;
q проблемы при работе с глобальными структурами данных.
Существует два варианта тестирования, поддерживающих процесс интеграции: нисходящее тестирование и восходящее тестирование. Рассмотрим каждый из них.
Тестирование элементов
Объектом тестирования элементов является наименьшая единица проектирования ПС — модуль. Для обнаружения ошибок в рамках модуля тестируются его важнейшие управляющие пути. Относительная сложность тестов и ошибок определяется как результат ограничений области тестирования элементов. Принцип тестирования — «белый ящик», шаг может выполняться для набора модулей параллельно.
Тестированию подвергаются:
q интерфейс модуля;
q внутренние структуры данных;
q независимые пути;
q пути обработки ошибок;
q граничные условия.
Интерфейс модуля тестируется для проверки правильности ввода-вывода тестовой информации. Если нет уверенности в правильном вводе-выводе данных, нет смысла проводить другие тесты.
Исследование внутренних структур данных гарантирует целостность сохраняемых данных.
Тестирование независимых путей гарантирует однократное выполнение всех операторов модуля. При тестировании путей выполнения обнаруживаются следующие категории ошибок: ошибочные вычисления, некорректные сравнения, неправильный поток управления [3].
Наиболее общими ошибками вычислений являются:
1) неправильный или непонятый приоритет арифметических операций;
2) смешанная форма операций;
3) некорректная инициализация;
4) несогласованность в представлении точности;
5) некорректное символическое представление выражений.
Источниками ошибок сравнения и неправильных потоков управления являются:
1) сравнение различных типов данных;
2) некорректные логические операции и приоритетность;
3) ожидание эквивалентности в условиях, когда ошибки точности делают эквивалентность невозможной;
4) некорректное сравнение переменных;
5) неправильное прекращение цикла;
6) отказ в выходе при отклонении итерации;
7) неправильное изменение переменных цикла.
Обычно при проектировании модуля предвидят некоторые ошибочные условия.
Для защиты от ошибочных условий в модуль вводят пути обработки ошибок. Такие пути тоже должны тестироваться. Тестирование путей обработки ошибок можно ориентировать на следующие ситуации:
1) донесение об ошибке невразумительно;
2) текст донесения не соответствует, обнаруженной ошибке;
3) вмешательство системных средств регистрации аварии произошло до обработки ошибки в модуле;
4) обработка исключительного условия некорректна;
5) описание ошибки не позволяет определить ее причину.
И, наконец, перейдем к граничному тестированию. Модули часто отказывают на «границах». Это означает, что ошибки часто происходят:
1) при обработке n-го элемента n-элементного массива;
2) при выполнении m-й итерации цикла с т проходами;
3) при появлении минимального (максимального) значения.
Тестовые варианты, ориентированные на данные ситуации, имеют высокую вероятность обнаружения ошибок.
Тестирование элементов обычно рассматривается как дополнение к этапу кодирования. Оно начинается после разработки текста модуля. Так как модуль не является автономной системой, то для реализации тестирования требуются дополнительные средства, представленные на рис. 8.2.
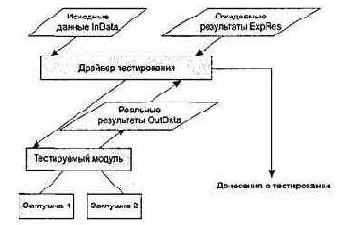
Рис. 8.2. Программная среда для тестирования модуля
Дополнительными средствами являются драйвер тестирования и заглушки. Драйвер — управляющая программа, которая принимает исходные данные (InData) и ожидаемые результаты (ExpRes) тестовых вариантов, запускает в работу тестируемый модуль, получает из модуля реальные результаты (OutData) и формирует донесения о тестировании. Алгоритм работы тестового драйвера приведен на рис. 8.3.

Рис. 8.3. Алгоритм работы драйвера тестирования
Заглушки замещают модули, которые вызываются тестируемым модулем. Заглушка, или «фиктивная подпрограмма», реализует интерфейс подчиненного модуля, может выполнять минимальную обработку данных, имитирует прием и возврат данных.
Создание драйвера и заглушек подразумевает дополнительные затраты, так как они не поставляются с конечным программным продуктом.
Если эти средства просты, то дополнительные затраты невелики. Увы, многие модули не могут быть адекватно протестированы с помощью простых дополнительных средств. В этих случаях полное тестирование может быть отложено до шага тестирования интеграции (где драйверы или заглушки также используются).
Тестирование элемента просто осуществить, если модуль имеет высокую связность. При реализации модулем только одной функции количество тестовых вариантов уменьшается, а ошибки легко предсказываются и обнаруживаются.
Тестирование на основе состояний
В качестве источника исходной информации используют диаграммы схем состояний, фиксирующие динамику поведения класса. Данный способ позволяет получить набор тестов, проверяющих поведение класса и тех классов, которые сотрудничают с ним [43]. В качестве примера на рис. 16.2 показана диаграмма схем состояний класса Счет.
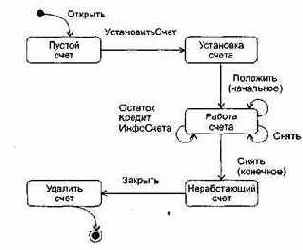
Рис. 16.2. Диаграмма схем состояний класса Счет
Видим, что объект Счета начинает свою жизнь в состоянии Пустой счет, а заканчивает жизнь в состоянии Удалить счет. Наибольшее количество событий (и действий) связано с состоянием Работа счета. Для упрощения рисунка здесь принято, что имена событий совпадают с именами действий (поэтому действия не показаны).
Проектируемые тесты должны обеспечить покрытие всех состояний. Это значит, что тестовые варианты должны инициировать переходы через все состояния объекта:
Тестовый вариант 1: Открыть >УстановитьСчет >Положить (начальное) >Снять (конечное) >Закрыть.
Отметим, что эта последовательность аналогична минимальной тестовой последовательности. Добавим к минимальной последовательности дополнительные тестовые варианты:
Тестовый вариант 2: Открыть >УстановитьСчет >Положить (начальное) >Положить >Остаток >Кредит >Снять (конечное) >Закрыть
Тестовый вариант 3: Открыть >Установить >Положить (начальное) >Положить >Снять >ИнфоСчета >Снять (конечное) >Закрыть
Для гарантии проверки всех вариантов поведения количество тестовых вариантов может быть увеличено. Когда поведение класса определяется в сотрудничестве с несколькими классами, для отслеживания «потока поведения» используют набор диаграмм схем состояний, характеризующих смену состояний других классов.
Возможна другая методика исследования состояний.— «преимущественно в ширину».
В этой методике:
q каждый тестовый вариант проверяет один новый переход;
q новый переход можно проверять, если полностью проверены все предшествующие переходы, то есть переходы между предыдущими состояниями.
Рассмотрим объект Карта клиента (рис. 16.3). Начальное состояние карты Не определена, то есть не установлен номер карты. После чтения карты (в ходе диалога с банкоматом) объект переходит в состояние Определена. Это означает, что определены банковские идентификаторы Номер Карты и Дата Истечения Срока. Карта клиента переходит в состояние Предъявляется на рассмотрение, когда проводится ее авторизация, и в состояние Разрешена, когда авторизация подтверждается. Переход карты клиента из одного состояния в другое проверяется отдельным тестовым вариантом.
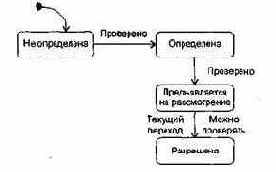
Рис. 16.3. Тестирование «преимущественно в ширину»
Подход «преимущественно в ширину» требует: нельзя проверять Разрешена перед проверкой Не определена, Определена и Предъявляется на рассмотрение. В противном случае нарушается условие этого подхода: перед тестированием текущего перехода должны быть протестированы все переходы, ведущие к нему.
Тестирование объектно-ориентированной интеграции
Объектно-ориентированное ПО не имеет иерархической управляющей структуры, поэтому здесь неприменимы методики как восходящей, так и нисходящей интеграции. Мало того, классический прием интеграции (добавление по одной операции в класс) зачастую неосуществим.
Р. Байндер предлагает две методики интеграции объектно-ориентированных систем [16]:
q тестирование, основанное на потоках;
q тестирование, основанное на использовании.
В первой методике объектом интеграции является набор классов, обслуживающий единичный ввод данных в систему. Иными словами, средства обслуживания каждого потока интегрируются и тестируются отдельно. Для проверки отсутствия побочных эффектов применяют регрессионное тестирование. По второй методике вначале интегрируются и тестируются независимые классы. Далее работают с первым слоем зависимых классов (которые используют независимые классы), со вторым слоем и т. д. В отличие от стандартной интеграции, везде, где возможно, избегают драйверов и заглушек.
Д. МакГрегор считает, что одним из шагов объектно-ориентированного тестирования интеграции должно быть кластерное тестирование [50]. Кластер сотрудничающих классов определяется исследованием CRC-модели или диаграммы сотрудничества объектов. Тестовые варианты для кластера ориентированы на обнаружение ошибок сотрудничества.
Тестирование, основанное на ошибках
Цель тестирования, основанного на ошибках, — проектирование тестов, ориентированных на обнаружение предполагаемых ошибок [46]. Разработчик выдвигает гипотезу о предполагаемых ошибках. Для проверки его предположений разрабатываются тестовые варианты.
В качестве примера рассмотрим булево выражение
if (X and not Y or Z).
Инженер по тестированию строит гипотезу о предполагаемых ошибках выражения:
q операция not сдвинулась влево от нужного места (она должна применяться к Z);
q вместо and должно быть or;
q вокруг not Y or Z должны быть круглые скобки.
Для каждой предполагаемой ошибки проектируются тестовые варианты, которые заставляют некорректное выражение отказать.
Обсудим первую предполагаемую ошибку. Значения (X = false, Y = false, Z = false) устанавливают указанное выражение в false. Если вместо not Y должно быть not Z, то выражение принимает неправильное значение, которое приводит к неправильному ветвлению. Аналогичные рассуждения применяются к генерации тестов по двум другим ошибкам.
Эффективность этой методики зависит от того, насколько правильно инженер выделяет предполагаемую ошибку. Если действительные ошибки объектно-ориентированной системы не воспринимаются как предполагаемые, то этот подход не лучше стохастического тестирования. Если же визуальные модели анализа и проектирования обеспечивают понимание ошибочных действий, то тестирование, основанное на ошибках, поможет найти подавляющее большинство ошибок при малых затратах.
При тестировании интеграции предполагаемые ошибки ищутся в пересылаемых сообщениях. В этом случае рассматривают три типа ошибок: неожиданный результат, вызов не той операции, некорректный вызов. Для определения предполагаемых ошибок (при вызове операций) нужно исследовать процесс выполнения операции.
Тестирование интеграции применяется как к свойствам, так и к операциям. Поведение объекта определяется значениями, которые получают его свойства. Поэтому проверка значений свойств обеспечивает проверку правильности поведения.
При тестировании интеграции ищутся ошибки в объектах-клиентах, запрашивающих услуги, а не в объектах-серверах, предоставляющих эти услуги. Тестирование интеграции определяет ошибки в вызывающем коде, а не в вызываемом коде. Вызов операции используют как средство, обеспечивающее тестирование вызывающего кода.
Тестирование, основанное на сценариях
Тестирование, основанное на ошибках, оставляет в стороне два важных типа ошибок:
q некорректные спецификации;
q взаимодействия между подсистемами.
Ошибка из-за неправильной спецификации означает, что продукт не выполняет то, чего хочет заказчик. Он делает что-то неправильно, или в нем пропущена важная функциональная возможность. В любом случае страдает качество — соответствие требованиям заказчика.
Ошибки, связанные с взаимодействием подсистем, происходят, когда поведение одной подсистемы создает предпосылки для отказа другой подсистемы.
Тестирование, основанное на сценариях, ориентировано на действия пользователя, а не на действия программной системы [47]. Это означает фиксацию задач, которые выполняет пользователь, а затем применение их в качестве тестовых вариантов. Задачи пользователя фиксируются с помощью элементов Use Case.
Сценарии элементов Use Case обнаруживают ошибки взаимодействия, каждая из которых может быть следствием многих причин. Поэтому соответствующие тестовые варианты более сложны и лучше отражают реальные проблемы, чем тесты, основанные на ошибках. С помощью одного теста, основанного на сценарии, проверяется множество подсистем.
Рассмотрим, например, проектирование тестов, основанных на сценариях, для текстового редактора.
Рабочие сценарии опишем в виде спецификаций элементов Use Case.
Элемент Use Case: Исправлять черновик.
Предпосылки: обычно печатают черновик, читают его и обнаруживают ошибки, которые не видны на экране. Данный элемент Use Case описывает события, которые при этом происходят.
1. Печатать весь документ.
2. Прочитать документ, изменить определенные страницы.
3. После внесения изменения страница перепечатывается.
4. Иногда перепечатываются несколько страниц.
Этот сценарий определяет как требования тестов, так и требования пользователя. Требования пользователя очевидны, ему нужны:
q метод для печати отдельной страницы;
q метод для печати диапазона страниц.
В ходе тестирования проверяется редакция текста как до печати, так и после печати. Разработчик теста может надеяться обнаружить, что функция печати вызывает ошибки в функции редактирования. Это будет означать, что в действительности две программные функции зависят друг от друга.
Элемент Use Case: Печатать новую копию.
Предпосылки: кто-то просит пользователя напечатать копию документа.
1. Открыть документ.
2. Напечатать документ.
3. Закрыть документ.
И в этом случае подход к тестированию почти очевиден. За исключением того, что не определено, откуда появился документ. Он был создан в ранней задаче. Означает ли это, что только эта задача влияет на сценарий?
Во многих современных редакторах запоминаются данные о последней печати документа. По умолчанию эту печать можно повторить. После сценария Исправлять черновик достаточно выбрать в меню Печать, а затем нажать кнопку Печать в диалоговом окне — в результате повторяется печать последней исправленной страницы. Таким образом, откорректированный сценарий примет вид:
Элемент Use Case: Печатать новую копию.
1. Открыть документ.
2. Выбрать в меню пункт Печать.
3. Проверить, что печаталось, и если печатался диапазон страниц, то выбрать опцию Печатать целый документ.
4. Нажать кнопку Печать.
5. Закрыть документ.
Этот сценарий указывает возможную ошибку спецификации: редактор не делает того, что пользователь ожидает от него. Заказчики часто забывают о проверке, предусмотренной шагом 3. Они раздражаются, когда рысью бегут к принтеру и находят одну страницу вместо ожидаемых 100 страниц. Раздраженные заказчики считают, что в спецификации допущена ошибка.
Разработчик может опустить эту зависимость в тестовом варианте, но, вероятно, проблема обнаружится в ходе тестирования. И тогда разработчик будет выкрикивать: «Я предполагал, я предполагал это учесть!!!».
Тестирование поверхностной и глубинной структуры
Поверхностная структура — это видимая извне структура объектно-ориентированной системы. Она отражает взгляд пользователя, который видит не функции, а объекты для обработки. Тестирование поверхностной структуры основывается на задачах пользователя. Главное — выяснить задачи пользователя. Для разработчика это нетривиальная проблема, поскольку требует отказа от своей точки зрения.
Глубинная структура отражает внутренние технические подробности объектно-ориентированной системы (на уровне проектных моделей и программного текста). Тесты глубинной структуры исследуют зависимости, поведение и механизмы взаимодействия, которые создаются в ходе проектирования подсистем и объектов.
В качестве базиса для тестирования глубинной структуры используются модели анализа и проектирования. Например, разработчик исследует диаграмму взаимодействия (невидимую извне) и спрашивает: «Проверяет ли тест сотрудничество, отмеченное на диаграмме?»
Диаграммы классов обеспечивают понимание структуры наследования, которая используется в тестах, основанных на ошибках. Рассмотрим операцию ОБРАБОТАТЬ (Ссылка_на_РодительскийКласс). Что произойдет, если в вызове этой операции указать ссылку на дочерний класс? Есть ли различия в поведении, которые должны отражаться в операции ОБРАБОТАТЬ? Эти вопросы инициируют создание конкретных тестов.
Тестирование правильности
После окончания тестирования интеграции программная система собрана в единый корпус, интерфейсные ошибки обнаружены и откорректированы. Теперь начинается последний шаг программного тестирования — тестирование правильности. Цель — подтвердить, что функции, описанные в спецификации требований к ПС, соответствуют ожиданиям заказчика [64], [69].
Подтверждение правильности ПС выполняется с помощью тестов «черного ящика», демонстрирующих соответствие требованиям. При обнаружении отклонений от спецификации требований создается список недостатков. Как правило, отклонения и ошибки, выявленные при подтверждении правильности, требуют изменения сроков разработки продукта.
Важным элементом подтверждения правильности является проверка конфигурации ПС. Конфигурацией ПС называют совокупность всех элементов информации, вырабатываемых в процессе конструирования ПС. Минимальная конфигурация ПС включает следующие базовые элементы:
1) системную спецификация;
2) план программного проекта;
3) спецификацию требований к ПС; работающий или бумажный макет;
4) предварительное руководство пользователя;
5) спецификация проектирования;
6) листинги исходных текстов программ;
7) план и методику тестирования; тестовые варианты и полученные результаты;
8) руководства по работе и инсталляции;
9) ехе-код выполняемой программы;
10) описание базы данных;
11) руководство пользователя по настройке;
12) документы сопровождения; отчеты о проблемах ПС; запросы сопровождения; отчеты о конструкторских изменениях;
13) стандарты и методики конструирования ПС.
Проверка конфигурации гарантирует, что все элементы конфигурации ПС правильно разработаны, учтены и достаточно детализированы для поддержки этапа сопровождения в жизненном цикле ПС.
Разработчик не может предугадать, как заказчик будет реально использовать ПС. Для обнаружения ошибок, которые способен найти только конечный пользователь, используют процесс, включающий альфа- и бета-тестирование.
Альфа-тестирование проводится заказчиком в организации разработчика. Разработчик фиксирует все выявленные заказчиком ошибки и проблемы использования.
Бета-тестирование проводится конечным пользователем в организации заказчика. Разработчик в этом процессе участия не принимает. Фактически, бета-тестирование — это реальное применение ПС в среде, которая не управляется разработчиком. Заказчик сам записывает все обнаруженные проблемы и сообщает о них разработчику. Бета-тестирование проводится в течение фиксированного срока (около года). По результатам выявленных проблем разработчик изменяет ПС и тем самым подготавливает продукт полностью на базе заказчика.
Тестирование производительности
В системах реального времени и встроенных системах недопустимо ПО, которое реализует требуемые функции, но не соответствует требованиям производительности.
Тестирование производительности проверяет скорость работы ПО в компьютерной системе. Производительность тестируется на всех шагах процесса тестирования. Даже на уровне элемента при проведении тестов «белого ящика» может оцениваться производительность индивидуального модуля. Тем не менее, пока все системные элементы не объединятся полностью, не может быть установлена истинная производительность системы. Иногда тестирование производительности сочетают со стрессовым тестированием. При этом нередко требуется специальный аппаратный и программный инструментарий. Например, часто требуется точное измерение используемого ресурса (процессорного цикла и т. д.). Внешний инструментарий регулярно отслеживает интервалы выполнения, регистрирует события (например, прерывания) и машинные состояния. С помощью инструментария испытатель может обнаружить состояния, которые приводят к деградации и возможным отказам системы.
Тестирование разбиений
В основу этого метода положен тот же подход, который применялся к отдельному классу. Отличие в том, что тестовая последовательность расширяется для включения тех операций, которые вызываются с помощью сообщений для сотрудничающих классов.
Другой подход к тестированию разбиений основан на взаимодействиях с конкретным классом. Как показано на рис. 16.1, Банк получает сообщения от Банкомата и класса Работа с наличными. Поэтому операции внутри Банка тестируются разбиением их на те, которые обслуживают класс Банкомат, и на те, которые обслуживают класс Работа с наличными. Для дальнейшего уточнения может быть использовано разбиение на категории по состояниям.
Тестирование разбиений на уровне классов
Тестирование разбиений уменьшает количество тестовых вариантов, требуемых для проверки классов (тем же способом, что и разбиение по эквивалентности для стандартного ПО). Области ввода и вывода разбивают на категории, а тестовые Варианты разрабатываются для проверки каждой категории.
Обычно используют одну из трех категории разбиения [43]. Категории образуются операциями класса.
Первый способ — разбиение на категории по состояниям. Основывается на способности операций изменять состояние класса. Обратимся к классу Счет. Операции Снять, Положить изменяют его состояние и образуют первую категорию. Операции Остаток, Итог, ОграничитьКредит не меняют состояние Счета и образуют вторую категорию. Проектируемые тесты отдельно проверяют операции, которые изменяют состояние, а также те операции, которые не изменяют состояние. Таким образом, для нашего примера:
Тестовый вариант 1:
Открыть >Установить >Положить >Положить >Снять >Снять >Закрыть.
Тестовый вариант 2:
Открыть >Установить >Положить >Остаток >Итог >ОграничитьКредит >Снять >Закрыть.
ТВ1 изменяет состояние объекта, в то время как ТВ2 проверяет операции, которые не меняют состояние. Правда, в ТВ2 пришлось включить операции минимальной тестовой последовательности, поэтому для нейтрализации влияния операций Снять и Положить их аргументы должны иметь одинаковые значения.
Второй способ —разбиение на категории по свойствам. Основывается на свойствах, которые используются операциями. В классе Счет для определения разбиений можно использовать свойства остаток и ограничение кредита. Например, на основе свойства ограничение кредита операции подразделяются на три категории:
1) операции, которые используют ограничение кредита;
2) операции, которые изменяют ограничение кредита;
3) операции, которые не используют и не изменяют ограничение кредита.
Для каждой категории создается тестовая последовательность.
Третий способ — разбиение на категории по функциональности. Основывается на общности функций, которые выполняют операции. Например, операции в классе Счет могут быть разбиты на категории:
q операции инициализации (Открыть, Установить);
q вычислительные операции (Положить, Снять);
q запросы (Остаток, Итог, ОграничитьКредит);
q операции завершения (Закрыть).
Тестирование ветвей и операторов отношений
Способ тестирования ветвей и операторов отношений (автор К. Таи, 1989) обнаруживает ошибки ветвления и операторов отношения в условии, для которого выполняются следующие ограничения [72]:
q все булевы переменные и операторы отношения входят в условие только по одному разу;
q в условии нет общих переменных.
В данном способе используются естественные ограничения условий (ограничения на результат). Для составного условия С, включающего п простых условий, формируется ограничение условия:
ОУс = (d1,d2,d3.....dn),
где di — ограничение на результат i-го простого условия.
Ограничение на результат фиксирует возможные значения аргумента (переменной) простого условия (если он один) или соотношения между значениями аргументов (если их несколько).
Если i-e простое условие является булевой переменной, то его ограничение на результат состоит из двух значений и имеет вид
di = (true, false).
Если j-е простое условие является выражением отношения, то его ограничение на результат состоит из трех значений и имеет следующий вид:
dj= (>,<,=).
Говорят, что ограничение условия ОУc (для условия С) покрывается выполнением С, если в ходе этого выполнения результат каждого простого условия в С удовлетворяет соответствующему ограничению в ОУc.
На основе ограничения условия ОУ создается ограничивающее множество ОМ, элементы которого являются сочетаниями всех возможных значений d1, d2, d3, ..., dn.
Ограничивающее множество — удобный инструмент для записи задания на тестирование, ведь оно составляется из сведений о значениях переменных, которые влияют на значение проверяемого условия. Поясним это на примере. Положим, надо проверить условие, составленное из трех простых условий:
b&(х>у)&а.
Условие принимает истинное значение, если все простые условия истинны. В терминах значений простых условий это соответствует записи
(true, true, true),
а в терминах ограничений на значения аргументов простых условий — записи
Поэтому ограничивающее множество имеет вид:
ОМ& = {(false, true), (true, false), (true, true)};
q для условия типа ИЛИ (а or b) варианты 2 и 3 поглощают вариант 4. Поэтому ограничивающее множество имеет вид:
ОМor = {(false, false), (false, true), (true, false)}.
Рассмотрим шаги способа тестирования ветвей и операторов отношений.
Для каждого условия в программе выполняются следующие действия:
1) строится ограничение условий ОУ;
2) выявляются ограничения результата по каждому простому условию;
3) строится ограничивающее множество ОМ. Построение выполняется путем подстановки в константные формулы ОМ& или OMOR выявленных ограничений результата;
4) для каждого элемента ОМ разрабатывается тестовый вариант.
Пример 2. Рассмотрим составное условие С1 вида:
В1
&(E1,E2),
где В1 — булево выражение, E1, Е2 — арифметические выражения.
Ограничение составного условия имеет вид
ОУ

где ограничения простых условий равны
d1 = (true, false), d2 = (=, <, >).
Проводя аналогию между С1
и С& (разница лишь в том, что в С1 второе простое условие — это выражение отношения), мы можем построить ограничивающее множество для С1 модификацией
ОМ& = {(false, true), (true, false), (true, true)}.
Заметим, что true для (E1= E2) означает =, a false для (E1 = E2) означает или <, или >. Заменяя (true, true) и (false, true), ограничениями (true, =) и (false, =) соответственно, a (true, false) — ограничениями (true, <) и (true, >), получаем ограничивающее множество для С1:
ОМ
Покрытие этого множества гарантирует обнаружение ошибок булевых операторов и операторов отношения в С1.
Пример 3. Рассмотрим составное условие С2
вида
(E3 >E4)&(E1=E2),
где E1, Е2, Е3, Е4
— арифметические выражения. Ограничение составного условия имеет вид
ОУ

где ограничения простых условий равны
d1=(=,<,>), d2 =(=,<,>).
Проводя аналогию между С2
и С1 (разница лишь в том, что в С2 первое простое условие — это выражение отношения), мы можем построить ограничивающее множество для С2 модификацией ОМ
ОМ
Покрытие этого ограничивающего множества гарантирует обнаружение ошибок операторов отношения в С2.
Тестирование восстановления
Многие компьютерные системы должны восстанавливаться после отказов и возобновлять обработку в пределах заданного времени. В некоторых случаях система должна быть отказоустойчивой, то есть отказы обработки не должны быть причиной прекращения работы системы. В других случаях системный отказ должен быть устранен в пределах заданного кванта времени, иначе заказчику наносится серьезный экономический ущерб.
Тестирование восстановления использует самые разные пути для того, чтобы заставить ПС отказать, и проверяет полноту выполненного восстановления. При автоматическом восстановлении оцениваются правильность повторной инициализации, механизмы копирования контрольных точек, восстановление данных, перезапуск. При ручном восстановлении оценивается, находится ли среднее время восстановления в допустимых пределах.
Типы информационных потоков
Различают 2 типа информационных потоков:
1) поток преобразований;
2) поток запросов.
Как показано на рис. 5.1, в потоке преобразований выделяют 3 элемента: Входящий поток, Преобразуемый поток и Выходящий поток.
Потоки запросов имеют в своем составе особые элементы — запросы.
Назначение элемента-запроса состоит в том, чтобы запустить поток данных по одному из нескольких путей. Анализ запроса и переключение потока данных на один из путей действий происходит в центре запросов.
Структуру потока запроса иллюстрирует рис. 5.2.

Рис. 5.1. Элементы потока преобразований
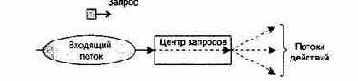
Рис. 5.2. Структура потока запроса
Тяжеловесные и облегченные процессы
В XXI веке потребности общества в программном обеспечении информационных технологий достигли экстремальных значений. Программная индустрия буквально «захлебывается» от потока самых разнообразных заказов. «Больше процессов разработки, хороших и разных!» — скандируют заказчики. «Сейчас, сейчас! Только об этом и думаем!» — отвечают разработчики.
Традиционно для упорядочения и ускорения программных разработок предлагались строго упорядочивающие тяжеловесные (heavyweight) процессы. В этих процессах прогнозируется весь объем предстоящих работ, поэтому они называются прогнозирующими (predictive) процессами. Порядок, который должен выполнять при этом человек-разработчик, чрезвычайно строг — «шаг вправо, шаг влево — виртуальный расстрел!». Иными словами, человеческие слабости в расчет не принимаются, а объем необходимой документации способен отнять покой и сон у «совестливого» разработчика.
В последние годы появилась группа новых, облегченных (lightweight) процессов [29]. Теперь их называют подвижными (agile) процессами [8], [25], [36]. Они привлекательны отсутствием бюрократизма, характерного для тяжеловесных (прогнозирующих) процессов. Новые процессы должны воплотить в жизнь разумный компромисс между слишком строгой дисциплиной и полным ее отсутствием. Иначе говоря, порядка в них достаточно для того, чтобы получить разумную отдачу от разработчиков.
Подвижные процессы требуют меньшего объема документации и ориентированы на человека. В них явно указано на необходимость использования природных качеств человеческой натуры (а не на применение действий, направленных наперекор этим качествам).
Более того, подвижные процессы учитывают особенности современного заказчика, а именно частые изменения его требований к программному продукту. Известно, что для прогнозирующих процессов частые изменения требований подобны смерти. В отличие от них, подвижные процессы адаптируют изменения требований и даже выигрывают от этого. Словом, подвижные процессы имеют адаптивную природу.
Таким образом, в современной инфраструктуре программной инженерии существуют два семейства процессов разработки:
q семейство прогнозирующих (тяжеловесных) процессов;
q семейство адаптивных (подвижных, облегченных) процессов.
У каждого семейства есть свои достоинства, недостатки и область применения:
q адаптивный процесс используют при частых изменениях требований, малочисленной группе высококвалифицированных разработчиков и грамотном заказчике, который согласен участвовать в разработке;
q прогнозирующий процесс применяют при фиксированных требованиях и многочисленной группе разработчиков разной квалификации.
Трассировка и контроль
Каждая задача, помеченная в плане, отслеживается руководителем проекта. При отставании в решении задачи применяются утилиты повторного планирования. С помощью утилит определяется влияние этого отставания на промежуточную веху и общее время конструирования. Под вехой понимается временная метка, к которой привязано подведение промежуточных итогов.
В результате повторного планирования:
q могут быть перераспределены ресурсы;
q могут быть реорганизованы задачи;
q могут быть пересмотрены выходные обязательства.
Учет системного времени
На шаге учета системного времени проектировщик определяет временные ограничения, накладываемые на систему, фиксирует дисциплину планирования. Дело в том, что на предыдущих шагах проектирования была получена система, составленная из последовательных процессов. Эти процессы связывали только потоки данных, передаваемые через буфер, и взаимные наблюдения векторов состояния. Теперь необходимо произвести дополнительную синхронизацию процессов во времени, учесть влияние внешней программно-аппаратной среды и совместно используемых системных ресурсов.
Временные ограничения для системы обслуживания перевозок, в частности, включают:
q временной интервал на выработку команды STOP; он должен выбираться путем анализа скорости транспорта и ограничения мощности;
q время реакции на включение и выключение ламп панели.
Для рассмотренного примера нет необходимости вводить специальный механизм синхронизации. Однако при расширении может потребоваться некоторая синхронизация обмена данными.
Унифицированный язык моделирования
UML — стандартный язык для написания моделей анализа, проектирования и реализации объектно-ориентированных программных систем [23], [53], [67]. UML может использоваться для визуализации, спецификации, конструирования и документирования результатов программных проектов. UML — это не визуальный язык программирования, но его модели прямо транслируются в текст на языках программирования (Java, C++, Visual Basic, Ada 95, Object Pascal) и даже в таблицы для реляционной БД.
Словарь UML образуют три разновидности строительных блоков: предметы, отношения, диаграммы.
Предметы — это абстракции, которые являются основными элементами в модели, отношения связывают эти предметы, диаграммы группируют коллекции предметов.
Unknown — базовый интерфейс COM
Интерфейс lUnknown обеспечивает минимальное «снаряжение» каждого объекта СОМ. Он содержит три операции и предоставляет любому объекту СОМ две функциональные возможности:
q операция Querylnterface() позволяет клиенту получить указатель на любой интерфейс объекта (из другого указателя интерфейса);
q операции AddRef() и Release() обеспечивают механизм управления временем жизни объекта.
Свой первый указатель на интерфейс объекта клиент получает при создании объекта СОМ. Порядок получения других указателей на интерфейсы (для вызова их операций) поясняет рис. 13.17, где расписаны три шага работы. В качестве параметра операции Querylnterface задается идентификатор требуемого интерфейса (IID). Если требуемый интерфейс отсутствует, операция возвращает значение NULL.
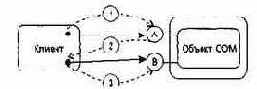
Рис. 13.17. Получение указателя на интерфейс с помощью Querylnterface: 1 — с помощью
указателя на интерфейс А клиент запрашивает указатель на интерфейс В, вызывая
Querylnterface (IID_B); 2 — объект возвращает указатель на интерфейс В;
3 — теперь клиент может вызывать операции из интерфейса В
Имеет смысл отметить и второе важное достоинство операции Querylnterface. В сочетании с требованием неизменности СОМ-интерфейсов она позволяет «убить двух зайцев»:
q развивать компоненты;
q обеспечивать стабильность клиентов, использующих компоненты.
Поясним это утверждение. По законам СОМ-этики новый СОМ-объект должен нести в себе и старый СОМ-интерфейс, а операция Querylnterface всегда обеспечит доступ к нему.
Ну а теперь обсудим правила жизни, а точнее смерти СОМ-объекта. В многоликой СОМ-среде бремя ответственности за решение вопроса о финализации должно лежать как на клиенте, так и на СОМ-объекте. Можно сказать, что фирма Microsoft (создатель этой модели) разработала самурайский кодекс поведения СОМ-объекта — он должен сам себя уничтожить. Возникает вопрос — когда? Когда он перестанет быть нужным всем своим клиентам, когда вытечет песок из часов его жизни. Роль песочных часов играет счетчик ссылок (СЧС) СОМ-объекта.
Правила финализации СОМ-объекта очень просты:
q при выдаче клиенту указателя на интерфейс выполняется СЧС+1;
q при вызове операции AddRef выполняется СЧС+1;
q при вызове операции Release выполняется СЧС-1;
q при СЧС=0 объект уничтожает себя.
Конечно, клиент должен помогать достойному харакири объекта-самурая:
q при получении от другого клиента указателя на интерфейс СОМ-объекта он должен вызвать в этом объекте операцию AddRef;
q в конце работы с объектом он обязан вызвать его операцию Release.
Управление риском
Словарь русского языка С. И. Ожегова и Н. Ю. Шведовой определяет риск как «возможность опасности, неудачи». Влияние риска вычисляют по выражению
RE = P(UO) x L(UO),
где:
q RE — показатель риска (Risk Exposure — подверженность риску);
q P(UO) — вероятность неудовлетворительного результата (Unsatisfactory Outcome);
q L(UO) — потеря при неудовлетворительном результате.
При разработке программного продукта неудовлетворительным результатом может быть: превышение бюджета, низкая надежность, неправильное функционирование и т. д. Управление риском включает шесть действий:
1. Идентификация риска — выявление элементов риска в проекте.
2. Анализ риска — оценка вероятности и величины потери по каждому элементу риска.
3. Ранжирование риска — упорядочение элементов риска по степени их влияния.
4. Планирование управления риском — подготовка к работе с каждым элементом риска.
5. Разрешение риска — устранение или разрешение элементов риска.
6. Наблюдение риска — отслеживание динамики элементов риска, выполнение корректирующих действий.
Первые три действия относят к этапу оценивания риска, последние три действия — к этапу контроля риска [20].
Условные переходы
Между состояниями возможны различные типы переходов. Обычно переход инициируется событием. Допускаются переходы и без событий. Наконец, разрешены условные или охраняемые переходы.
Правила пометки стрелок условных переходов иллюстрирует рис. 12.7.

Рис. 12.7. Обозначение условного перехода
Порядок выполнения условного перехода:
1) происходит событие;
2) вычисляется условие УсловиеПерехода;
3) при УсловиеПерехода=true запускается переход и активизируется действие, в противном случае переход не выполняется.
Пример условного перехода между состояниями Инициализация и Ожидание приведен на рис. 12.8. Он происходит по событию ПитаниеПодано, но только в том случае, если достигнут боевой режим лазера.

Рис. 12.8. Условный переход между состояниями
Узлы
Узел — физический элемент, который существует в период работы системы и представляет компьютерный ресурс, имеющий память, а возможно, и способность обработки. Графически узел изображается как куб с именем (рис. 13.25).

Рис. 13.25. Обозначение узла
Как и класс, узел может иметь дополнительную секцию, отображающую размещаемые в нем элементы (рис. 13.26).
Рис. 13.26. Размещение компонентов в узле
Сравним узлы с компонентами. Конечно, у них есть сходные характеристики:
q наличие имени;
q возможность быть вложенным;
q наличие экземпляров.
Последняя характеристика говорит о том, что на предыдущем рисунке изображен тип Контроллера. Изображение конкретного экземпляра, принадлежащего этому типу, представлено на рис. 13.27.
Теперь обсудим отличия узлов от компонентов. Во-первых, они принадлежат к разным уровням иерархии в физической реализации системы. Физически система состоит из узлов, а узлы — из компонентов. Во-вторых, у каждого из них свое назначение. Компонент предназначен для физической упаковки и материализации набора логических элементов (классов и коопераций). Узел же является тем местом, где физически размещаются компоненты, то есть играет роль «квартиры» для компонентов.
Рис. 13.27. Экземпляр узла
Отношение между узлом и компонентами, которые он размещает, можно отобразить явно. Отношение зависимости между узлом Контроллер и компонентами Вводы.ехе, Выводы.ехе иллюстрирует рис. 13.28. Правда, чаще всего такие отношения не отображаются. Их удобно представлять в отдельной спецификации узла.
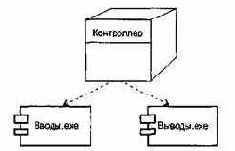
Рис. 13.28. Зависимость узла от компонентов
Группировку набора объектов или компонентов, размещаемых в узле, обычно называют распространяемым модулем.
Для узла, как и для класса, можно задать свойства и операции. Например, можно определить свойства БыстродействиеПроцессора, ЕмкостьПамяти, а также операции Запустить, Выключить.
Вершины в диаграммах классов
Итак, вершина в диаграмме классов — класс. Обозначение класса показано на рис. 11.1.

Рис. 11.1. Обозначение класса
Имя класса указывается всегда, свойства и операции — выборочно. Предусмотрено задание области действия свойства (операции). Если свойство (операция) подчеркивается, его областью действия является класс, в противном случае областью Действия является экземпляр (рис. 11.2).
Что это значит? Если областью действия свойства является класс, то все его экземпляры (объекты) используют общее значение этого свойства, в противном случае у каждого экземпляра свое значение свойства.

Рис. 11.2. Свойства уровней класса и экземпляра
Видимость объектов
Рассмотрим два объекта, А и В, между которыми имеется связь. Для того чтобы объект А мог послать сообщение в объект В, надо, чтобы В был виден для А.
В примере из предыдущего подраздела объект РабочийКонтроллер должен видеть объект РабочийГрафик (чтобы иметь возможность использовать его как аргумент в операции Обрабатывать).
Различают четыре формы видимости между объектами.
1. Объект-поставщик (сервер) глобален для клиента.
2. Объект-поставщик (сервер) является параметром операции клиента.
3. Объект-поставщик (сервер) является частью объекта-клиента.
4. Объект-поставщик (сервер) является локально объявленным объектом в операции клиента.
На этапе анализа вопросы видимости обычно опускают. На этапах проектирования и реализации вопросы видимости по связям обязательно должны рассматриваться.
Виды отношений между классами
Классы, подобно объектам, не существуют в изоляции. Напротив, с отдельной проблемной областью связывают ключевые абстракции, отношения между которыми формируют структуру из классов системы.
Всего существует четыре основных вида отношений между классами:
q ассоциация (фиксирует структурные отношения — связи между экземплярами классов);
q зависимость (отображает влияние одного класса на другой класс);
q обобщение-специализация («is а»-отношение);
q целое-часть («part of»-отношение).
Для покрытия основных отношений большинство объектно-ориентированных языков программирования поддерживает следующие отношения:
1) ассоциация;
2) наследование;
3) агрегация;
4) зависимость;
5) конкретизация;
6) метакласс;
7) реализация.
Ассоциации обеспечивают взаимодействия объектов, принадлежащих разным классам. Они являются клеем, соединяющим воедино все элементы программной системы. Благодаря ассоциациям мы получаем работающую систему. Без ассоциаций система превращается в набор изолированных классов-одиночек.
Наследование — наиболее популярная разновидность отношения обобщение-специализация. Альтернативой наследованию считается делегирование. При делегировании объекты делегируют свое поведение родственным объектам. При этом классы становятся не нужны.
Агрегация обеспечивает отношения целое-часть, объявляемые для экземпляров классов.
Зависимость часто представляется в виде частной формы — использования, которое фиксирует отношение между клиентом, запрашивающим услугу, и сервером, предоставляющим эту услугу.
Конкретизация выражает другую разновидность отношения обобщение-специализация. Применяется в таких языках, как Ada 95, C++, Эйфель.
Отношения метаклассов поддерживаются в языках SmallTalk и CLOS. Метакласс — это класс классов, понятие, позволяющее обращаться с классами как с объектами.
Реализация определяет отношение, при котором класс-приемник обеспечивает свою собственную реализацию интерфейса другого класса-источника. Иными словами, здесь идет речь о наследовании интерфейса. Семантически реализация — это «скрещивание» отношений зависимости и обобщения-специализации.
Виды отношений между объектами
В поле зрения разработчика ПО находятся не объекты-одиночки, а взаимодействующие объекты, ведь именно взаимодействие объектов реализует поведение системы. У Г. Буча есть отличная цитата из Галла: «Самолет — это набор элементов, каждый из которых по своей природе стремится упасть на землю, но ценой совместных непрерывных усилий преодолевает эту тенденцию» [22]. Отношения между парой объектов основываются на взаимной информации о разрешенных операциях и ожидаемом поведении. Особо интересны два вида отношений между объектами: связи и агрегация.
Вложенные циклы
С увеличением уровня вложенности циклов количество возможных путей резко возрастает. Это приводит к нереализуемому количеству тестов [13]. Для сокращения количества тестов применяется специальная методика, в которой используются такие понятия, как объемлющий и вложенный циклы (рис. 6.11).

Рис. 6.11. Объемлющий и вложенный циклы
Порядок тестирования вложенных циклов иллюстрирует рис. 6.12.
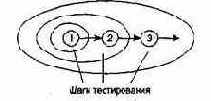
Рис. 6.12. Шаги тестирования вложенных циклов
Шаги тестирования.
1. Выбирается самый внутренний цикл. Устанавливаются минимальные значения параметров всех остальных циклов.
2. Для внутреннего цикла проводятся тесты простого цикла. Добавляются тесты для исключенных значений и значений, выходящих за пределы рабочего диапазона.
3. Переходят в следующий по порядку объемлющий цикл. Выполняют его тестирование. При этом сохраняются минимальные значения параметров для всех внешних (объемлющих) циклов и типовые значения для всех вложенных циклов.
4. Работа продолжается до тех пор, пока не будут протестированы все циклы.
Вложенные состояния
Одной из наиболее важных характеристик конечных автоматов в UML является подсостояние. Подсостояние позволяет значительно упростить моделирование сложного поведения. Подсостояние — это состояние, вложенное в другое состояние. На рис. 12.9 показано составное состояние, содержащее в себе два подсостояния.

Рис. 12.9. Обозначение подсостояний
На рис. 12.10 приведена внутренняя структура составного состояния Активна.

Рис. 12.10. Переходы в состоянии Активна
Семантика вложенности такова: если система находится в состоянии Активна, то она должна быть точно в одном из подсостояний: Проверка, Звонок, Ждать. В свою очередь, в подсостояние могут вкладываться другие подсостояния. Степень вложенности подсостояний не ограничивается. Данная семантика соответствует случаю последовательных подсостояний.
Возможно наличие параллельных подсостояний — они выполняются параллельно внутри составного состояния. Графически изображения параллельных подсостояний отделяются друг от друга пунктирными линиями.
Иногда при возврате в составное состояние возникает необходимость попасть в то его подсостояние, которое в прошлый раз было последним. Такое подсостояние называют историческим. Информация об историческом состоянии запоминается. Как показано на рис. 12.11, подобная семантика переходов отображается значком истории — буквой Н внутри кружка.

Рис. 12.11. Историческое состояние
При первом посещении состояния Активна автомат не имеет истории, поэтому происходит простой переход в подсостояние Проверка. Предположим, что в подсостоя-нии Звонок произошло событие Запрос. Средства управления заставляют автомат покинуть подсостояние Звонок (и состояние Активна) и вернуться в состояние Команды. Когда работа в состоянии Команды завершается, выполняется возврат в историческое подсостояние состояния Активна. Поскольку теперь автомат запомнил историю, он переходит прямо в подсостояние Звонок (минуя подсостояние Проверка).
Как показано на рис. 12.12, для обозначения составного состояния, имеющего внутри себя скрытые (не показанные на диаграмме) подсостояния, используется символ «очки».

Рис. 12.12. Символ состояния со скрытыми подсостояниями
Восходящее тестирование интеграции
При восходящем тестировании интеграции сборка и тестирование системы начинаются с модулей-атомов, располагаемых на нижних уровнях иерархии. Модули подключаются движением снизу вверх. Подчиненные модули всегда доступны, и нет необходимости в заглушках.
Рассмотрим шаги методики восходящей интеграции.
1. Модули нижнего уровня объединяются в кластеры (группы, блоки), выполняющие определенную программную подфункцию.
2. Для координации вводов-выводов тестового варианта пишется драйвер, управляющий тестированием кластеров.
3. Тестируется кластер.
4. Драйверы удаляются, а кластеры объединяются в структуру движением вверх. Пример восходящей интеграции системы приведен на рис. 8.6.
Модули объединяются в кластеры 1,2,3. Каждый кластер тестируется драйвером. Модули в кластерах 1 и 2 подчинены модулю Ма, поэтому драйверы D1 и D2 удаляются и кластеры подключают прямо к Ма. Аналогично драйвер D3 удаляется перед подключением кластера 3 к модулю Mb. В последнюю очередь к модулю Мс подключаются модули Ма и Mb.
Рассмотрим различные типы драйверов:
q драйвер А — вызывает подчиненный модуль;
q драйвер В — посылает элемент данных (параметр) из внутренней таблицы;
q драйвер С —отображает параметр из подчиненного модуля;
q драйвер D — является комбинацией драйверов В и С.
Очевидно, что драйвер А наиболее прост, а драйвер D наиболее сложен в реализации. Различные типы драйверов представлены на рис. 8.7.
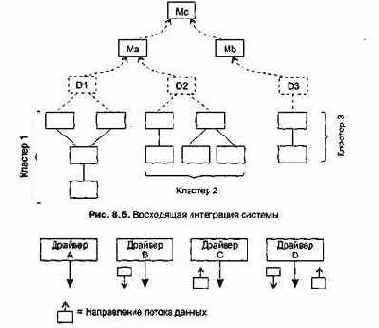
Рис. 8.7. Различные типы драйверов
По мере продвижения интеграции вверх необходимость в выделении драйверов уменьшается. Как правило, в двухуровневой структуре драйверы не нужны.
Временная связность
При связности по времени элементы-обработчики модуля привязаны к конкретному периоду времени (из жизни программной системы).
Классическим примером временной связности является модуль инициализации:
Модуль Инициализировать Систему
перемотать магнитную ленту 1
Счетчик магнитной ленты 1 := 0
перемотать магнитную ленту 2
Счетчик магнитной ленты 2 := 0
Таблица текущих записей : = пробел..пробел
Таблица количества записей := 0..0
Переключатель 1 : = выкл
Переключатель 2 := вкл
Конец модуля
Элементы данного модуля почти не связаны друг с другом (за исключением того, что должны выполняться в определенное время). Они все — часть программы запуска системы. Зато элементы более тесно взаимодействуют с другими модулями, что приводит к сложным внешним связям.
Модуль со связностью по времени испытывает те же трудности, что и процедурно связный модуль. Программист соблазняется возможностью совместного использования кода (действиями, которые связаны только по времени), модуль становится трудно использовать повторно.
Так, при желании инициализировать магнитную ленту 2 в другое время вы столкнетесь с неудобствами. Чтобы не сбрасывать всю систему, придется или ввести флажки, указывающие инициализируемую часть, или написать другой код для работы с лентой 2. Оба решения ухудшают сопровождаемость.
Процедурно связные модули и модули с временной связностью очень похожи. Степень их непрозрачности изменяется от темного серого до светло-серого цвета, так как трудно объявить функцию такого модуля без перечисления ее внутренних деталей. Различие между ними подобно различию между информационной и коммуникативной связностью. Порядок выполнения действий более важен в процедурно связных модулях. Кроме того, процедурные модули имеют тенденцию к совместному использованию циклов и ветвлений, а модули с временной связностью чаще содержат более линейный код.
что основной задачей первых трех
Известно, что основной задачей первых трех десятилетий компьютерной эры являлось развитие аппаратных компьютерных средств. Это было обусловлено высокой стоимостью обработки и хранения данных. В 80-е годы успехи микроэлектроники привели к резкому увеличению производительности компьютера при значительном снижении стоимости.
Основной задачей 90-х годов и начала XXI века стало совершенствование качества компьютерных приложений, возможности которых целиком определяются программным обеспечением (ПО).
Современный персональный компьютер теперь имеет производительность большой ЭВМ 80-х годов. Сняты практически все аппаратные ограничения на решение задач. Оставшиеся ограничения приходятся на долю ПО.
Чрезвычайно актуальными стали следующие проблемы:
q аппаратная сложность опережает наше умение строить ПО, использующее потенциальные возможности аппаратуры;
q наше умение строить новые программы отстает от требований к новым программам;
q нашим возможностям эксплуатировать существующие программы угрожает низкое качество их разработки.
Ключом к решению этих проблем является грамотная организация процесса создания ПО, реализация технологических принципов промышленного конструирования программных систем (ПС).
Настоящий учебник посвящен систематическому изложению принципов, моделей и методов (формирования требований, анализа, синтеза и тестирования), используемых в инженерном цикле разработки сложных программных продуктов.
В основу материала положен двенадцатилетний опыт постановки и преподавания автором соответствующих дисциплин в Рижском авиационном университете и Рижском институте транспорта и связи. Базовый курс «Технология конструирования программного обеспечения» прослушали больше тысячи студентов, работающих теперь в инфраструктуре мировой программной индустрии, в самых разных странах и на самых разных континентах.
Автор стремился к достижению трех целей:
q показать последние научные и практические достижения, характеризующие динамику развития в области Software Engineering;
q обеспечить комплексный охват наиболее важных вопросов, возникающих в больших программных проектах.
Компьютерные науки вообще и программная инженерия в частности — очень популярные и стремительно развивающиеся области знаний. Обоснование простое: человеческое общество XXI века — информационное общество. Об этом говорят цифры: в ведущих странах занятость населения в информационной сфере составляет 60%, а в сфере материального производства — 40%. Именно поэтому специальности направления «Компьютерные науки и информационные технологии» гарантируют приобретение наиболее престижных, дефицитных и высокооплачиваемых профессий. Так считают во всех развитых странах мира. Ведь не зря утверждают: «Кто владеет информацией — тот владеет миром!»
Поэтому понятно то пристальное внимание, которое уделяет компьютерному образованию мировое сообщество, понятно стремление унифицировать и упорядочить знания, необходимые специалисту этого направления. Одними из результатов такой работы являются международный стандарт по компьютерному образованию Computing Curricula 2001 — Computer Science и международный стандарт по программной инженерии IEEE/ACM Software Engineering Body of Knowledge SWEBOK 2001.
Содержание данного учебника отвечает рекомендациям этих стандартов. Учебник состоит из 17 глав.
Первая глава посвящена организации классических, современных и перспективных процессов разработки ПО.
Вторая глава знакомит с вопросами руководства программными проектами — планированием, оценкой затрат. Вводятся размерно-ориентированные и функционально-ориентированные метрики затрат, обсуждается методика их применения, описывается наиболее популярная модель для оценивания затрат — СОСОМО II. Приводятся примеры предварительной оценки программного проекта и анализа чувствительности проекта к изменению условий разработки.
Третья глава рассматривает классические методы анализа при разработке ПО.
Четвертая глава отведена основам проектирования программных систем. Здесь обсуждаются архитектурные модели ПО, основные проектные характеристики: модульность, информационная закрытость, сложность, связность, сцепление и метрики для их оценки.
Пятая глава описывает классические методы проектирования ПО.
Шестая глава определяет базовые понятия структурного тестирования программного обеспечения (по принципу «белого ящика») и знакомит с наиболее популярными методиками данного вида тестирования: тестированием базового пути, тестированием ветвей и операторов отношений, тестированием потоков данных, тестированием циклов.
Седьмая глава вводит в круг понятий функционального тестирования ПО и описывает конкретные способы тестирования — путем разбиения по эквивалентности, анализа граничных значений, построения диаграмм причин-следствий.
Восьмая глава ориентирована на комплексное изложение содержания процесса тестирования: тестирование модулей, тестирование интеграции модулей в программную систему; тестирование правильности, при котором проверяется соответствие системы требованиям заказчика; системное тестирование, при котором проверяется корректность встраивания ПО в цельную компьютерную систему. Здесь же рассматривается организация отладки ПО (с целью устранения выявленных при тестировании ошибок).
Девятая глава посвящена принципам объектно-ориентированного представления программных систем — особенностям их абстрагирования, инкапсуляции, модульности, построения иерархии. Обсуждаются характеристики основных строительных элементов объектно-ориентированного ПО — объектов и классов, а также отношения между ними.
В десятой главе дается сжатое изложение базовых понятий языка визуального моделирования — UML, рассматривается его современная версия 1.4.
Одиннадцатая глава представляет инструментарий UML для задания статических моделей, описывающих структуру объектно-ориентированных программных систем.
Двенадцатая глава отображает самый многочисленный инструментарий UML — инструментарий для задания динамических моделей, описывающих поведение объектно-ориентированных программных систем.
Впрочем, здесь излагаются и смежные вопросы: формирование модели требований к разработке ПО с помощью аппарата Use Case, фиксация комплексных динамических решений с помощью коопераций и паттернов, бизнес-моделирование как средство предпроектного анализа организации-заказчика.
Тринадцатая глава отведена моделям реализации, описывающим формы представления объектно-ориентированных программных систем в физическом мире. Помимо компонентов, узлов и соответствующих диаграмм их обитания здесь приводится пример современной компонентной модели от Microsoft — COM.
В четырнадцатой главе обсуждается метрический аппарат для оценки качества объектно-ориентированных проектных решений: метрики оценки объектно-ориентированной связности, сцепления; широко известные наборы метрик Чидамбера и Кемерера, Фернандо Абреу, Лоренца и Кидда; описывается методика их применения.
Пятнадцатая глава решает задачу презентации унифицированного процесса разработки объектно-ориентированных программных систем, на конкретном примере обучает методике применения этого процесса. Кроме того, здесь рассматриваются методика управления риском разработки, процесс разработки в стиле «экстремальное программирование».
Шестнадцатая глава обучает особенностям объектно-ориентированного тестирования, проведению такого тестирования на уровне визуальных моделей, уровне методов, уровне классов и уровне взаимодействия классов.
Семнадцатая глава демонстрирует возможности применения CASE-системы Rational Rose к решению задач автоматизации формирования требований, анализа, проектирования, компонентной упаковки и программирования программного продукта.
Учебник предназначен для студентов бакалаврского и магистерского уровней компьютерных специальностей, может быть полезен преподавателям, разработчикам промышленного программного обеспечения, менеджерам программных проектов.
Вот и все. Насколько удалась эта работа — судить Вам, уважаемый читатель.
Благодарности
Прежде всего, мои слова искренней любви родителям — Нине Николаевне и Александру Ивановичу Орловым (светлая им память).
Самые теплые слова благодарности моей семье, родным, любимым и близким мне людям — Лизе, Иванне, Жене. Без их долготерпения, внимания, поддержки, доброжелательности и сердечной заботы эта книга никогда не была бы написана. Моя признательность также и верному сеттеру Эльфу — это он внимательно следил за всеми моими ночными бдениями и клал мне лапу на плечо в особо трудные минуты.
Выход в свет этой работы был бы невозможен вне творческой атмосферы, бесчисленных вопросов и положительной обратной связи, которую создавали мои многочисленные студенты.
Хочется отметить, что корабль-учебник не прибыл бы в порт назначения без опытного капитана (руководителя проекта) Андрея Васильева. Автор искренне признателен талантливым сотрудникам издательства «Питер».
И конечно, огромное спасибо моим коллегам, всем людям, которые принимали участие в моем путешествии по городам, улицам и бесконечным переулкам страны ПРОГРАММНАЯ ИНЖЕНЕРИЯ.
q изложить классические основы, отражающие накопленный мировой опыт программной инженерии;
Выполнение оценки проекта на основе LOC- и FP-метрик
Цель этой деятельности — сформировать предварительные оценки, которые позволят:
q предъявить заказчику корректные требования по стоимости и затратам на разработку программного продукта;
q составить план программного проекта.
При выполнении оценки возможны два варианта использования LOC- и FP-данных:
q в качестве оценочных переменных, определяющих размер каждого элемента продукта;
q в качестве метрик, собранных за прошлые проекты и входящих в метрический базис фирмы.
Обсудим шаги процесса оценки.
q Шаг 1. Область назначения проектируемого продукта разбивается на ряд функций, каждую из которых можно оценить индивидуально:
f1, f2,…,fn.
q Шаг 2. Для каждой функции fi, планировщик формирует лучшую LOCлучшi (FРлучшi), худшую LOCхудшi
(FРхудшi) и вероятную оценку LOCвероятнi (FРвероятнi). Используются опытные данные (из метрического базиса) или интуиция. Диапазон значения оценок соответствует степени предусмотренной неопределенности.
q Шаг 3. Для каждой функции/ в соответствии с

LOCожi =(LOCлучшi + LOCхудшi +4x LOCвероятнi )/ 6.
q Шаг 4. Определяется значение LOC- или FP-производительности разработки функции.
Используется один из трех подходов:
1) для всех функций принимается одна и та же метрика средней производительности ПРОИЗВср, взятая из метрического базиса;
2) для i-й функции на основе метрики средней производительности вычисляется настраиваемая величина производительности:
ПРОИЗВi =ПРОИЗВсрх(LOCср /LOCожi),
где LOCcp — средняя LOC-оценка, взятая из метрического базиса (соответствует средней производительности);
3) для i-й функции настраиваемая величина производительности вычисляется по аналогу, взятому из метрического базиса:
ПРОИЗВi =ПРОИЗВанiх(LOCанi
/LOCожi).
Первый подход обеспечивает минимальную точность (при максимальной простоте вычислений), а третий подход — максимальную точность (при максимальной сложности вычислений).
q Шаг 5. Вычисляется общая оценка затрат на проект: для первого подхода

для второго и третьего подходов

q Шаг 6. Вычисляется общая оценка стоимости проекта: для первого и второго подходов

где УД_СТОИМОСТЬср
— метрика средней стоимости одной строки, взятая из метрического базиса.
для третьего подхода

где УД_СТОИМОСТЬанi — метрика стоимости одной строки аналога, взятая из метрического базиса. Пример применения данного процесса оценки приведем ниже.
Выполнение оценки в ходе руководства проектом
Процесс руководства программным проектом начинается с множества действий, объединяемых общим названием планирование проекта. Первое из этих действий — выполнение оценки. Оно закладывает фундамент для других действий по планированию проекта. При оценке проекта чрезвычайно высока цена ошибок. Очень важно провести оценку с минимальным риском.
Взаимодействие с заказчиком
Одно из требований ХР — постоянное участие заказчика в проведении разработки. По сути, заказчик является одним из разработчиков.
Все этапы ХР требуют непосредственного присутствия заказчика в команде разработчиков. Причем разработчикам нужен заказчик-эксперт. Он создает пользовательские истории, на основе которых оценивается время и назначаются приоритеты работ. В ходе планирования реализации заказчик указывает, какие истории следует включить в план реализации. Активное участие он принимает и при планировании итерации.
Заказчик должен как можно раньше увидеть программную систему в работе. Это позволит как можно раньше испытать систему и дать отзыв о ее работе. Поскольку при укрупненном планировании заказчик остается в стороне, разработчикам нужно постоянно общаться с заказчиком, чтобы получать как можно больше сведений при реализации задач программирования. Нужен заказчик и на этапе функционального тестирования, при проведении тестов приемки.
Таким образом, активное участие заказчика не только предотвращает появление некачественной системы, но и является непременным условием выполнения разработки.
и быстро развивающаяся область знаний
Современная программная инженерия (Software Engineering) — молодая и быстро развивающаяся область знаний и практик. Она ориентирована на комплексное решение задач, связанных с разработкой особой разновидности сложных систем — программных систем.
Программные системы — самые необычные и удивительные создания рук человеческих. Они не имеют физических тел, их нельзя потрогать, ощутить одним из человеческих чувств. Они не подвергаются физическому износу, их нельзя изготовить в обычном инженерном смысле, как автомобиль на заводе. И вместе с тем разработка программных систем является самой сложной из задач, которые приходилось когда-либо решать человеку-инженеру. В пределе — это задача создания рукотворной системы, сопоставимой по сложности самому творцу.
Многие стереотипы и приемы, разработанные в физическом мире, оказались неприменимы к инженерии программных систем. Приходилось многое изобретать и придумывать. Все это теперь история. Программные инженеры начинали с полного неприятия инструментария других инженерных дисциплин, уверовав в свою кастовость «жрецов в белых халатах», и совершили эволюционный круг, вернувшись в лоно общечеловеческой инженерии.
Впрочем, были времена, когда и другие «кланы» людей относились к «программе-рам» с большим подозрением: им мало платили, унижая материально, не находили для них ласковых слов (а употребляли большей частью ругательные). Где эти люди? И где их прежнее отношение?
Современное общество впадает во все большую зависимость от программных технологий. Программного инженера стали любить, охотно приглашать в гости, хорошо кормить, обувать и одевать. Словом, стали лелеять и холить (правда, время от времени продолжают сжигать на костре и предавать анафеме).
Современная программная инженерия почти достигла уровня зрелости — об этом свидетельствуют современные тенденции; она разворачивается от сердитого отношения к своим разработчикам к дружелюбному, снисходительному пониманию человеческих слабостей.
Базис современной программной инженерии образуют следующие составляющие:
q процессы конструирования ПО;
q метрический аппарат, обеспечивающий измерения процессов и продуктов;
q аппарат формирования исходных требований к разработкам;
q аппарат анализа и проектирования ПО;
q аппарат визуального моделирования ПО;
q аппарат тестирования программных продуктов.
Все эти составляющие рассмотрены в данном учебнике. Конечно, многое осталось за кадром. Реорганизация (рефакторинг), особенности конструирования web-приложений, работа с базами данных — вот неполный перечень тем, обсудить которые не позволили ресурсные ограничения. Хотелось бы обратить внимание на новейшие постобъектные методологии — аспектно-ориентированное и многомерное проектирование и программирование. Они представляют собой новую высоту в стремительном полете в компьютерный космос. Но это — тема следующей работы. Впереди длинная и интересная дорога познаний. Как хочется подольше шагать по этой дороге.
В заключение «родился теплый лирический тост» — за программистов всех стран! А если серьезно, друзья, вы — строители целого виртуального мира, я верю в вас, я горжусь вами. Дерзайте, творите, разочаровывайтесь и очаровывайтесь! Я уверен, вы построите достойное информационное обеспечение человеческого общества!
Зависимость
Зависимость — это отношение, которое показывает, что изменение в одном классе (независимом) может влиять на другой класс (зависимый), который использует его. Графически зависимость изображается как пунктирная стрелка, направленная на класс, от которого зависят. С помощью зависимости уточняют, какая абстракция является клиентом, а какая — поставщиком определенной услуги. Пунктирная стрелка зависимости направлена от клиента к поставщику.
Наиболее часто зависимости показывают, что один класс использует другой класс как аргумент в сигнатуре своей операции. В предыдущем примере (на языке Ada 95) класс ГрафикРазворота появляется как аргумент в методах Обрабатывать и Запланировано класса КонтроллерУгла. Поэтому, как показано на рис. 9.16, КонтроллерУгла зависит от класса ГрафикРазворота.
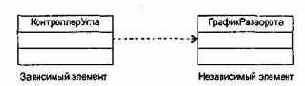
Рис. 9.16. Отношение зависимости
