Абстрактные базы как двоичные интерфейсы
Оказывается, применение техники разделения интерфейса и реализации может решить и проблемы совместимости транслятора/компоновщика C++. При этом, однако, определение класса интерфейса должно принять несколько иную форму. Как отмечалось ранее, проблемы совместимости возникают из-за того, что разные трансляторы имеют различные соображения по поводу того, как
передавать особенности языка на этапе выполнения;
символические имена будут представлены на этапе компоновки.
Если бы кто-нибудь придумал, как скрыть детали реализации транслятора/компоновщика за каким-либо двоичным интерфейсом, это сделало бы написанные на C++ библиотеки DLL значительно более широко используемыми.
Двоичная защита, то есть тот факт, что класс интерфейса C++ не использует языковых конструкций, зависящих от транслятора, решает проблему зависимости от транслятора/компоновщика. Чтобы сделать эту независимость более полной, необходимо в первую очередь определить те аспекты языка, которые имеют одинаковую реализацию в разных трансляторах. Конечно, представление на этапе выполнения таких сложных типов, как С-структуры (structs), может быть выдержано инвариантным по отношению к трансляторам. Это — основное, что должен делать системный интерфейс, основанный на С, и иногда это достигается применением условно транслируемых определений типа прагм (pragmas) или других директив транслятора. Второе, что следует сделать, — это заставить все компиляторы проходить параметры функций в одном и том же порядке (слева направо, справа налево) и зачищать стек также одинаково. Подобно совместимости структур, это также решаемая задача, и для унификации работы со стеком часто используются условные директивы транслятора. В качестве примера можно привести макросы WINAPI/WINBASEAPI из Win32 API. Каждая извлеченная из системных DLL функция определена с помощью этих макросов:
WINBASEAPI void WINAPI Sleep(DWORD dwMsecs);
Каждый разработчик транслятора определяет эти символы препроцессора для создания гибких стековых фреймов.
Хотя в среде производителей может возникнуть желание использовать аналогичную методику для определений всех методов, фрагменты программ в этой главе для большей наглядности ее не используют.
Третье требование к независимости трансляторов — наиболее уязвимое для критики из всех, так как оно делает возможным определение двоичного интерфейса: все трансляторы C++ с заданной платформой одинаково осуществляют механизм вызова виртуальных функций. Действительно, это требование единообразия применимо только к классам, не имеющим элементов данных, а имеющим не более одного базового класса, который также не имеет элементов данных. Вот что означает это требование для следующего простого определения класса:
class calculator { public: virtual void add1(short x); virtual void add2(short x, short y); };
Все трансляторы с данной платформой должны создать эквивалентные последовательности машинного кода для следующего фрагмента программы пользователя:
extern calculator *pcalc; pcalc->add1(1); pcalc->add2(1, 2);
Отметим, что требуется не идентичность машинного кода на всех трансляторах, а его эквивалентность. Это означает, что каждый транслятор должен делать одинаковые допущения относительно того, как объект такого класса размещен в памяти и как его виртуальные функции динамически вызываются на этапе выполнения.
Впрочем, это не такое уж блестящее решение проблемы, как может показаться. Реализация виртуальных функций на C++ на этапе выполнения выливается в создание конструкций vptr и vtbl практически на всех трансляторах. При этой методике транслятор молча генерирует статический массив указателей функций для каждого класса, содержащего виртуальные функции. Этот массив называется vtbl (virtual function table — таблица виртуальных функций) и содержит один указатель функции для каждой виртуальной функции, определенной в данном классе или в ее базовом классе. Каждый объект класса содержит единственный невидимый элемент данных, именуемый vptr (virtual function pointer - указатель виртуальных функций); он автоматически инициализируется конструктором для указания на таблицу vtbl класса.
Когда клиент вызывает виртуальную функцию, транслятор генерирует код, чтобы разыменовать указатель vptr, занести его в vtbl и вызвать функцию через ее указатель, найденный в назначенном месте. Так на C++ обеспечивается полиморфизм и диспетчеризация динамических вызовов. Рисунок 1.5 показывает представление на этапе выполнения массивов vptr/vtbl для класса calculator, рассмотренного выше.

Фактически каждый действующий в настоящее время качественный транслятор C++ использует базовые концепции vprt и vtbl. Существует два основных способа размещения таблицы vtbl: с помощью CFRONT и корректирующего переходника (adjuster thunk). Каждый из этих приемов имеет свой способ обращения с тонкостями множественного наследования. К счастью, на каждой из имеющихся платформ доминирует один из способов (трансляторы Win32 используют adjuster thunk, Solaris — стиль CFRONT для vtbl). К тому же формат таблицы vtbl не влияет на исходный код C++, который пишет программист, а скорее является артефактом сгенерированного кода. Желающие узнать подробности об этих двух способах могут обратиться к прекрасной книге Стэна Липпмана "Объектная модель C++ изнутри" (Stan Lippman. Inside C++ Object Model).
Основываясь на столь далеко идущих допущениях, теперь можно решить проблему зависимости от транслятора. Предполагая, что все трансляторы на данной платформе одинаково реализуют механизм вызова виртуальной функции, можно определить класс интерфейса C++ так, чтобы глобальные операции над типами данных определялись в нем как виртуальные функции; тогда можно быть уверенным, что все трансляторы будут генерировать эквивалентный машинный код для вызова методов со стороны клиента. Это предположение об единообразии означает, что ни один класс интерфейса не имеет элементов данных и ни один класс интерфейса не может быть прямым потомком более чем одного класса интерфейса. Поскольку в классе интерфейса нет элементов данных, эти методы практически невозможно использовать.
Чтобы подчеркнуть это обстоятельство, полезно определить члены интерфейса как простые виртуальные функции, указав, что класс интерфейса задает только возможность вызова методов, а не их реализацию.
// ifaststring.h class IFastString { public: virtual int Length(void) const = 0; virtual int Find(const char *psz) const = 0; };
Определение этих методов как чисто виртуальных также дает знать транслятору, что от класса интерфейса не требуется никакой реализации этих методов. Когда транслятор генерирует таблицу vtbl для класса интерфейса, входная точка для каждой простой виртуальной функции является или нулевой (null), или точкой входа в С-процедуру этапа выполнения (_purecall в Microsoft C++), которая при вызове генерирует логическое утверждение. Если бы метод не был определен как чисто виртуальный, транслятор попытался бы включить в соответствующую входную точку vtbl системную реализацию метода класса интерфейса, которая в действительности не существует. Это вызвало бы ошибку компоновки. Определенный таким образом класс интерфейса является абстрактным базовым классом. Соответствующий класс реализации должен порождаться классом интерфейса и перекрывать все чисто виртуальные фyнкции содержательными реализациями. Эта наследственная связь проявится в объектах, которые в качестве своего представления имеют двоичное надмножество представления класса интерфейса (которое как раз и есть vptr/vtbl). Дело в том, что отношение "является" ("is-a") между порождаемым и базовым классами применяется на двоичном уровне в C++ так же, как и на уровне моделирования в объектно-ориентированной разработке:
class FastString : public IFastString { const int m_cch; // count of characters // число символов char *m_psz; public: FastString(const char *psz); ~FastString(void); int Length(void) const; // returns # of characters // возвращает число символов int Find(const char *psz) const; // returns offset // возвращает смещение };
Поскольку FastString порождается от IFastString, двоичное представление объектов FastString должно быть надмножеством двоичного представления IFastString. Это означает, что объекты FastString будут содержать указатель vptr, указывающий на совместимую с таблицей vtbl IFastString.
Поскольку классу FastString можно приписывать различные конкретные типы данных, его таблица vtbl будет содержать указатели на существующие реализации методов Length и Find. Их связь показана на рис. 1.6.
Даже несмотря на то, что открытые операторы над типами данных подняты до уровня чисто виртуальных функций в классе интерфейса, клиент не может приписывать значения объектам FastString, не имея определения класса для класса реализации. При демонстрации клиенту определения класса реализации от него будет скрыта двоичная инкапсуляция интерфейса; что не позволит клиенту использовать класс интерфейса. Одним из разумных способов обеспечить клиенту возможность использовать объекты FastString является экспорт из DLL глобальной функции, которая будет вызывать новый оператор от имени клиента. При условии, что эта подпрограмма экспортируется с опцией extern "С", она будет доступна для любого транслятора C++.

// ifaststring.h class IFastString { public: virtual int Length(void) const = 0; virtual int Find(const char *psz) const = 0; };
extern "C" IFastString *CreateFastString(const char *psz); // faststring.cpp (part of DLL) // faststring.cpp (часть DLL) IFastString *CreateFastString (const char *psz) { return new FastString(psz); }
Как было в случае класса-дескриптора, новый оператор вызывается исключительно внутри DLL FastString, а это означает, что размер и расположение объекта будут установлены с использованием того же транслятора, который транслировал все методы реализации.
Последнее препятствие, которое предстоит преодолеть, относится к уничтожению объекта. Следующая клиентская программа пройдет трансляцию, но результаты будут непредсказуемыми:
int f(void) { IFastString *pfs = CreateFastString("Deface me"); int n = pfs->Find("ace me"); delete pfs; return n; }
Непредсказуемое поведение вызвано тем фактом, что деструктор класса интерфейса не является виртуальным. Это означает, что вызов оператора delete не сможет динамически найти последний порожденный деструктор и рекурсивно уничтожит объект ближайшего внешнего типа по отношению к базовому типу.
Поскольку деструктор FastString никогда не вызывается, в данном примере из буфера исчезнет строка "Deface me", которая должна там присутствовать.
Очевидное решение этой проблемы — сделать деструктор виртуальным в классе интерфейса. К сожалению, это нарушит независимость класса интерфейса от транслятора, так как положение виртуального деструктора в таблице vtbl может изменяться от транслятора к транслятору. Одним из конструктивных решений этой проблемы является добавление к интерфейсу явного метода Delete как еще одной чисто виртуальной функции, чтобы заставить производный класс уничтожать самого себя в своей реализации этого метода. В результате этого будет выполнен нужный деструктор. Модифицированная версия заголовочного файла интерфейса выглядит так:
// ifaststring.h class IFastString { public: virtual void Delete(void) = 0; virtual int Length(void) const = 0; virtual int Find(const char *psz) const = 0; };
extern "C" IFastString *CreateFastString (const char *psz);
она влечет за собой соответствующее определение класса реализации:
// faststring.h #include "ifaststring.h" class FastString : public IFastString { const int m_cch; // count of characters // счетчик символов char *m_psz; public: FastString(const char *psz); ~FastString(void); void Delete(void); // deletes this instance // уничтожает этот экземпляр int Length(void) const; // returns # of characters // возвращает число символов int Find(const char *psz) const; // returns offset // возвращает смещение };
// faststring.cpp #include <string.h> #include "faststring.h"
IFastString* CreateFastString (const char *psz) { return new FastString(psz); }
FastString::FastString(const char *psz) : m_cch(strlen(psz)), m_psz(new char[m_cch + 1]) { strcpy(m_psz, psz); }
void FastString::Delete(void) { delete this; }
FastString::~FastString(void) { delete[] m_psz; }
int FastString::Lengtn(void) const { return m_cch; }
int FastString::Find(const char *psz) const { // O(1) lookup code deleted for clarity // код поиска 0(1) уничтожен для ясности }
Рисунок 1. 7 показывает представление FastString на этапе выполнения. Чтобы использовать тип данных FastString, клиентам надо просто включить в программу файл определения интерфейса и вызвать CreateFastString:
#include "ifaststring.h" int f(void) { int n = -1; IFastString *pfs = CreateFastString("Hi Bob!"); if (pfs) { n = pfs->Find("ob"); pfs->Delete(); } return n; }

Отметим, что все, кроме одной, точки входа в DLL FastString являются виртуальными функциями. Виртуальные функции класса интерфейса всегда вызываются косвенно, через указатель функции, хранящийся в таблице vtbl, избавляя клиента от необходимости указывать их символические имена на этапе разработки. Это означает, что методы интерфейса защищены от различий в коррекции символических имен на разных трансляторах. Единственная точка входа, которая явно компонуется по имени, — это CreateFastString — глобальная функция, которая обеспечивает клиенту доступ в мир FastString. Заметим, однако, что эта функция была экспортирована с опцией extern "С", которая подавляет коррекцию символов. Следовательно, все трансляторы C++ ожидают, что импортируемая библиотека и DLL экспортируют один и тот же идентификатор. Полезным результатом этой методики является то, что вы можете спокойно извлечь класс из DLL, использующей одну среду C++, а обратиться к этому классу из любой другой среды C++. Эта возможность необходима при построении основы для независимых от разработчика компонентов повторного пользования.
C++ и мобильность
Поскольку вы решили распространять классы C++ как DLL, вы непременно столкнетесь с одним из фундаментальных недостатков C++ — недостаточной стандартизацией на двоичном уровне. Хотя рабочий документ ISO/ANSI C++ Draft Working Paper (DWP) предпринимает попытку определить, какие программы будут транслироваться и каковы будут семантические эффекты при их запуске, двоичная динамическая модель C++ ею не стандартизируется. Впервые клиент сталкивается с этой проблемой при попытке скомпоновать библиотеку импорта DLL FastString из среды развития C++, отличной от той, в которой он привык строить эту DLL.
Для обеспечения перегрузки операторов и функций компиляторы C++ обычно видоизменяют символическое имя каждой точки входа, чтобы разрешить многократное использование одного и того же имени (или с различными типами аргументов, или в различных областях действия) без нарушения работы существующих компоновщиков для языка С. Этот прием часто называют коррекцией имени. Несмотря на то что ARM (C++ Annotated Reference Manual) документировала схему кодирования, использующуюся в CFRONT, многие разработчики трансляторов предпочли создать свою собственную схему коррекции. Поскольку библиотека импорта FastString и DLL экспортирует символы, используя корректирующую схему того транслятора, который создал DLL (то есть GNU C++), клиенты, скомпилированные другим транслятором (например, Borland C++), не могут быть корректно скомпонованы с библиотекой импорта. Классическая методика использования extern "С" для отключения коррекции символов не поможет в данном случае, так как DLL экспортирует функции-члены (методы), а не глобальные функции.
Для решения этой проблемы можно проделать фокусы с клиентским компоновщиком, применяя файл описания модуля (Module Definition File), известный как DEF-файл. Одно из свойств DEF-файлов заключается в том, что они позволяют экспортируемым символам совмещаться с различными импортируемыми символами. Имея достаточно времени и информации относительно каждой схемы коррекции, разработчик библиотек может создать особую библиотеку импорта для каждого компилятора.
Это утомительно, но зато позволяет любому компилятору обеспечить совместимость с DLL на уровне компоновки, при условии, что разработчик библиотеки заранее ожидал ее использование и создал нужный DEF-файл.
Если вы разрешили проблемы, возникшие при компоновке, вам еще придется столкнуться с более сложными проблемами несовместимости, которые связаны со сгенерированным кодом. За исключением простейших языковых конструкций, разработчики трансляторов часто предпочитают реализовывать особенности языка своими собственными путями. Это формирует объекты, недоступные для кода, созданного любым другим компилятором. Классическим примером таких языковых особенностей являются исключительные ситуации (исключения). Исключительная ситуация в среде C++, исходящая от функции, которая была транслирована компилятором Microsoft, не может быть надежно перехвачена клиентской программой, оттранслированной компилятором Watcom. Это происходит потому, что DWP не может определить, как должна выглядеть та или иная особенность языка на этапе выполнения, поэтому для каждого разработчика компилятора вполне естественно реализовать такую языковую особенность в своей собственной, новаторской манере. Это несущественно при построении независимой однобинарной (single-binary) исполняемой программы, так как весь код будет транслироваться и компоноваться в одной и той же среде. При построении мультибинарных (multibinary) исполняемых программ, основанных на компонентах (component-based), это представляет серьезную проблему, так как каждый компонент может, очевидно, быть построен с использованием другого компилятора и компоновщика. Отсутствие двоичного стандарта в C++ ограничивает возможности того, какие особенности языка могут быть использованы вне границ DLL. Это означает, что простой экспорт функций-членов C++ из DLL недостаточен для создания независимого от разработчика набора компонентов.
Динамическая компоновка и С++
Один из путей решения этих проблем — упаковка класса FastString в динамически подключаемую библиотеку (Dynamic Link Library — DLL). Это может быть сделано несколькими способами. Простейший из них — использовать директиву компилятора, действующую на уровне классов, чтобы заставить все методы FastString экспортироваться из DLL. Компилятор Microsoft C++ предусматривает для этого ключевое слово _declspec(dllexport):
class _declspec(dllexport) FastString { char *m_psz; public: FastString(const char *psz); ~FastString(void); int Length(void) const; // returns # of characters // возвращает число символов int Find(const char *psz) const; // returns offset // возвращает смещение };
В этом случае все методы FastString будут добавлены в список экспорта соответствующей библиотеки DLL, что позволит записать время выполнения каждого метода в его адрес в памяти. Кроме того, компоновщик создаст библиотеку импорта (import library), которая объявляет символы для методов FastString. Вместо того чтобы содержать сам код, библиотека импорта включает в себя ссылки на имя файла DLL и имена экспортируемых символов. Когда клиент обращается к библиотеке импорта, эти ссылки добавляются к исполняемой программе. Это побуждает загрузчик динамически загружать DLL FastString во время выполнения и размещать импортируемые символы в соответствующие ячейки памяти. Это размещение автоматически происходит в момент запуска клиентской программы операционной системой.
Рисунок 1.2 иллюстрирует модель FastString на этапе выполнения (runtime model), объявляемую из DLL. Заметим, что библиотека импорта достаточно мала (примерно вдвое больше, чем суммарный размер экспортируемого символьного текста). Когда класс экспортируется из DLL, код FastString должен присутствовать на жестком диске пользователя только один раз. Если даже несколько клиентов применяют этот код для своей библиотеки, загрузчик операционной системы обладает достаточным интеллектом, чтобы разделить физические страницы памяти, содержащие исполняемый код FastString (только для чтения), между всеми клиентскими программами. Кроме того, если разработчик библиотеки найдет дефект в исходном коде, теоретически возможно послать новую DLL конечному пользователю, исправляя дефектную реализацию для всех клиентских приложений сразу. Ясно, что перемещение библиотеки FastString в DLL является важным шагом на пути превращения класса C++ в заменяемый и эффективный компонент повторного использования.

Где мы находимся?
Мы начали эту главу с простого класса C++ и рассмотрели проблемы, связанные с объявлением этого класса как двоичного компонента повторного использования. Первым шагом было употребление этого класса в качестве библиотеки Dynamic Link Library (DLL) для отделения физической упаковки этого класса от упаковок его клиентов. Затем мы использовали понятие интерфейсов и реализации для инкапсуляции элементов реализации типов данных за двоичной защитой, что позволило изменять двоичные представления объектов без необходимости перетрансляции клиентами. Затем, используя для определения интерфейсов подход абстрактного базового класса, эта защита приобрела форму указателя vptr и таблицы vtbl. Далее мы исследовали приемы для динамического выбора различных полиморфных реализаций данного интерфейса на этапе выполнения с использованием LoadLibrary и GetProcAddress. Наконец, мы использовали RTTI-подобную структуру для динамического опроса объекта с целью определить, действительно ли он использует нужный интерфейс. Эта структура предоставила нам методику расширения существующих версий интерфейса, а также возможность выставления нескольких несвязанных интерфейсов из одного объекта.
Короче, мы только что создали модель компонентных объектов (Component Object Model - СОМ).
Инкапсуляция и С++
Предположим, что вам удалось преодолеть проблемы с транслятором и компоновщиком, описанные в предыдущем разделе. Очередное препятствие при построении двоичных компонентов на C++ появится, когда вы будете проводить инкапсуляцию (encapsulation), то есть формирование пакета. Посмотрим, что получится, если организация, использующая FastString в приложении, возьмется выполнить невыполнимое: закончит разработку и тестирование за два месяца до срока рассылки продукта. Пусть также в течение этих двух месяцев некоторые из наиболее скептически настроенных разработчиков решили протестировать O(1)-поисковый алгоритм FastString, запустив профайлер своего приложения. К их большому удивлению, FastString::Find стала бы на самом деле работать очень быстро, независимо от заданной длины строки. Однако с оператором Length дело обстоит не столь хорошо, так как FastString::Length использует подпрограмму strlen из динамической библиотеки С. Эта подпрограмма — алгоритм O(n)- осуществляет линейный поиск по строкам с использованием символа конца строки (null terminator); скорость его работы пропорциональна длине строки. Столкнувшись с тем, что клиентское приложение может многократно вызывать оператор Length, один из таких скептиков, скорее всего, свяжется с разработчиком библиотеки и попросит его убыстрить Length, чтобы его работа также не зависела от длины строки. Но здесь есть одно препятствие. Разработчик библиотеки уже закончил свою разработку и, скорее всего, не расположен менять одну строку исходного кода, чтобы воспользоваться преимуществами улучшенного метода Length. Кроме того, некоторые другие разработчики, возможно, уже выпустили свои продукты, основанные на текущей версии FastString, и теперь разработчик библиотеки не имеет морального права изменять эти приложення.
С этой точки зрения нужно просто вернуться к определению класса FastString и решить, что можно изменить и что необходимо сохранить, чтобы уже установленная база успешно функционировала. К счастью, класс FastString был разработан с учетом возможности инкапсуляции, и все его элементы данных (data members) являются закрытыми (private).
Это придает классу значительную гибкость, так как ни одна клиентская программа не может непосредственно получить доступ к элементам данных FastString. В силу того, что по отношению к четырем открытым (public) членам класса не было сделано никаких изменений, то и в любом клиентском приложении никаких изменений также не потребуется. Вооружившись этой верой, разработчик библиотеки переходит к реализации FastString версии 2.0.
Очевидным улучшением является следующее решение: в тексте конструктора (constructor) занести длину строки в кэш и возвращать кэшированную длину в новой версии метода Length. Так как строка не может быть изменена после создания, нет необходимости беспокоиться, что ее длина будет вычисляться многократно. В действительности длина уже однажды вычислена в конструкторе при назначении буфера, так что понадобится только горстка дополнительных машинных инструкций. Вот каким будет модифицированное определение класса:
// faststring.h version 2.0 class _declspec(dllexport) FastString { const int m_cch; // count of characters // число символов char m_psz; public: FastString(const char *psz); ~FastString(void); int Length(void) const; // returns # of characters // возвращает число символов int Find(const char *psz) const; // returns offset - возвращает смещение };
Отметим, что единственной модификацией является добавление закрытого элемента данных. Чтобы правильно инициализировать такой элемент, конструктор должен быть изменен следующим образом:
FastString::FastString(const char *psz) : m_cch(strlen(psz)), m_psz(new char[m_cch + 1]) { strcpy(m_psz, psz); }
С введением кэшированной длины метод Length становится тривиальным:
int FastString::Length(void) const { return m_cch; // return cached length // возвращает скрытую длину }
Сделав эти три модификации, разработчик библиотеки может теперь перестроить DLL FastString и сопутствующий ей набор тестов, которые полностью проверяют каждый аспект класса FastString. Разработчик будет приятно удивлен, узнав, что принцип инкапсуляции обошелся ему дешево, и в исходных текстах тестов не понадобилось делать никаких изменений.
После проверки того. что новая DLL работает правильно, разработчик библиотек отсылает FastString версии 2.0 клиенту, будучи уверенным, что вся работа завершена.
Когда клиенты, заказавшие изменения, получают модернизированный FastString, они включают новое определение класса и DLL в систему контроля своего исходного кода и запускают тестирование нового и улучшенного FastString. Подобно разработчику библиотеки, они тоже приятно удивлены: для того, чтобы воспользоваться преимуществами новой версии Length, не требуется никаких модификаций исходного кода. Вдохновленная этим опытом, команда разработчиков убеждает начальство включить новую DLL в окончательный "золотой" CD, уже готовый для выпуска. Это тот редкий случай, когда руководство идет навстречу энтузиастам-разработчикам и включает в окончательный продукт новую DLL. Подобно большинству программ инсталляции, описание установки клиентской программы настроено на молчаливое (без предупреждения) замещение всех старых версий FastString DLL, какие есть на машине конечного пользователя. Это выглядит вполне безобидно, поскольку эти изменения не затронули открытый интерфейс класса, так что тотальная молчаливая модернизация под версию 2.0 FastString только улучшит любые имеющиеся клиентские приложения, которые были установлены раньше.
Представим себе следующий сценарий: конечные пользователи наконец-то получают свои экземпляры вожделенного продукта. Каждый из них тут же бросает все и устанавливает новое приложение на свою машину, дабы попробовать его. После того как высохли слезы восторга от того, что наконец-то можно делать быстрый текстовый поиск, пользователь возвращается к его или ее нормальному состоянию и запускает ранее установленное приложение, которое также имеет неосторожность использовать DLL FastString. Первые несколько минут всё идет хорошо. Затем внезапно появляется сообщение, что возникла исключительная ситуация и что вся работа конечного пользователя пропала. Он пытается запустить приложение снова, но на этот раз диалоговое окно об исключительной ситуации появляется почти сразу.
Конечный пользователь, привычный к употреблению современного программного обеспечения, переустанавливает операционную систему и все приложения, но даже это не спасает от повторения исключительной ситуации. Что же произошло?

А произошло то, что разработчик библиотеки был убаюкан верой в то, что C++ поддерживает инкапсуляцию. Хотя C++ и поддерживает синтаксическую инкапсуляцию через свои закрытые и защищенные ключевые слова, в стандарте C++ ничего не сказано о двоичной инкапсуляции. Это происходит потому, что модель трансляции C++ требует, чтобы клиентский компилятор имел доступ ко всей информации относительно двоичного представления объектов, — с целью обработать экземпляр класса или делать невиртуальные вызовы метода. Это включает в себя информацию о размере и порядке закрытых и защищенных элементов данных объекта. Рассмотрим сценарий, показанный на рис. 1.3. Версия 1.0 FastString требует четыре байта на экземпляр (принимая sizeof(char *) == 4). Клиенты написанного под версию 1.0 определения класса выделяют четыре байта памяти под вызов конструктора класса. Конструктор, деструктор и методы версии 2.0 (а именно эти версии содержатся в DLL в машине конечного пользователя) ожидают, что клиент выделил восемь байт на экземпляр (принято sizeof(int) == 8), и не предусматривают собственных резервов для записи во все восемь байт. К сожалению, у клиентов с версией 1.0 вторые четыре байта этого объекта на самом деле принадлежат кому-то другому, и запись в это место указателя на текстовую строку недопустима, о чем и сообщает диалог исключительной ситуации.
Существует общее решение проблемы версий — переименовывать DLL всякий раз, когда появляется новая версия. Такая стратегия принята в Microsoft Foundation Classes (MFC). Когда номер версии включен в имя файла DLL (например, FastString10.DLL, FastString20.DLL), клиенты всегда загружают ту версию DLL, с которой они были сконфигурированы, независимо от присутствия в системе других версий. К сожалению, со временем, из-за недостаточного опыта в системном конфигурировании, число версий DLL, имеющихся в системе конечного пользователя, может превысить реальное число пользовательских приложений.Чтобы убедиться в этом, достаточно проверить системный каталог любого компьютера, проработавшего больше шести месяцев.
В конечном счете, проблема управления версиями коренится в модели трансляции C++, не рассчитанной на поддержку независимых двоичных компонентов. Требуя знания клиентом двоичного представления объектов, C++ предполагает тесную двоичную связь между клиентом и исполняемыми программами объекта. Обычно такая связь является преимуществом C++, так как она позволяет трансляторам генерировать весьма эффективный код. К сожалению, эта тесная двоичная связь не позволяет переместить реализации класса без проведения клиентом повторной компиляции. По причине этой связи и несовместимости транслятора и компоновщика, упомянутых в предыдущем разделе, простой экспорт определений класса C++ из DLL не обеспечивает приемлемой архитектуры двоичных компонентов.
Отделение интерфейса от реализации
Концепция инкапсуляции основана на разделении того, как объект выглядит (его интерфейса), и того, как он в действительности работает (его реализации). Проблема в C++ в том, что этот принцип неприменим на двоичном уровне, так как класс C++ одновременно является и интерфейсом, и реализацией. Этот недостаток может быть преодолен, если смоделировать две новые абстракции, являющиеся классами C++, но различающиеся по своей сущности. Если определить один класс C++ как интерфейс для типа данных, а второй — как саму реализацию типа данных, то конструктор объектов теоретически может модифицировать некоторые детали класса реализации, в то время как класс интерфейса останется неизменным. Все, что нужно, — это выдержать соотношение интерфейса с его реализацией так, чтобы не показывать клиенту никаких деталей реализации.
Класс интерфейса должен содержать только такое описание основных типов данных, какое должен, по мнению разработчика, представлять себе клиент. Поскольку интерфейс не должен сообщать ни о каких деталях реализации, класс интерфейса C++ не может содержать никаких элементов данных, которые могут быть использованы в реализации объекта. Вместо этого класс интерфейса должен содержать только описания методов для каждой открытой операции объекта. Класс реализации C++ будет содержать фактические элементы данных, необходимые для обеспечения функционирования объекта. Одним из простейших подходов является использование класса-дескриптора (handle-class) в качестве интерфейса. Класс-дескриптор мог бы просто содержать непрозрачный (opaque) указатель, чей тип никогда не может быть полностью определен клиентом. Следующее определение класса демонстрирует эту технику:
// FastStringItf.h class _declspec(dllexport) FastStringItf { class FastString; // introduce name of impl. class // вводится имя класса реализации FastString *m_pThis; // opaque pointer (size remains constant) // непрозрачный указатель (размер остается постоянным) public : FastStringItf(const char *psz); ~FastStringItf(void); int Length(void) const; // returns # of characters // возвращает число символов int Find(const char *psz) const; // returns offset // возвращает смещение };
Заметим, что двоичное представление этого класса интерфейса не меняется с добавлением или удалением элементов данных из класса реализации FastString. Кроме того, использование опережающего объявления означает, что определение класса FastString не является необходимым для трансляции этого заголовочного файла. Это эффективно скрывает все детали реализации FastString от транслятора клиента. При использовании этого способа машинный код для методов интерфейса становится единственной точкой входа в DLL объекта, и их двоичные сигнатуры никогда не изменятся. Реализации методов класса интерфейса просто передают вызовы методов действующему классу реализации:
// faststringitf.срр // (part of DLL, not client) // (часть DLL, а не клиента) #include "faststring.h" #include "faststringitf.h" FastStringItf::FastStringItf(const char *psz) : m_pThis(new FastString(psz)) { assert(m_pThis != 0); } FastStringItf::~FastStringItf(vo1d) { delete m_pThis; } int FastStringItf::Length(void) const { return m_pThis->Length(); } int FastStringItf::Find(const char *psz) const { return m_pThis->Find(psz); }
Эти передающие методы должны быть транслированы как часть DLL FastString, так что когда двоичное представление класса реализации FastString меняется, вызов нового оператора в конструкторе FastStringItf будет сразу же перекомпилирован, если, конечно, зарезервировано достаточно памяти. И опять клиент не получит описания класса реализации FastString. Это дает разработчику FastString возможность со временем развивать реализацию без прерывания существующих клиентов.

Рисунок 1.4 показывает, как использовать классы-дескрипторы для отделения интерфейса от реализации на этапе выполнения. Заметим, что косвенный подход, введенный классом интерфейса, устанавливает двоичную защитную стену (firewall — брандмауэр) между клиентом и реализацией объекта. Эта двоичная стена очень точно описывает, как клиент может сообщаться с реализацией. Все связи клиент-объект осуществляются через класс интерфейса, который содержит очень простой двоичный протокол для входа в область реализации объекта.
Этот протокол не содержит никаких деталей класса реализации в C++.
Хотя методика использования классов-дескрипторов имеет свои преимущества и безусловно приближает нас к возможности безопасного извлечения классов из DLL, она также имеет свои недостатки. Отметим, что класс интерфейса вынужден явно передавать каждый вызов метода классу реализации. Для простого класса вроде FastString только с двумя открытыми операторами, конструктором и деструктором, это не проблема. Для большой библиотеки классов с сотнями или тысячами методов написание этих передающих процедур было бы весьма утомительным и явилось бы потенциальным источником ошибок. Кроме того, для областей с повышенными требованиями к эффективности программ (performance-critical domains), цена двух вызовов для каждого метода (один вызов на интерфейс, один вложенный вызов на реализацию) весьма высока. Наконец, методика классов-дескрипторов не полностью решает проблемы совместимости транслятора/компоновщика, а они все же должны быть решены, если мы хотим иметь основу, действительно пригодную для создания компонентов повторного использования.
Полиморфизм на этапе выполнения
Управление реализациями классов с использованием абстрактных базовых классов как интерфейсов открывает целый мир новых возможностей в терминах того, что может случиться на этапе выполнения. Напомним, что DLL FastString экспортирует только один идентификатор — CreateFastString. Теперь пользователю легко динамически загрузить DLL, используя по требованию LoadLibrary, и разрешить этой единственной точке входа использовать GetProcAddress:
IFastString *CallCreateFastString(const char *psz) { static IFastString * (*pfn)(const char *) = 0; if (!pfn) { // init ptr 1st time through // первое появление ptr const TCHAR szDll[] = _TEXT("FastString.DLL"); const char szFn[] = "CreateFastString"; HINSTANCE h = LoadLibrary(szDll); if (h) *(FARPROC*)&pfn = GetProcAddress(h, szFn); } return pfn ? pfn(psz) : 0; }
Эта методика имеет несколько возможных приложений. Одна из причин ее использования — предотвращение ошибок, генерируемых операционной системой при работе на машине, где не установлена реализация объектов. Приложения, использующие дополнительные системные компоненты, такие как WinSock или MAPI, используют похожую технику для запуска приложений на машинах с минимальной конфигурацией. Поскольку клиенту никогда не нужно компоновать импортируемую библиотеку DLL, он не зависит от загрузки DLL и может работать на машинах, на которых DLL вообще не установлена. Другой причиной для использования этой методики может быть медленная инициализация адресного пространства. Кроме того, DLL не загружается автоматически во время инициализации; и если в действительности реализация объекта не используется, то DLL не загрузится никогда. Другими преимуществами этого способа являются ускорение запуска клиента и сохранение адресного пространства для длительных процессов, которые могут никогда реально не использовать DLL.
Возможно, одним из наиболее интересных применений этой методики является возможность для клиента динамически выбирать между различными реализациями одного и того же интерфейса.
Если описание интерфейса IFastString дано как общедоступное (publicly available), то ничто не препятствует как исходному конструктору (implementor) FastString, так и любым сторонним средствам реализации порождать дополнительные классы реализации от того же самого интерфейса. Подобно исходной реализации класса FastString, эти новые реализации будут иметь такое двоичное представление, что будут совместимы на двоичном уровне с исходным классом интерфейса. Все, что должен сделать пользователь, чтобы добиться полностью совместимых ("plug-compatible") реализаций, — это определить правильное имя файла для желаемой реализации DLL.
Чтобы понять, как применить эту методику, предположим, что исходная реализация IFastString выполняла поиск слева направо. Это прекрасно для языков, анализируемых слева направо (например, английский, французский, немецкий). Для языков, анализируемых справа налево, предпочтительней вторая реализация IFastString, осуществляющая поиск справа налево. Эта альтернативная реализация может быть построена как вторая DLL с характерным именем (например, FastStringRL.DLL). Пусть обе DLL установлены на машине конечного пользователя, тогда он может выбрать нужный вариант IFastString простой загрузкой требуемой DLL на этапе выполнения:
IFastString * CallCreateFastString(const char *psz, bool bLeftToRight = true) { static IFastString * (*pfnlr)(const char *) = 0; static IFastString * (*pfnrl)(const char *) = 0; IFastString *(**ppfn) (const char *) = &pfnlr; const TCHAR *pszDll = _TEXT("FastString.DLL"); if (!bLeftToRight) { pszDll = _TEXT("FastStringRL.DLL"); ppfn = &pfnrl; } if (!(*ppfn)) { // init ptr 1st time through // первое появление ptr const char szFn[] = "CreateFastString"; HINSTANCE h = LoadLibrary(pszDll); if (h) *(FARPROC*)ppfn = GetProcAddress(h, szFn); } return (*ppfn) ? (*ppfn)(psz) : 0; }
Когда клиент вызывает функцию без второго параметра,
pfs = CallCreateFastString("Hi Bob!"); n = pfs->Find("ob");
то загружается исходная DLL FastString, и поиск идет слева направо. Если же клиент указывает, что строка написана на разговорном языке, анализируемом справа налево:
pfs = CallCreateFastString("Hi Bob!", false); n = pfs->Find("ob");
то загружается альтернативная версия DLL (FastStringRL.DLL), и поиск будет начинаться с крайней правой позиции строки. Главное здесь то, что вызывающие операторы CallCreateFastString не заботятся о том, какая из DLL используется для реализации методов объекта. Существенно лишь то, что указатель на совместимый с IFastString vptr возвращается функцией и что vptr обеспечивает успешное и семантически корректное функционирование. Эта форма полиморфизма на этапе выполнения чрезвычайно полезна при создании системы, динамически скомпонованной из двоичных компонентов.
Распространение программного обеспечения и язык С++
Для понимания проблем, связанных с использованием C++ как набора компонентов, полезно проследить, как распространялись библиотеки C++ в конце 1980-х годов. Представим себе разработчика библиотек, который создал алгоритм поиска подстрок за время O(1) (то есть время поиска постоянно, а не пропорционально длине строки). Это, как известно, нетривиальная задача. Для того чтобы сделать алгоритм возможно более простым для пользователя, разработчик должен создать класс строк, основанный на алгоритме, который будет быстро передавать текстовые строки (fast text strings) в любую программу клиента. Чтобы сделать это, разработчику необходимо подготовить заголовочный файл, содержащий определение класса:
// faststring.h class FastString { char *m_psz; public: FastString(const char *psz); ~FastString(void); int Length(void) const; // returns # of characters // возвращает число символов int Find(const char *psz) const; // returns offset //возвращает смещение };
После того как класс определен, разработчик должен реализовать его функции-члены в отдельном файле:
// FastString.cpp #include "faststring.h" #include <string.h>
FastString::FastString(const char *psz) : m_psz(new char [strlen(psz) + 1]) { strcpy(m_psz, psz); }
FastString::~FastString(void) { delete[] m_psz; }
int FastString::Length(void) const { return strlen(m_psz); }
int FastString::Find(const char *psz) const { //O(1) lookup code deleted for> clarity // код поиска 0(1) удален для ясности }
Библиотеки C++ традиционно распространялись в форме исходного кода. Ожидалось, что пользователи библиотеки будут добавлять реализации исходных файлов и создаваемую ими систему и перекомпилировать библиотечные исходные файлы на месте, с использованием своего компилятора C++. Если предположить, что библиотека написана на наиболее употребительной версии языка C++, то такой подход был бы вполне работоспособным. Подводным камнем этой схемы было то, что исполняемый код этой библиотеки должен был включаться во все клиентские приложения.
Предположим, что для показанного выше класса FastString сгенерированный машинный код для четырех методов занял 16 Мбайт пространства в результирующем исполняемом файле. Напомним, что при выполнении O(1)-поиска может потребоваться много пространства для кода, чтобы обеспечить заданное время исполнения, - дилемма, которая ограничивает большинство алгоритмов. Как показано на рис. 1.1, если три приложения используют библиотеку FastString, то каждая из трех исполняемых программ будет включать в себя по 16 Мбайт кода. Это означает, что если конечный пользователь инсталлирует все три клиентских приложения, то реализация FastString займет 48 Мбайт дискового пространства. Хуже того — если конечный пользователь запустит все три клиентских приложения одновременно, то код FastString займет 48 Мбайт виртуальной памяти, так как операционная система не может обнаружить дублирующий код, имеющийся в каждой исполняемой программе.

Есть еще одна проблема в таком сценарии: когда разработчик библиотеки находит дефект в классе FastString, нет способа всюду заменить его реализацию. После того как код FastString скомпонован с клиентским приложением, невозможно исправить машинный код FastString непосредственно в компьютере конечного пользователя. Вместо этого разработчик библиотеки должен известить разработчиков каждого клиентского приложения об изменениях в исходном коде и надеяться, что они переделают свои приложения, чтобы получить эффект от этих исправлений. Ясно, что модульность компонента FastString утрачивается, как только клиент запускает компоновщик и заново формирует исполняемый файл.
1
В момент написания этого текста автор не имел работающей версии этого алгоритма, годной для публикации. Детали такой реализации оставлены как упражнение для читателя.
Расширяемость объекта
Описанные до сих пор методики позволяют клиентам выбирать и динамически загружать двоичные компоненты, что дает возможность изменять с течением времени двоичное представление их реализации без необходимости повторной трансляции клиента. Это само по себе чрезвычайно полезно при построении динамически компонуемых систем. Существует, однако, один аспект объекта, который не может изменяться во времени, — это его интерфейс. Это связано с тем, что пользователь осуществляет трансляцию с определенной сигнатурой класса интерфейса, и любые изменения в описании интерфейса требуют повторной трансляции клиента для учета этих изменений. Хуже того, изменение описания интерфейса полностью нарушает инкапсуляцию объекта (так как его открытый интерфейс изменился) и может испортить программы всех существующих клиентов. Даже самое безобидное изменение, такое как изменение семантики метода с сохранением его сигнатуры, делает бесполезной всю установленную клиентскую базу. Это означает, что интерфейсы являются постоянными двоичными и семантическими контрактами (contracts), которые никогда не должны изменяться. Эта неизменяемость требует стабильной и предсказуемой среды на этапе выполнения.
Несмотря на неизменяемость интерфейсов, часто возникает необходимость добавить дополнительные функциональные возможности, которые не могли быть предусмотрены в период первоначального составления интерфейса. Хотелось бы, например, использовать знание двоичного представления таблицы vtbl и просто добавлять новые методы в конец существующего описания интерфейса. Рассмотрим исходную версию IFastString:
class IFastString { public: virtual void Delete(void) = 0; virtual int Length(void) = 0; virtual int Find(const char *psz) = 0; };
Простое изменение класса интерфейса путем объявлений добавочных виртуальных функций после объявлений существующих методов имело бы следствием двоичный формат таблицы vtbl, который является надмножеством исходной версии по мере того, как появятся какие-либо новые элементы vtbl после тех, которые соответствуют исходным методам.
У реализации объектов, которые транслируются с новым описанием интерфейса, все новые методы будут добавляться
к исходному размещению vtbl:
class IFastString { public: // faux version 1.0 // фиктивная версия 1.0 virtual void Delete(void) = 0; virtual int Length(void) = 0; virtual int Find(const char *psz) = 0; // faux version 2.0 // фиктивная версия 2.0 virtual int FindN(const char *psz, int n) = 0; };
Это решение почти работает. Те клиенты, у которых оттранслирована исходная версия интерфейса, остаются в счастливом неведении относительно всех составляющих таблицы vtbl, кроме первых трех. Когда старые клиенты получают обновленные объекты, имеющие в vtbl вход для FindN, они продолжают нормально работать. Проблема возникает, когда новым клиентам, ожидающим, что IFastString имеет четыре метода, случится столкнуться с устаревшими объектами, где метод FindN не реализуется. Когда клиент вызовет FindN на объект, странслированный с исходным описанием интерфейса, результаты будут вполне определенными. Программа прервет работу.
В этой методике проблема заключается в том, что она нарушает инкапсуляцию объекта, изменяя открытый интерфейс. Подобно тому, как изменение открытого интерфейса в классе C++ может вызвать ошибки на этапе трансляции, когда происходит перестройка клиентского кода, так и изменение двоичного описания интерфейса вызовет ошибки на этапе выполнения, когда клиентская программа перезапущена. Это означает, что интерфейсы должны быть неизменяемыми с момента первой редакции. Решение этой проблемы заключается в том, чтобы разрешить классу реализации выставлять более чем один интерфейс. Этого можно достигнуть, если предусмотреть, что один интерфейс порождается от другого, связанного с ним интерфейса. А можно сделать так, чтобы класс реализации наследовал от нескольких несвязанных классов интерфейса. В любом случае клиент мог бы использовать имеющуюся в C++ возможность определения типа на этапе выполнения — идентификацию Runtime Type Identification — RTTI, чтобы динамически опросить объект и убедиться в том, что его требуемая функциональность действительно поддерживается уже работающим объектом.
Рассмотрим простой случай интерфейса, расширяющего другой интерфейс. Чтобы добавить в IFastString операцию FindN, позволяющую находить n-е вхождение подстроки, необходимо породить второй интерфейс от IFastString и добавить в него новое описание метода:
class IFastString2 : public IFastString { public: // real version 2.0 // настоящая версия 2.0 virtual int FindN(const char *psz, int n) = 0; };
Клиенты могут с уверенностью динамически опрашивать объект с помощью оператора C++ dynamic_cast, чтобы определить, является ли он совместимым с IFastString2
int Find10thBob(IFastString *pfs) { IFastString2 *pfs2 = dynamic_cast<IFastString2*>(pfs); if(pfs2) // the object derives from IFastString2 // объект порожден от IFastString2 return pfs2->FindN("Bob", 10); else { // object doesn't derive from IFastString2 // объект не порожден от IFastString2 error("Cannot find 10th occurrence of Bob"); return -1; }
Если объект порожден от расширенного интерфейса, то оператор dynamic_cast возвращает указатель на вариант объекта, совместимый с IFastString2, и клиент может вызвать расширенный метод объекта. Если же объект не порожден от расширенного интерфейса, то оператор dynamic_cast возвратит пустой (null) указатель. В этом случае клиент может или выбрать другой способ реализации, зарегистрировав сообщение об ошибке, или молча продолжить без расширенной операции. Эта способность назначенного клиентом постепенного сокращения возможностей очень важна при создании гибких динамических систем, которые могут обеспечить со временем расширенные функциональные возможности.
Иногда требуется раскрыть еще один аспект функциональности объекта, тогда разворачивается еще более интересный сценарий. Обсудим, что следует предпринять, чтобы добавить постоянства, или персистентности (persistence), классу реализации IFastString. Хотя, вероятно, можно добавить методы Load и Save к расширенной версии IFastString, другие типы объектов, не совместимые с IFastString, могут тоже быть постоянными.
Простое создание нового интерфейса, который расширяет IFastString:
class IPersistentObject : public IFastString { public: virtual bool Load(const char *pszFileName) = 0; virtual bool Save(const char *pszFileName) = 0; };
требует, чтобы все постоянные объекты поддерживали также операции Length и Find. Для некоторого, весьма малого подмножества объектов это могло бы иметь смысл. Однако для того, чтобы сделать интерфейс IPersistentObject возможно более общим, он должен быть своим собственным интерфейсом, а не порождаться от IFastString:
class IPersistentObject { public: virtual void Delete(void) = 0; virtual bool Load(const char *pszFileName) = 0; virtual bool Save(const char *pszFileName) = 0; };
Это не мешает реализации FastString стать постоянной; это просто означает, что постоянная версия FastString должна поддерживать оба интерфейса: и IFastString, и IPersistentObject:
class FastString : public IFastString, public IPersistentObject { int m_cch; // count of characters // счетчик символов char *m_psz; public: FastString(const char *psz); ~FastString(void); // Common methods // Общие методы void Delete(void); // deletes this instance // уничтожает этот экземпляр // IFastString methods // методы IFastString int Length(void) const; // returns # of characters // возвращает число символов int Find(const char *psz) const; // returns offset // возвращает смещение
// IPersistentObject methods // методы IPersistentObject
bool Load(const char *pszFileName); bool Save(const char *pszFileName); };
Чтобы записать FastString на диск, пользователю достаточно с помощью RTTI связать указатель с интерфейсом IPerststentObject, который выставляется объектом:
bool SaveString(IFastString *pfs, const char *pszFN) { bool bResult = false; IPersistentObject *ppo = dynamic_cast<IPersistentObject*>(pfs); if (ppo) bResult = ppo->Save(pszFN); return bResult; }
Эта методика работает, поскольку транслятор имеет достаточно информации о представлении и иерархии типов класса реализации, чтобы динамически проверить объект для выяснения того, действительно ли он порожден от IPersistentObject.
Но здесь есть одна проблема.
RTTI - особенность, сильно зависящая от транслятора. В свою очередь, DWP передает синтаксис и семантику RTTI, но каждая реализация RTTI разработчиком транслятора уникальна и запатентована. Это обстоятельство серьезно подрывает независимость от транслятора, которая была достигнута путем использования абстрактных базовых классов как интерфейсов. Это является неприемлемым для архитектуры компонентов, не зависимой от разработчиков. Удачным решением было бы упорядочение семантики dynamic_cast без использования свойств языка, зависящих от транслятора. Явное выставление хорошо известного метода из каждого интерфейса, представляющего семантический эквивалент dynamic_cast, позволяет достичь желаемого эффекта, не требуя, чтобы все объекты использовали тот же самый транслятор C++:
class IPersistentObject { public: virtual void *Dynamic_Cast(const char *pszType) = 0; virtual void Delete(void) = 0; virtual bool Load(const char *pszFileName) = 0; virtual bool Save(const char *pszFileName) = 0; };
class IFastString { public: virtual void *Dynamic_Cast(const char *pszType) = 0; virtual void Delete(void) = 0; virtual int Length(void) = 0; virtual int Find(const char *psz) = 0; };
Так как всем интерфейсам необходимо выставить этот метод вдобавок к уже имеющемуся методу Delete, имеет большой смысл включить общее подмножество методов в базовый интерфейс, из которого могли бы порождаться все последующие интерфейсы:
class IExtensibleObject { public: virtual void *Dynamic_Cast(const char* pszType) = 0; virtual void Delete(void) = 0; };
class IPersistentObject : public IExtensibleObject { public: virtual bool Load(const char *pszFileName) = 0; virtual bool Save(const char *pszFileName) = 0; };
class IFastString : public IExtensibleObject { public: virtual int Length(void) = 0; virtual int Find(const char *psz) = 0; };
Имея такую иерархию типов, пользователь может динамически запросить объект о данном интерфейсе с помощью следующей не зависящей от транслятора конструкции:
bool SaveString(IFastString *pfs, const char *pszFN) { boot bResult = false; IPersistentObject *ppo = (IPersistentObject) pfs->Dynamic_Cast("IPers1stentObject"); if (ppo) bResult = ppo->Save(pszFN); return bResult; }
В только что приведенном примере клиентского использования присутствуют требуемая семантика и механизм для определения типа, но каждый класс реализации должен выполнять это функциональное назначение самолично:
class FastString : public IFastString, public IPersistentObject { int m_cсh; // count of characters // счетчик символов char *m_psz; public: FastString(const char *psz); ~FastString(void);
// IExtensibleObject methods // методы IExtensibleObject void *Dynamic_Cast(const char *pszType); void Delete(void); // deletes this instance // удаляет этот экземпляр
// IFastString methods // методы IFastString int Length(void) const; // returns # of characters // возвращает число символов int Find(const char *psz) const; // returns offset // возвращает смещение
// IPersistentObject methods // методы IPersistentObject bool Load(const char *pszFileName); bool Save(const char *pszFileName); };
Реализации Dynamic_Cast необходимо имитировать действия RTTI путем управления иерархией типов объекта. Рисунок 1.8 иллюстрирует иерархию типов для только что показанного класса FastString. Поскольку класс реализации порождается из каждого интерфейса, который он выставляет, реализация Dynamic_Cast в FastString может просто использовать явные статические приведения типа (explicit static casts), чтобы ограничить область действия указателя this, основанного на подтипе, который запрашивается клиентом:
void *FastString::Dynam1c_Cast(const char *pszType) { if (strcmp(pszType, "IFastString") == 0) return static_cast<IFastString*>(this); else if (strcmp(pszType, "IPersistentObject") == 0) return static_cast<IPersistentObject*>(this); else if (strcmp(pszType, "IExtensibleObject") == 0) return static_cast<IFastString*>(this); else return 0; // request for unsupported interface // запрос на неподдерживаемый интерфейс }

Так как объект порождается от типа, используемого в этом преобразовании, оттранслированные версии операторов преобразования просто добавляют определенное смещение к указателю объекта this, чтобы найти начало представления базового класса.
Отметим, что после запроса на общий базовый интерфейс IExtensibleObject реализация статически преобразуется в IFastString. Это происходит потому, что интуитивная версия (intuitive version) оператора
return static_cast<IExtensibleObject*>(this);
неоднозначна, так как и IFastString, и IPersistentObject порождены от IExtensibleObject. Если бы IExtensibleObject был виртуальным базовым классом как для IFastString, так и для IPersistentObject, то данное преобразование не было бы неоднозначным и оператор бы оттранслировался. Тем не менее, применение виртуальных базовых классов добавляет на этапе выполнения ненужную сложность в результирующий объект и к тому же вносит зависимость от транслятора. Дело в том, что виртуальные базовые классы являются всего лишь особенностями языка C++, которые имеют несколько специфических реализации.
СОМ как улучшенный C++
template <class Т, class Ex> class list_t : virtual protected CPrivateAlloc { list<T**> m_list; mutable TWnd m_wnd; virtual ~list_t(void); protected: explicit list_t(int nElems, ...); inline operator unsigned int *(void) const { return reinterpret_cast <int*>(this) ; } template <class X> void clear(X& rx) const throw(Ex); };
Аноним, 1996
C++ уже давно с нами. Сообщество программистов на C++ весьма обширно, и большинство из них хорошо знают о западнях и подводных камнях языка. Язык C++ был создан высоко квалифицированной командой разработчиков, которые, работая в Bell Laboratories, выпустили не только первый программный продукт C++ (CFRONT), но и опубликовали много конструктивных работ о C++. Большинство правил языка C++ было опубликовано в конце 1980-х и начале 1990-х годов. В этот период многие разработчики C++ (включая авторов практически каждой значительной книги по C++) работали на рабочих станциях UNIX и создавали довольно монолитные приложения, использующие технологию компиляции и компоновки того времени. Ясно, что среда, в которой работало это поколение программистов, была в основном создана умами всего сообщества C++.
Одной из главных целей языка C++ являлось позволить программистам строить типы, определенные пользователем (user-defined types — UDTs), которые затем можно было бы использовать вне их исходного контекста. Этот принцип лег в основу идеи создания библиотек классов, или структур, какими мы знаем их сегодня. С момента появления C++ рынок библиотек классов C++ расширялся, хотя и довольно медленно. Одной из причин того. что этот рынок рос не так быстро, как можно было ожидать, был NIH-фактор (not invented here — «изобретен не здесь») среди разработчиков C++. Использовать код других разработчиков часто представляется более трудным, чем воспроизведение собственных наработок. Иногда это представление базируется исключительно на высокомерии разработчика. В других случаях сопротивление использованию чужого кода проистекает из неизбежности дополнительного умственного усилия, необходимого для понимания чужой идеологии и стиля программирования.
Это особенно верно для библиотек-оберток (wrappers), когда необходимо понять не только технологию того, что упаковано, но и дополнительные абстракции, добавленные самой библиотекой.
Другая проблема: многие библиотеки составлены с расчетом на то, что пользователь будет обращаться к исходному коду данной библиотеки как к эталону. Такое повторное использование «белого ящика» часто приводит к огромному количеству связей между программой клиента и библиотекой классов, что с течением времени усиливает неустойчивость всей программы. Эффект чрезмерной связи ослабляет модульный принцип библиотеки классов и усложняет адаптацию к изменениям в реализации основной библиотеки. Это побуждает пользователей относиться к библиотеке как всего лишь к одной из частей исходного кода проекта, а не как к модулю повторного использования. Действительно, разработчики фактически подгоняют коммерческие библиотеки классов под собственные нужды, выпуская «собственную версию», которая лучше приспособлена к данному программному продукту, но уже не является оригинальной библиотекой.
Повторное использование (reuse) кода всегда было одной из классических мотиваций объектного ориентирования. Несмотря на это обстоятельство, написание классов C++, простых для повторного использования, довольно затруднительно. Помимо таких препятствий для повторного использования, как этап проектирования (design-time) и этап разработки (development-time), которые уже можно считать частью культуры C++, существует и довольно большое число препятствий на этапе выполнения (runtime), что делает объектную модель C++ далекой от идеала для создания программных продуктов повторного использования. Многие из этих препятствий обусловлены моделями компиляции и компоновки, принятой в C++. Данная глава будет посвящена техническим проблемам приведения классов C++ к виду компонентов повторного использования. Все задачи будут решаться методами программирования, которые базируются на готовых общедоступных (off-the-shelf) технологиях. В этой главе будет показано, как, применяя эти технологии, можно создать архитектуру для повторного использования модулей, которая позволяла бы динамично и эффективно строить системы из независимо сконструированных двоичных компонентов.
Управление ресурсами
Еще одна проблема поддержки нескольких интерфейсов из одного объекта становится яснее, если исследовать схему использования клиентом метода Dynamic_Cast. Рассмотрим следующую клиентскую программу:
void f(void) { IFastString *pfs = 0; IPersistentObject *ppo = 0;
pfs = CreateFastString("Feed BOB"); if (pfs) { ppo = (IPersistentObject *) pfs->Dynamic_Cast("IPersistentObject"); if (!ppo) pfs->Delete(); else { ppo->Save("C:\\autoexec.bat"); ppo->Delete(); } } }
Хотя вначале объект был связан через свой интерфейс IFastString, клиентский код вызывает метод Delete через интерфейс IPersistentObject. С использованием свойства C++ о множественном наследовании это вполне допустимо, так как все таблицы vtbl, порожденные классом IExtensibleObject, укажут на единственную реализацию метода Delete. Теперь, однако, пользователь должен хранить информацию о том, какие указатели связаны с какими объектами, и вызывать Delete только один раз на объект. В случае простого кода, приведенного выше, это не слишком тяжелое бремя. Для более сложных клиентских кодов управление этими связями становится делом весьма сложным и чреватым ошибками. Одним из способов упрощения задачи пользователя является возложение ответственности за управление жизненным циклом объекта на реализацию. Кроме того, разрешение клиенту явно удалять объект вскрывает еще одну деталь реализации: тот факт, что объект находится в динамически распределяемой памяти (в "куче", on the heap).
Простейшее решение этой проблемы — ввести в каждый объект счетчик ссылок, который увеличивается, когда указатель интерфейса дублируется, и уменьшается, когда указатель интерфейса уничтожается. Это предполагает изменение определения IExtensibleObject с
class IExtensibleObject { public: virtual void *Dynamic_Cast (const char* pszType) =0; virtual void Delete(void) = 0; };
на
class IExtensibleObject { public: virtual void *Dynamic_Cast(const char* pszType) = 0; virtual void DuplicatePointer(void) = 0; virtual void DestroyPointer(void) = 0; };
Разместив эти методы, все пользователи IExtensibleObject должны теперь придерживаться следующих двух соображений: 1) Когда указатель интерфейса дублируется, требуется вызов DuplicatePointer. 2) Когда указатель интерфейса более не используется, следует вызвать DestroyPointer.
Эти методы могут быть реализованы в каждом объекте: нужно просто фиксировать количество действующих указателей и уничтожать объект, когда невыполненных указателей не осталось:
class FastString : public IFastString, public IPersistentObject { int m_cPtrs; // count of outstanding ptrs // счетчик невыполненных указателей public: // initialize pointer count to zero // сбросить счетчик указателя в нуль FastString(const char *psz) : m_cPtrs(0) { } void DuplicatePointer(void) { // note duplication of pointer // отметить дублирование указателя ++m_cPtrs; } void DestroyPointer(void) { // destroy object when last pointer destroyed // уничтожить объект, когда уничтожен последний указатель if (--m_cPtrs == 0) delete this; } : : : };
Этот совершенно стандартный код мог бы просто быть включен в базовый класс или в макрос С-препроцессора, чтобы его могли использовать все реализации.
Чтобы поддерживать эти методы, все программы, которые манипулируют или управляют указателями интерфейса, должны придерживаться двух простых правил DuplicatePointer/DestroyPointer. Для реализации FastString это означает модификацию двух функций. Функция CreateFastString берет начальный указатель, возвращаемый новым оператором C++, и копирует его в стек для возврата клиенту. Следовательно, необходим вызов DuplicatePointer:
IFastString* CreateFastString(const char *psz) { IFastString *pfsResult = new FastString(psz); if (pfsResult) pfsResult->DuplicatePointer(); return pfsResult; }
Реализация копирует указатель и в другом месте — в методе Dynamic_Cast:
void *FastString::Dynamic_Cast(const char *pszType) { void *pvResult = 0; if (strcmp(pszType, "IFastString") == 0) pvResult = static_cast<IFastString*>(this); else if (strcmp(pszType, "IPersistentObject") == 0) pvResult = static_cast<IPersistentObject*>(this); else if (strcmp(pszType, "IExtensibleObject") == 0) pvResult = static_cast<IFastString*>(this); else return 0; // request for unsupported interface // запрос на неподдерживаемый интерфейс // pvResult now contains a duplicated pointer, so // we must call DuplicatePointer prior to returning // теперь pvResult содержит скопированный указатель, // поэтому нужно перед возвратом вызвать DuplicatePointer ((IExtensibleObject*)pvResult)->DuplicatePo1nter(); return pvResult; }
С этими двумя усовершенствованиями соответствующий код пользователя становится значительно более однородным и прозрачным:
void f(void) { IFastString *pfs = 0; IPersistentObject *ppo = 0; pfs = CreateFastString("Feed BOB"); if (pts) { рро = (IPersistentObject *) pfs->Dynamic_Cast("IPersistentObject"); if (ppo) { ppo->Save("C:\\autoexec.bat"); ppo->DestroyPointer(); } pfs->DestroyPointer(); } }
Поскольку каждый указатель теперь трактуется как автономный объект с точки зрения времени жизни, клиенту можно не интересоваться тем, какой указатель соответствует какому объекту. Вместо этого клиент просто придерживается двух простых правил и предоставляет объектам самим управлять своим временем жизни. При желании способ вызова DuplicatePointer и DestroyPointer можно легко скрыть за интеллектуальным указателем (smart pointer) C++.
Использование этой схемы вычисления ссылок позволяет объекту весьма единообразно выставлять множественные интерфейсы. Возможность выставления нескольких интерфейсов из одного класса реализации позволяет типу данных участвовать в различных контекстах. Например, новая постоянная подсистема могла бы определить собственный интерфейс для управления автозагрузкой и автозаписью объектов на некоторый специализированный носитель. Класс FastString мог бы добавить поддержку этих возможностей простым наследованием от постоянного интерфейса этой подсистемы. Добавление этой поддержки никак не повлияет на уже установленные базы клиентов, которые, может быть, используют прежний постоянный интерфейс для записи и загрузки строки на диск. Механизм согласования интерфейсов на этапе выполнения может служить краеугольным камнем для построения динамической системы из компонентов, которые могут изменяться со временем.
Атрибуты и свойства
Иногда бывает полезно показать, что объект имеет некие открытые свойства, которые могут быть доступны и/или которые можно модифицировать через СОМ-интерфейс. СОМ IDL позволяет аннотировать методы интерфейса с тем, чтобы данный метод либо модифицировал, либо читал именованный атрибут объекта. Рассмотрим такое определение интерфейса:
[ object, uuid(0BB3DAE1-11F4-11d1-8C84-0080C73925BA) ] interface ICollie : IDog { // Age is a read-only property // Age (возраст) - это свойство только для чтения [propget] HRESULT Age([out, retval] long *pVal); // HairCount is a read/write property // HairCount (счетчик волос) - свойство для чтения/записи [propget] HRESULT HairCount([out, retval] long *pVal); [propput] HRESULT HairCount([in] long val); // CurrentThought is a write-only property // CurrentThought (текущая мысль) — свойство только для записи [propput] HRESULT CurrentThought([in] BSTR val); }
Использование атрибутов [propget] и [propput] информирует компилятор IDL, что методы, которые ему соответствуют, должны быть отображены в преобразователи свойств (property mutators) или в аксессоры на языках, явно поддерживающих свойства. Применительно к Visual Basic это означает, что элементами Age, HairCount и CurrentThought можно манипулировать, используя тот же синтаксис, как при обращении к элементам структуры:
Sub UseCollie(fido as ICollie) fido.HairCount = fido.HairCount - (fido.Age * 1000) fido.CurrentThought = "I wish I had a bone" End Sub
С++-отображение этого интерфейса просто прибавляет к именам методов конструкции put_ или get_, чтобы подсказать программисту, что обращение относится к свойству:
void UseCollie(ICollie *pFido) { long n1, n2; HRESULT hr = pFido->get_HairCount(&n1); assert(SUCCEEDED(hr)); hr = pFido->get_Age(&n2); assert(SUCCEEDED(hr)); hr = pFido->put_HairCount(n1 - (n2 * 1000)): assert(SUCCEEDED(hr)); BSTR bstr = SysAllocString(OLESTR("I wish I had a bone")); hr = pFido->put_CurrentThought(bstr); assert(SUCCEEDED(hr)); SysFreeString(bstr); }
Хотя свойства напрямую не обеспечивают развития, они полезны для выполнения точных преобразований на те языки, которые их поддерживают.
1
Пакет Direct-to-COM фирмы Microsoft позволяет клиентам использовать свойства как открытые элементы данных интерфейса с помощью некоего очень хитрого механизма.
Где мы находимся?
В этой главе была представлена концепция интерфейса СОМ. Интерфейсы СОМ обладают простыми двоичными сигнатурами, которые позволяют любому клиенту обращаться к объекту независимо от языка программирования, использованного клиентом или конструктором объекта. Чтобы облегчить поддержку различных языков, интерфейсы СОМ определяются на языке IDL (Interface Definition Language). Эти IDL-определения интерфейса могут быть также использованы для генерирования кода передачи данных (communications code), который позволяет получать доступ к объекту через сеть.
Большая часть этой главы была посвящена IUnknown - базовому интерфейсу, на котором построен весь СОМ. Все интерфейсы СОМ должны наследовать от IUnknown. Следовательно, все объекты СОМ должны реализовывать IUnknown. В IUnknown предусмотрено три сигнатуры метода, посредством которых клиент может безошибочно управлять иерархией типов объекта для доступа к дополнительным возможностям, предоставляемым этим объектом. С учетом этого QueryInterface можно рассматривать как оператор приведения типа в СОМ. По этой же причине IUnknown можно рассматривать как "void *" (указатель на пустой тип) среди указателей интерфейса, так как от него не слишком много пользы до тех пор, пока он не "приведен" (is "cast") к чему-нибудь более содержательному с помощью QueryInterface.
Следует заметить, что при обращении или реализации IUnknown не было сделано никаких существенных системных вызовов. В этом смысле IUnknown просто является протоколом или набором обещаний (promises), которого должны придерживаться все программы. Это позволяет объектам СОМ быть очень простыми и эффективными. Реализация IUnknown в C++ требует всего нескольких строк стандартного кода. Чтобы автоматизировать реализацию IUnknown в C++, была представлена серия макросов для препроцессора, которые реализуют QueryInterface под табличным управлением. Хотя эти макросы не были совершенно необходимыми, они удаляли большую часть общего стандартного кода из каждого определения класса, не внося при этом заметных усложнений в реализацию.
IDL
СОМ IDL базируется на языке определения интерфейсов основного открытого математического обеспечения удаленного вызова процедур в распределенной вычислительной среде — Open Software Foundation Distributed Computing Environment Remote Procedure Call (OSF DCE RPC). DCE IDL позволяет описывать удаленные вызовы процедур не зависящим от языка способом. Это дает возможность компилятору IDL генерировать код для работы в сети, который прозрачным образом (transparently), то есть незаметно для пользователя, переносит описанные операции на всевозможные сетевые средства сообщения. СОМ IDL просто добавляет некоторые расширения, специфические для СОМ, в DCE IDL для поддержки объектно-ориентированных понятий СОМ (например, наследование, полиморфизм). Не случайно, что когда обращение к объектам СОМ осуществляется через границу контекста выполнения или через границы между машинами, все связи клиент-объект используют MS-RPC (реализация DCE RPC, являющаяся частью Windows NT и Windows 95) как основное средство сообщения.
Win32 SDK включает в себя компилятор МIDL.ЕХЕ, который анализирует файлы СОМ IDL и генерирует несколько искусственных объектов — артефактов (artifacts). Как показано на рис. 2.1, MIDL генерирует совместимые с C/C++ заголовочные файлы, которые содержат определения абстрактного базового класса, соответствующие интерфейсам, описанным в исходном IDL-файле.
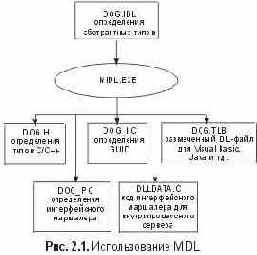
Эти заголовочные файлы также содержат совместимые с С, основанные на структурах определения (structure-based definitions), которые позволяют С-программам обращаться к интерфейсам, описанным на IDL, или обеспечивать их выполнение. То, что MIDL автоматически генерирует С/С++-заголовочный файл, означает, что ни один из СОМ-интерфейсов не нужно определять на C++ вручную. Исход определений из одной точки исключает возникновение множества несовместимых версий определений интерфейсов, которые со временем могут вызвать асинхронность. MIDL также генерирует исходный код, который позволяет использовать интерфейсы в различных потоках, процессах и машинах.
Этот код будет обсуждаться в главе 5. И наконец, MIDL может генерировать двоичный файл, который позволяет другим средам, принимающим СОМ, отображать интерфейсы, определенные в исходном IDL-файле, на другие языки. Этот двоичный файл называется библиотекой типа (type library) и содержит разобранный файл IDL в наиболее эффективной для анализа форме. Библиотеки типа обычно распространяются как часть исполняемого файла реализации и позволяют таким языкам, как Visual Basic, Java, Object Pascal использовать интерфейсы, которые выставляются этой реализацией.
Чтобы понять IDL, необходимо рассмотреть логический и физический аспекты интерфейса. Обсуждение методов интерфейса и выполняемых ими операций относятся к логическому аспекту интерфейса. Обсуждение памяти, стекового фрейма, сетевых пакетов и других динамических явлений обычно относятся к физическому аспекту интерфейса. Некоторые физические аспекты интерфейса могут непосредственно наследовать логическому описанию (например, расположение таблицы vtbl, порядок параметров в стеке). Другие физические аспекты (например, границы массивов, сетевые представления сложных типов данных) требуют дополнительной квалификации.
IDL позволяет разработчикам интерфейса работать непосредственно в сфере логики, используя синтаксис С. Но в то же время IDL требует от разработчиков точно определять все те аспекты интерфейса, которые не могут быть воспроизведены непосредственно по их логическому описанию на С, с помощью использования аннотаций, формально называемых атрибутами. Атрибуты IDL легко распознать в основном тексте IDL: разделенные запятыми, они заключены в скобки. Атрибуты всегда предшествуют описанию объекта, к которому они относятся. Например, в следующем IDL- фрагменте
[ v1_enum, helpstring("This is a color!") ] enum COLOR { RED, GREEN, BLUE };
атрибут v1_enum относится к описанию перечисления (enumeration) COLOR. Этот атрибут информирует компилятор IDL о том, что представление COLOR при передаче значения через сеть должно иметь 32 бита, а не 16, как принято по умолчанию.
Атрибут helpstring также относится к СОLОR и добавляет строку "This is a color!" ("Это — цвет!") в создаваемую библиотеку типа как описание этого перечисления. Если игнорировать атрибуты в IDL-файле, то его синтаксис такой же, как в С. IDL поддерживает структуры, объединения, массивы, перечисления, а также определения типа (typedef) — с синтаксисом, идентичным их аналогам в С.
Определяя методы СОМ в IDL, необходимо четко указать, кто — вызывающий или вызываемый объект — будет записывать или читать каждый параметр метода. Это выполняется с помощью атрибутов параметра [in] и [out]:
void Method1([in] long arg1, [out] long *parg2, [in, out] long *parg3);
Для этого фрагмента IDL предполагается, что вызывающий объект передаст значение в объект arg1 и по адресу, содержащемуся в указателе parg3. По завершении возвращаемые значения будут получены вызывающим объектом по адресам, указанным в parg2 и parg3. Это означает, что для последовательности вызовов:
long arg2 = 20, arg3 = 30; p->Method1(10, &arg2, &arg3);
объект не может полагаться на получение передаваемого значения 20 через parg2. Если объект запускается в том же контексте выполнения, что и вызывающий объект, и оба участника вызова реализованы на C++, то *parg2 действительно будет иметь на входе метода значение 20. Однако если объект вызывается из другого контекста выполнения или один из участников вызова реализован на языке, который сводит на нет оптимизацию начальных значений чисто выходных (out-only) параметров, то инициализация параметра вызывающим объектом будет утеряна.
1Термин контекст выполнения (execution context) используется в определении СОМ, чтобы описать все, что было впоследствии переименовано в апартамент (apartment). Апартамент — не поток и не процесс; однако он имеет общие для этих обоих понятии признаки. Подробно понятие апартамента описано в главе 5.
Интерфейс IUnknown
СОМ-интерфейс IUnknown имеет то же назначение, что и интерфейс IExtensibleObject, определенный в предыдущей главе. Последняя версия IExtensibleObject, появившаяся в конце предыдущей главы, имеет вид:
class IExtensibleObject { public: virtual void *Dynamic_Cast(const char* pszType) = 0; virtual void DuplicatePointer(void) = 0; virtual void DestroyPointer(void) = 0; }
Для определения типа на этапе выполнения был применен метод Dynamic_Cast, аналогичный оператору C++ dynamic_cast. Для извещения объекта о том, что указатель интерфейса дублировался, использовался метод DuplicatePointer. Для сообщения объекту, что указатель интерфейса уничтожен и все используемые им ресурсы могут быть освобождены, был применен метод DestroyPointer. Вот как выглядит определение IUnknown на C++:
extern "С" const IID IID_IUnknown: interface IUnknown { virtual HRESULT STDMETHODCALLTYPE QueryInterface(REFIID riid, void **ppv) = 0; virtual ULONG STDMETHODCALLTYPE AddRef(void) = 0; virtual ULONG STDMETHODCALLTYPE Release(void) = 0; };
Заголовочные файлы SDK дают псевдоним interface ключевому слову C++ struct, используя препроцессор С. Поскольку интерфейсы в СОМ определены не как классы, а как структуры, то для того, чтобы сделать методы интерфейса общедоступными, ключевое слово public не требуется. Чтобы создать для целевой платформы СОМ-совместимые стековые фреймы, необходим макрос STDMETHODCALLTYPE. Если целевыми являются платформы Win32, то при использовании компилятора Microsoft C++ этот макрос раскрывается в _stdcall.
IUnknown функционально эквивалентен IExtensibleObject. Метод QueryInterface используется для динамического определения типа и аналогичен С++-оператору dynamic_cast. Метод AddRef используется для сообщения объекту, что указатель интерфейса дублирован. Метод Release используется для сообщения объекту, что указатель интерфейса уничтожен и все ресурсы, которые объект поддерживал от имени клиента, могут быть отключены. Главное различие между IUnknown и интерфейсом, определенным в предыдущей главе, заключается в том, что IUnknown использует идентификаторы GUID, а не строки для идентификации типов интерфейса на этапе выполнения.
IDL-определение IUnknown можно найти в файле unknwn. idl из директории SDK, содержащей заголовочные файлы:
// unknwn.idl - system IDL file // unknwn.idl - системный файл IDL [ local, object, uuid (00000000-0000-0000-C000-000000000046) ] interface IUnknown { HRESULT QueryInterface([in] REFIID riid, [out] void **ppv); ULONG AddRef(void); ULONG Release(void); }
Атрибут local подавляет генерирование сетевого кода для этого интерфейса. Этот атрибут необходим для того, чтобы смягчить требования СОМ о том, что все методы при вызове с удаленных машин должны возвращать HRESULT. Как будет показано в следующих главах, интерфейс IUnknown трактуется особым образом при работе с удаленными объектами. Заметим, что фактические, то есть использующиеся на практике IDL-описания интерфейсов, которые содержатся в заголовках SDK, немного отличаются от определений, данных в этой книге. Фактические определения часто содержат дополнительные атрибуты для оптимизации генерируемого сетевого кода, которые не имеют отношения к нашему обсуждению. В случае сомнений обратитесь за полными определениями к последней версии заголовочных файлов SDK.
Интерфейс IUnknown является родительским для всех СОМ-интерфейсов. IUnknown — единственный интерфейс СОМ, который не наследует от другого интерфейса. Любой другой допустимый интерфейс СОМ должен быть прямым потомком IUnknown или какого-нибудь другого допустимого интерфейса СОМ, который, в свою очередь, должен сам наследовать или прямо от IUnknown, или от какого-нибудь другого допустимого интерфейса СОМ. Это означает, что на двоичном уровне все интерфейсы СОМ являются указателями на таблицы vtbl, которые начинаются с трех точек входа: QueryInterface, AddRef и Release. Все специфические для интерфейсов методы будут иметь точки входа в vtbl, которые появляются после этих трех общих точек входа.
Чтобы наследовать от интерфейса IDL, нужно или определить базовый интерфейс в том же IDL-файле, или использовать директиву import, чтобы сделать внешнее IDL-определение базового интерфейса явным в данной области действия:
// calculator.idl [object, uuid(BDA4A270-A1BA-11dO-8C2C-0080C73925BA)] interface ICalculator : IUnknown { import "unknwn.idl"; // bring in def. of IUnknown // импортируем определение IUnknown HRESULT Clear(void); HRESULT Add([in] long n); HRESULT Sum([out, retval] long *pn); }
Оператор import может появляться или внутри определения интерфейса, как показано здесь, или предшествовать описанию интерфейса в глобальной области действия. В любом из этих случаев действия оператора import одинаковы, он может многократно импортировать один IDL-файл без всякого ущерба. Поскольку сгенерированный C/C++ заголовочный файл будет требовать С/С++-версии импортируемого IDL-файла, чтобы обеспечить наследование, оператор import из IDL-файла будет странслирован в команду #include в генерируемом заголовочном С/С++-файле:
// calculator.h - generated by MIDL // calculator.h - генерированный MIDL // bring in def. of IUnknown // вводим определения IUnknown #include "unknwn.h" extern "C" const IID IID_ICalculator; interface ICalculator : public IUnknown { virtual HRESULT STDMETHODCALLTYPE Clear(void) = 0; virtual HRESULT STDMETHODCALLTYPE Add(long n) = 0; virtual HRESULT STDMETHODCALLTYPE Sum(long *pn) = 0; }
Компилятор MIDL также создаст С-файл, содержащий фактические определения всех GUID, имеющихся в исходном IDL-файле:
// calculator_i.с - generated by MIDL const IID IID_ICalculator = { 0xBDA4A270, 0xA1BA, 0x11d0, { 0x8C, 0x2C, 0x00, 0х80, 0хC7, 0х39, 0x25, 0xBA } };
Каждый проект, который будет использовать этот интерфейс, должен или добавить calculator_i.c к своему файлу сборки (makefile), или включить calculator_i.c в один из исходных файлов на С или C++ с использованием препроцессора С. Если это не сделано, то идентификатору IID_ICalculator не будет выделено памяти для его 128-битного значения и проект не будет скомпонован по причине неразрешенных внешних идентификаторов.
СОМ не накладывает никаких ограничений на глубину иерархии интерфейсов при условии, что конечным базовым интерфейсом является IUnknown.
Нижеследующий IDL является вполне допустимым и корректным для СОМ:
import "unknwn.idl"; [object, uuid(DF12E151-A29A-11d0-8C2D-0080C73925BA)] interface IAnimal : IUnknown { HRESULT Eat(void); }
[object, uuid(DF12E152-A29A-11d0-8C2D-0080C73925BA)] interface ICat : IAnimal { HRESULT IgnoreMaster(void); }
[object, uuid(DF12E153-A29A-11d0-8C2D-0080C73925BA)] interface IDog : IAnimal { HRESULT Bark(void); }
[object, uuid(DF12E154-A29A-11d0-8C2D-0080C73925BA)] interface IPug : IDog { HRESULT Snore(void); }
[object, uuid(DF12E155-A29A-11d0-8C2D-0080C73925BA)] interface IOldPug : IPug { HRESULT SnoreLoudly(void); }
СОМ накладывает одно ограничение на наследование интерфейсов: интерфейсы СОМ не могут быть прямыми потомками более чем одного интерфейса. Следующий фрагмент в СОМ недопустим:
[object, uuid(DF12E156-A29A-11d0-8C2D-0080C73925BA)] interface ICatDog : ICat, IDog { // illegal, multiple bases // неверно, несколько базовых интерфейсов HRESULT Meowbark(void); }
СОМ запрещает наследование от нескольких интерфейсов по целому ряду причин. Одна из них состоит в том, что двоичное представление результирующего абстрактного базового класса C++ не будет независимым от компилятора. В этом случае СОМ уже не будет являться двоичным стандартом, независимым от разработчика. Другая причина кроется в тесной связи между СОМ и DCE RPC. При ограничении наследования интерфейсов одним базовым интерфейсом преобразование между интерфейсами СОМ и интерфейсными векторами DCE RPC вполне однозначно. В конце концов, отсутствие поддержки нескольких базовых интерфейсов не является ограничением, так как каждая реализация может выбрать для открытия столько интерфейсов, сколько пожелает. Это означает, что основанный на СОМ Cat/Dog по-прежнему допустим на уровне реализации:
class CatDog : public ICat, public IDog { // ... };
Клиент, желающий трактовать объект как Cat/Dog, просто использует QueryInterface для привязки к объекту обоих типов указателей. Если один из вызовов QueryInterface не достигает успеха, то данный объект не является Cat/Dog и клиент может справляться с этим, как сумеет.Поскольку реализации могут открывать несколько интерфейсов, то запрет для интерфейсов наследовать более чем от одного интерфейса является лишь небольшой потерей в смысле семантической информации или информации о типе.
СОМ поддерживает стандарт обозначений, который показывает, какие интерфейсы доступны из объекта. Этот способ придерживается философии СОМ относительно отделения интерфейса от реализации и не раскрывает никаких деталей реализации объекта иначе, чем через список выставляемых им интерфейсов.

Рисунок 2.4 показывает стандартное обозначение класса CatDog. Заметим, что из этой схемы можно сделать единственный вывод: если не произойдет катастрофических сбоев, объекты CatDog выставят четыре интерфейса: ICat, IDog, IAnimal и IUnknown.
Интерфейсы
void *pv = malloc(sizeof(int)); int *pi = (int*)pv; (*pi)++; free(pv);
Аноним,1982
В предыдущей главе было показано несколько приемов программирования на C++, позволяющих разрабатывать двоичные компоненты повторного использования, которые со временем могут быть модернизированы. По своему смыслу эти приемы идентичны тем, которые используются моделью СОМ. Незначительные различия между методиками предыдущей главы и теми, которые используются СОМ, в большинстве случаев заключаются в деталях и почти всегда достаточно обоснованы. Вообще-то предыдущая глава прослеживала историю модели СОМ, которая прежде всего и в основном есть отделение интерфейса от реализации.
Интерфейсы и IDL
Определения методов в IDL являются просто аннотированными аналогами С-функций. Определения интерфейсов в IDL требуют расширения по сравнению с С, так как С не имеет встроенной поддержки этого понятия. Определение интерфейса в IDL начинается с ключевого слова interface. Это определение состоит их четырех частей: имя интерфейса, базовое имя интерфейса, тело интерфейса и атрибуты интерфейса. Тело интерфейса представляет собой просто набор определений методов и операторов определения типов:
[ attribute1, attribute2, ...] interface IThisInterface : IBaseInterface { typedef1; typedef2; : : method1; method2; }
Каждый интерфейс СОМ должен иметь как минимум два атрибута IDL. Атрибут [object] служит признаком того, что данный интерфейс является СОМ-, а не DCE-интерфейсом. Второй обязательный атрибут указывает на физическое имя интерфейса (в предшествующем IDL-фрагменте IThisInterface является логическим именем интерфейса).
Чтобы понять, почему СОМ-интерфейсы требуют физическое имя, отличное от логического имени интерфейса, рассмотрим следующую ситуацию. Два разработчика независимо друг от друга решили создать интерфейс, моделирующий ручной калькулятор. Два их определения интерфейса будут, вероятно, похожими, будучи заданными в общей проблемной области, но скорее всего фактический порядок определений методов и, возможно, сигнатур методов могут в чем-то различаться. Несмотря на это, оба разработчика, вероятно, выберут одно и то же логическое имя: ICalculator.
Клиентская программа на машине какого-нибудь конечного пользователя может реализовать определение интерфейса от первого разработчика, а запустить объект, созданный вторым. Поскольку оба интерфейса имеют одно и то же логическое имя, то если клиент запросит объект для поддержки ICalculator, просто использовав строку "ICalculator", объект ответит на запрос возвратом ненулевого указателя интерфейса. Однако представление клиента о том, на что похож ICalculator, вступит в конфликт с тем, какое представление о нем имеет этот объект, и результирующий указатель будет не тем, которого ожидает клиент.
Ведь эти два интерфейса могут быть совершенно разными, несмотря на то, что оба используют одно и то же логическое имя.
Чтобы исключить коллизию имен, всем СОМ-интерфейсам на этапе проектирования назначается уникальное двоичное имя, которое является физическим именем интерфейса. Эти физические имена называются глобально уникальными идентификаторами (Globally Unique Identifiers — GUIDs), что рифмуется со словом squids. GUID используются в СОМ повсюду для именования статических сущностей, таких как интерфейсы или реализации. GUID являются чрезвычайно большими 128-битными числами, что гарантирует их уникальность как во времени, так и в пространстве. GUID в СОМ основаны на универсальных уникальных идентификаторах (Universally Unique Identifiers — UUIDs), используемых в DCE RPC. При использовании GUID для именования СОМ-интерфейсов их часто называют идентификаторами интерфейса (Interface IDs — IIDs). Реализации в СОМ также именуются с помощью GUID, и в этом случае GUID называются идентификаторами класса (Class IDs — CLSIDs). Будучи представленными в текстовой форме, GUID всегда имеют следующий канонический вид:
BDA4A270-A1BA-11d0-8C2C-0080C73925BA
Эти 32 шестнадцатеричные цифры представляют 128-битное значение GUID. Именование интерфейсов и реализации с помощью GUID важно для предотвращения коллизий между разными компонентами.
Для создания нового GUID в СОМ имеется API-функция, которая использует децентрализованный алгоритм уникальности для генерирования нового 128-битного числа, которое никогда больше не встретится в природе:
HRESULT CoCreateGuid(GUID *pguid);
Алгоритм, задействованный в функции CoCreateGuid, использует локальный сетевой интерфейсный адрес машины, текущее машинное время и два постоянных счетчика для компенсации точности часов и нестандартных изменении в них (таких, как переход на летнее время или ручная коррекция системных часов). Если данная машина не имеет сетевого интерфейса, то синтезируется статистически уникальная величина и CoCreateGuid возвращает особого вида HRESULT, показывающий, что данная величина является глобально уникальной только статистически и может считаться таковой только при использовании на локальной машине.
Хотя прямой вызов функции CoCreateGuid иногда полезен, большинство разработчиков вызывают ее в неявной форме, применяя из SDK программу GUIDGEN.EXE. На рис. 2.3 показана работа GUIDGEN. GUIDGEN вызывает CoCreateGuid и преобразует полученный GUID в один из четырех форматов, удобных для включения в исходный код на C++ или IDL. При работе в IDL используется четвертый формат (каноническая текстовая форма).

Чтобы связать физическое имя интерфейса с его определением на IDL, используется второй обязательный атрибут интерфейса — [uuid]. Атрибут [uuid] содержит один параметр — каноническую текстовую форму GUID:
[object, uuid(BDA4A270-A1BA-11dO-8C2C-0080C73925BA)] interface ICalculator : IBaseInterface { HRESULT Clear(void); HRESULT Add([in] long n); HRESULT Sum([out, retval] long *pn); }
При использовании при программировании на С или C++ физического имени интерфейса IID данного интерфейса представляет собой просто логическое имя интерфейса, предшествуемое префиксом IID_. Например, интерфейс ICalculator будет иметь IID, которым можно программно манипулировать, используя сгенерированную IDL константу IID_ICalculator. Для предотвращения коллизий между символическими именами интерфейсов можно использовать пространство имен C++.
Поскольку лишь немногие из компиляторов C++ могут поддерживать 128-битные числа, СОМ определяет С-структуру для представления 128-битовой величины GUID и предлагает псевдонимы для типов IID и CLSID с использованием следующего определения типов:
typedef struct _GUID { DWORD Data1; WORD Data2; WORD Data3; BYTE Data4[8]; } GUID; typedef GUID IID; typedef GUID CLSID;
Внутренняя структура GUID для большинства программистов несущественна, так как единственная значимая операция, которую можно выполнить с GUID, — это проверка их эквивалентности. Для обеспечения эффективной передачи величин GUID как аргументов функций СОМ предусматривает также постоянные псевдонимы для ссылок (constant reference aliases) для каждого типа GUID:
#define REFGUID const GUID& #define REFIID const IID& #define REFCLSID const CLSID&
Чтобы иметь возможность сравнивать величины GUID, СОМ обеспечивает функции эквивалентности и перегружает операторы == и != для постоянных ссылок GUID:
inline BOOL IsEqualGUID(REFGUID r1, REFGUID r2) { return !memcmp(&r1, &r2, sizeof(GUID)); }
#def1ne IsEqualIID(r1, r2) IsEqualGUID((r1) , (r2))
#define IsEqualCLSID(r1, r2) IsEqualGUID((r1), (r2))
inline BOOL operator == (REFGUID r1, REFGUID r2) { return !memcmp(&r1, &r2, sizeof(GUID)); }
inline BOOL operator != (REFGUID r1, REFGUID r2) { return !(r1 == r2); }
Фактические заголовки SDK содержат условно компилируемые совместимые с С версии определений типа, макросов и встраиваемых функций, как показано выше.
Поскольку показано, что представления имен интерфейсов на этапе выполнения являются GUID, а не строками; это означает, что метод Dynamic_Cast, описанный в предыдущей главе, следует пересмотреть. Действительно, весь интерфейс IЕхtensibleObject должен быть изменен и преобразован в свой аналог IUnknown, совместимый с СОМ.
1Точное произношение слова GUID является предметом горячих споров между разработчиками СОМ. Хотя спецификация СОМ формулирует, что GUID рифмуется с fluid (подвижный), а не squid (кальмар), автор уверен, что она ошибается, ссылаясь как на прецедент на слово languid (медлительный)
Исключения
СОМ имеет специфическую поддержку выбрасывания (throwing) исключительных ситуаций из реализации методов. Поскольку в языке C++ не существует двоичного стандарта для исключений, СОМ предлагает явные API-функции для выбрасывания и перехвата объектов СОМ-исключений:
// throw an exception // возбуждаем исключения HRESULT SetErrorInfo([in] ULONG reserved, // m.b.z. [in] IErrorlnfo *pei); // catch an exception // перехватываем исключение HRESULT GetErrorInfo([in] ULONG reserved, // m.b.z. [out] IErrorInfo **ppei);
Процедура SetErrorInfo вызывается из реализации метода, чтобы связать объект исключения с текущим логическим потоком (logical thread). GetErrorInfo выбирает объект исключения из текущего логического потока и сбрасывает исключение, так что следующие вызовы GetErrorInfo возвратят S_FALSE, показывая тем самым, что необработанных исключений нет. Как следует из приведенных ниже подпрограмм, объекты исключений должны поддерживать по крайней мере интерфейс IErrorInfo:
[ object, uuid(1CF2B120-547D-101B-8E65-08002B2BD119) ] interface IErrorInfo: IUnknown { // get IID of interface that threw exception // получаем IID того интерфейса, который возбудил исключение HRESULT GetGUID([out] GUID * pGUID); // get class name of object that threw exception // получаем имя класса того объекта, который возбудил исключение HRESULT GetSource([out] BSTR * pBstrSource); // get human-readable description of exception // получаем читабельное описание исключения HRESULT GetDescription([out] BSTR * pBstrDescription); // get WinHelp filename of documentation of error // получаем имя файла WinHelp, содержащего документацию об ошибке HRESULT GetHelpFile([out] BSTR * pBstrHelpFile); // get WinHelp context ID for documentation of error // получаем контекстный идентификатор WinHelp для документации ошибки HRESULT GetHelpContext([out] DWORD * pdwHelpContext); }
Специальные объекты исключений могут выбрать другие специфические для исключений интерфейсы в дополнение к IErrorInfo.
СОМ предусматривает по умолчанию реализацию IErrorInfo, которую можно создать с использованием API-функции СОМ CreateErrorInfo:
HRESULT CreateErrorInfo([out] ICreateErrorInfo **ppcei);
В дополнение к IErrorInfo объекты исключений по умолчанию открывают интерфейс ICreateErrorInfo, чтобы позволить пользователю инициализировать состояние нового исключения:
[ object, uuid(22F03340-547D-101B-8E65-08002B2BD119) ] interface ICreateErrorInfo: IUnknown { // set IID of interface that threw exception // устанавливаем IID интерфейс, который возбудил исключение HRESULT SetGUID([in] REFGUID rGUID); // set class name of object that threw exception // устанавливаем классовое имя объекта, который возбудил исключение HRESULT SetSource([in, string] OLECHAR* pwszSource); // set human-readable description of exception // устанавливаем читабельное описание исключения HRESULT SetDescription([in, string] OLECHAR* pwszDesc); // set WinHelp filename of documentation of error // устанавливаем имя файла WinHelp, содержащего документацию об ошибке HRESULT SetHelpFile([in, string] OLECHAR* pwszHelpFile); // set WinHelp context ID for documentation of error // устанавливаем идентификатор контекста WinHelp для документации ошибки HRESULT SetHelpContext([in] DWORD dwHelpContext); }
Заметим, что этот интерфейс просто позволяет пользователю заполнить объект исключения пятью основными атрибутами, доступными из интерфейса IErrorInfo.
Следующая реализация метода выбрасывает СОМ-исключение своему вызывающему объекту, используя объект исключений по умолчанию:
STDMETHODIMP PugCat::Snore(void) { if (this->IsAsleep()) // ok to perform operation? // можно ли выполнять операцию? return this->DoSnore(); //do operation and return // выполняем операцию и возвращаемся //otherwise create an exception object // в противном случае создаем объект исключений ICreateErrorInfo *рсеi = 0; HRESULT hr = CreateErrorInfo(&pcei); assert(SUCCEEDED(hr)); // initialize the exception object // инициализируем объект исключений hr = pcei->SetGUID(IID_IPug); assert(SUCCEEDED(hr)); hr = pcei->SetSource(OLESTR("PugCat")); assert(SUCCEEDED(hr)); hr = pcei->SetDescription(OLESTR("I am not asleep!")); assert(SUCCEEDED(hr)); hr = pcei->SetHelpFile(OLESTR("C:\\PugCat.hlp")); assert(SUCCEEDED(hr)); hr = pcei->SetHelpContext(5221); assert(SUCCEEDED(hr)); // "throw" exception // "выбрасываем" исключение IErrorInfo *pei = 0; hr = pcei->QueryInterface(IID_IErrorInfo, (void**)&pei); assert(SUCCEEDED(hr)); hr = SetErrorInfo(0, pei); // release resources and return a SEVERITY_ERROR result // высвобождаем ресурсы и возвращаем результат // SEVERITY_ERROR (серьезность ошибки) pei->Release(); pcei->Release(); return PUG_E_PUGNOTASLEEP; }
Отметим, что поскольку объект исключений передается в процедуру SetErrorInfo, СОМ сохраняет ссылку на исключение до тех пор, пока оно не будет "перехвачено" вызывающим объектом, использующим GetErrorInfo.
Объекты, которые сбрасывают исключения СОМ, должны использовать интерфейс ISupportErrorInfo, чтобы показывать, какие интерфейсы поддерживают исключения. Этот интерфейс используется клиентами, чтобы установить, верный ли результат дает GetErrorInfo. Этот интерфейс предельно прост:
[ object, uuid(DFOB3060-548F-101B-8E65-08002B2BD119) ] interface ISupportErrorInfo: IUnknown { HRESULT InterfaceSupportsErrorInfo([in] REFIID riid); }
Предположим, что класс PugCat, рассмотренный в этой главе, сбрасывает исключения из каждого поддерживаемого им интерфейса. Тогда его реализация будет выглядеть так:
STDMETHODIMP PugCat::InterfaceSupportsErrorInfo(REFIID riid) { if (riid == IID_IAnimal riid == IID_ICat riid == IID_IDog riid == IID_IPug) return S_OK; else return S_FALSE; }
Ниже приведен пример клиента, который надежно обрабатывает исключения, используя ISupportErrorInfo и GetErrorInfo:
void TellPugToSnore(/*[in]*/ IPug *pPug) { // call a method // вызываем метод HRESULT hr = pPug->Snore(); if (FAILED(hr)) { // check to see if object supports СОМ exceptions // проверяем, поддерживает ли объект исключения СОМ ISupportErrorInfo *psei = 0; HRESULT hr2 =pPug->QueryInterface( IID_ISupportErrorInfo, (void**)&psei); if (SUCCEEDED(hr2)) { // check if object supports СОМ exceptions via IPug methods // проверяем, поддерживает ли объект исключения СОМ через методы IPug hr2 = psei->InterfaceSupportsErrorInfo(IID_IPug); if (hr2 == S_OK) { // read exception object for this logical thread // читаем объект исключений для этого логического потока IErrorInfo *реi = 0; hr2 = GetErrorInfo(0, &pei); if (hr2 == S_OK) { // scrape out source and description strings // извлекаем строки кода и описания BSTR bstrSource = 0, bstrDesc = 0; hr2 = pei->GetDescription(&bstrDesc); assert(SUCCEEDED(hr2)); hr2 = pei->GetSource(&bstrSource); assert(SUCCEEDED(hr2)); // display error information to end-user // показываем информацию об ошибке конечному пользователю MessageBoxW(0, bstrDesc ? bstrDesc : L"", bstrSource ? bstrSource : L"", MB_OK); // free resources // высвобождаем ресурсы SysFreeString(bstrSource); SysFreeString(bstrDesc); pei->Release(); } } psei->Release(); } } if (hr2 != S_OK) // something went wrong with exception // что-то неладно с исключением MessageBox(0, "Snore Failed", "IPug", MB_OK); }
Довольно просто отобразить исключения СОМ в исключения C++, причем в любом месте. Определим следующий класс, который упаковывает объект исключений СОМ и HRESULT в один класс C++:
struct COMException { HRESULT m_hresult; // hresult to return // hresult для возврата IErrorInfo *m_pei; // exception to throw // исключение для выбрасывания COMException(HRESULT hresult, REFIID riid, const OLECHAR *pszSource, const OLECHAR *pszDesc, const OLECHAR *pszHelpFile = 0, DWORD dwHelpContext = 0) { // create and init an error info object // создаем и инициализируем объект информации об ошибке ICreateErrorInfo *рсеi = 0; HRESULT hr = CreateErrorInfo(&pcei); assert(SUCCEEDED(hr)); hr = pcei->SetGUID(riid); assert(SUCCEEDED(hr)); if (pszSource) hr=pcei->SetSource(const_cast<OLECHAR*>(pszSource)); assert(SUCCEEDED(hr)); if (pszDesc) hr=pcei->SetDescription(const_cast<OLECHAR*>(pszDesc)); assert(SUCCEEDED(hr)); if (pszHelpFile) hr=pcei->SetHelpFile(const_cast<OLECHAR*>(pszHelpFile)); assert(SUCCEEDED(hr)); hr = pcei->SetHelpContext(dwHelpContext); assert(SUCCEEDED(hr)); // hold the HRESULT and IErrorInfo ptr as data members // сохраняем HRESULT и указатель IErrorInfo как элементы данных m_hresult = hresult; hr=pcei->QueryInterface(IID_IErrorInfo, (void**)&m_pei); assert(SUCCEEDED(hr)); pcei->Release(); } };
С использованием только что приведенного С++-класса COMException показанный выше метод Snore может быть модифицирован так, чтобы он преобразовывал любые исключения C++ в исключения СОМ:
STDMETHODIMP PugCat::Snore(void) { HRESULT hrex = S_OK; try { if (this->IsAsleep()) return this->DoSnore(); else throw COMException(PUG_E_PUGNOTASLEEP, IID_IPug, OLESTR("PugCat"), OLESTR("I am not asleep!")); } catch (COMException& ce) { // a C++ COMException was thrown // было сброшено исключение COMException C++ HRESULT hr = SetErrorInfo(0, ce.m_pei); assert(SUCCEEDED(hr)); ce.m_pei->Release(); hrex = ce.m_hresult; } catch (...) { // some unidentified C++ exception was thrown // было выброшено какое-то неидентифицированное исключение C++ COMException ex(E_FAIL, IID_IPug, OLESTR("PugCat"), OLESTR("A C++ exception was thrown")); HRESULT hr = SetErrorInfo(0, ex.m_pei); assert(SUCCEEDED(hr)); ex.m_pei->Release(); hrex = ex.m_hresult; } return hrex; }
Заметим, что реализация метода заботится о том, чтобы не позволить чисто С++-исключениям переходить через границы метода. Таково безусловное требование СОМ.
1
Спецификация СОМ использует термин логический поток (logical thread) для наименования последовательности вызовов методов, которая может превосходить физический OS-поток.
2
Объект, который обеспечивает выполнение GetErrorInfo, декларирует, что он явно программирует с использованием исключений СОМ и что никаких ошибочных исключений, сброшенных объектами младшего уровня, случайно не распространилось.
Использование указателей интерфейса СОМ
Программисты C++ должны использовать методы IUnknown явно, потому что перевод модели СОМ на язык C++ не предусматривает использования среды поддержки выполнения (runtime layer) между кодом клиента и кодом объекта. Поэтому IUnknown можно рассматривать просто как набор обещаний, которые все программисты СОМ дают друг другу. Это дает преимущество программистам C++, так как C++ может создавать код, который потенциально более эффективен, чем языки, которые требуют такого динамического слоя при работе с СОМ.
При работе на Visual Basic и Java, в отличие от C++, программисты никогда не видят QueryInterface, AddRef или Release. Для этих двух языков детали IUnknown надежно скрыты за поддерживающей эти языки виртуальной машиной. На Java QueryInterface просто отображается в приведение типа:
public void TryToSnoreAndIgnore(Object obj) { IPug pug; try { pug = (IPug)obj; // VM calls QueryInterface // VM вызывает QueryInterface pug.Snore(); } catch (Throwable ex) { // ignore method or QI failures // игнорируем сбой метода или QI }
ICat cat;
try { cat = (ICat)obj; // VM calls QueryInterface // VM вызывает QueryInterface cat.IgnoreMaster(); } catch (Throwable ex) { // ignore method or QI failures // игнорируется сбой метода или QI } }
Visual Basic не требует от клиентов приведения типов. Вместо этого, когда указатель интерфейса присваивается переменной неподходящего типа, виртуальная машина (VM) Visual Basic молча вызывает QueryInterface от имени клиента:
Sub TryToSnoreAndIgnore(obj as Object) On Error Resume Next ' ignore errors ' игнорируем ошибки Dim pug as IPug Set pug = obj ' VM calls QueryInterface ' VM вызывает QueryInterface If Not (pug is Nothing) Then pug.Snore End if Dim cat as ICat Set cat = obj ' VM calls QueryInterface ' VM вызывает QueryInterface If Not (cat is Nothing) Then cat.IgnoreMaster End if End Sub
Обе виртуальные машины, как Java, так и Visual Basic, выбросят при сбое QueryInterface исключения. В обеих средах виртуальная машина автоматически преобразует языковую концепцию живучести переменной в явные вызовы AddRef и Release, избавляя клиента и от этой подробности.
Одна методика, потенциально способная упростить использование в СОМ интерфейсных указателей из C++, состоит в том, чтобы скрыть их в классе интеллектуальных указателей. Это устраняет необходимость необработанных (raw) вызовов методов IUnknown. В идеале интеллектуальный указатель СОМ будет:
Корректно обрабатывать каждый вызов Add/Release во время присваивания.
Автоматически уничтожать интерфейс в деструкторе, что снижает возможность утечки ресурса и повышает безопасность (надежность) исключений.
Использует систему типов C++ для упрощения вызовов QueryInterface.
Прозрачным образом (незаметно для пользователя или программы) замещает необработанные интерфейсные указатели в существующем коде без компрометации правильности программы.
Последний пункт представляет собой чрезвычайно серьезную проблему. Интернет забит интеллектуальными СОМ-указателями, которые проделывают прозрачную замену обычных указателей, но при этом вводят столько же скрытых ошибок, сколько претендуют устранить. Visual C++ 5.0, например, фактически действует с тремя такими указателями (один на MSC, другой на ATL, а третий для поддержки Direct-to-COM), которые очень просто использовать как правильно, так и неправильно. В сентябрьском 1995 года и в февральском 1996 года выпусках "C++ Report" опубликованы две статьи, где на примерах показаны различные подводные камни при использовании интеллектуальных указателей. Исходный код, который приводится в данной книге, содержит интеллектуальный СОМ-указатель, созданный в процессе написания этих двух статей. В нем делается попытка учесть общие ошибки, случающиеся как в простых, так и в интеллектуальных указателях СОМ. Класс интеллектуальных указателей, SmartInterface, имеет два шаблонных (template) параметра: тип интерфейса в C++ и указатель на соответствующий IID. Все обращения к методам IUnknown скрыты путем перегрузки операторов:
#include "smartif.h" void TryToSnoreAndIgnore(/* [in] */ IUnknown *pUnk) { // copy constructor calls QueryInterface // конструктор копирования вызывает QueryInterface SmartInterface<IPug, &IID_IPug> pPug = pUnk; if (pPug) // typecast operator returns null-ness // оператор приведения типа возвращает нуль pPug->Snore(); // operator-> returns safe raw ptr // оператор -> возвращает прямой указатель // copy constructor calls QueryInterface // конструктор копирования вызывает QueryInterface SmartInterface<ICat, &IID_ICat> pCat = pUnk; if (pCat) // typecast operator returns null-ness // оператор приведения типа возвращает нуль pCat->IgnoreMaster(); // operator-> returns safe raw ptr // оператор -> возвращает прямой указатель // destructors release held pointers on leaving scope // деструкторы освобождают удерживаемые указатели при // выходе из области действия }
Интеллектуальные указатели выглядят очень привлекательными на первый взгляд, но могут оказаться очень опасными, так как погружают программиста в дремотное состояние; будто бы ничего страшного, относящегося к СОМ, произойти не может. Интеллектуальные указатели действительно решают реальные проблемы, особенно связанные с исключениями; однако при неосторожном употреблении они могут внести столько же дефектов, сколько они предотвращают. Например, многие интеллектуальные указатели позволяют вызывать любой метод интерфейса через оператор интеллектуального указателя ->. К сожалению, это позволяет клиенту вызывать Release с помощью этого оператора-стрелки без сообщения базовому интеллектуальному указателю о том, что его автоматический вызов Release в его деструкторе теперь является излишним и недопустимым.
1
Эти статьи можно найти на сайтах и .
Методы и их результаты
Результаты методов — это одна из сторон СОМ, где логический и физический миры расходятся. В сущности, все методы СОМ физически возвращают номер ошибки с типом НRESULT. Использование одного типа возвращаемого результата позволяет удаленной COM-архитектуре перегружать результат выполнения метода, а также сообщать об ошибках соединения, просто зарезервировав ряд величин для RPC-ошибок. Величины НRESULT представляют собой 32-битные целые числа, которые передают в вызывающий контекст выполнения информацию о типе ошибок, которые могут произойти (например, ошибки сети, сбои сервера). Во многих языках, поддерживающих СОМ (например, Visual Basic, Java), HRESULT-значения перехватываются контекстом выполнения или виртуальной машиной и преобразуются в программные исключения (programmatic exceptions).

Как показано на рис. 2.2, HRESULT-значения состоят из трех битовых полей: бита серьезности ошибки (severity bit), кода устройства и информационного кода. Бит серьезности ошибки показывает, успешно выполнена операция или нет, код устройства индицирует, к какой технологии относится HRESULT, а информационный код представляет собой точный результат в рамках заданной технологии и серьезности. Заголовки SDK (software development kit - набор инструментальных средств разработки программного обеспечения) определяют два макроса, облегчающие работу с HRESULT:
#define SUCCEEDED(hr) (long(hr) >= 0) #def1ne FAILED(hr) (long(hr) < 0)
Эти два макроса используют тот факт, что при трактовке НRESULT как целого числа со знаком бит серьезности ошибки он является также знаковым битом.
Заголовки SDK содержат определения всех стандартных HRESULT. Эти HRESULT имеют символические имена, соответствующие трем компонентам HRESULT, и используются в следующем формате:
<facility>_<severity>_<information>
Например, HRESULT с именем STG_S_CONVERTED показывает, что кодом устройства является FACILITY_STORAGE. Это означает, что результат относится к структурированному хранилищу (Structured Storage) или к персистентности (Persistence).
Код серьезности ошибки — SEVERITY_SUCCESS. Это означает, что вызов смог успешно выполнить операцию. Третья составляющая — CONVERTED — означает, что в данном случае было произведено преобразование базового файла для поддержки структурированного хранилища. HRESULT-значения, являющиеся универсальными и не привязанными к определенной технологии, используют FACILITY_NULL, и их символическое имя не содержит префикса кода устройства. Вот некоторые стандартные имена HRESULT-значений с кодом FACILITY_NULL:
S_OK - успешная нормальная операция S_FALSE - используется для возвращения логического false в случае успеха E_FAIL - общий сбой E_NOTIMPL - метод не реализован E_UNEXPECTED - метод вызван в неподходящее время
FACILITY_ITF используется в специфически интерфейсных HRESULT-значениях и является в то же время единственным допустимым кодом устройства для HRESULT, определяемых пользователем. При этом значения FACILITY_ITF должны быть уникальными в контексте каждого отдельного интерфейса. Стандартные заголовки определяют макрос MAKE_HRESULT для определения пользовательского HRESULT из трех необходимых полей:
const HRESULT CALC_E_IAMHOSED = MAKE_HRESULT(SEVERITY_ERROR, FACILITY_ITF, 0х200 + 15);
Для пользовательских HRESULT принято соглашение, что значения информационного кода должны превышать 0х200, чтобы избежать повторного использования значений, уже задействованных в системных HRESULT-значениях. Хотя это не опасно, таким образом предотвращается повторное использование значений, уже имеющих смысл для стандартных интерфейсов. Например, большинство HRESULT имеют текстовые описания для пользователя, которые можно получить на этапе выполнения с помощью функции API FormatMessage. Выбор HRESULT, не пересекающихся со значениями, определенными в системе, служит гарантией того, что неверные сообщения об ошибках не будут получены.
Чтобы позволить методам возвращать логический результат, не имеющий отношения к их физическому HRESULT-значению, язык СОМ IDL поддерживает атрибут параметров retval.
Атрибут retval показывает, что соответствующий параметр физического метода в действительности является логическим результатом операции и, если контекст это позволяет, должен быть представлен как результат операции. Рассмотрим IDL-описание следующего метода:
HRESULT Method2([in] short arg1, [out, retval] short *parg2);
на языке Java это соответствует:
public short Method2(short arg1);
в то время как Visual Basic дает такое описание метода:
Function Method2(arg1 as Integer) As Integer
Поскольку C++ не использует поддержку контекста выполнения для обращения к СОМ-интерфейсам, представление этого метода в Microsoft C++ имеет вид:
virtual HRESULT _stdcall Method2(short arg1, short *parg2) = 0;
Это значит, что следующий клиентский код на языке C++:
short sum = 10; short s; HRESULT hr = pItf->Method2(20, &s); if (FAILED(hr)) throw hr; sum += s;
примерно эквивалентен такому Java-коду:
short sum == 10; short s = Itf.Method2(20); sum += s;
Если HRESULT, возвращенный методом, сообщает об аварийном результате, то Java Virtual Machine преобразует HRESULT в исключение Java. Во фрагменте кода на языке C++ необходимо проверить вручную HRESULT, возвращенный этим методом, и соответствующим образом обработать этот аварийный результат.
Оптимизация QueryInterface
Фактически реализация QueryInterface, показанная ранее в этой главе, очень проста и легко может поддерживаться любым программистом, имеющим хоть некоторое представление о СОМ и C++. Тем не менее, многие среды и каркасы приложений поддерживают реализацию, управляемую данными. Это помогает достичь большей расширяемости и эффективности благодаря уменьшению размера кода. Такие реализации предполагают, что каждый совместимый с СОМ класс предусматривает таблицу, которая отображает каждый поддерживаемый IID на какой-нибудь аспект объекта, используя фиксированные смещения или какие-то другие способы. В сущности, реализация QueryInterface, приведенная ранее в этой главе, строит таблицу, основанную на скомпилированном машинном коде для каждого из последовательных операторов if, а фиксированные смещения вычисляются с использованием оператора static_cast (static_cast просто добавляет смещение базового класса, чтобы найти совместимый с типом указатель vptr).
Чтобы реализовать управляемый таблицей QueryInterface, необходимо сначала определить, что эта таблица будет содержать. Как минимум, каждый элемент таблицы должен содержать указатель на IID и некое дополнительное состояние, которое позволит реализации найти указатель vptr объекта для запрошенного интерфейса. Хранение указателя функции в каждом элементе таблицы придаст этому способу максимальную гибкость, так как это даст возможность добавлять новые методики поиска интерфейсов к обычному вычислению смещения, которое используется для приведения к базовому классу. Исходный код в приложении к данной книге содержит заголовочный файл inttable.h, который определяет элементы таблицы интерфейсов следующим образом:
// inttable.h (book-specific header file) // inttable.h (заголовочный файл, специфический для этой книги) // typedef for extensibility function // typedef для функции расширяемости
typedef HRESULT (*INTERFACE_FINDER) (void *pThis, DWORD dwData, REFIID riid, void **ppv);
// pseudo-function to indicate entry is just offset // псевдофункция для индикации того, что запись просто // является смещением
#define ENTRY_IS_OFFSET INTERFACE_FINDER(-1) // basic table layout // представление базовой таблицы
typedef struct INTERFACE_ENTRY { const IID * pIID; // the IID to match // соответствующий IID INTERFACE_FINDER pfnFinder; // функция finder DWORD dwData; // offset/aux data // данные по offset/aux } INTERFACE_ENTRY;
Заголовочный файл также содержит следующие макросы для создания интерфейсных таблиц внутри определения класса:
// Inttable.h (book-specific header file) // Inttable.h (заголовочный файл, специфический для данной книги)
#define BASE_OFFSET(ClassName, BaseName) \ (DWORD(static_cast<BaseName*>(reinterpret_cast\ <ClassName*>(0x10000000))) - 0х10000000)
#define BEGIN_INTERFACE_TABLE(ClassName) \ typedef ClassName _ITCls;\ const INTERFACE_ENTRY *GetInterfaceTable(void) {\ static const INTERFACE_ENTRY table [] = {\
#define IMPLEMENTS_INTERFACE(Itf) \ {&IID_##Itf,ENTRY_IS_OFFSET,BASE_OFFSET(_ITCls,Itf)},
#define IMPLEMENTS_INTERFACE_AS(req, Itf) \ {&IID_##req,ENTRY_IS_OFFSET, BASE_OFFSET(_ITCls, Itf)},
#define END_INTERFACE_TABLE() \ { 0, 0, 0 } }; return table; }
Все, что требуется, — это стандартная функция, которая может анализировать интерфейсную таблицу в ответ на запрос QueryInterface. Такая функция содержится в файле Inttable.h:
// inttable.cpp (book-specific source file) // inttable.h (заголовочный файл, специфический для данной книги) HRESULT InterfaceTableQueryInterface(void *pThis, const INTERFACE_ENTRY *pTable, REFIID riid, void **ppv) { if (InlineIsEqualGUID(riid, IID_IUnknown)) { // first entry must be an offset // первый элемент должен быть смещением *ppv = (char*)pThis + pTable->dwData; ((Unknown*) (*ppv))->AddRef () ; // A2 return S_OK; } else { HRESULT hr = E_NOINTERFACE; while (pTable->pfnFinder) { // null fn ptr == EOT if (!pTable->pIID InlineIsEqualGUID(riid,*pTable->pIID)) { if (pTable->pfnFinder == ENTRY_IS_OFFSET) { *ppv = (char*)pThis + pTable->dwData; ((IUnknown*)(*ppv))->AddRef(); // A2 hr = S_OK; break; } else { hr = pTable->pfnFinder(pThis, pTable->dwData, riid, ppv); if (hr == S_OK) break; } } pTable++; } if (hr != S_OK) *ppv = 0; return hr; } }
Получив указатель на запрошенный объект, InterfaceTableQueryInterface сканирует таблицу в поисках элемента, соответствующего запрошенному IID, и либо добавляет соответствующее смещение, либо вызывает соответствующую функцию. Приведенный выше код использует усовершенствованную версию IsEqualGUID, которая генерирует несколько больший код, но результаты по скорости примерно на 20-30 процентов превышают данные по существующей реализации, которая не управляется таблицей. Поскольку код для InterfaceTableQueryInterface появится в исполняемой программе только один раз, это весьма неплохой компромисс.
Очень легко автоматизировать поддержку СОМ для любого класса C++, основанную на таком табличном управлении, простым использованием С-препроцессора. Следующий фрагмент из заголовочного файла impunk.h определяет QueryInterface, AddRef и Release для объекта, использующего интерфейсные таблицы и расположенного в динамически распределяемой области памяти:
// impunk.h (book-specific header file) // impunk.h (заголовочный файл, специфический для данной книги) // AUTO_LONG is just a long that constructs to zero // AUTO_LONG - это просто long, с конструктором, // устанавливающим значение в О
struct AUTO_LONG { LONG value; AUTO_LONG (void) : value (0) {} };
#define IMPLEMENT_UNKNOWN(ClassName) \ AUTO_LONG m_cRef;\ STDMETHODIMP QueryInterface(REFIID riid, void **ppv){\ return InterfaceTableQueryInterface(this,\ GetInterfaceTable(), riid, ppv);\ }\ STDMETHODIMP_(ULONG) AddRef(void) { \ return InterlockedIncrement(&m_cRef.value); \ }\ STDMETHODIMP_(ULONG) Release(void) {\ ULONG res = InterlockedDecrement(&m_cRef.value) ;\ if (res == 0) \ delete this;\ return res;\ }\
Настоящий заголовочный файл содержит дополнительные макросы для поддержки объектов, не находящихся в динамически распределяемой области памяти.
Для реализации примера PugCat, уже встречавшегося в этой главе, необходимо всего лишь удалить текущие реализации QueryInterface, AddRef и Release и добавить соответствующие макросы:
class PugCat : public IPug, public ICat { protected: virtual ~PugCat(void); public: PugCat(void); // IUnknown methods // методы IUnknown IMPLEMENT_UNKNOWN (PugCat) BEGIN_INTERFACE_TABLE(PugCat) IMPLEMENTS_INTERFACE(IPug) IMPLEMENTS_INTERFACE(IDog) IMPLEMENTS_INTERFACE_AS(IAnimal,IDog) IMPLEMENTS_INTERFACE(ICat) END_INTERFACE_TABLE() // IAnimal methods // методы IAnimal STDMETHODIMP Eat(void); // IDog methods // методы IDog STDMETHODIMP Bark(void); // IPug methods // методы IPug STDMETHODIMP Snore(void); // ICat methods // методы ICat STDMETHODIMP IgnoreMaster(void); };
Когда используются эти макросы препроцессора, для поддержки IUnknown не требуется никакого дополнительного кода. Все, что осталось сделать, это реализовать текущие методы интерфейса, которые делают этот класс уникальным.
Приведение типов и IUnknown
В предыдущей главе обсуждалось, почему необходимо определять тип на этапе выполнения в динамически собранной системе. Язык C++ предусматривает разумный механизм для динамического определения типа с помощью оператора dynamic_cast. Хотя эта языковая возможность имеет собственную реализацию для каждого компилятора, в предыдущей главе было предложено средство урегулирования этого — добавление к каждому интерфейсу явного метода, являющегося семантическим эквивалентом dynamic_cast. Ниже приводится IDL-описание QueryInterface:
HRESULT QueryInterface([in] REFIID riid, [out] void **ppv);
Первый параметр (riid) является физическим именем запрошенного интерфейса. Второй параметр (ppv) указывает на переменную интерфейсного указателя, которая в случае успешного завершения будет содержать запрошенный указатель на интерфейс.
В ответ на запрос QueryInterface, если объект не поддерживает запрошенный тип интерфейса, он должен возвратить E_NOINTERFACE после установки *ppv в нулевое значение. Если же объект поддерживает запрошенный интерфейс, он должен перезаписать *ppv указателем запрошенного типа и возвратить HRESULT S_OK. Поскольку ppv является [out]-параметром, реализация QueryInterface должна выполнить AddRef для возвращаемого указателя перед тем, как вернуть управление вызывающему объекту (см. в этой главе выше руководящий принцип А2). Этот вызов AddRef должен быть согласован с вызовом Release со стороны клиента. Следующий код показывает динамическое определение типа с использованием оператора C++ dynamic_cast на примере иерархии типов Dog/Cat, описанного ранее в данной главе:
void TryToSnoreAndIgnore(/* [in] */ IUnknown *pUnk) { IPug *pPug = 0; pPug = dynamic_cast<IPug*> (pUnk); if (pPug) // the object is Pug-compatible // объект совместим с Pug pPug->Snore(); ICat *pCat = 0; pCat = dynamic_cast<ICat*>(pUnk); if (pCat) // the object is Cat-compatible // объект совместим с Cat pCat-> IgnoreMaster(); }
Если объект, переданный этой функции, совместим одновременно с ICat и с IDog, то задействованы обе функциональные возможности.
Если же объект в действительности не совместим с ICat или с IDog, то данная функция просто проигнорирует пропущенный аспект объекта (или оба аспекта сразу). Ниже показан семантически эквивалентный вариант с использованием QueryInterface:
void TryToSnoreAndIgnore(/* [in] */ IUnknown *pUnk) { HRESULT hr; IPug *pPug = 0; hr = pUnk->QueryInterface(IID_IPug, (void**)&pPug); if (SUCCEEDED(hr)) { // the object is Pug-compatible // объект совместим с Pug pPug->Snore(); pPug->Release(); // R2 }
ICat *pCat = 0; hr = pUnk->QueryInterface(IID_ICat, (void**)&pCat); if (SUCCEEDED(hr)) { // the object is Cat-compatible // объект совместим с Cat pCat->IgnoreMaster(); pCat->Release(); // R2 } }
Хотя имеются очевидные различия в синтаксисе, единственная существенная разница между двумя приведенными фрагментами кода состоит в том, что вариант, основанный на QueryInterface, подчиняется правилам подсчета ссылок СОМ.
Есть несколько тонкостей, связанных с QueryInterface и его употреблением. Метод QueryInterface может возвращать указатели только на тот же самый СОМ-объект, для которого он вызван. Глава 4 посвящена объяснению каждого нюанса этого оператора. Полезно, однако, отметить уже сейчас, что клиент не должен трактовать AddRef и Release как операции с объектом. Вместо этого следует рассматривать их как операции с указателем интерфейса. Это означает, что нижеследующий код ошибочен:
void BadCOMCode(/*[in]*/ IUnknown *pUnk) { ICat *pCat = 0; IPug *pPug = 0; HRESULT hr; hr = pUnk->QueryInterface(IID_ICat, (void**)&pCat); if (FAILED(hr)) goto cleanup; hr = pUnk->QueryInterface(IID_IPug, (void**)&pPug); if (FAILED(hr)) goto cleanup; pPug->Bark(); pCat->IgnoreMaster(); cleanup: if (pCat) pUnk->Release(); // pCat got AddRefed in QI // pCat получил AddRef в QI if (pPug) pUnk->Release(); // pDog got AddRefed in QI // pDog получил AddRef в QI }
Несмотря на то что все три указателя: pCat, pPug и pUnk — указывают на тот же самый объект, клиент не имеет права компенсировать AddRef, который происходит для pCat и pPug при вызове QueryInterface, вызовами Release для pUnk.
Правильный вариант этого кода такой:
cleanup: if (pCat) pCat->Release(); // use AddRefed ptr // используем указатель AddRef if (pPug) pPug->Release(); // use AddRefed ptr // используем указатель AddRef
Здесь Release вызывается для того же интерфейсного указателя, для которого и AddRef (что произошло неявно, когда указатель был возвращен из QueryInterface). Это требование предоставляет разработчику значительную гибкость при реализации объекта. Например, объект может решить подсчитывать ссылки на каждый интерфейс, чтобы активным образом использовать ресурсы, которые обычно используются одним определенным интерфейсом на объект.
Еще одна тонкость относится ко второму параметру QueryInterface, имеющему тип void**. Весьма забавно то, что QueryInterface, являющийся основой системы типов СОМ, имеет довольно сомнительный в смысле типа аналог в C++:
HRESULT _stdcall QueryInterface(REFIID riid, void** ppv);
Как было отмечено ранее, клиенты вызывают QueryInterface, передавая объекту указатель на интерфейсный указатель в качестве второго параметра вместе с IID, который определяет тип ожидаемого интерфейсного указателя:
IPug *pPug = 0; hr = punk->QueryInterface(IID_IPug, (void**)&pPug);
К сожалению, для компилятора C++ таким же правильным выглядит и следующее:
IPug *pPug = 0; hr = punk->QueryInterface(IID_ICat, (void**)&pPug);
Даже еще более хитроумный вариант компилируется без ошибок:
IPug *pPug = 0; hr = punk->QueryInterface(IID_IPug, (void**)pPug);
Исходя из того, что правила наследования неприменимы к указателям, такое альтернативное определение QueryInterface нe облегчает проблему:
HRESULT QueryInterface(REFIID riid, IUnknown** ppv);
так как неявное приведение типа к родительскому типу (upcasting) применимо только к объектам и указателям на объекты, а не к указателям на указатели на объекты:
IDerived **ppd; IBase **ppb = ppd; // illegal // неверно
To же ограничение применимо в равной мере и к ссылкам на указатели. Следующее альтернативное определение вряд ли более удобно для использования клиентами:
HRESULT QueryInterface(const IID& riid, void* ppv);
так как позволяет клиентам отказаться от приведения типа (cast). К сожалению, это решение не уменьшает количества ошибок (обе из предшествующих ошибок все еще возможны), а устраняя необходимость приведения, уничтожает и видимый индикатор того, что устойчивость типов C++ может оказаться в опасности. Если желательна семантика QueryInterface, то выбор типов аргументов, сделанный корпорацией Microsoft, по крайней мере, разумен, если не надежен или изящен. Простейший путь избежать ошибок, связанных c QueryInterface,— это всегда быть уверенным в том, что IID соответствует типу указателя интерфейса, который проходит как второй параметр QueryInterface. На самом деле первый параметр QueryInterface описывает "форму" типа указателя второго параметра. Их связь может быть усилена на этапе компиляции с помощью такого макроса предпроцессора С:
#define IID_PPV_ARG(Type, Expr) IID_##type, \ reinterpret_cast<void**>(static_cast<Type **>(Expr))
С помощью этого макроса компилятор будет уверен в том, что выражение, использованное в приведенном ниже вызове QueryInterface, имеет правильный тип и что используется соответствующий уровень изоляции (indirecton):
IPug *pPug = 0; hr = punk->QueryInterface(IID_PPV_ARG(IPug, &pPug));
Этот макрос закрывает брешь, вызванную параметром void**, без каких-либо затрат на этапе выполнения.
1Который в значительной мере инспирирован дискуссией между автором и Tye McQueen во время семинара по СОМ.
Реализация IUnknown
Имея описанные выше образцы клиентского использования, легко видеть, как реализовать методы IUnknown. Примем предложенную выше иерархию типов Dog/Cat. Чтобы определить С++-класс, который реализует интерфейсы IPug и ICat, нужно просто добавить к списку базовых классов самые последние в иерархии наследования версии интерфейсов:
class PugCat : public IPug, public ICat
При использовании наследования компилятор C++ обеспечивает совместимость двоичного представления производного класса с каждым базовым классом. Для класса PugCat это означает, что все объекты PugCat будут содержать указатель vptr, указывающий на таблицу vtbl, совместимую с IPug. Объекты PugCat также будут содержать указатель vptr, указывающий на вторую таблицу vtbl, совместимую с ICat. Рисунок 2.5 показывает, как интерфейсы в качестве базовых классов соотносятся с представлением объектов.
Поскольку все функции-члены в СОМ-определениях интерфейса являются чисто виртуальными, производный класс должен обеспечивать реализацию каждого метода, имеющегося в любом из его интерфейсов. Методы, общие для двух или более интерфейсов (например, QueryInterface, AddRef и т. д.) нужно реализовывать только один раз, так как компилятор и компоновщик инициализируют все таблицы vtbl так, чтобы они указывали на одну реализацию метода. Таков естественный побочный эффект от использования множественного наследования в языке C++.

Следующий код является определением класса, которое создает объекты, поддерживающие интерфейсы IPug и ICat:
class PugCat : public IPug, public ICat { LONG m_cRef; protected: virtual ~PugCat(void); public: PugCat(void); // IUnknown methods // методы IUnknown STDMETHODIMP QueryInterface(REFIID riid, void **ppv); STDMETHODIMP_(ULONG) AddRef(void); STDMETHODIMP_(ULONG) Release(void); // IAnimal methods // методы IAnimal STDMETHODIMP Eat(void); // IDog methods // методы IDog STDMETHODIMP Bark(void); // IPug methods // методы IPug STDMETHODIMP Snore(void); // ICat methods // методы ICat STDMETHODIMP IgnoreMaster(void); };
Отметим, что в классе должен быть реализован каждый метод, определенный в любом интерфейсе, от которого он наследует, так же, как и каждый метод, определенный в любых производных (implied) базовых интерфейсах (например, IDog, IAnimal). Для создания стековых фреймов, совместимых с СОМ, необходимо использовать макросы STDMETHODIMP и STDMETHODIMP_. При ориентации на платформы Win32, использующие компилятор Microsoft C++, заголовки SDK определяют эти два макроса следующим образом:
#define STDMETHODIMP HRESULT _stdcall #define STDMETHODIMP_(type) type _stdcall
Заголовочные файлы SDK также определяют макросы STDMETHOD и STDMETHOD_, которые можно использовать при определении интерфейсов без IDL-компилятора. В серийно выпускаемом программировании на СОМ эти два макроса не нужны.
Реализация AddRef и Release чрезвычайно прозрачна. Элемент данных m_cRef отслеживает, сколько неосвобожденных интерфейсных указателей удерживают объект. Конструктор класса приводит счетчик ссылок в нулевое состояние:
PugCat::PugCat(void) : m_cRef(0) // initialize reference count to zero // устанавливаем счетчик ссылок в нуль { }
Реализация AddRef в классе фиксирует путем увеличения счетчика ссылок, что вызывающий объект продублировал указатель интерфейса. Измененное значение счетчика ссылок возвращается для целей диагностики:
STDMETHODIMP_(ULONG) AddRef(void) { return ++m_cRef; }
Реализация Release фиксирует уничтожение указателя интерфейса простым уменьшением счетчика ссылок, а также производит соответствующее действие, когда счетчик ссылок достигает нуля. Для объектов, находящихся в динамически распределяемой области памяти, это означает вызов оператора delete для уничтожения объекта:
STDMETHODIMP_(ULONG) Release(void) { LONG res = --m_cRef; if (res == 0) delete this; return res; }
Для кэширования обновленного счетчика ссылок необходимо использовать временную переменную, так как нельзя обращаться к элементам данных объекта после того, как объект уже уничтожен.
Заметим, что показанные реализации Addref и Release используют собственные операторы инкремента и декремента (увеличения и уменьшения на единицу).
Для простой реализации это весьма разумно, так как СОМ не допускает более одного потока для обращения к объекту до тех пор, пока конструктор не обеспечит явный многопоточный доступ (почему и как конструктор сделает это, подробно описано в главе 5). В случае объектов, доступных в многопоточной среде, для автоматического подсчета ссылок следует использовать подпрограммы Win32 InterlockedIncrement/InterlockedDecrement:
STDMETHODIMP_(ULONG) AddRef(void) { return InterlockedIncrement(&m_cRef); }
STDMETHODIMP_(ULONG) Release(void) { LONG res = InterlockedDecrement(&m_cRef); if (res == 0) delete this; return res; }
Этот код несколько менее эффективен, чем версии, использующие собственные операторы C++. Но, вообще говоря, разумнее использовать менее эффективные варианты InterlockedIncrement / InterlockedDecrement, так как известно, что они надежны во всех ситуациях и освобождают разработчика от необходимости сохранять две версии практически одинакового кода.
Показанные выше реализации AddRef и Release предполагают, что объект может размещаться только в динамически распределяемой области памяти (в "куче") с использованием С++-оператора new. В определении класса деструктор сделан защищенной операцией для обеспечения того, чтобы ни один экземпляр класса не был определен никаким другим способом. Однако иногда желательно иметь объекты, не размещенные в «куче». Для этих объектов вызов delete в последнем вызове Release был бы гибельным. Так как единственной причиной для того, чтобы объект в первую очередь поддерживал счетчик ссылок, была необходимость вызова delete this, допустимо оптимизировать счетчик ссылок для объектов, не содержащихся в динамически распределяемой области памяти:
STDMETHODIMP_(ULONG) GlobalVar::AddRef(void) { return 2; // any non-zero value is legal // допустима любая ненулевая величина }
STDMETHODIMP_(ULONG) GlobalVar::Release (void) { return 1; // any non-zero value is legal // допустима любая ненулевая величина }
Эта реализация использует тот факт, что результаты AddRef и Release служат только для сведения и не обязаны быть точными.
При наличии реализации AddRef и Release единственным еще не реализованным методом из IUnknown остается QueryInterface. Его реализации должны отслеживать иерархию типов объекта и использовать статические приведения типов для возврата правильного типа указателя для всех поддерживаемых интерфейсов. Для определения класса PugCat, рассмотренного ранее, следующий код является корректной реализацией QueryInterface:
STDMETHODIMP PugCat::QueryInterface(REFIID riid, void **ppv) { assert(ppv != 0); // or return E_POINTER in production // или возвращаем E_POINTER в реальный продукт if (riid == IID_IPug) *ppv = static_cast<IPug*>(this); else if (riid == IID_IDog) *ppv = static_cast<IDog*>(this); else if (riid == IID_IAnimal) // cat or pug? // кот или мопс? *ppv == static_cast<IDog*>(this); else if (riid == IID_IUnknown) // cat or pug? // кот или мопс? *ppv = static_cast<IDog*>(this); else if (riid == IID_ICat) *ppv = static_cast<ICat*>(this); else { // unsupported interface // неподдерживаемый интерфейс *ppv = 0; return E_NOINTERFACE; } // if we reach this point, *ppv is non-null // and must be AddRef'ed (guideline A2) // если мы дошли до этого места, то *ppv ненулевой // и должен быть обработан AddRef'ом ( принцип A2) reinterpret_cast<IUnknown*>(*ppv)->AddRef(); return S_OK; }
Использование static_cast более предпочтительно, чем традиционные приведения типа в стиле С:
*ppv = (IPug*)this;
так как вариант static_cast вызовет ошибку этапа компиляции, если произведенное приведение типа не согласуется с существующим базовым классом.
Заметим, что в показанной здесь реализации QueryInterface при запросе на интерфейс, поддерживающийся более чем одним базовым интерфейсом (например, IUnknown, IAnimal) приведение типа должно явно выбрать более определенный базовый класс. Например, для класса PugCat такой вполне безобидно выглядящий код не откомпилируется:
if (riid == IID_IUnknown) *ppv = static_cast<IUnknown*>(this);
Этот код не пройдет компиляцию, поскольку такое приведение типа является неоднозначным и может соответствовать более чем одному базовому классу.
Это было показано в случае FastString и IExtensibleObject из предыдущей главы. Вместо этого реализация должна более точно выбрать тип для приведения:
if (riid == IID_IUnknown) ppv = static_cast<IDog*>(this);
или
if (riid == IID_IUnknown) ppv = static_cast<ICat*>(this);
Каждый из этих двух фрагментов кода допустим для реализации PugCat. Первый вариант предпочтительнее, так как многие компиляторы выдают несколько более эффективный код, когда использован крайний левый базовый класс.
1Входы в таблицу vtbl для крайнего левого базового класса не требуют, чтобы «переходник» установщика (adjuster thunk) устанавливал указатель this перед вхождением в реализацию метода. Это применимо только к компиляторам, которые используют «переходники» установщика и располагают крайний левый базовый класс в самом верху расположения объекта. Компилятор Microsoft C++ удовлетворяет этому описанию.
Снова об интерфейсах и реализациях
Цель отделения интерфейса от реализации заключалась в сокрытии от клиента всех деталей внутренней работы объекта. Этот фундаментальный принцип предусматривал уровень косвенности, или изоляции (level of indirection), который позволял изменяться количеству или порядку элементов данных в реализации класса без перекомпиляции клиента. Кроме того, этот принцип позволял клиентам обнаруживать расширенную функциональность путем опроса объекта на этапе выполнения. И, наконец, этот принцип позволяет сделать библиотеку DLL независимой от транслятора C++, который используется клиентом.
Хотя этот последний аспект и полезен, он далеко не достаточен для обеспечения универсальной основы для двоичных компонентов. Важно отметить, что хотя клиенты могут использовать любой выбранный ими транслятор C++, в конечном счете это будет всего лишь транслятор C++. Приемы, описанные в предыдущей главе, обеспечивают независимость от транслятора. В конце концов, главное, что необходимо для создания действительно универсальной основы для двоичных компонентов, — это независимость от языка. А чтобы достичь независимости от языка, принцип отделения интерфейса от реализации должен быть применен еще раз.
Рассмотрим определения интерфейса, использованные в предыдущей главе. Каждое определение интерфейса принимало форму определения абстрактного базового класса C++ в заголовочном файле C++. Тот факт, что определение интерфейса постоянно находится в файле, читаемом только на одном языке, вскрывает один остаточный признак реализации этого объекта — язык, на котором он был написан. Но, в конечном счете, объект должен быть доступен для любого языка, а не только для того, который выбрал разработчик объекта. Предусматривая только совместимое с C++ определение интерфейса, разработчик объекта тем самым вынуждает всех использующих этот объект также работать на C++.
Хотя C++ — чрезвычайно полезный язык программирования, существует множество областей программирования, где больше подходят другие языки. Но точно так же, как проблемы совместимости при компоновке можно решить путем обеспечения всех существующих компиляторов файлами определения модуля, возможно и перевести определение интерфейса с C++ на любые другие языки программирования.
А так как двоичная сигнатура интерфейса есть просто сочетание vptr/vtbl, этот перевод может быть сделан для большой группы языков.
Проделывание этих языковых преобразований данных для всех известных интерфейсов потребовало бы огромного количества работы, а главное — невозможно успевать делать это для бурного потока языков программирования, которые индустрия программного обеспечения не устает изобретать чуть ли не каждую декаду. Идеально было бы написать сервисную программу, которая переводила бы определения класса C++ в некую абстрактную промежуточную форму. Из этой промежуточной формы такая программа могла бы преобразовывать данные для любого языка программирования, имеющего соответствующий выходной генератор (back-end generator). По мере того как новые языки приобретают значимость, могли бы добавляться новые выходные генераторы, и все ранее определенные интерфейсы смогли бы тотчас использоваться в совершенно новом контексте.
К сожалению, язык программирования C++ полон неоднозначностей, что делает его малопригодным для преобразования данных на все мыслимые языки. Многие из этих неоднозначностей приводят к неопределенным соотношениям между указателями, памятью и массивами. Это не является проблемой, когда оба объекта: вызывающий (caller) и вызываемый (callee) — скомпилированы на С или на C++, но они не могут быть точно переведены на другие языки без дополнительной квалификации. Поэтому, чтобы устранить зависимость определения интерфейса от языка, используемого в какой-либо конкретной реализации, необходимо для определений интерфейсов использовать один язык, а для определений реализации — другой. Если все участники договорятся о едином языке для определений интерфейсов, то станет возможным определить интерфейс однажды и получать по мере необходимости новые представления реализации на специфических языках. СОМ предусматривает язык, который основан на хорошо известном синтаксисе С, но добавляет возможность при переводе на другие языки корректно устранить неоднозначность любых особенностей языка С.Этот язык называется языком описаний интерфейса (Interface Definition Language — IDL).
Типы данных
Все интерфейсы СОМ должны быть определены в IDL. IDL позволяет описывать довольно сложные типы данных в стиле, не зависящем от языка и платформы. Рисунок 2.6 показывает базовые типы, которые поддерживаются IDL, и их отображения в языки С, Java и Visual Basic. Целые и вещественные типы не требуют объяснений. Первые "интересные" типы данных, встречающиеся при программировании в СОМ, — это символы и строки.
Язык
IDL
Microsoft C++
Visual Basic
Microsoft Java
| Основные типы | boolean | unsigned char | unsupported | char |
| byte | unsigned char | unsupported | char | |
| small | char | unsupported | char | |
| short | short | Integer | short | |
| long | long | Long | int | |
| hyper | _int64 | unsupported | long | |
| float | float | Single | float | |
| double | double | Double | double | |
| char | unsigned char | unsupported | char | |
| wchar_t | wchar_t | Integer | short | |
| enum | enum | Enum | int | |
| Interface Pointer | Interface Pointer | Interface Ref. | Interface Ref. | |
| Расширенные типы | VARIANT | VARIANT | Variant | ms.com.Variant |
| BSTR | BSTR | String | java.lang.String | |
| VARIANT_BOOL | short [-1/0] | Boolean [True/False] | boolean [true/false] |
Рис. 2.6. Базовые типы СОМ
Все символы в СОМ представлены с использованием типа данных OLECHAR. Для Windows NT, Windows 95, Win32s и Solaris OLECHAR — это просто typedef для типа данных С wchar_t. Специфика других платформ описана в соответствующих документациях. Платформы Win32 используют тип данных wchar_t для представления 16-битных символов Unicode. Поскольку типы указателей в IDL созданы так, что указывают на одиночные переменные, а не на массивы, то IDL вводит атрибут [string], чтобы подчеркнуть, что указатель указывает на массив-строку с завершающим нулем:
HRESULT Method([in, string] const OLECHAR *pwsz);
Для определения строк и символов, совместимых с OLECHAR, в СОМ введен макрос OLESTR, который приписывает букву L перед строковой или символьной константой, информируя таким образом компилятор о том, что эта константа имеет тип wchar_t. Например, правильным будет такой способ инициализировать указатель OLECHAR с помощью строкового литерала:
const OLECHAR *pwsz = OLESTR("Hello");
Под Win32 или Solaris это эквивалентно
const wchar_t *pwsz = L"Hello";
Первый вариант предпочтительней, так как он будет надежно компилироваться на всех платформах.
Поскольку часто возникает необходимость копировать строки на основе типа wchar_t в обычные буфера на основе char, то динамическая библиотека С предлагает две процедуры для преобразования типов:
size_t mbstowcs(wchar_t *pwsz, const char *psz, int cch); size_t wcstombs(char *psz, const wchar_t *pwsz, int cch);
Эти две процедуры работают аналогично динамической С-процедуре strncpy, за исключением того, что в эти процедуры как часть операции копирования включено расширение или сужение строки. Следующий код показывает, как параметр метода, размещенный в OLECHAR, можно скопировать в элемент данных, размещенный в char:
class BigDog : public ILabrador { char m_szName[1024] ; public: STDMETHODIMP SetName(/* [in,string]*/ const OLECHAR *pwsz) { HRESULT hr = S_OK; size_t cb = wcstombs(m_szName, pwsz, 1024); // check for buffer overflow or bad conversion // проверяем переполнение буфера или неверное преобразование if (cb == sizeof(m_szName) cb == (size_t)-1) { m_szName[0] = 0; hr = E_INVALIDARG; } return hr; } };
Этот код является довольно простым, хотя программист должен осознавать, что используются два различных типа символов. Несколько более сложный (и чаще встречающийся) случай — преобразование между типами данных OLECHAR и TCHAR из Win32. Так как OLECHAR условно компилируется как char или wchar_t, то при реализации метода необходимо должным образом рассмотреть оба сценария:
class BigDog : public ILabrador { TCHAR m_szName[1024]; // note TCHAR-based string // отметим строку типа TCHAR public: STDMETHODIMP SetName( /*[in,string]*/ const OLECHAR *pwsz) { HRESULT hr = S_OK; #ifdef UNICODE // Unicode build (TCHAR == wchar_t) // конструкция Unicode (TCHAR == wchar_t) wcsncpy(m_szName, pwsz, 1024); // check for buffer overflow // проверка на переполнение буфера if (m_szName[1023] != 0) { m_szName[0] = 0; hr = E_INVALIDARG; } #else // Non-Unicode build (TCHAR == char) // не является конструкцией Unicode (TCHAR == char) size_t cb = wcstombs(m_szName, pwsz, 1024); // check for buffer overflow or bad conversion // проверка переполнения буфера или ошибки преобразования if (cb == sizeof(m_szName) cb == (size_t)-1) { m_szName[0] =0; hr = E_INVALIDARG; } #endif return hr; } };
Очевидно, операции с преобразованиями OLECHAR в TCHAR значительно сложнее. Но, к сожалению, это самый распространенный сценарий при программировании в СОМ на базе Win32.
Одним из подходов к упрощению преобразования текста является применение системы типов C++ и использование перегрузки функций для выбора нужной строковой процедуры, построенной на типах параметров. Заголовочный файл ustring.h из приложения к этой книге содержит семейство библиотечных строковых процедур, аналогичных стандартным библиотечным процедурам С, которые находятся в файле string.h. Например, функция strncpy имеет четыре соответствующих процедуры, зависящие от каждого из параметров, которые могут быть одного из двух символьных типов (wchar_t или char):
// from ustring.h (book-specific header) // из ustring.h (заголовок, специфический для данной книги) inline bool ustrncpy(char *p1, const wchar_t *p2, size_t c) { size_t cb = wcstombs(p1, p2, c); return cb != c && cb != (size_t)-1; };
inline bool ustrncpy(wchar_t *p1, const wchar_t *p2, size_t c) { wcsncpy(p1, p2, c); return p1[c - 1] == 0; };
inline bool ustrncpy(char *p1, const char *p2, size_t c) { strncpy(p1, p2, c); return p1[c - 1] == 0; };
inline bool ustrncpy(wchar_t *p1, const char *p2, size_t c) { size_t cch = mbstowcs(p1, p2, c); return cch != c && cch != (size_t)-1; }
Отметим, что для любого сочетания типов идентификаторов может быть найдена соответствующая перегруженная функция ustrncpy, причем результат показывает, была или нет вся строка целиком скопирована или преобразована. Поскольку эти процедуры определены как встраиваемые (inline) функции, их использование не внесет никаких затрат при выполнении. С этими процедурами предыдущий фрагмент кода станет значительно проще и не потребует условной компиляции:
class BigDog : public ILabrador { TCHAR m_szName[1024]; // note TCHAR-based string // отметим строку типа TCHAR public: STDMETHODIMP SetName(/* [in,string] */ const OLECHAR *pwsz) { HRESULT hr = S_OK; // use book-specific overloaded ustrncpy to copy or convert // используем для копирования и преобразования // перегруженную функцию ustrncpy, специфическую для данной книги if (!ustrncpy(m_szName, pwsz, 1024)) { m_szName[0] = 0; hr = E_INVALIDARG; } return hr; } };
Соответствующие перегруженные функции для процедур strlen, strcpy и strcat также включены в заголовочный файл ustring.h.
Использование перегрузки библиотечных функций для копирования строк из одного буфера в другой, как это показано выше, обеспечивает лучшее качество исполнения, уменьшает размер кода и непроизводительные издержки программиста. Однако часто возникает ситуация, когда одновременно используются СОМ и API-функции Win32, что не дает возможности применить эту технику. Рассмотрим следующий фрагмент кода, читающий строку из элемента редактирования и преобразующий ее в IID:
HRESULT IIDFromHWND(HWND hwnd, IID& riid) { TCHAR szEditText[1024]; // call a TCHAR-based Win32 routine // вызываем TCHAR-процедуру Win32 GetWindowText(hwnd, szEditText, 1024); // call an OLECHAR-based СОМ routine // вызываем OLECHAR-процедуру СОМ return IIDFromString(szEditText, &riid); }
Допуская, что этот код скомпилирован с указанным символом С-препроцессора UNICODE; он работает безупречно, так как TCHAR и OLECHAR являются просто псевдонимами wchar_t и никакого преобразования не требуется. Если же функция скомпилирована с версией Win32 API, не поддерживающей Unicode, то TCHAR является псевдонимом для char, и первый параметр для IIDFromString имеет неправильный тип. Чтобы решить эту проблему, нужно провести условную компиляцию:
HRESULT IIDFromHWND(HWND hwnd, IID& riid) { TCHAR szEditText[1024]; GetWindowText(hwnd, szEditText, 1024); #ifdef UNICODE return IIDFromString(szEditText, &riid); #else OLECHAR wszEditText[l024]; ustrncpy(wszEditText, szEditText, 1024); return IIDFromString(wszEditText, &riid); #endif }
Хотя этот фрагмент и генерирует оптимальный код, очень утомительно применять эту технику всякий раз, когда символьный параметр имеет неверный тип. Можно справиться с этой проблемой, если использовать промежуточный (shim) класс с конструктором, принимающим в качестве параметра любой тип символьной строки. Этот промежуточный класс должен также содержать в себе операторы приведения типа, что позволит использовать его в обоих случаях: когда ожидается const char * или const wchar_t *.
В этих операциях приведения промежуточный класс либо выделяет резервный буфер и производит необходимое преобразование, либо просто возвращает исходную строку, если преобразования не требовалось. Деструктор промежуточного класса может затем освободить все выделенные буферы. Заголовочный файл ustring.h содержит два таких промежуточных класса: _U и _UNCC. Первый предназначен для нормального использования; второй используется с функциями и методами, тип аргументов которых не включает спецификатора const (таких как IIDFromString). При возможности применения двух промежуточных классов предыдущий фрагмент кода может быть значительно упрощен:
HRESULT IIDFromHWND(HWND hwnd, IID& riid) { TCHAR szEditText[1024]; GetWindowText(hwnd, szEditText, 1024); // use _UNCC shim class to convert if necessary // используем для преобразования промежуточный класс _UNCC, // если необходимо return IIDFromString(_UNCC(szEditText), &riid); }
Заметим, что не требуется никакой условной компиляции. Если код скомпилирован с версией Win32 с поддержкой Unicode, то класс _UNCC просто пропустит исходный буфер через свой оператор приведения типа. Если же код компилируется с версией Win32, не поддерживающей Unicode, то класс _UNCC выделит буфер и преобразует строку в Unicode. Затем деструктор _UNCC освободит буфер, когда операция будет выполнена полностью.
Следует обсудить еще один дополнительный тип данных, связанный с текстом, — BSTR. Строковый тип BSTR нужно применять во всех интерфейсах, которые предполагается использовать из языков Visual Basic или Java. Строки BSTR являются OLECHAR-строками с префиксом длины (length-prefix) в начале строки и нулем в ее конце. Префикс длины показывает число байт, содержащихся в строке (исключая завершающий нуль) и записан в форме четырехбайтового целого числа, непосредственно предшествующего первому символу строки. Рисунок 2.7 демонстрирует BSTR на примере строки "Hi". Чтобы позволить методам свободно возвращать строки BSTR без заботы о выделении памяти, все BSTR размещены с помощью распределителя памяти, управляемого СОМ.
В СОМ предусмотрено несколько API-функций для управления BSTR:

// from oleauto.h // allocate and initialize a BSTR // выделяем память и инициализируем строку BSTR
BSTR SysAllocString(const OLECHAR *psz); BSTR SysAllocStringLen(const OLECHAR *psz, UINT cch);
// reallocate and initialize a BSTR // повторно выделяем память и инициализируем BSTR INT SysReAllocString(BSTR *pbstr, const OLECHAR *psz); INT SysReAllocStringLen(BSTR *pbstr, const OLECHAR * psz, UINT cch);
// free a BSTR // освобождаем BSTR void SysFreeString(BSTR bstr);
// peek at length- prefix as characters or bytes // считываем префикс длины как число символов или байт UINT SysStringLen(BSTR bstr); UINT SysStringByteLen(BSTR bstr);
При пересылке строк методу в качестве параметров типа [in] вызывающий объект должен заботиться о том, чтобы вызвать SysAllocString прежде, чем запускать сам метод, и чтобы вызвать SysFreeString после того, как метод закончил работу. Рассмотрим следующее определение метода:
HRESULT SetString([in] BSTR bstr);
Пусть в вызывающей программе уже имеется строка, совместимая с OLECHAR, тогда для того, чтобы преобразовать строку в BSTR до вызова метода, необходимо следующее:
// convert raw OLECHAR string to a BSTR // преобразовываем "сырую" строку OLECHAR в строку BSTR BSTR bstr = SysAllocString(OLESTR("Hello")); // invoke method // вызываем метод HRESULT hr = p->SetString(bstr); // free BSTR // освобождаем BSTR SysFreeString(bstr);
Промежуточный класс для работы с BSTR, _UBSTR, включен в заголовочный файл ustring.h:
// from ustring.h (book-specific header file) // из ustring.h (специфический для данной книги заголовочный файл) class _UBSTR { BSTR m_bstr; public: _UBSTR(const char *psz) : m_bstr(SysAllocStringLen(0, strlen(psz))) { mbstowcs(m_bstr, psz, INT_MAX); } _UBSTR(const wchar_t *pwsz) : m_bstr(SysAllocString(pwsz)) { } operator BSTR (void) const { return m_bstr; } ~_UBSTR(void) { SysFreeString(m_bstr); } };
При наличии такого промежуточного класса предыдущий фрагмент кода значительно упростится:
// invoke method // вызываем метод HRESULT hr = p->SetString(_UBSTR(OLESTR("Hello")));
Заметим, что в промежуточном классе UBSTR могут быть в равной степени использованы строки типов char и wchar_t.
При передаче из метода строк через параметры типа [out] объект обязан вызвать SysAllocString, чтобы записать результирующую строку в буфер. Затем вызывающий объект должен освободить буфер путем вызова SysFreeString. Рассмотрим следующее определение метода:
HRESULT GetString([out, retval] BSTR *pbstr);
При реализации метода потребуется создать новую BSTR-строку для возврата вызывающему объекту:
STDMETHODIMP MyClass::GetString(BSTR *pbstr) { *pbstr = SysAllocString(OLESTR("Coodbye!")) ; return S_OK; }
Теперь вызывающий объект должен освободить строку сразу после того, как она скопирована в управляемый приложением строковый буфер:
extern OLECHAR g_wsz[]; BSTR bstr = 0; HRESULT hr = p->GetString(&bstr); if (SUCCEEDED(hr)) { wcscpy(g_wsz, bstr); SysFreeString(bstr); }
Тут нужно рассмотреть еще один важный аспект BSTR. В качестве BSTR можно передать нулевой указатель, чтобы указать на пустую строку. Это означает, что предыдущий фрагмент кода не совсем корректен. Вызов wcscpy:
wcscpy(g_wsz, bstr);
должен быть защищен от возможных нулевых указателей:
wcscpy (g_wsz, bstr ? bstr : OLESTR(""));
Для упрощения использования BSTR в заголовочном файле ustring.h содержится простая встраиваемая функция:
intline OLECHAR *SAFEBSTR(BSTR b) { return b ? b : OLESTR(""); }
Разрешение использовать нулевые указатели в качестве BSTR делает тип данных более эффективным с точки зрения использования памяти, хотя и приходится засорять код этими простыми проверками.
Простые типы, показанные на рис. 2.6, могут компоноваться вместе с применением структур языка С. IDL подчиняется правилам С для пространства имен тегов (tag namespace). Это означает, что большинство IDL-определений интерфейсов либо используют операторы определения типа (typedef):
typedef struct tagCOLOR { double red; double green; double blue; } COLOR;
HRESULT SetColor([in] const COLOR *pColor);
либо должны использовать ключевое слово struct для квалификации имени тега:
struct COLOR { double red; double green; double blue; };
HRESULT SetColor([in] const struct COLOR *pColor);
Первый вариант предпочтительней. Простые структуры, подобные приведенной выше, можно использовать как из Visual Basic, так и из Java. Однако в то время, когда пишется эта книга, текущая версия Visual Basic может обращаться только к интерфейсам, использующим структуры, но она не может быть использована для реализации интерфейсов, в которых структуры являются параметрами методов.
IDL и СОМ поддерживают также объединения (unions). Для обеспечения однозначной интерпретации объединения IDL требует, чтобы в этом объединении имелся дискриминатор (discriminator), который показывал бы, какой именно член объединения используется в данный момент. Этот дискриминатор должен быть целого типа (integral type) и должен появляться на том же логическом уровне, что и само объединение. Если объединение объявлено вне области действия структуры, то оно считается неинкапсулированным (nonencapsulated):
union NUMBER { [case(1)] long i; [case(2)] float f; };
Атрибут [case] применен для установления соответствия каждого члена объединения своему дискриминатору. Для того чтобы связать дискриминатор с неинкапсулированным объединением, необходимо применить атрибут [switch_is]:
HRESULT Add([in, switch_is(t)] union NUMBER *pn, [in] short t);
Если объединение заключено вместе со своим дискриминатором в окружающую структуру, то этот составной тип (aggregate type) называется инкапсулированным, или размеченным объединением (discriminated union):
struct UNUMBER { short t; [switch_is(t)] union VALUE { [case(1)] long i; [case(2)] float f; }; };
СОМ предписывает для использования с Visual Basic одно общее размеченное объединение. Это объединение называется VARIANT и может хранить объекты или ссылки на подмножество базовых типов, поддерживаемых IDL.
Каждому из поддерживаемых типов присвоено соответствующее значение дискриминатора:
VT_EMPTY nothing VT_NULL SQL style Null VT_I2 short VT_I4 long VT_R4 float VT_R8 double VT_CY CY (64-bit currency) VT_DATE DATE (double) VT_BSTR BSTR VT_DISPATCH IDispatch * VT_ERROR HRESULT VT_BOOL VARIANT_BOOL (True=-1, False=0) VT_VARIANT VARIANT * VT_UNKNOWN IUnknown * VT_DECIMAL 16 byte fixed point VT_UI1 opaque byte
Следующие два флага можно использовать в сочетании с вышеприведенными тегами, чтобы указать, что данный вариант (variant) содержит ссылку или массив данного типа:
VT_ARRAY Указывает, что вариант содержит массив SAFEARRAY VT_BYREF Указывает, что вариант является ссылкой
СОМ предлагает несколько API-функций для управления VARIANT:
// initialize a variant to empty // обнуляем вариант void VariantInit(VARIANTARG * pvarg);
// release any resources held in a variant // освобождаем все ресурсы, используемые в варианте HRESULT VariantClear(VARIANTARG * pvarg);
// deep-copy one variant to another // полностью копируем один вариант в другой HRESULT VariantCopy(VARIANTARG * plhs, VARIANTARG * prhs);
// dereference and deep-copy one variant into another // разыменовываем и полностью копируем один вариант в другой HRESULT VariantCopyInd(VARIANT * plhs, VARIANTARG * prhs);
// convert a variant to a designated type // преобразуем вариант к указанному типу HRESULT VariantChangeType(VARIANTARG * plhs, VARIANTARG * prhs, USHORT wFlags, VARTYPE vtlhs);
// convert a variant to a designated type // преобразуем вариант к указанному типу (с явным указанием кода локализации) HRESULT VariantChangeTypeEx(VARIANTARG * plhs, VARIANTARG * prhs, LCID lcid, USHORT wFlags, VARTYPE vtlhs);
Эти функции значительно упрощают управление VARIANT'ами. Чтобы понять, как используются эти API-функции, рассмотрим метод, принимающий VARIANT в качестве [in]-параметра:
HRESULT UseIt([in] VARIANT var);
Следующий фрагмент кода демонстрирует, как передать в этот метод целое число:
VARIANT var; VariantInit(&var); // initialize VARIANT // инициализируем VARIANT V_VT(&var) = VT_I4; // set discriminator // устанавливаем дискриминатор V_I4(&var) = 100; // set union // устанавливаем объединение HRESULT hr = pItf->UseIt(var); // use VARIANT // используем VARIANT VariantClear(&var); // free any resources in VARIANT // освобождаем все ресурсы VARIANT
Отметим, что этот фрагмент кода использует макросы стандартного аксессора (accessor) для доступа к элементам данных VARIANT. Две следующие строки
V_VT(&var) = VT_I4; V_I4(&var) = 100;
эквивалентны коду, который обращается к самим элементам данных:
var.vt = VT_I4; var.lVal = 100;
Первый вариант предпочтительнее, так как он может компилироваться на С-трансляторах, которые не поддерживают неименованных объединений.
Ниже приведен пример того, как с помощью приведенной выше технологии реализация метода использует параметр VARIANT в качестве строки:
STDMETHODIMP MyClass::UseIt( /*[in] */ VARIANT var) { // declare and init a second VARIANT // объявляем и инициализируем второй VARIANT VARIANT var2; VariantInit(&var2); // convert var to a BSTR and store it in var2 // преобразуем переменную в BSTR и заносим ее в var2 HRESULT hr = VariantChangeType(&var2, &var, 0, VT_BSTR); // use the string // используем строку if (SUCCEEDED(hr)){ ustrcpy(m_szSomeDataMember, SAFEBSTR(V_BSTR(&var2))); // free any resources held by var2 // освобождаем все ресурсы, поддерживаемые var2 VariantClear(&var2); } return hr; }
Отметим, что API-процедура VariantChangeType способна осуществлять сложное преобразование любого переданного клиентом типа из VARIANT в нужный тип (в данном случае BSTR).
Один из последних типов данных, который вызывает дискуссию, — это интерфейс СОМ. Интерфейсы СОМ могут быть переданы в качестве параметров метода одним из двух способов. Если тип интерфейсного указателя известен на этапе проектирования, то тип интерфейса может быть объявлен статически:
HRESULT GetObject([out] IDog **ppDog);
Если же тип на этапе проектирования неизвестен, то разработчик интерфейса может дать пользователю возможность задать тип на этапе выполнения. Для поддержки динамически типизируемых интерфейсов в IDL имеется атрибут [iid_is]:
HRESULT GetObject([in] REFIID riid, [out, iid_is(riid)] IUnknown **ppUnk);
Хотя эта форма будет работать вполне хорошо, следующий вариант предпочтительнее из-за его подобия с QueryInterface:
HRESULT GetObject([in] REFIID riid, [out, iid_is(riid)] void **ppv);
Атрибут [iid_is] можно использовать как с параметрами [in], так и [out] для типов IUnknown * или void *. Для того чтобы использовать параметр интерфейса с динамически типизируемым типом, необходимо просто установить IID указателя требуемого типа:
IDog *pDog = 0; HRESULT hr = pItf->GetObject(IID_IDog, (void**)&pDog);
Соответствующая реализация для инициализации этого параметра просто использовала бы метод QueryInterface для нужного объекта:
STDMETHODIMP Class::GetObject(REFIID riid, void **ppv) { extern IUnknown * g_pUnkTheDog; return g_pUnkTheDog->QueryInterface(riid, ppv); }
Для уменьшения количества дополнительных вызовов методов между клиентом и объектом указатели интерфейса с динамически типизируемым типом должны всегда использоваться вместо указателей интерфейса со статически типизируемым типом IUnknown.
1
Тип OLECHAR был предпочтен типу данных TCHAR, используемому Wn32 API, чтобы избежать необходимости поддержки двух версий каждого интерфейса (CHAR и WCHAR). Поддерживая только один тип символов, разработчики объектов становятся независимыми от типов символов препроцессора UNICODE, который используется их клиентами.
2
_UNCC является просто версией _U и имеет операторы приведения типа для wchart * и char *. Хотя расширенный вариант можно использовать где угодно, автор предпочитает использовать его только при согласовании с непостоянно корректными интерфейсами, чтобы подчеркнуть, что система типов в некоторой степени компрометируется. Увы, многие из СОМ API не являются постоянно корректными, так что промежуточный класс _UNCC применяется очень часто.
3
Хотя автор и находит строковые процедуры из ustring.h более чем подходящими для управления обработкой текстов в СОМ, библиотеки ATL и MFC используют несколько иной подход, основанный на аllоса и макросах. Более подробную информацию об этих подходах можно прочитать в соответствующей документации.
4
К нему можно обращаться и как к VARIANTARG.Термин VARIANTARG относится к вариантам, которые являются допустимыми типами параметров. Термин же VARIANT относится к вариантам, которые являются допустимыми результатами методов. Тип данных VARIANTARG является просто псевдонимом для VARIANT, и оба этих типа могут использоваться равнозначно.
Управление ресурсами и IUnknown
Как было в случае с DuplicatePointer и DestroyPointer из предыдущей главы, методы AddRef и Release из IUnknown имеют очень простой протокол, которого должны придерживаться все, кто пользуется указателями этих интерфейсов. Эти правила освобождают клиента от необходимости управлять временем жизни объекта, когда несколько интерфейсных указателей могут указывать или не указывать на один и тот же объект. Клиентам необходимо только следовать простым правилам AddRef/Release единообразно для всех интерфейсных указателей, с которыми им приходится сталкиваться, а объект будет сам управлять своим временем жизни.
Спецификация модели компонентных объектов (Component Object Model Specification) содержит четкие определения правил подсчета ссылок СОМ. Понимание мотивировки этих определений имеет решающее значение при СОМ-программировании на C++. Эти правила СОМ о подсчете ссылок могут быть сведены к трем простым аксиомам:
Когда ненулевой указатель интерфейса копируется из одной ячейки памяти в другую, должен вызываться AddRef для извещения объекта о дополнительной ссылке.
Перед тем как произойдет перезапись той ячейки памяти, где содержится ненулевой указатель интерфейса, необходимо вызвать Release, чтобы известить объект, что ссылка уничтожается.
Избыточное количество вызовов AddRef и Release можно сократить, если иметь дополнительную информацию о связях между двумя и более ячейками памяти.
Аксиома о дополнительной информации введена главным образом для того, чтобы ввести возможность преобразования запутанных ситуаций в разумные и осмысленные идиомы программирования (например, стеки временных вызовов и сгенерированное компилятором занесение переменной в регистр не нуждаются в подсчете ссылок). Можно провести месяцы в поиске особых связей между переменными, содержащими явные указатели на интерфейс в программе и оптимизировать избыточные вызовы AddRef и Release, но поступать так было бы неосмотрительно. Выгода от удаления этих избыточных вызовов явно незначительна, так как даже в худшем случае, когда объект вызывается с расстояния более 8500 миль со средней скоростью передачи 14.4 кбит /сек, эти избыточные вызовы никогда не уйдут из вызывающего потока и нечасто требуют множество инструкций для выполнения.
Если руководствоваться приведенными выше тремя простыми аксиомами о подсчете ссылок в интерфейсных указателях, то можно записать это в виде руководящих принципов программирования, чтобы установить, когда вызывать и когда не вызывать AddRef и Release. Вот несколько типичных ситуаций, требующих вызова метода AddRef:
А1. Когда ненулевой интерфейсный указатель записывается в локальную переменную.
А2. Когда вызываемый объект пишет ненулевой интерфейсный указатель в параметр [out] или [in, out] метода или функции.
A3. Когда вызываемый объект возвращает ненулевой интерфейсный указатель как физический результат (physical result) функции. А4. Когда ненулевой интерфейсный указатель пишется в элемент данных объекта.
Некоторые типичные ситуации, требующие вызова метода Release:
R1. Перед перезаписью ненулевой локальной переменной или элемента данных.
R2. Перед тем как покинуть область действия ненулевой локальной переменной.
R3. Когда вызываемый объект перезаписывает параметр [in,out] метода или функции, начальное значение которых отлично от нуля. Заметим, что параметры [out] предполагаются нулевыми при вводе и никогда не могут освобождаться вызываемым объектом.
R4. Перед перезаписью ненулевого элемента данных объекта.
R5. Перед завершением работы деструктора объекта, имеющего в качестве элемента данных ненулевой интерфейсный указатель.
Типичная ситуация, к которой применимо правило о дополнительной информации, возникает при передаче указателей интерфейсов функциям как параметрам [in]:
S1. Когда при вызове функции или метода ненулевой интерфейсный указатель передается через [in]-параметр, вызов AddRef и Release, не требуются, так как время жизни временной переменной в стеке является строгим подмножеством времени жизни выражения, использованного для инициализации формального аргумента.
Эти десять руководящих принципов охватывают ситуации, снова и снова возникающие при программировании в СОМ, и было бы неплохо их запомнить.
Чтобы конкретизировать правила подсчета ссылок в СОМ, предположим, что имеется глобальная функция, которая возвращает объекту интерфейсный указатель:
void GetObject([out] IUnknown **ppUnk);
и что имеется другая глобальная функция, которая выполняет некую полезную работу над объектом:
void UseObject([in] IUnknown *pUnk);
Написанный ниже код использует эти процедуры, чтобы управлять некоторыми объектами и возвращать интерфейсный указатель вызывающему объекту. Руководящие принципы, применимые к каждому оператору, указаны в комментариях к нему:
void GetAndUse(/* [out] */ IUnknown ** ppUnkOut) { IUnknown *pUnk1 = 0, *pUnk2 = 0; *ppUnkOut =0; // R3
// get pointers to one (or two) objects // получаем указатели на один (или два) объекта
GetObject(&pUnk1); //A2 GetObject(&pUnk2); //A1
// set pUnk2 to point to first object // устанавливаем pUnk2, чтобы указать на первый объект
if (pUnk2) pUnk2->Release(): //R1 if (pUnk2 = pUnk1) pUnk2->AddRef(): //A1
// pass pUnk2 to some other function // передаем pUnk2 какой-нибудь другой функции
UseObject(pUnk2); //S1
// return pUnk2 to caller using ppUnkOut parameter // возвращаем pUnk2 вызывающему объекту, используя // параметр ppUnkOut
if (*ppUnkOut = pUnk2) (*ppUnkOut)->AddRef(); // A2
// falling out of scope so clean up // выходит за область действия и поэтому освобождаем
if (pUnk1) pUnkl->Release(); //R2 if (pUnk2) pUnk2->Release(); //R2 }
Важно отметить, что в вышеприведенном коде правило A2 применяется дважды, но по двум разным причинам. При вызове GetObject код выступает как вызывающий объект, а реализация GetObject является вызываемым объектом. Это означает, что реализация GetObject является ответственной за вызов AddRef через параметр [out]. При перезаписи памяти, на которую ссылается ppUnkOut, код выступает как вызываемый объект и корректно вызывает AddRef через интерфейсный указатель перед возвратом управления вызывающему объекту.
Существуют некоторые тонкости относительно AddRef и Release, подлежащие обсуждению. Как AddRef, так и Release предназначались для возврата 32-битного целого числа без знака. Это целое число отражает общее количество оставшихся ссылок после применения операций AddRef или Release.
Однако по целому ряду причин, связанных с многопоточным режимом, удаленным доступом и мультипроцессорной архитектурой, нельзя быть уверенным в том, что эта величина будет точно отражать общее число неосвобожденных интерфейсных указателей, и клиенту следует игнорировать ее, если только она не используется в целях диагностики при отладке.
Единственный случай, заслуживающий внимания, это когда Release возвращает нуль. Нулевой результат от Release надежно свидетельствует о том, что данный объект более не действителен ни в каком смысле. Однако обратное неверно. Это значит, что когда Release возвращает не нуль, нельзя утверждать, что объект еще работоспособен. Фактически, если Release был вызван указателем интерфейса столько же раз, сколько этим же указателем интерфейса был вызван AddRef, то данный указатель интерфейса недействителен и более не обеспечивает указание на действующий объект. В то же время возможно, что это — случайность, а объект все еще работоспособен благодаря другим, еще не освобожденным, указателям, и все может измениться в самый неподходящий момент. Чтобы однажды освобожденные (released) интерфейсные указатели более не использовались, можно, например, обнулять их сразу же после вызова метода Release:
inline void SafeRelease(IUnknown * &rpUnk) { if (rpUnk) { rpUnk->Release(); rpUnk = 0; // rpUnk passed by reference // rpUnk, переданный ссылкой } }
Когда этот способ применен, любое использование указателя интерфейса после его высвобождения немедленно вызовет ошибку доступа. Эта ошибка затем может быть достоверно воспроизведена и, можно надеяться, отловлена еще на этапе разработки.
Еще одна тонкость, относящаяся к AddRef и Release, состоит в выходе из блока. Функция GetAndUse, приведенная ранее, имеет только одну точку выхода. Это означает, что операторы, высвобождающие указатели интерфейса в конце функции, будут всегда выполняться ранее завершения работы функции. Если же функция завершит работу, не доходя до этих операторов — либо благодаря явному оператору return или же, что хуже, необработанному (unhandled) исключению C++, — то эти завершающие операторы будут пропущены и все ресурсы, удерживаемые неосвобожденными интерфейсными указателями, будут утеряны до окончания клиентской программы.Это означает, что к указателям интерфейса СОМ следует относиться с осторожностью, особенно при использовании их в средах, использующих исключения C++. Впрочем, это касается и других системных ресурсов, с которыми приходится работать, будь то семафоры или динамически распределяемая память. Далее в этой главе обсуждаются интеллектуальные СОМ-указатели, которые обеспечивают вызов Release во всех ситуациях.
